©作者 | leo
早于90年代初,数据透视的概念就被提出,主要的应用场景是处理大量数据的交互式汇总查询,它实现了行或列的移动,使得行可以移到列上,列移到行上,从而根据使用者的诉求取对关注的数据子集进行排序,分组,筛选,汇总等等,它以强大而灵活的数据查询方式被广泛推广开来,人们可以自定义计算公式,展开或者折叠需要关注的结果数据集,查看数据摘要信息。
今天我们讨论的是两个均有数据透视功能的工具,也是时下最为常见和流行的数据分析工具:Excel和Python,希望能够通过本文让您加深对数据透视的理解和使用。文中也会在合适的地方讲二者进行对比,希望能对读者有一定启发。
首先我们来介绍下Excel中的数据透视表的使用方法。
01 Excel数据透视简介
数据源的基本要求:
Excel使用的数据源是有一定的格式要求的,并非任何数据都能够直接进行数据透视,这点来说,python对数据的选择则更为灵活。
● 数据源首行需要是标题行
如果没有标题行,则在后面的字段汇总就会产生问题,因此这是首要条件。
● 不能包含空行和空列
因为透视表的数据截取是以空行和空列作为停止的条件的。
● 不能包含空的单元格
数据透视主要是对数值型进行汇总、文本型计数,空的单元格会对汇总结果产生影响。
● 不能包含合并单元格
合并的单元格会导致读取失败。
● 不能包含同类字段
02 数据透视表使用方法
创建数据透视表
下面介绍如何快速建立数据透视表,首先通过ctrl+shift+⬇和ctrl+shift+向左箭头选中数据区域,然后单击菜单栏下的插入-数据透视表,在弹出框中选择透视表的位置是在新的工作表还是现有工作表的某个区域,位置栏旁边的箭头用于设定区域。
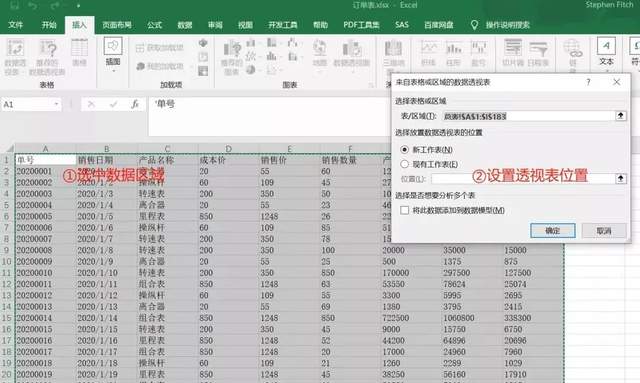
新生成的透视表允许我们对不同的字段进行各种数学汇总,只需要将不同的维度字段拖入对应的栏目中即可,比如查看不同月份、季度的销量、销售额情况可以将销售日期字段拖入行中,将销售数量拖入值中,并选择加和汇总。
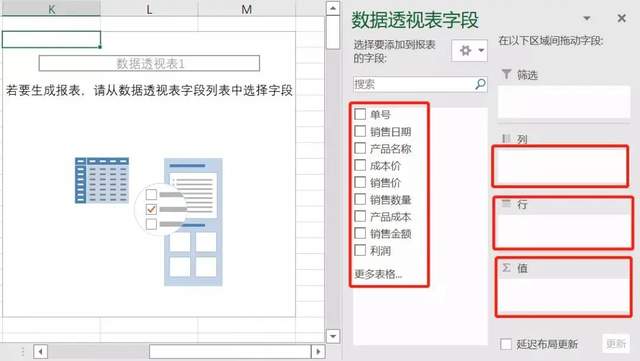
数据刷新
Excel数据透视表使用的是缓存数据,当数据源有更新时,并不会自动刷新数据,需要手动刷新数据源,根据改动类型分为:数据变动,数据区域变动。
数据变动
指的是在现有的数据区域内,对数据做了改动,需要在透视表上面进行更新。可以通过手动刷新,可以通过点击透视表选项下的刷新按钮自动更新数据。

数据区域变动
指的是有新的数据添加,此时数据区域发生了变化,无法通过手动刷新数据来实现数据的更新。此时,可以通过刷新按钮旁边的【更改数据源】选项,重新选择数据区域来实现。
数据分组
数值和文本分组
如果我们想将不同年龄段的人群进行分组,不同姓氏的人群分组,这时就需要应用到数值和文本分组了。
如下图,属于文本型分组,需要选择需要的字段,连续字段直接圈选,非连续字段可以使用ctrl键。
对于数值型分组,由于数值是有规律的,因此选择创建组之后会自动进行分组。
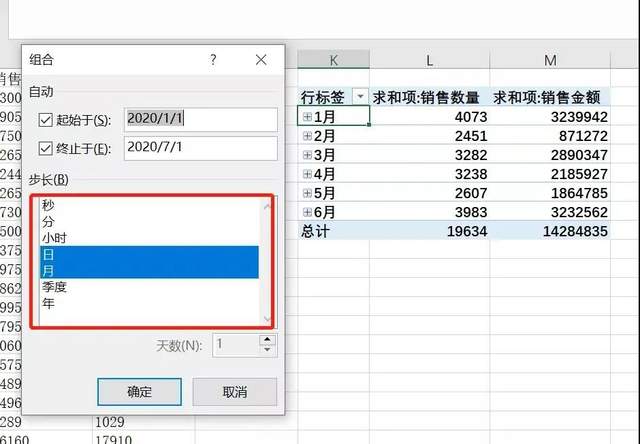
日期分组
在透视表上面右击日期项,根据需要的时间频度进行选择。
常用的值显示方式
Excel透视表提供值显示方式,可以满足多种不同的数据对比和数据构成计算分析。
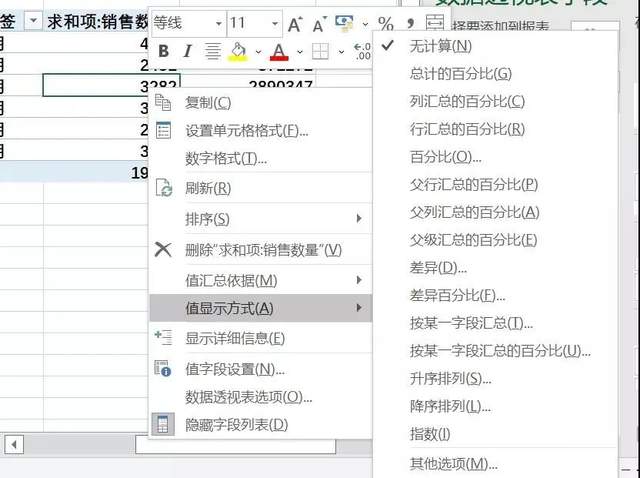
下面介绍常用的几种计算方式:
● 总计的百分比
每个数据占所在行列总和的百分比
● 行/列总百分比
每个数据占所在行或列所有项总和的百分比
● 百分比
根据某个字段完成百分比对比计算
● 父行汇总百分比
每个数据项占该列父级项总和的百分比
● 父级汇总百分比
每个数据项占该列和行父级项总和的百分比
● 差异百分比
每个字段与固定被选取字段的差百分比
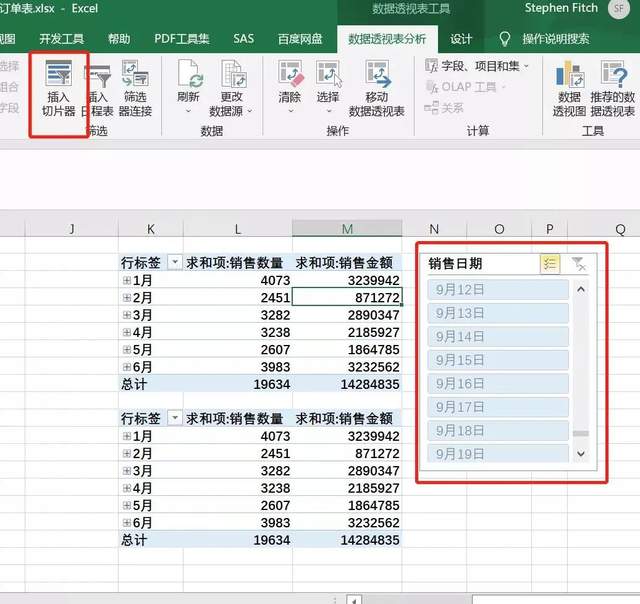
03 切片的使用
切片器是Excel2010引入的新功能,它提供了更为强大的数据交互能力,比起单纯的数据筛选,使用更加流畅和灵活。
多表联动筛选
使用前提
Excel2013版本以上,使用同一份数据源建立的透视表才能进行多表联动。
使用方法
在透视表选项卡下选择插入切片器,然后选择要呈现的字段,切片器会自动将数据加载到切片窗口。
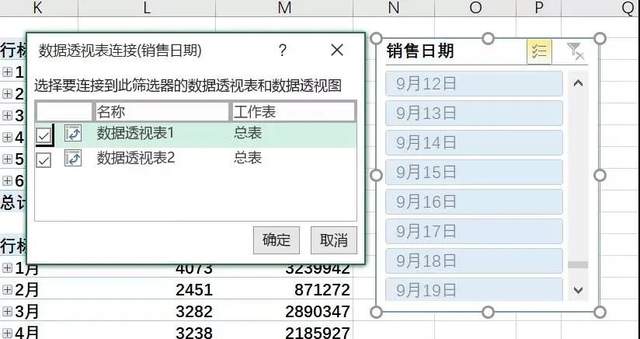
设置多表联动,右击切片器窗口,选择报表链接,就可以选择切片器关联的透视表了。
2.1 Python数据透视功能简介
Python的数据透视功能主要通过pivot_table()函数实现,接下来主要介绍它的相关使用。
pivot_table()函数参数介绍
在python中,主要通过pandas里面pivot_table()函数来进行数据透视,让我们首先了解下该方法的主要参数功能:
完整的pivot_table()表达式如下
pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
● data
数据源dataframe对象
● index
指定分组的列,相当于行索引
pt = pd.pivot_table(p_data,index=['销售日期'])
● values
需要进行聚合运算的数值字段
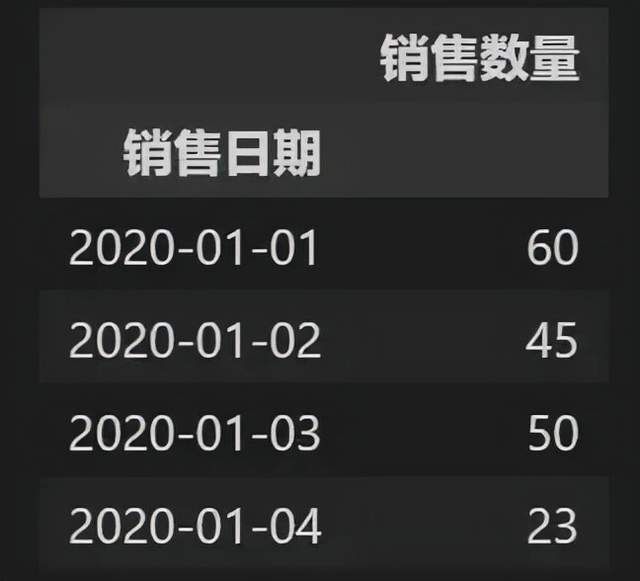
pt = pd.pivot_table(p_data,index=['销售日期'],values=['销售数量'])
● aggfunc
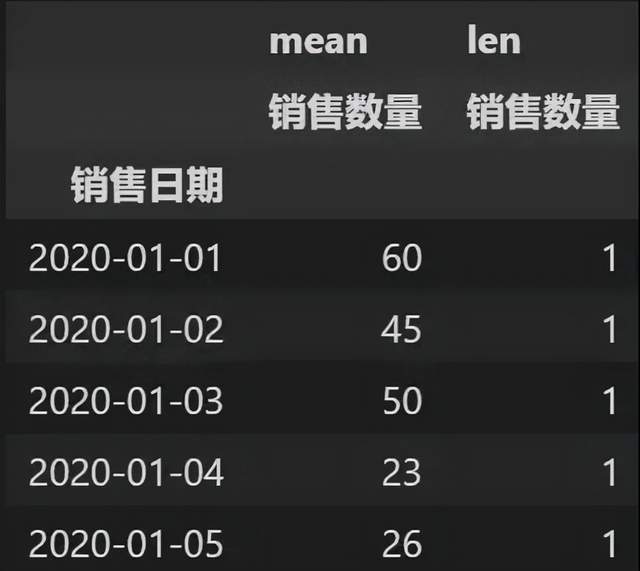
指定聚合方法,默认求和,既可以使用字典的形式对不同字段进行不同的运算方法,也可以对同个字段进行不同的运算方法,同时也可以使用自定义函数来作为聚合方法运算。
pt = pd.pivot_table(p_data,index=['销售日期'],values=['销售数量'],aggfunc=[np.mean,len])
● columns
添加列索引,更细化的展示数据的汇总情况
pt = pd.pivot_table(p_data,index=['销售日期'],columns=['产品名称'], values=['销售数量'],aggfunc=[np.mean,len])

● fill_value
用于填充缺失值
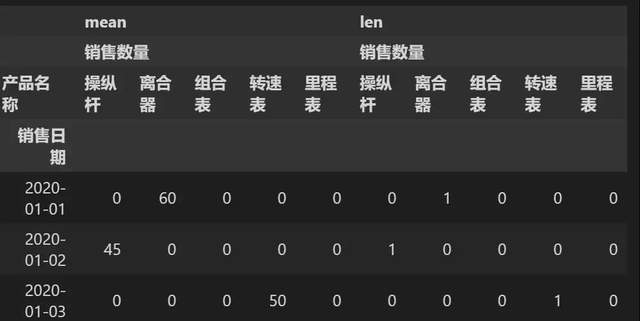
pt = pd.pivot_table(p_data,index=['销售日期'],fill_value=0,columns=['产品名称'], values=['销售数量'],aggfunc=[np.mean,len])
通过了解pivot_table()函数的基本参数,可以发现,通过index和columns参数,能够自由的选取不同字段进行Excel当中的行列互换汇总计算,比如百分比的计算,我们可以通过自定义函数,添加到aggfunc参数中,应用到所有相关字段。
高级透视功能
一旦通过上述设置得到透视数据后,就可以使用高级透视功能进行数据过滤。
比如想查看Manger字段是Debra Henley下的所有数据
pt.query('Manager == ["Debra Henley"]')
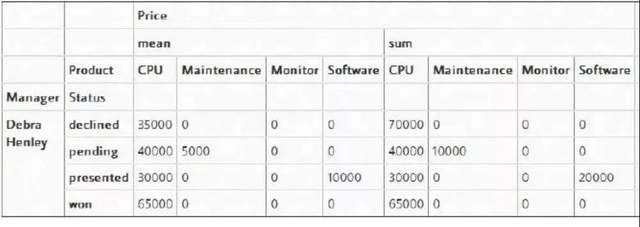
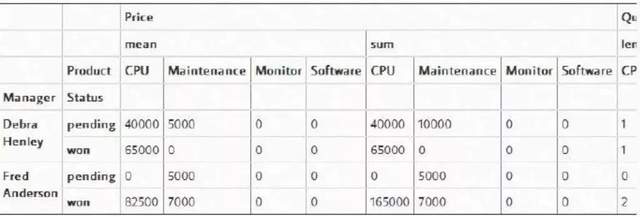
筛选status(状态)是"pending"和"won"的数据信息
pt.query('Status == ["pending","won"]')
通过以上展示,可以发现Excel在处理数据透视方便具有更好的交互性和数据呈现能力,缺点是数据的汇总相对比较固定,不具备更多的灵活度,因此对于数据分析并不复杂的应用场景,选择Excel比较合适。
而Python在处理数据透视方面,计算能力和字段的灵活组合方面远远胜于Excel,因此如果需要复杂的数据透视功能,可以通过python来实现。
此外,python相较于Excel透视更为强大的一点是python的时间处理功能,也就是时间序列的处理,对于金融从业者来说,python的时间序列处理能够更为精细化的展示数据透视结果,限于篇幅不做进一步展开。