Yolo v3论文精读
-
论文结构
-
一、主干网络-DarkNet-53(backbone)
-
二、特征金字塔-FPN(neck)
-
三、对feature map进行预测(Head)
-
四、先验框
-
五、训练策略
-
六、损失函数
-
七、实验结果分析
-
总结
论文结构

一、主干网络-DarkNet-53(backbone)

例如,输入的图片是256x256x3,经过一次卷积核为3x3的卷积后,shape变为256x256x32;再经过一次残差网络shape变为128x128x64,再经过两次残差网络shape变为64x64x128,再经过8次残差网络shape变为32x32x256,再经过8次残差网络shape变为16x16x512,再经过4次残差网络shape变为8x8x1024。

Darknet-53处理速度每秒78张图片,比Darknet-19慢不少,但是比同精度的ResNet快很多。Darknet-53在精度上略优于Darknet-19和ResNet。Yolov3依然保持了高性能,做到了速度和精度之间的平衡,综合考虑选择了Darknet-53作为主干网络。
Darknet-53的特点:借鉴ResNet:将输入的特征图与输出的特征图对应维度相加。
二、特征金字塔-FPN(neck)

Darknet-53的的三个特征层分别用于提取大物体,中型物体,和小物体的特征。首先对最底层8x8x1024的特征层进行5次卷积操作(8x8x512),再经过一次3x3的卷积和1x1的卷积获得小尺度的feature map(8x8x255)。对5次卷积操作后的特征层进行上采样和次底层16x16x512的特征层进行堆叠(16x16x768),然后再进行5次卷积操作(16x16x256),再经过一次3x3的卷积和1x1的卷积获得中尺度的feature map(16x16x255)。对5次卷积操作后的特征层进行上采样和中层32x32x256的特征层进行堆叠(32x32x384),再进行5次卷积操作和一次1x1和3x3的卷积后得到大尺度的feature map(32x32x255)。
Yolo Head本质上是一次3x3卷积加上一次1x1卷积,3x3卷积的作用是特征整合,1x1卷积的作用是调整通道数。
特征金字塔FPN可以将不同尺度的特征层进行特征融合,有利于取出更好的特征。
特征金字塔-FPN的特点:借鉴DsenseNet将特征图通道维度直接拼接。
三、对feature map进行预测(Head)

输入不同尺寸大小的图片会生成不同大小的特征图。特征图的每个像素点中,都会配置3个不同的先验框,所以最后三个特征图reshape为8x8x3x85,16x16x3x85,32x32x3x85,85代表检测框位置包括x偏移量,y偏移量,w,h(4维)、检测置信度(1维)、类别(80维)。
四、先验框
Yolov3沿用了Yolov2中关于先验框的技巧,并且使用k-means对数据集中的标签框进行聚类,得到类别中心点的9个框作为先验框。有了先验框与输出特征图,就可以解码检测框x,y,w,h。
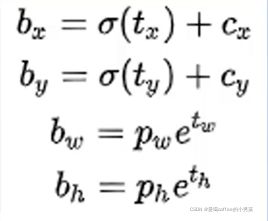
置信度在输出85维中占固定一维,由sigmoid函数解码可得,解码之后的数值在[0,1]中。
85维中有80维维类别数,每一维独立代表一个类别的置信度,使用sigmoid激活函数代替了Yolov2中的softmax,取消了类别之间的排斥,可以使网络更加灵活。
三个特征图一共可以解码出8x8x3+16x16x3+32x32x3=4032个先验框,训练时4032个先验框全面送入打标签函数,然后计算损失函数,再进行反向传播。在推理时,选择一个置信度阈值,过滤掉低置信度的先验框,再通过非极大值抑制NMS,就可以输出网络预测结果了。
五、训练策略
预测框:正例(positive)、负例(negative)、忽略样例(ignore)
先验框的数量:416输入:10647个
256输入:4032个
正例:取一个ground truth,与4032个框全部计算iou,最大的维为正例。正例产生置信度loss,检测框loss,类别loss。
负例:与全部ground truth的iou都小于阈值(0.5),则为负例。负例只有分类置信度的loss,检测框loss和类别loss都为0。
忽略样本:除了正例意外,与ground truth的iou大于阈值则为忽略样本。忽略样本不产生任何loss。
六、损失函数
x,y,w,h使用MSE作为损失函数,也可以使用smooth L1loss

七、实验结果分析

总结
创新点:结合检测与识别技术于一体,3个尺度的特征图,置信度和类别解码
不足:对于小目标的检 测精度较低。
总结:YoLov3比之前的版本更大但更精确,和SSD一样精确但是比SSD快3倍,用 Titan X时实现57.9AP,用时51ms,比RetinaNet快3.8倍。