基于深度学习的视觉三维重建研究总结2进阶
What Is Single-view 3D Object Reconstruction ?
摘要
随着人工智能,计算机视觉和图像处理的发展,三维重建在机器人,自动驾驶,虚拟现实和增强现实的需求日益增加。在三维重建中最重要的就是几何结构,如何有效的重建三维物体的几何结构是三维重建的关键问题。目前大部分工作通过2D图像重建3D物体,图像重建3D物体又划分为单视图与多视图。在单视图中,如何正确的估计物体深度信息,物体遮挡部分重建,重建拓扑结构复杂的物体和模型的泛化能力是充满挑战性的问题。现有的方法通过从2D估计2.5D深度信息以及抽取物体骨架来解决泛化问题,通过大量学习物体结构获得的先验信息来解决遮挡部分重建问题。最近,大量工作开始关注3D重建占用内存与训练时间问题,通过将三维曲面表示为深度神经网络二分类器的连续决策边界来优化内存占用。
1.概论
单视图三维理解:单视图三维理解是一个复杂的任务,需要从几何和语义两方面对视觉数据进行解释。事实上,这两种模式并不是完全脱节的,而是从单纯的几何重构到单纯的语义识别的一个跨越。
三维重建:三维重建意味着对输入图像中显示的对象的三维结构进行逐像素推理,这可以通过使用颜色、纹理、阴影、视角、阴影和散焦等低级图像线索来实现。此模式不需要对图像内容进行语义理解。
三维识别:识别是使用语义先验的一个极端例子:它在整个图片的高级语义信息上操作,相当于对输入图像中的对象进行分类,并从数据库中检索对应的三维形状,同时它为关于对象的不可见部分的推理提供了一个鲁棒的先验,但是这种纯粹的语义解决方案只有在新对象可以在数据库中的检索到的情况下才有效。
由于三维重建和三维识别代表了3D范围的两个相反的端点,仅依靠其中之一是不可能产生最准确的三维形状,因为两者都忽略了输入图像中存在的有价值的信息。因此,通常假设,一个成功的单视图三维重建方法需要结合低层图像线索、结构信息和高层对象语义信息[27]。
近年来,基于学习的三维重建方法得到了广泛的应用,与传统的多视图立体视觉算法相比,学习模型能够对空间的丰富先验信息进行编码以防止输入的歧义。虽然生成模型最近在生成现实的高分辨率图片方面取得了引人注目的成功[28],但是在三维领域没有被成功实现。相比较于二维领域,三维领域至今还没有公认的能够有效的利用内存和对数剧有效推断的三维输出表示形式。现存的表示方法可以分为三种:体素,点云和网格,见 图1。

2. 相关工作与技术
(1)彩色图像与深度图像:彩色图像也叫作RGB图像,R、G、B三个分量对应于红、绿、蓝三个通道的颜色,它们的叠加组成了图像像素的不同灰度级。RGB颜色空间是构成多彩现实世界的基础。深度图像又被称为距离图像,与灰度图像中像素点存储亮度值不同,其像素点存储的是该点到相机的距离,即深度值。深度值指的目标物体与测量器材之间的距离。由于深度值的大小只与距离有关,而与环境、光线、方向等因素无关,所以深度图像能够真实准确的体现景物的几何深度信息。通过建立物体的空间模型,能够为深层次的计算机视觉应用提供更坚实的基础。
(2)早期的3D物体重建是通过 shape-from-shading 重建物体形状 [1,2,3]。在早期方法下,纹理[4]和散焦[5]信息提供了更多有意义的重建信息,这些方法只能对使用单一深度线索的物体的可见表面进行深度信息推理,更普遍的方法是利用多重线索和整体结构信息对单目图像可见表面进行深度估计。Saxena et al. [6] 通过在单幅图像的全局和局部特征训练一个马尔科夫随机场来估计深度信息。 Oswald et al.[7]使用交互式用户输入解决了相同的问题。Hoiem et al.[8]通过从一张图像中识别简单的几何假设来构建三维模型。Karsch et al [9]提出了一个非参数框架,该框架通过识别部分级别和对象级别的来从图像和相应深度映射的数据库中收集估计值。最近,利用卷积网络进行单目深度估计取得了重大进展 [10, 11, 12]。
我们关注的方法不仅可以推理3D物体可见部分的结构信息,而且可以使用从数据中获得的先验信息来推理不可见部分。 Tulsiani et al. [13] 使用特定对象类别的可变形模型来处理此任务。最近的大多数方法利用3D监督信息训练卷积神经网络将2D图像直接映射到3D形状。基于体素的表示方式使用3D卷积神经网络将潜在向量直接生成3D形状 [13, 14]。一些研究[13,38,46]对输出空间进行了层级划分实现了高效的计算和存储,为高分辨率体素的三维形状的重建提供了可能。Groueix et al. [15] 使用小块面片来拼接3D物体表面。 Wu et al. [16]以全监督的方式学习从输入图像到2.5D草图的映射,然后训练一个网络将这些中间表示映射到最终的3D形状。
最近,使用较弱监督训练的卷积神经网络来进行单视图3D形状预测已经成为一种趋势。多种方法[17,18]通过比较标签和预测的投影来训练形状回归网络。
由于单幅图像三维重建的数据集非常少。大多数现有的方法使用ShapeNet[1]的子集进行训练和测试。Pix3D数据集[44]提供了一对完美对齐的自然图像和CAD模型。然而,此数据集包含的三维样本数目很低,不能作为数据集来训练深度网络。
表示形式: 现有的基于学习的三维重建工作可以大致分为基于体素、基于点云或基于网格的输出表示形式。
基于体素的表示形式: 由于体素的简单性,对于识别[19,20]和生成式的3D任务[14,21]体素是最常用的表示形式。早期的工作[21]已经考虑到了使用3D卷积神经网络直接从单张图片重建三维几何,然而由于内存的限制这些方法被限制在了 32 3 {32}^3 323的体素网格内。虽然近期工作[16,22]将体素网格分辨率提升到了 128 3 {128}^3 1283,但是这只有在浅层网络架构和小批量处理的情况下才有可能,这将导致训练过程十分缓慢。
基于点云的表示形式:三维几何另一种表示形式就是点云,点云在机器人和计算机图形领域得到了广泛的应用。 Qi et al. [23]首先在深度学习任务中使用了点云作为表示形式,并且通过使用全连接网络处理每一个点云以及使用全局池化来保持排列不变性。
基于表格的表示形式:网格是第一个被考虑通过在网格点和边所张成的图进行卷积用于3D分类与分割任务中。最近,网格也被认为是三维重建的输出表示[24]。不幸的是,这些方法大多容易产生自交网格。此外,它们只能生成拓扑简单的网格[25],并且需要来自相同对象类的模板[25],或者不能保证封闭曲面[24]。Liao et al.提出了移动立方体算法[44]的端到端的可学习版本。然而这种方法局限于潜在的三维网格的内存需要,因此这种方法也只能局限于 32 3 {32}^3 323的体素分辨率。
最近,Mescheder, Lars, et al.[26]实现了没有自交的高分辨率网络封闭曲面,并且不需要相同类的模板,与早期使用这种输出表示的工作[4]相比,OGN允许通过使用八叉树来有效地表示八叉空间来预测更高分辨率的形状。
3.现有方法
(1) Octree Generating Networks (OGN)[29] 作为直接在体素网格上预测输出的典型方法,与早期使用这种输出表示的工作[13]相比,OGN允许通过使用八叉树来有效地表示八叉空间来预测更高分辨率的形状。
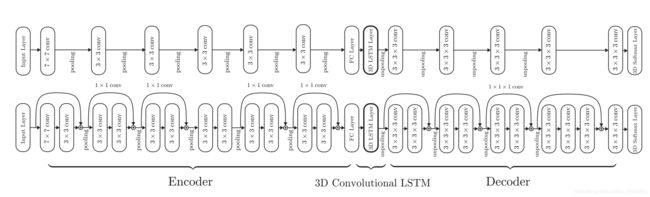
(2)3D-R2N2[13]:借鉴了LSTM和GRU的思想,构建一个3D Recurrent Reconstruction Neural Network (3D-R2N2)。整个网络分为3个部分,2D-Encoder部分,3D-LSTM部分,3D-Decoder部分。其中2D-Encoder部分输入为图片,可以是单视图或者多视图,输出为feature,为常见2维图片卷积网络。3D-LSTM为中间部分,主要是为decoder部分提供输入,将二维特征转换为三维特征。评价指标为输出和真实值的误差以及交并比(IoU):IOU越高越好
(3)从单视图RGB图像中恢复三维结构,MarrNet[16]包含三个部分:首先,一个2.5D的sketch 估计结构,它可以预测对象的深度、表面法线和轮廓图像(图a);第二,三维形状估计器,使用体素表示来推断三维物体形状(图b);第三,重投影一致性函数,加强估计的3D结构和推断的2.5D草图之间的对齐(图c)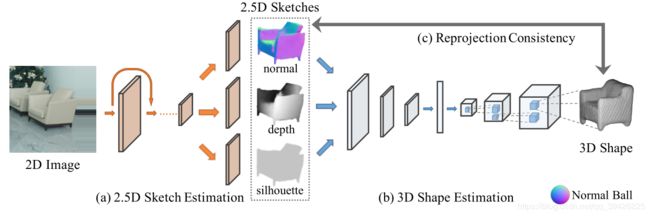
(4)AtlasNet[15]预测了参数曲面的集合,并在操作这种输出表示的方法中达到了最优。AtlasNet提高了精度和泛化能力,并且可以生成任意分辨率的形状,而不存在内存问题,并在shapeNet数据集上取得了很好的效果。

(5) Matryoshka networks[31]使用由多个嵌套深度映射组成的形状表示,这些深度映射在体积上融合成一个单一的输出对象。

(6)Occupany Networks[26]实现了隐式地将三维曲面表示为深度神经网络分类器的连续决策边界。
4.评价标准
(1)交并比: 在三维重建的背景下,G,R表示二分类的占用图
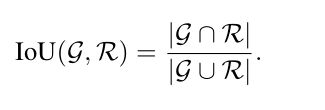
(2)倒角距离:定义真实形状G与重构形状R(均表示为点云)之间的倒角距离(CD)为
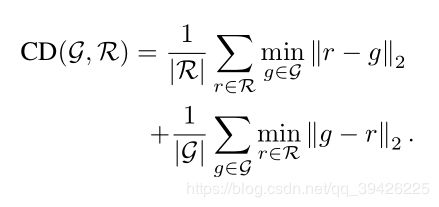

如上图,亮绿色为AtlasNet重建效果( 0.38 IoU),绿色为OGN重建效果( 0.46 IoU),暗绿色为 Matryoshka Networks重建效果
(0.47 IoU)。
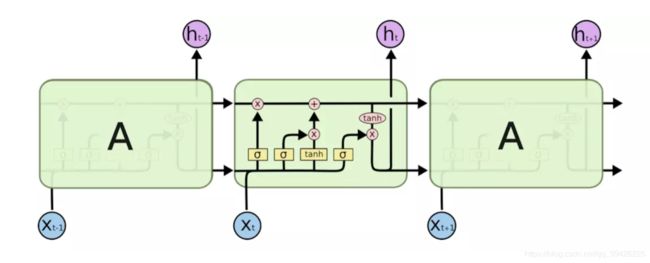
LSTM:
Long Short Term Memory networks(以下简称LSTMs),一种特殊的RNN网络,该网络设计出来是为了解决长依赖问题。该网络由 Hochreiter & Schmidhuber (1997)引入,并有许多人对其进行了改进和普及。他们的工作被用来解决了各种各样的问题,直到目前还被广泛应用。
6.参考文献
[1] Jean-Denis Durou, Maurizio Falcone, and Manuela Sagona.Numerical methods for shape-from-shading: A new survey with benchmarks. CVIU, 109(1):22–43, 2008.
[2] Berthold K.P. Horn. Shape from Shading: A Method for Obtaining the Shape of a Smooth Opaque Object [3] from One View. PhD thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1970. 2 Ruo Zhang, Ping sing Tsai, James Edwin Cryer, andMubarak Shah. Shape from shading: A survey. TPAMI, 21:690–706, 1999.
[4] Angeline M. Loh. The recovery of 3D structure using visualtexturepatterns. PhD thesis,University of WesternAustralia,2006.
[5] P. Favaro and S. Soatto. A geometric approach to shape from defocus. TPAMI, 27(3):406–417, 2005
[6] Ashutosh Saxena, Sung H. Chung, and Andrew Y. Ng.Learning depth from single monocular images. In NIPS,2005.
[7] Martin R. Oswald, Eno Töppe, and Daniel Cremers. Fastand globally optimal single view reconstruction of curved objects. In CVPR, 2012.
[8] Derek Hoiem, Alexei A. Efros, and Martial Hebert. Auto-matic photo pop-up. ACM Trans.Graph.,24(3):577–584,2005.
[9] Kevin Karsch, Ce Liu, and Sing Bing Kang. Depth transfer:Depth extraction from video using non-parametric sampling.TPAMI, 36(11):2144–2158, 2014.
[10] Weifeng Chen, Zhao Fu, Dawei Yang, and Jia Deng. Single-image depth perception in the wild. In NIPS, 2016.
[11] Clément Godard, Oisin Mac Aodha, and Gabriel J. Bros-tow. Unsupervised monocular depth estimation with left-right consistency. In CVPR, 2017.
[12] Zhengqi Li and Noah Snavely. MegaDepth: Learning single-view depth prediction from internet photos. In CVPR, 2018.
[13] Shubham Tulsiani, Abhishek Kar, Jo˜ ao Carreira, and Jitendra Malik. Learning category-specific deformable 3D models for object reconstruction. TPAMI, 39(4):719–731, 2016.
[13] Christopher Bongsoo Choy, Danfei Xu, JunYoung Gwak,Kevin Chen, and Silvio Savarese. 3D-R2N2: A unified approach for single and multi-view 3D object reconstruction.In ECCV, 2016
[14] Jiajun Wu, Chengkai Zhang, Tianfan Xue, William T Freeman, and Joshua B Tenenbaum. Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. In NIPS, 2016
[15] Thibault Groueix, Matthew Fisher, Vladimir G. Kim, Bryan Russell, and Mathieu Aubry. AtlasNet: A papier-mâché approach to learning 3D surface generation. In CVPR, 2018.
[16] Jiajun Wu, Yifan Wang, Tianfan Xue, Xingyuan Sun,William T Freeman, and Joshua B Tenenbaum. MarrNet:3D Shape Reconstruction via 2.5D Sketches. In NIPS, 2017
[17] Xinchen Yan, Jimei Yang, Ersin Yumer, Yijie Guo, and Honglak Lee. Perspective transformer nets: Learning single-view 3D object reconstruction without 3D supervision. In NIPS, 2016
[18] Rui Zhu, Hamed Kiani Galoogahi, Chaoyang Wang, and Simon Lucey. Rethinking reprojection: Closing the loop for pose-aware shape reconstruction from a single image. In ICCV, 2017
[19] C. R. Qi, H. Su, M. Nießner, A. Dai, M. Yan, and L. Guibas.Volumetric and multi-view CNNs for object classification on 3D data. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2016
[20] S. Song and J. Xiao. Deep sliding shapes for amodal 3D object detection in RGB-D images. In Proc. IEEE Conf on Computer Vision and Pattern Recognition (CVPR), June 2016.
[21] S. Song and J. Xiao. Deep sliding shapes for amodal 3D object detection in RGB-D images. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), June 2016.
[22] J. Wu, C. Zhang, X. Zhang, Z. Zhang, W. T. Freeman, and J. B. Tenenbaum. Learning shape priors for single-view 3D completion and reconstruction. In Proc. of the European Conf. on Computer Vision (ECCV), 2018.
[23] C. R. Qi, L. Yi, H. Su, and L. J. Guibas. PointNet++:Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Processing Systems (NIPS), 2017.
[24] T. Groueix, M. Fisher, V. G. Kim, B. Russell, and M. Aubry.AtlasNet: A papier-mâché approach to learning 3d surface
generation. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2018
[25] N. Wang, Y. Zhang, Z. Li, Y. Fu, W. Liu, and Y.-G. Jiang.Pixel2Mesh: Generating 3D mesh models from single RGB images. In Proc. of the European Conf. on Computer Vision (ECCV), 2018.
[26] Mescheder, Lars, et al. “Occupancy networks: Learning 3d reconstruction in function space.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[27] Ashutosh Saxena, Min Sun, and Andrew Y. Ng. Learning 3D scene structure from a single still image. In ICCV, 2007
[28] T. Karras, T. Aila, S. Laine, and J. Lehtinen. Progressive growing of GANs for improved quality, stability, and variation. In Proc. of the International Conf. on Learning Representations (ICLR), 2018
[29] Maxim Tatarchenko, Alexey Dosovitskiy, and Thomas Brox.Octree generating networks: Efficient convolutional architectures for high-resolution 3D outputs. In ICCV, 2017
[30] Christopher Bongsoo Choy, Danfei Xu, JunYoung Gwak,Kevin Chen, and Silvio Savarese. 3D-R2N2: A unified approach for single and multi-view 3D object reconstruction.In ECCV, 2016.
[31] Stephan R. Richter and Stefan Roth. Matryoshka networks:Predicting 3D geometry via nested shape layers. In CVPR,2018.