超越YOLOv5的PP-YOLOv2和1.3M超轻量PP-YOLO Tiny都来了!(附源码)
计算机视觉研究院专栏
作者:Edison_G
mAP 50.3%,106.5FPS 的 PP-YOLOv2,1.3M超轻量PPYOLO Tiny, 让目标检测界再起风波。

长按扫描二维码关注我们
转自“机器之心”
单阶段目标检测界的扛把子 --YOLO,以其 「又快又好的效果」 在学术及产业界全面风靡。自 20 年下半年 YOLOv4、YOLOv5、PP-YOLO、YOLO-Fastest 和 YOLOv4 Tiny 等等轮番轰炸、掀起 「YOLO 狂潮」 后,时隔半年,超越 YOLOv5 的 PP-YOLOv2 和 1.3M 超超超轻量级的 PP-YOLO tiny 一起来了!!!
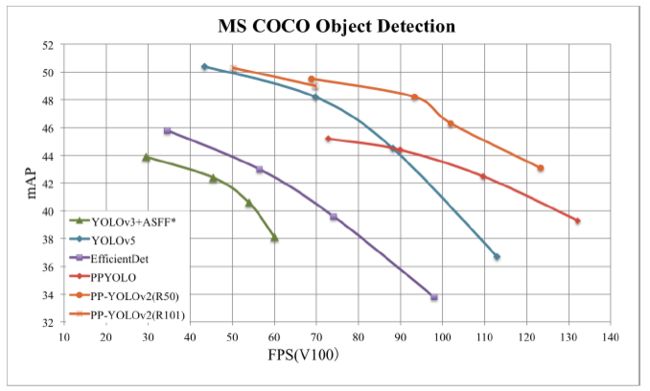
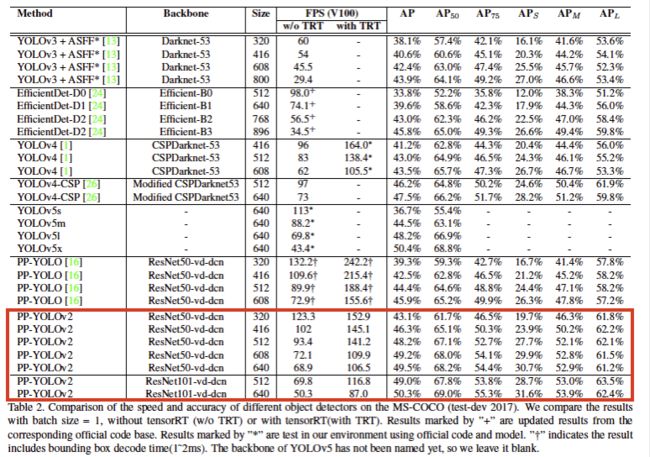
图 1:PP-YOLOv2 和其他目标检测器性能对比
如图 1 可见,PP-YOLOv2 在同等速度下,精度超越 YOLOv5!相较 20 年发布的 PP-YOLO,v2 版本在 COCO 2017 test-dev 上的精度提升了 3.6%,由 45.9% 提升到了 49.5%;在 640*640 的输入尺寸下,FPS 达到 68.9FPS,而采用 TensorRT 加速的话,FPS 更是达到了 106.5!这样的性能,超越了当前所有同等计算量下的检测器,包括 YOLOv4-CSP 和 YOLOv5l !
而如果将骨架网络从 ResNet50 更换为 ResNet101,PP-YOLOv2 的优势则更为显著:mAP 达到 50.3%,速度比同计算量的 YOLOv5x 高出了 15.9%。
不仅如此,与 PP-YOLOv2 一同面世的,还有体积只有 1.3M 的 PP-YOLO Tiny,比 YOLO-Fastest 更轻、更快!这样超超超轻量的算法面世,更是很好的满足了产业里大量边缘、轻量化、低成本芯片上使用目标检测算法的种种诉求!

感兴趣的小伙伴可以直接查看 PP-YOLOv2 论文:https://arxiv.org/abs/2104.10419
并查看 PP-YOLOv2 和 PP-YOLO Tiny 的代码实现:https://github.com/paddlepaddle/paddledetection
(记得 Star 收藏一下,支持开源也防止走丢~)
PP-YOLOv2:产业最实用的目标检测器
关注百度飞桨的小伙伴可能还记得,PP-YOLO(https://arxiv.org/abs/2007.12099)是在 YOLOv3 的基础上,采用了一整套优化策略,在几乎不增加模型参数和计算量(FLOPs)的前提下,提升检测器的精度得到的极高性价比(mAP 45.9,72.9FPS)的单阶段目标检测器。
而 PP-YOLOv2,是以 PP-YOLO 为基线模型进行了一系列的延展实验得到的。下面,就让我们来一起看看具体是哪些策略给 PP-YOLO 带来了进一步的优化提升呢?
1、采用 Path Aggregation Network(路径聚合网络)设计 Detection Net
YOLO 系列的一大通病,是对不同尺幅的目标检测效果欠佳,因此,PP-YOLOv2 第一个优化的尝试是设计一个可以为各种尺度图像构建高层语义特征图的检测颈(detection neck)。不同于 PP-YOLO 采用 FPN 来从下至上的构建特征金字塔,PP-YOLOv2 采用了 FPN 的变形之一—PAN(Path Aggregation Network)来从上至下的聚合特征信息。而采用 PAN 构建的 detection neck 可以由图 2 看到。
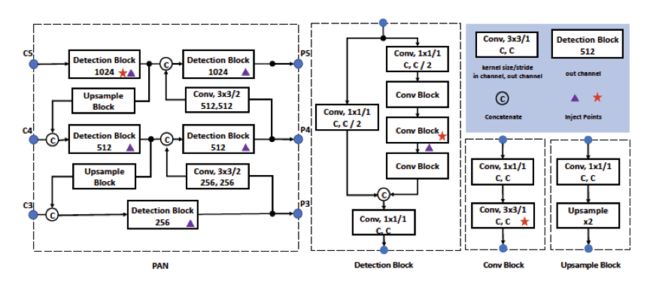
图 2 PP-YOLOv2 Detection Neck 的结构
2、采用 Mish 激活函数
Mish 激活函数被很多实用的检测器采用,并拥有出色的表现,例如 YOLOv4 和 YOLOv5 都在骨架网络(backbone)的构建中应用 mish 激活函数。而对于 PP-YOLOv2,我们倾向于仍然采用原有的骨架网络,因为它的预训练参数使得网络在 ImageNet 上 top-1 准确率高达 82.4%。所以我们把 mish 激活函数应用在了 detection neck 而不是骨架网络上。
3、更大的输入尺寸
增加输入尺寸直接带来了目标面积的扩大。这样,网络可以更容易捕捉到小尺幅目标的信息,得到更高的性能。然而,更大的输入会带来更多的内存占用。所以在使用这个策略的同时,我们需要同时减少 Batch Size。在具体实验中,我们将 Batch Size 减少了一倍,从每个 GPU 24 张图像减少到每个 GPU 12 张图像,并将最大输入从 608 扩展到 768。输入大小均匀地从 [320, 352, 384, 416, 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, 768] 获取。
4、IoU Aware Branch
在 YOLOv3 中,将分类概率和 objectness 相乘作为最终的检测置信度,但却没有考虑定位置信度。为了解决这一问题,我们将 objectness 与定位置信度 IoU 综合起来, 使用下面的公式来计算出一个新的 objectness:
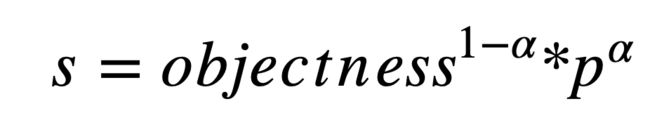
其中 p 为检测框与 ground truth 之间的 IoU 的预测值, 为平衡参数,在 PP-YOLOv2 中设置为 0.5。我们使用 BCE(binary cross entropy) loss 来学习 p,公式如下所示
为平衡参数,在 PP-YOLOv2 中设置为 0.5。我们使用 BCE(binary cross entropy) loss 来学习 p,公式如下所示
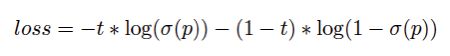
其中 t 为检测框与 ground truth 之间的 IoU,σ(.)代表 sigmoid 激活函数。需要注意的是,只有正性样本的 IoU aware loss 被计算。
而以上这一系列优化策略对网络的改进效果分别是怎样的呢?通过消融实验得到的图表我们可以清晰的看到,以上 PAN、MISH 和输入尺寸的增大都带来了一些计算量的增加,但 mAP 却得到了显著的提升。

而优化后的 PP-YOLOv2 的完整性能测试及与 YOLOv4、YOLOv5 全系列算法的比较如下表,PP-YOLOv2(R50)计算量相当于 YOLOv5l,PP-YOLOv2(R101)计算量相当于 YOLOv5x。可以看到,PP-YOLOv2 的性能超越了当前所有同等计算量下的检测器!
值得注意的是:不管是 PP-YOLO 还是 PP-YOLOv2,都是在寻找在产业实践中最高性价比的目标检测方案,而不是单纯的以提升单阶段目标检测的精度去堆网络和策略。论文中也特别提到,是以实验报告的角度来为业界开发者展示更多网络优化的方法,这些策略也可以被应用在其他网络的优化上,希望在给业界开发者带来更好的网络的同时,也带来更多的算法优化启发。
PPYOLO Tiny:1.3M 超超超轻量 目标检测算法
在当前移动互联网、物联网、车联网等行业迅猛发展的背景下,边缘设备上直接部署目标检测的需求越来越旺盛。生产线上往往需要在极低硬件成本的硬件例如树莓派、FPGA、K210 等芯片上部署目标检测算法。而我们常用的手机 App,也很难直接在终端采用超过 6M 的深度学习算法。
如何在尽量不损失精度的前提下,获得体积更小、运算速度更快的算法呢?
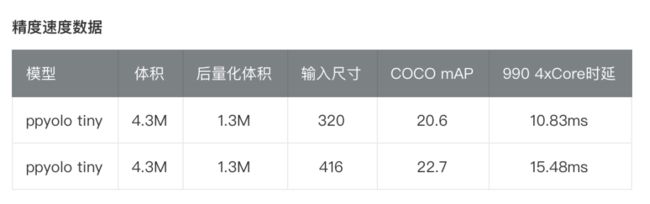
得益于 PaddleSlim 飞桨模型压缩工具的能力,体积仅为 1.3M 的 PPYOLO Tiny 诞生了!
那 PP-YOLO Tiny 具体采用了哪些优化策略呢?
首先,PP-YOLO Tiny 沿用了 PP-YOLO 系列模型的 spp,iou loss, drop block, mixup, sync bn 等优化方法,并进一步采用了近 10 种针对移动端的优化策略:
1、更适用于移动端的骨干网络:
骨干网络可以说是一个模型的核心组成部分,对网络的性能、体积影响巨大。PPYOLO Tiny 采用了移动端高性价比骨干网络 MobileNetV3。
2、更适用移动端的检测头(head):
除了骨干网络,PP-YOLO Tiny 的检测头(head)部分采用了更适用于移动端的深度可分离卷积(Depthwise Separable Convolution),相比常规的卷积操作,有更少的参数量和运算成本, 更适用于移动端的内存空间和算力。
3、去除对模型体积、速度有显著影响的优化策略:
在 PPYOLO 中,采用了近 10 种优化策略,但并不是每一种都适用于移动端轻量化网络,比如 iou aware 和 matrix nms 等。这类 Trick 在服务器端容易计算,但在移动端会引入很多额外的时延,对移动端来说性价比不高,因此去掉反而更适当。
4、使用更小的输入尺寸
为了在移动端有更好的性能,PP-YOLO Tiny 采用 320 和 416 这两种更小的输入图像尺寸。并在 PaddleDetection2.0 中提供 tools/anchor_cluster.py 脚本,使用户可以一键式的获得与目标数据集匹配的 Anchor。例如,在 COCO 数据集上,我们使用 320*320 尺度重新聚类了 anchor,并对应的在训练过程中把每 batch 图⽚的缩放范围调整到 192-512 来适配⼩尺⼨输⼊图片的训练,得到更高性能。
5、召回率优化
在使⽤⼩尺寸输入图片时,对应的目标尺寸也会被缩⼩,漏检的概率会变大,对应的我们采用了如下两种方法来提升目标的召回率:
a.原真实框的注册方法是注册到网格⾥最匹配的 anchor 上,优化后还会同时注册到所有与该真实框的 IoU 不小于 0.25 的 anchor 上,提⾼了真实框注册的正例。
b.原来所有与真实框 IoU 小于 0.7 的 anchor 会被当错负例,优化后将该阈值减小到 0.5,降低了负例比例。
通过以上增加正例、减少负例的方法,弥补了在小尺寸上的正负例倾斜问题,提高了召回率。
6、更大的 batch size
往往更大的 Batch Size 可以使训练更加稳定,获取更优的结果。在 PP-YOLO Tiny 的训练中,单卡 batch size 由 24 提升到了 32,8 卡总 batch size=8*32=256,最终得到在 COCO 数据集上体积 4.3M,精度与预测速度都较为理想的模型。
7、量化后压缩
最后,结合 Paddle Inference 和 Paddle Lite 预测库支持的后量化策略,即在将权重保存成量化后的 int8 数据。这样的操作,是模型体积直接压缩到了 1.3M,而预测时使用 Paddle Lite 加载权重,会将 int8 数据还原回 float32 权重,所以对精度和预测速度⼏乎没有任何影响。
通过以上一系列优化,我们就得到了 1.3M 超超超轻量的 PP-YOLO tiny 模型,而算法可以通过 Paddle Lite 直接部署在麒麟 990 等轻量化芯片上,预测效果也非常理想。
以上所有 PP-YOLOv2 和 PPYOLO Tiny 的代码实现,均在 PaddleDetection 飞桨目标检测开发套件中开源提供:github.com/paddlepaddle/paddledetection
还在等什么?赶紧来实际上手体验一下吧!也欢迎感兴趣的小伙伴参与共建!
![]()
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
源代码|回复“PPYolo”获取源码