【大数据】ETL 数据迁移工具 Kettle 入门
一、前言
ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换,迁移,所以了解并掌握一种ETL工具的使用,必不可少,这里我介绍一个原作者在工作中使用了3年左右的ETL工具Kettle,本着好东西不独享的想法,跟大家分享碰撞交流一下!在使用中这个工具真的很强大,支持图形化的GUI设计界面,然后可以以工作流的形式流转,在做一些简单或复杂的数据抽取、质量检测、数据清洗、数据转换、数据过滤等方面有着比较稳定的表现,其中最主要的我们通过熟练的应用它,减少了非常多的研发工作量,提高了我们的工作效率
Kettle 是一款国外开源的 ETL 工具,纯 Java 编写,绿色无需安装,数据抽取高效稳定(数据迁移工具)。
- Kettle 中文网 : https://www.kettle.net.cn/

- Kettle Web 在线体验平台:https://trimdata.cn:2000/myservice/sjdx/list.do?dxdm=SYS_QX_QXXX_ZYGLCD
Kettle 中有两种脚本文件,transformation 和 job,
- transformation 完成针对数据的基础转换
- job 则完成整个工作流的控制。
基本概念
- Transformation(转换):数据抽取/迁移主要设计的对象,负责定义数据从数据源到目标地流动。各步骤并发执行。
- Job(作业):支持组合多个转换,即流程控制,支持定时任务执行。各步骤按一定规则顺序执行,可定义为并行执行。
- Step(步骤):最核心的概念,转换和作业都是由步骤组成,数据转换和数据清洗都是在步骤中完成,步骤是 Kettle 具体做事情的对象。
- hop(跳):即连接,步骤与步骤之间的连接称之为跳。代表数据流量。
二、ETL介绍
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据, ETL是BI(商业智能)项目重要的一个环节。
- Kettle 主要包含4类产品,Spoon,Carte,Pan,Kitchen。
- Spoon:可视化开发工具。可视化运行,监控等。
- Carte:轻量级 Web 服务器,支持远程执行 Kettle 脚本。
- Pan:命令行执行 Kettle Transformation 脚本。如:pan.sh file=xxx.ktr 。
- Kitchen:命令行形式执行 Kettle Job 脚本工具。如:kitchen.sh file=xxx.kjb 。
特性
- 高效稳定,支持多种类型的数据格式,如:MySQL,Oracle,PostGreSQL,CSV 等。
- 可视化设计。
安装部署
- 官网地址 https://community.hitachivantara.com/docs/DOC-1009855
- 下载地址 https://sourceforge.net/projects/pentaho/files/Data%20Integration/
2.1 Windows 下安装使用
- 安装 JDK
- 下载 Kettle 压缩包,Kettle 是绿色软件,解压缩到任意本地路径即可
- 双击 Spoon.bat,启动图形化界面工具,就可以直接使用了
2.2 单机
运行数据库资源库中的转换
[djm data-integration]$./pan.sh -rep=my_repo -user=admin -pass=admin -trans=stu1tostu2 -dir=/参数说明:
- rep:资源库名称
- user:资源库用户名
- pass:资源库密码
- trans:要启动的转换名称
- dir:目录(不要忘了前缀 /)
运行资源库里的作业:
[djm data-integration]$./kitchen.sh -rep=repo1 -user=admin -pass=admin -job=jobDemo1 -logfile=./logs/log.txt -dir=/参数说明:
- rep:资源库名
- user:资源库用户名
- pass:资源库密码
- job:job名
- dir:job路径
- logfile:日志目录
2.3 集群安装
准备三台服务器,hadoop102 作为 Kettle 主服务器,服务器端口号为 8080,hadoop103 和 hadoop104 作为两个子服务器,端口号分别为 8081 和 8082
上传解压 kettle 的安装包
进到 /opt/module/data-integration/pwd 目录,修改配置文件
- 修改主服务器配置文件 carte-config-master-8080.xml
master
hadoop102
8080
Y
cluster
cluster
- 修改从服务器配置文件carte-config-8081.xml
master
hadoop102
8080
cluster
cluster
Y
Y
slave1
hadoop103
8081
cluster
cluster
N
- 修改从配置文件carte-config-8082.xml
master
hadoop102
8080
cluster
cluster
Y
Y
slave2
hadoop104
8082
cluster
cluster
N
分发
启动相关进程,在 hadoop102,hadoop103,hadoop104 上执行
[djm@hadoop102 data-integration]$./carte.sh hadoop102 8080
[djm@hadoop103 data-integration]$./carte.sh hadoop103 8081
[djm@hadoop104 data-integration]$./carte.sh hadoop104 8082三、案例分析
- 把 stu1 的数据按 id 同步到 stu2,stu2 有相同 id 则更新数据
- 使用作业执行上述转换,并且额外在表 stu2 中添加一条数据
- 将 Hive 表的数据输出到 hdfs
- 读取 HDFS 文件并将 sal 大于 1000 的数据保存到 HBase 中
3.1 案例一:把 stu1 的数据按 id 同步到 stu2,stu2 有相同 id 则更新数据
1)在 mysql 中创建两张表
mysql> create database kettle;
mysql> use kettle;
mysql> create table stu1(id int,name varchar(20),age int);
mysql> create table stu2(id int,name varchar(20));
2)往两张表中插入数据
mysql> insert into stu1 values(1001,'zhangsan',20),(1002,'lisi',18), (1003,'wangwu',23);
mysql> insert into stu2 values(1001,'wukong');
3)在 kettle 中新建转换
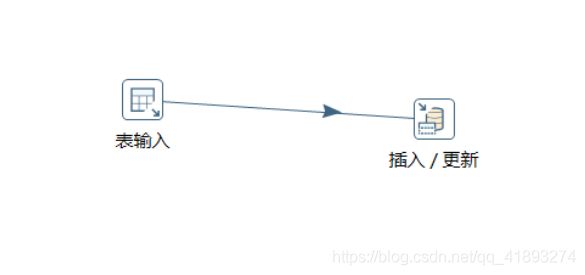
4)分别在输入和输出中拉出表输入和插入/更新
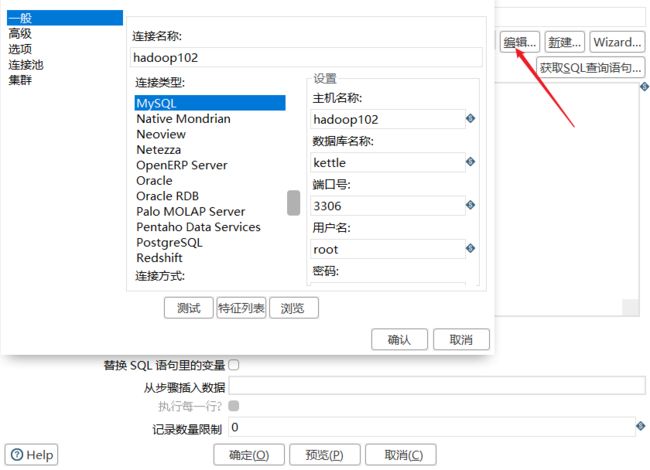
5)双击表输入对象,填写相关配置,测试是否成功
6)双击 更新/插入对象,填写相关配置
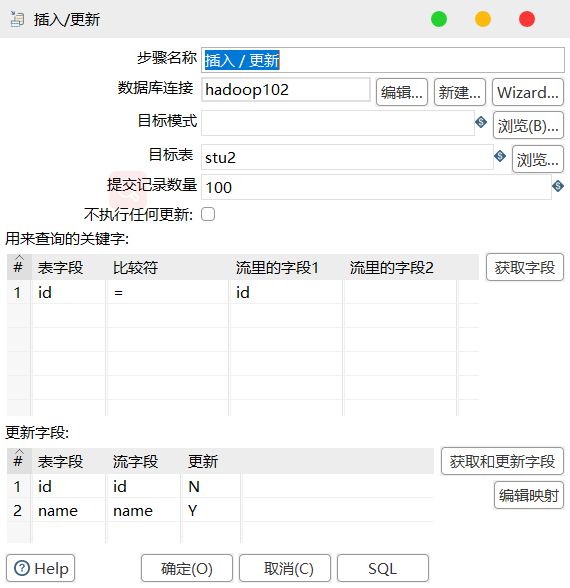
7)保存转换,启动运行,去 mysql 表查看结果
3.2 案例二:使用作业执行上述转换,并且额外在表 stu2 中添加一条数据
1)新建一个作业
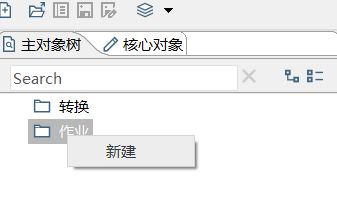
2)按图示拉取组件
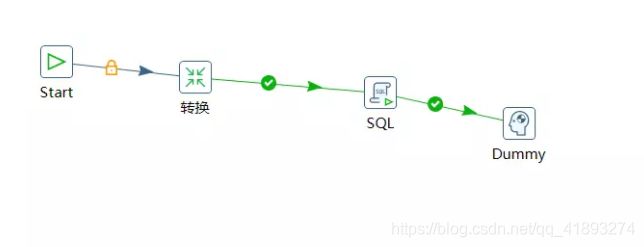
3)双击 Start 编辑属性
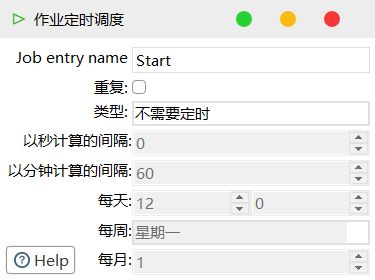
4)双击转换,选择案例 1 保存的文件
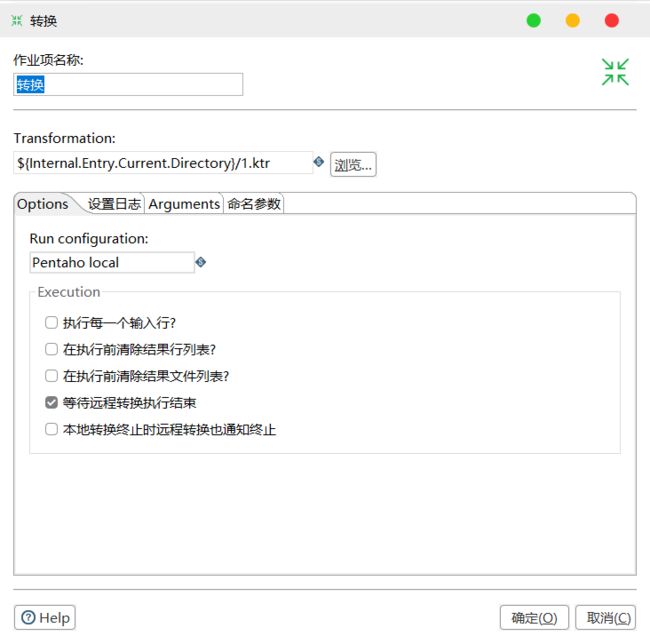
5)双击 SQL,编辑 SQL 语句
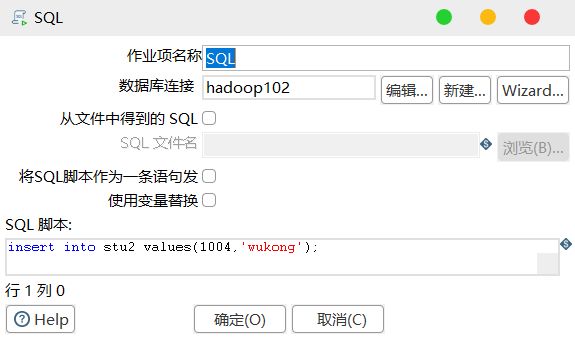
3.3 案例三:将 Hive 表的数据输出到 hdfs
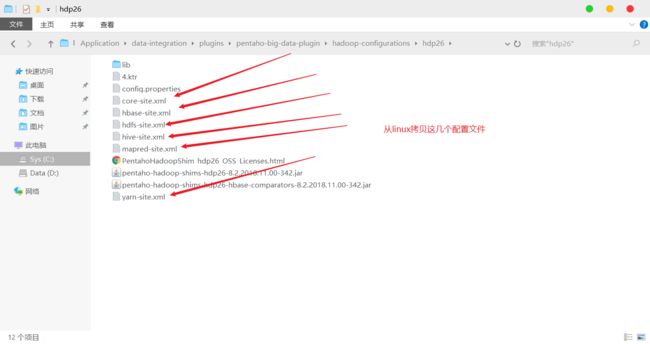
1)因为涉及到 Hive 和 HBase 的读写,需要修改相关配置文件
2)创建两张表 dept 和 emp
CREATE TABLE dept(deptno int, dname string,loc string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
CREATE TABLE emp(empno int, ename string, job string, mgr int,
hiredate string, sal double, comm int,deptno int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
3)导入数据
load data local inpath '/opt/module/datas/dept.txt' into table dept;
load data local inpath '/opt/module/datas/emt.txt' into table emp;
4)按下图建立流程图
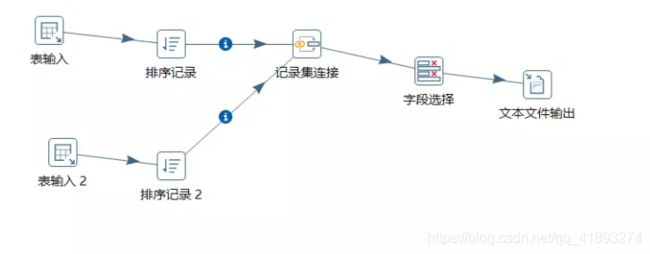
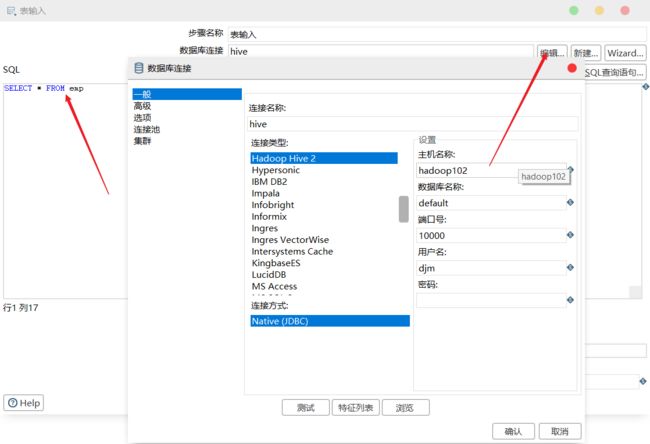
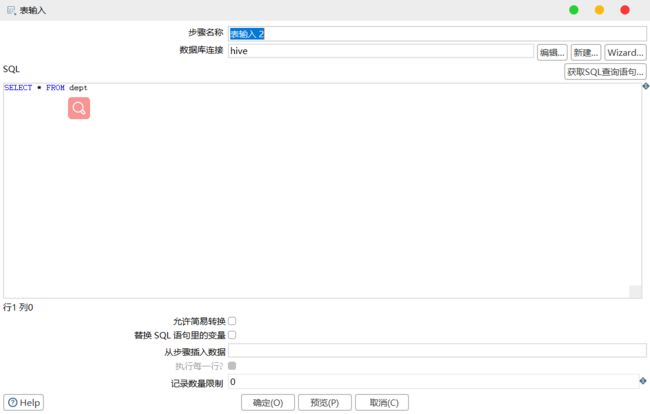
5)设置表输入,连接 Hive
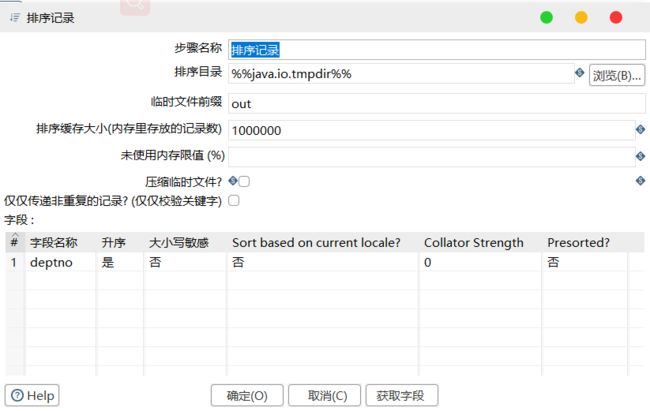
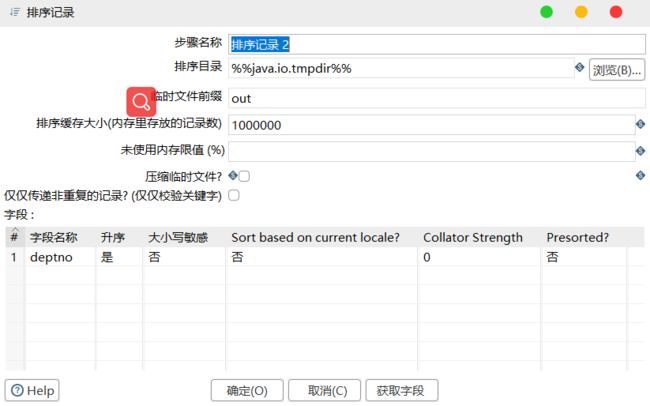
6)设置排序记录属性
7)设置连接属性
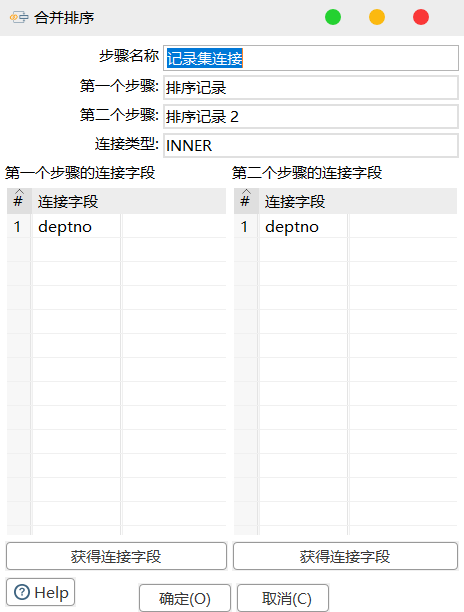
8)设置字段选择
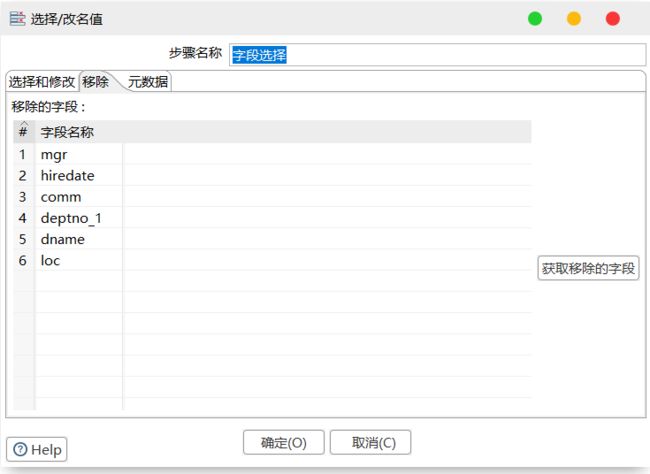
9)设置文件输出
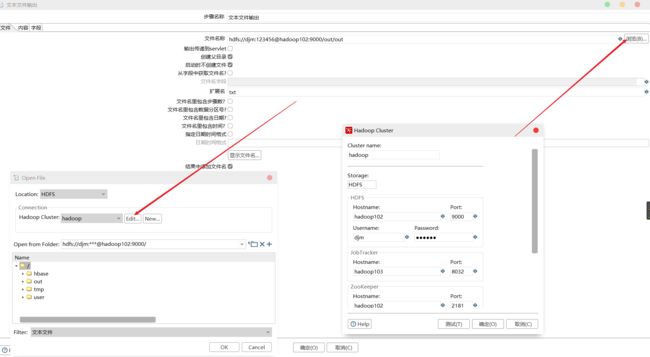
10)保存并查看 HDFS
3.4 案例四:读取 HDFS 文件并将 sal 大于 1000 的数据保存到 HBase 中
相关文章
- kettle 场景实践
四、ETL实现细说
其实实现ETL功能的工具很多,我熟悉并使用过的:Informatica PowerCenter、kettle、sql、PLSQL编程、python等等。
分别简单聊聊这些实现ETL的手段:
(1)、Informatica PowerCenter
此软件是商用的,网上成熟的中文资料比较少,而且版本较旧。英文资料居多,给很多初学者带来了困扰。国内最出名的大神就是杨晓东,国内的中文资料几乎全是杨晓东分享的,资料对应的版本还停留在7.6和8.5。(我当年学的时候,自己买了书,在淘宝上淘的视频,还在杨晓东的群里打酱油,经过6个月的努力,才能上手正常工作)
(2)、kettle
此软件是开源的,纯java编写,网上文档和视频资料特别多,有很多人在博客分享自己的案例。(从第一次接触Kettle,到灵活使用,我一共花了2天时间。这主要受益于我的技术沉淀:java编程、sql、Informatica PowerCenter的使用)
(3)、sql
一提到sql,各位感觉只要是个干IT的人就会。你以为就是select\insert\update\delete,你就实现ETL了?醒醒吧铁子,你如果这样想,你永远吃不上4个菜!!
此处提到的sql,要与你工作中的业务相结合,你得吃透业务,然后编写出来的sql。你操作完sql后,你还要验证一下,结果和你想的对不对?时效如何?如果性能不好,你还要sql调优。一说调优,有些人会说百度上找啊,文章特别多。你会发现很文章,好像是近亲,天下学文一大抄啊!而且你不懂业务,你要调优纯扯淡。
举例说明:
小明饭量很大,他一顿饭吃了一只烤鸭,小明说我刚刚吃饱了,吃饱了太幸福了。
你的饭量很小,你平时每顿就吃半个馒头的。你听了小明的说法,你也吃一只烤鸭,你肚皮都撑爆了,一张嘴烤鸭都快从嘴中吐出来了。
上面的小例子说明,不同的业务规则\数据量\访问量,对应的调优手段也不同。其实也是有一些通用的调优方法,就从sql的写法上实现的。可以来参考我的博文:点击 oracle调优笔记(揭开传言的面纱)
(4)、PLSQL编程
PLSQL是oracle的高级编程,如果想使用PLSQL编程实现ETL,基本要求和上面第3点sql的要求很相似。另外你要熟悉PLSQL语法,并能排除PLSQL运行时产生的Exception。(我做的是ORALCE DBA,对PLSQL编程非常熟悉,所以此处提到PLSQL。大部分数据都有自己编程,只要你熟悉都可以实现ETL)。如果你对plsql编程也感兴趣,可以参考我的博文:点击 史上最简单的数据抽取
(5)、Python
Python是一种编程语言,它里面集成了很多数学函数、工具类,都可以帮我们更加方便的实现ETL操作。如果你要操作的数据源是excel和csv,你就可以使用pandas,太方便了。
四、kettle 使用优化
1、调整 JVM 大小进行性能优化,修改 Kettle 根目录下的 Spoon 脚本
参数参考:
- -Xmx2048m:设置 JVM 最大可用内存为 2048M
- -Xms1024m:设置 JVM 促使内存为 1024M,此值可以设置与 -Xmx 相同,以避免每次垃圾回收完成后 JVM 重新分配内存
- -Xmn2g:设置年轻代大小为 2G,整个 JVM 内存大小=年轻代大小 + 年老代大小 + 持久代大小,持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小,此值对系统性能影响较大,Sun 官方推荐配置为整个堆的 3/8
- -Xss128k:设置每个线程的堆栈大小,JDK5.0 以后每个线程堆栈大小为 1M,以前每个线程堆栈大小为 256K,更具应用的线程所需内存大小进行调整,在相同物理内存下,减小这个值能生成更多的线程,但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在 3000~5000 左右
2、 调整提交(Commit)记录数大小进行优化,Kettle 默认 Commit 数量为:1000,可以根据数据量大小来设置Commitsize:1000~50000
3、尽量使用数据库连接池
4、尽量提高批处理的 commit size
5、尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流)
6、Kettle 是 Java 做的,尽量用大一点的内存参数启动 Kettle
7、可以使用 SQL 来做的一些操作尽量用 SQL
8、插入大量数据的时候尽量把索引删掉
9、尽量避免使用 update、delete 操作,尤其是 update,如果可以把 update 变成先 delete, 后 insert
10、能使用 truncate table 的时候,就不要使用 deleteall row 这种类似 sql 合理的分区,如果删除操作是基于某一个分区的,就不要使用 delete row 这种方式(不管是 deletesql 还是 delete 步骤),直接把分区 drop 掉,再重新创建
11、尽量缩小输入的数据集的大小(增量更新也是为了这个目的)
12、尽量使用数据库原生的方式装载文本文件(Oracle 的 sqlloader, mysql 的 bulk loader 步骤)
相关文章
- 使用kettle实现多表同步并部署到Linux(centos7) kettle 学习入门篇
- kettle 简介
- Kettle 入门
- kettle-manager
- kettle学习笔记及最佳实践
- kettle自动化的那些事儿