shell编程--三剑客之sed
一、基本使用
sed 常用的命令选项
| 命令选项 | 功能描述 |
|---|---|
| -n,-silent | 屏蔽默认输出功能,默认sed会把匹配到的数据显示在屏幕上 |
| -r | 支持扩展正则 |
| -i[SUFFIX] | 直接修改源文件,如果设置了SUFFIX后缀名,sed会将数据备份 |
| -e | 指定需要执行的sed指令,支持使用多个-e参数 |
| -f | 指定需要执行的脚本文件,需要提前将sed指令写入文件中 |
sed 基本操作指令表
| 基本操作指令 | 功能描述 |
|---|---|
| p | 打印当前匹配的数据行 |
| l | 小写L ,打印当前匹配的数据行(显示控制字符,如回车符等) |
| = | 打印当前读取的数据行数 |
| a text | 在匹配的数据行后面插入文本内容 |
| i text | 在匹配的数据行前面插入文本内容 |
| d | 删除匹配的数据行整行内容(删除行) |
| c text | 匹配的数据行整行内容替换为特定的文本内容 |
| f filename | 将文件中读取数据并追加到匹配的数据行后面 |
| w filename | 将前面匹配到的数据写入特定的文件中 |
| q [exit code] | 立刻退出sed脚本 |
| s/regexp/replace/ | 使用正则匹配,将匹配到的数据替换为特定的内容 |
sed 支持的数据定位方法
| 格式 | 功能描述 |
|---|---|
| number | 直接根据行号匹配数据 |
| first-step | 从first行开始,步长step,匹配所有满足条件的数据行 |
| $ | 匹配最后一行 |
| /regexp/ | 使用正则表达式匹配数据行 |
| \cregexpc | 使用正则表达式匹配数据行,c可以使任意字符 |
| addr1,addr2 | 直接使用行号定位,匹配从addr1到addr2的所有的行 |
| addr1,+N | 直接使用行号定位,匹配从addr1开始及后面的N行 |
注:sed 是逐行处理软件,我们可能仅输入了一条sed指令,但系统会将该指令应用在所有匹配的数据行上,因此相同的指令会被反复执行N次,这取决于匹配到的数据有几行。
1)打印案例:p
[root@www ~]# sed 'p' /etc/hosts #<==sed 默认会打印一次,而p又打印了一次,所以直接打印了两次,可以使用-n 参数屏蔽默认输出。
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@www ~]# sed -n 'p' /etc/hosts #<==使用-n参数,屏蔽默认输出
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@www ~]# sed -n '1p' /etc/hosts #<==仅显示文件的第一行
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
[root@www ~]# df -Th | sed -n '2p' #<==sed支持从管道读取数据,仅显示第二行
devtmpfs devtmpfs 475M 0 475M 0% /dev
匹配关键字打印
[root@www ~]# cat -n /etc/passwd > /tmp/passwd #<==生成带有行号的文件
[root@www ~]# sed -n '1,3p' /tmp/passwd #<==打印1到3行
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
[root@www ~]# sed -n '23,$p' /tmp/passwd #<==打印第23行到最后一行
23 nisuser1:x:1001:1001::/home/nisuser1:/bin/bash
24 nisuser2:x:1002:1002::/home/nisuser2:/bin/bash
25 nisuser3:x:1003:1003::/home/nisuser3:/bin/bash
[root@www ~]# sed -n '3,+3p' /tmp/passwd #<==打印第3行以及后面的3行
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
[root@www ~]# sed -n '20~2p' /tmp/passwd #<==打印第20行开始,步长为2的行
20 rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin
22 nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin
24 nisuser2:x:1002:1002::/home/nisuser2:/bin/bash
[root@www ~]# sed -n '$p' /tmp/passwd #<==显示最后一行
25 nisuser3:x:1003:1003::/home/nisuser3:/bin/bash
[root@www ~]# sed -n '/root/p' /tmp/passwd #<==打印有root的行
1 root:x:0:0:root:/root:/bin/bash
10 operator:x:11:0:operator:/root:/sbin/nologin
[root@www ~]# sed -n '/bash$/p' /tmp/passwd #<==寻找bash结尾的行
1 root:x:0:0:root:/root:/bin/bash
23 nisuser1:x:1001:1001::/home/nisuser1:/bin/bash
[root@www ~]# sed -n '/s..:x/p' /tmp/passwd #<==寻找s开头,:x结尾,中间任意三个字符的行
17 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
19 mysql:x:27:27:MySQL Server:/var/lib/mysql:/bin/false
21 rpcuser:x:29:29:RPC Service User:/var/lib/nfs:/sbin/nologin
[root@www ~]# sed -n '/[0-9]/p' /tmp/passwd | head -2 #<==打印有数字的行
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
[root@www ~]# sed -n '/^http/p' /etc/services #<==打印http开头的行
http 80/tcp www www-http # WorldWideWeb HTTP
http 80/udp www www-http # HyperText Transfer Protocol
默认sed不支持扩展正则,需要参数-r来支持扩展正则。
[root@www ~]# sed -n '/^(icmp|igmp)/p' /etc/protocols #<==默认不支持扩展正则
[root@www ~]# sed -rn '/^(icmp|igmp)/p' /etc/protocols #<==开启扩展正则功能
icmp 1 ICMP # internet control message protocol
igmp 2 IGMP # internet group management protocol
[root@www ~]# sed -n '\cbashcp' /etc/shells #<==正则匹配包含bash的行并显示
/bin/bash
/usr/bin/bash
[root@www ~]# sed -n '\xbashxp' /etc/shells #<==正则匹配包含bash的行并显示
/bin/bash
/usr/bin/bash
[root@www ~]# sed -n '\1bash1p' /etc/shells #<==正则匹配包含bash的行并显示
/bin/bash
/usr/bin/bash
[root@www ~]# sed -n '\:bash:p' /etc/shells #<==正则匹配包含bash的行并显示
/bin/bash
/usr/bin/bash
[root@www ~]# sed -n '\,bash,p' /etc/shells #<==正则匹配包含bash的行并显示
/bin/bash
/usr/bin/bash
显示数据内容时打印控制字符。
[root@www ~]# sed -n '\,bash,l' /etc/shells #<==显示数据内容时打印控制字符。
/bin/bash$
/usr/bin/bash$
sed程序使用=指令可以显示行号,结合条件匹配,可以显示特定数据行的行号
[root@www ~]# sed -n '/root/=' /tmp/passwd #<==显示包含root字符串的行号
1
10
[root@www ~]# sed -n '/root/=' /tmp/passwd #<==显示第3行的行号
1
10
[root@www ~]# sed -n '3=' /etc/passwd #<==显示第3行的行号
3
[root@www ~]# sed -n '$=' /etc/passwd #<==显示最后一行的行号
25
[root@www ~]# sed -n '1!p' /etc/hosts #<==除了第1行全部打印
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@www ~]# sed -n '/bash/!p' /etc/shells #<==除含bash外的所有行都显示
/bin/sh
/usr/bin/sh
[root@www ~]#
2)追加:a
[root@www ~]# cp /etc/hosts /tmp/hosts #<==复制素材文件
[root@www ~]# sed '1a aaaaaaaaaa' /tmp/hosts #<==第1行后面添加一行数据
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
aaaaaaaaaa
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@www ~]# sed '/localhost/a hello world' /tmp/hosts #<==匹配到localhost就打印hello world
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
hello world
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
hello world
3)插入:i
[root@www ~]# sed '1i add new line' /tmp/hosts #<==在第一行前面插入一行
add new line
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@www ~]# sed '/localhost/i hello world' /tmp/hosts #<==匹配到localhost之后,就在这一行前面添加hello world。
hello world
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
hello world
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
4)写入文件:-i (选项命令)
[root@www ~]# cp /etc/profile /tmp/ #<==复制文件
[root@www ~]# sed -i '/^$/d' /tmp/profile #<==删除空白行
[root@www ~]# sed -i '/^#/d' /tmp/profile #<==删除#开头的行
[root@www ~]# sed -i '/local/d' /tmp/profile #<==删除local的行
5)整行替换:c
[root@www ~]# sed '2c modify line' /tmp/hosts #<==将第2行替换为新的内容
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
modify line
[root@www ~]# sed '/127/c line' /tmp/hosts #<==将匹配到127的行替换为新的内容
line
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
6)单词替换:s
[root@www ~]# cat test.txt
hello the world.
go spurs go.
123 456 789.
hello the beijing.
I am Jacob
[root@www ~]# sed 's/hello/hi/' test.txt #<==每一行第一个hello替换为hi
hi the world.
go spurs go.
123 456 789.
hi the beijing.
I am Jacob
[root@www ~]# sed '1s/hello/hi/' test.txt #<==第一行第一个hello替换为hi
hi the world.
go spurs go.
123 456 789.
hello the beijing.
I am Jacob
[root@www ~]# sed 's/o/O/' test.txt #<==每行第一个e替换为E
hellO the world.
gO spurs go.
123 456 789.
hellO the beijing.
I am JacOb
[root@www ~]# sed 's/o/O/g' test.txt #<==每行所有的o替换为O(g是全局替换)
hellO the wOrld.
gO spurs gO.
123 456 789.
hellO the beijing.
I am JacOb
[root@www ~]# sed 's/o/O/2' test.txt #<==每行第二个o替换为O
hello the wOrld.
go spurs gO.
123 456 789.
hello the beijing.
I am Jacob
[root@www ~]# sed -n 's/e/E/2p' test.txt #<==仅显示被替换的数据行
hello thE world.
hello thE beijing.
[root@www ~]# sed -n 's/e/E/3p' test.txt
hello the bEijing.
[root@www ~]# sed -n 's/e/E/gp' test.txt
hEllo thE world.
hEllo thE bEijing.
[root@www ~]# sed 's/the//g' test.txt #<==将the替换为空,即删除。
hello world.
go spurs go.
123 456 789.
hello beijing.
I am Jacob
[root@www ~]# sed -r 's/^(.)(.*)(.)$/\3\2\1/' test.txt #<==将每行首尾互换
.ello the worldh
.o spurs gog
.23 456 7891
.ello the beijingh
b am JacoI
[root@www ~]#
[root@www ~]# sed 's#/sbin/nologin#/bin/sh#' /tmp/passwd #<==可以使用其他符号作为替换符。
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/bin/sh
3 daemon:x:2:2:daemon:/sbin:/bin/sh
[root@www ~]# echo '"hello" "world"' | sed 's/\".*\"//'
[root@www ~]# echo '"hello" "world"' | sed 's/\"[^\"]*\"//'
"world"
第一个替换是在匹配双引号开头双引号结尾和中间所有数据,并将其全部删除;而第二个替换仅仅是在匹配由一个引号开始,中间是不包括引号的任意其他字符(长度任意),最后一个引号结束的数据,这样当一行数据中包括多个引号数据时,就可以仅仅匹配最后一个双引号的数据。
在s替换命令的最后添加i标记可以忽略大小写。
[root@www ~]# sed 's/jacob/vicky/i' test.txt #<==在s替换命令的最后添加i标记可以忽略大小写。
hello the world.
go spurs go.
123 456 789.
hello the beijing.
I am vicky
7)读取其他文件内容并写入当前编译的文件:r
下面命令会读取hosts文件的第1行,然后执行一次r指令,接着读取hosts文件的第2行又会执行一次r指令。
[root@www ~]# sed 'r /etc/hostname' /tmp/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
www.centos.vbird
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
www.centos.vbird
[root@www ~]# sed '1r /etc/hostname' /tmp/hosts #<==仅在第一行后面添加主机名
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
www.centos.vbird
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
8)保存:w
[root@www ~]# sed 'w /tmp/myhosts' /tmp/hosts #<==把/tmp/hosts另存为/tmp/myhosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@www ~]# cat /tmp/myhosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@www ~]# sed '1,3w /tmp/myhosts' /etc/shells #<==只保存etc/shells的第1行和第3行
/bin/sh
/bin/bash
/usr/bin/sh
/usr/bin/bash
[root@www ~]# cat /tmp/myhosts
/bin/sh
/bin/bash
/usr/bin/sh
[root@www ~]#
9)退出:q
一般不要再使用类似于3q之类的指令时同时使用-i选项,这样会导致sed使用读取出来的的3行数据,写入并覆盖源文件,从而导致源文件中所有其他数据全部丢失。
[root@www ~]# sed '3q' /etc/shells #<==读取文件第3行时退出sed
/bin/sh
/bin/bash
/usr/bin/sh
10)执行:e
[root@www ~]# echo "/etc/hosts" | sed 's/^/ls -l /e'
-rw-r--r--. 1 root root 230 1月 28 10:10 /etc/hosts
[root@www ~]# echo "tmpfile" | sed 's#^#touch /tmp/#e'
[root@www ~]# ls -l /tmp/tmpfile
-rw-r--r--. 1 root root 0 2月 24 15:29 /tmp/tmpfile
[root@www ~]#
使用s替换命令时如果同时添加了e标记,则表示将替换后的内容当成shell命令在终端执行一次。上面第一条sed命令是将/etc/hosts替换为ls -l /etc/hosts,替换后在命令终端执行ls -l /etc/hosts。
11)一行编写多条命令,可以使用-e 或者 ;分号。
[root@www ~]# sed -n '1p;3p;5p' test.txt #<==显示1、3、5行
hello the world.
123 456 789.
I am Jacob
[root@www ~]# sed -n -e '1p' -e '3p' test.txt #<==显示第1、3行
hello the world.
123 456 789.
[root@www ~]# sed '/world/s/hello/hi/;s/the//' test.txt #<==不使用分组
hi world.
go spurs go.
123 456 789.
hello beijing.
I am Jacob
[root@www ~]# sed '/world/{s/hello/hi/;s/the//}' test.txt #<==使用分组
hi world.
go spurs go.
123 456 789.
hello the beijing.
I am Jacob
不使用分组:每一行都会寻找world,如果在找到了就执行s/hello/hi/,但是不管找不找到,每一行都会执行s/the//
使用分组:每一行都会寻找world,如果找到了就执行{s/hello/hi/;s/the//},找不到就执行下一行。
12)sed 脚本:-f(选项命令)
[root@www ~]# cat test.txt
hello the world.
go spurs go.
123 456 789.
hello the beijing.
I am Jacob
[root@www ~]# sed -f script.sed test.txt #<==使用-f 参数调用指令文件
hello world
go spurs go.
Go spurs go.
Hello the china.
I am Jacob
[root@www ~]# cat script.sed #<==手动编辑指令文件
1c hello world
2{
p
s/g/G/
}
/[0-9]/d
/beijing/{
s/h/H/
s/beijing/china/
}
[root@www ~]#
以上指令的含义:匹配第一-行数据后将整行内容替换为helloworld;匹配第二行数据,先显示该行中的所有数据,再将该行中的第一一个小写字母g替换为大写字母G;使用正则匹配包含数据的行并将该行的所有数据都删除;最后使用正则匹配包含bejjing的行,先将该行中第一个小写字母h替换为大写字母H,然后将该行中的bejing替换为china (仅对包含beijing的行执行两个s替换指令)。
二、高级使用
| 高级操作指令 | 功能描述 |
|---|---|
| h | 将模式空间中的数据复制到保留空间 |
| H | 将模式空间中的数据追加到保留空间 |
| g | 将保留空间中的数据复制到模式空间 |
| G | 将保留空间中的数据追加到模式空间 |
| x | 将模式空间和保留空间中的数据对调 |
| n | 读取下一行数据到模式空间 |
| N | 读取下一行数据追加到模式空间 |
| y/源/目标/ | 以字符为单位将源字符转为目标字符 |
| :label | 为 t 或 b 指令定义 label 标签 |
| t label | 有条件跳转到(label),如果没有 label 则跳转到指令的结尾 |
| b label | 跳转到标签(label),如果没有 label 则跳转到指令的结尾 |
sed在对数据进行编辑修改前需要先将读取的数据写入模式空间中,而sed除了有个用于临时存储数据的模式空间,还设计有一个保留空间,保留空间中默认仅包含有一个回车符。前面我们学习的a、i、d、C、s等指令都仅用到了模式空间,而不会调用保留空间中的数据,仅当我们使用特定的指令时(如h、g、x等)才会用到保留空间中的数据,注意在保留空间中默认包含-一个回车符。模式空间与保留空间的关系如图6-2所示。
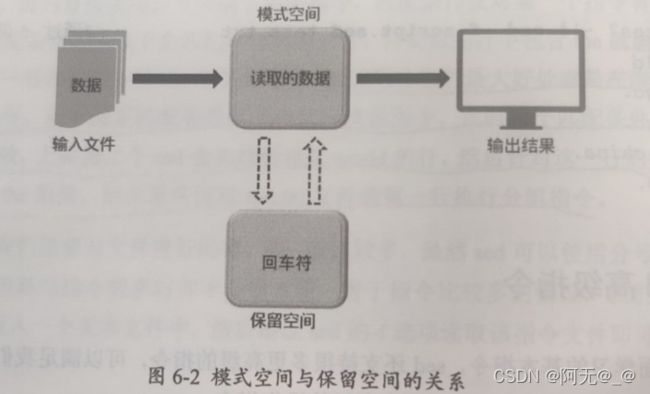
当我们使用h指令时,sed就会把模式空间中的所有内容复制到保留空间,并将保留空间中原有的回车符覆盖,而如果使用的是H指令,则sed会把模式空间中的所有内容追加到保留空间中回车符的后面,保留空间中的回车符不会被覆盖。反向操作时使用g指令,sed就会把保留空间中的所有数据复制到模式空间,此时模式空间中原有的所有数据都将被覆盖。而如果使用的是G指令,则sed就会把保留空间中的所有数据追加到模式空间原有数据的下面,模式空间中原有的数据不会被覆盖。如果需要将模式空间与保留空间中的数据直接交换则可以使用x指令。
注:只有模式模式空间的内容才会打印到屏幕,sed 每读取一行数据默认放到模式空间。
案例一:h g x的案例
[root@www jiaofan]# cat test.txt #<==准备素材
1:hello the world.
2:go spurs go.
3:123 456 789.
4:hello the beijing.
5:I am Jacob.
6:Test hold/pattern space.
当sed读取第二行数据时,会将整行复制到保留空间,打印输出第二行;当sed 读取第五行数据时,会把保留空间的数据(2:go spurs go.)复制到模式空间,所以直接打印的(2:go spurs go.)
[root@www jiaofan]# sed '2h;5g' test.txt
1:hello the world.
2:go spurs go.
3:123 456 789.
4:hello the beijing.
2:go spurs go.
6:Test hold/pattern space.
当sed读取第五行数据时,会把把保留空间的数据(2:go spurs go.)追加到模式空间,所以打印了两行数据
[root@www jiaofan]# sed '2h;5G' test.txt
1:hello the world.
2:go spurs go.
3:123 456 789.
4:hello the beijing.
5:I am Jacob.
2:go spurs go.
6:Test hold/pattern space.
下面这个案例为什么会打印空行?这是因为H是追加到保留空间,保留空间默认是有换行符的,因为是追加到保留空间,所以并没有覆盖原有的换行符。保留空间的内容是(\n2:go spurs go.$)
[root@www jiaofan]# sed '2H;5G' test.txt
1:hello the world.
2:go spurs go.
3:123 456 789.
4:hello the beijing.
5:I am Jacob.
2:go spurs go.
6:Test hold/pattern space.
[root@www jiaofan]#
这个案例会把符号打印出来,
[root@www jiaofan]# sed -n '2{N;l}' test.txt
2:go spurs go.\n3:123 456 789.$
[root@www jiaofan]# sed -n '2{N;p}' test.txt
2:go spurs go.
3:123 456 789.
[root@www jiaofan]# sed '2H;5g' test.txt
1:hello the world.
2:go spurs go.
3:123 456 789.
4:hello the beijing.
2:go spurs go.
6:Test hold/pattern space.
[root@www jiaofan]#
[root@www jiaofan]# sed '1h;4x' test.txt
1:hello the world.
2:go spurs go.
3:123 456 789.
1:hello the world.
5:I am Jacob.
6:Test hold/pattern space.
[root@www jiaofan]# sed '1h;2H;4x' test.txt
1:hello the world.
2:go spurs go.
3:123 456 789.
1:hello the world.
2:go spurs go.
5:I am Jacob.
6:Test hold/pattern space.
[root@www jiaofan]#
删除偶数行
[root@www jiaofan]# sed 'N;s/\n//' test.txt
1:hello the world.2:go spurs go.
3:123 456 789.4:hello the beijing.
5:I am Jacob.6:Test hold/pattern space.
案例二:替换符y///
[root@www jiaofan]# sed 'y/hg/HG/' test.txt #<==h替换为H,g替换为G
1:Hello tHe world.
2:Go spurs Go.
3:123 456 789.
4:Hello tHe beijinG.
5:I am Jacob.
6:Test Hold/pattern space.
[root@www jiaofan]# sed 'y/hg/21/' test.txt #<==h替换为2,g替换为1
1:2ello t2e world.
2:1o spurs 1o.
3:123 456 789.
4:2ello t2e beijin1.
5:I am Jacob.
6:Test 2old/pattern space.
[root@www jiaofan]# sed 'y/abcdefghijklmnopqrstuvwxyz/ABCDEFGHIJKLMNOPQRSTUVWXYZ/' test.txt #<==小写字母替换为大写字母
1:HELLO THE WORLD.
2:GO SPURS GO.
3:123 456 789.
4:HELLO THE BEIJING.
5:I AM JACOB.
6:TEST HOLD/PATTERN SPACE.
[root@www jiaofan]#
案例三:标签
当有多个sed指令时默认会按顺序依次执行,如果我们需要打破这种限制,让多个指令按照我们希望的顺序执行,则可以使用sed提供的标签功能,定义标签后可以使用分支(branch)或者测试(test) 控制sed指令回到特定的标签位置。
首先我们需要明确定义标签需要使用冒号开始,后面跟任意标签字符串(标签名称),冒号与标签字符串之间不能有空格,而如果字符串最后有空格,则空格也被理解为标签名称的一部分。
有了标签,我们就可以通过b或者t指令跳转至标签的位置,如果b或者t指令跳转的目标标签不存在,则sed直接跳转至命令结束位置。区别是b为无条件跳转,t为有条件跳转。t需要根据前面的s替换指令的结果决定是否跳转。需要注意的是,这里的跳转只影响sed指令的执行顺序,对输入的数据行没有影响。
Branch 无条件跳转,基本语法格式如下。
:label
sed 指令序列
... ...
b label
test 有条件跳转,基本格式如下。
:label
sed 指令序列
... ...
s/regex/replace/
t label
[root@www jiaofan]# sed -n ':top;=;p;4b top' test.txt | head -14
1
1:hello the world.
2
2:go spurs go.
3
3:123 456 789.
4
4:hello the beijing.
4
4:hello the beijing.
4
4:hello the beijing.
4
4:hello the beijing.
上面这条命令在打印行号(=)和打印当前行数据内容§ 之前定义了一个名称为top的标签,并在读取文件第4行数据时将sed指令跳转至top,循环执行=和p指令.针对tstxtt文件指令的执行流程如下。
(1)读取文件的第1行数据,定义名称为top的标签,执行=和p指令,屏幕输出行号1和第1行的数据内容" 1:hello the world.",因为第1行的行号不等于4,所以此时不会执行b跳转指令。
(2)接着读取文件的第2行数据,与第1行的情况相同,屏幕输出行号2和第2行的数据内容"2:go spurs go."。
(3)接着读取文件的第3行数据,与第1行的情况依然相同,屏幕输出行号3以及第三行的数据内容"3:123 456 789."。
(4)再读取文件的第4行数据,与前面类似的情况是,依然会按顺序执行和p指令,屏幕显示行号4和该行的数据内容"4:hello the beiing.",但不同的是,第4行的行号与b指令前面的行号条件匹配,因此在这里就会执行b跳转指令,将指令跳转至top,等于做了一次循环。回到top后,再按顺序执行=和p指令,因为跳转影响的仅仅是指令的执行顺序,不会导致数据行的跳转变化,所以当前行始终都是第4行,4b的条件匹配始终满足,b指令会反复跳转至top导致死循环。
[root@www jiaofan]# sed '/beijing/b end;s/\./!/;:end' test.txt
1:hello the world!
2:go spurs go!
3:123 456 789!
4:hello the beijing.
5:I am Jacob!
6:Test hold/pattern space!
案例三:多行合并一行
[root@www jiaofan]# cat contace.txt
phone:
1397949283
mail:
[email protected]
pheone:
13683943
mail:
dj;hfidhgiei
[root@www jiaofan]# sed -r 'N;s/\n//;s/: +/: /' contace.txt
phone: 1397949283
mail: [email protected]
pheone: 13683943
mail: dj;hfidhgiei
[root@www jiaofan]#
案例四:多行合并一行
[root@www jiaofan]# cat contace.txt
phone:
1397949283
mail:[email protected]
pheone:13683943
mail:
dj;hfidhgiei
[root@www jiaofan]# sed -r ':start;/:$/N;s/\n +//;t start' contace.txt
phone:1397949283
mail:[email protected]
pheone:13683943
mail:dj;hfidhgiei
与branch无条件跳转有所不同,test是一种有 条件的跳转,使用时必须和:替换操作配合使用。当s替换操作成功时则执行test跳转,如果跳转的目标标签不存在,则跳转到指令的结束位置,反之,如果s替换操作不成功,则不执行test跳转操作。
上面这 条命令在开始执行任何sed 指令前先定义了-一个名称为start 的标签,然后条件匹配以冒号(: )结尾的行,找到满足条件的行后执行N指令读取下一行数据到模式空间,接着使用s替换指令将\n (换行符)以及后面的若干空格都替换为空(即删除操作),最后test有条件跳转,如果前面的s替换操作成功则执行t跳转指令,否则不执行t跳转指令。针对contact.txt数据文件其执行流程如下。
(1)读取文件的第1行,定义名称为start的标签,该行数据是以冒号结尾的,与/:S/匹配成功,因此会执行N指令将下一-行数据追加读入模式空间。模式空间中的数据为第1行的数据和第2行数据,两行数据之间有一个换行符(n)。接着使用s指令对模式空间中的两行数据进行替换操作,将换行符及若干个空格替换为空(将两行合并为- -行)。注意在+前面有一个空格,+在正则表达式中表示前面的字符出现了至少一次。 s替换指令执行成功就会导致test跳转,将指令跳转至start位置,再次拿模式空间中的数据(两行合并为一行后的数据)与//匹配, 因为合并后以9结尾,所以匹配失败。匹配失败就不会再执行N指令读取下一行数据,因为合并时已经将换行符和空格删除,所以也无法再次执行s替换操作,最终也不会再次执行test跳转,到此所有sed指令执行结束。
(2) 所有sed指令都执行完毕后,sed 自动逐行读取下一-行数据(此时读取的下一 行已经是第3行数据了),miltets@test com不以冒号结尾,因此不会再执行N指令读取下一行数据。 没有执行N指令就不会有多行数据,也没有n换行符,S替换指令也不会被触发执行,因此test 跳转也不会被执行,到此所有sed指令执行结束。
(3)所有sed指令都执行完毕后,sed 自动逐行读取下一行数据(此时读取的下一行已经是第4行数据了),ple3134357678不以冒号结尾,因此不会再执行N指令读取下一行数据,没有执行N指令就不会有多行数据,也没有n换行符,s替换指令也不会被触发执行,因此test跳转也不会被执行,到此所有sed指令执行结束。
(4)所有sed指令都执行完毕后,sed 自动逐行读取下一行数据 (此时读取的下一行已经是第5行数据了),mail:确实以冒号结尾,因此会触发执行N指令将下一-行数据(也就是第6行数据)追加读入模式空间,模式空间中的数据为第5行的数据和第6行的数据,两行数据指令有一个换行符(n),接着使用s指令对模式空间中的两行数据进行替换操作,将换行符及若干个空格替换为空(将两行合并为一行),S替换指令执行成功就会导致test跳转,将指令跳转至start 位置,再次拿模式空间中的数据(两行合并为一行后的数据)与/:/匹配,因为合并后以m结尾,所以匹配失败,匹配失败就不会再执行N指令读取下一行数据,因为合并时已经将换行符和空格删除,所以也无法再次执行s替换操作,最终也不会再次执行test跳转,到此所有sed指令执行结束,所有contact.txt文件的数据也都读取完毕,sed程序退出。
案例五:
[root@www jiaofan]# echo fe:32:32:8f:24:87 | sed 's/://g'
fe32328f2487
[root@www jiaofan]# echo fe32328f2487 | sed -r 's/([^:])([0-9a-f]{2})/\1:\2/'
f:e32328f2487
[root@www jiaofan]# echo fe32328f2487 | sed -r 's/([^:]*)([0-9a-f]{2})/\1:\2/'
fe32328f24:87
[root@www jiaofan]# echo fe32328f2487 | sed -r ':loop;s/([^:]+)([0-9a-f]{2})/\1:\2/;t loop'
fe:32:32:8f:24:87
[root@www jiaofan]#