动手学深度学习PyTorch版--Task4、5--机器翻译及相关技术;注意力机制与Seq2seq模型;Transformer;;卷积神经网络基础;leNet;卷积神经网络进阶
一.机器翻译及相关技术
机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。
1.Encoder-Decoder
encoder:输入到隐藏状态
decoder:隐藏状态到输出

class Encoder(nn.Module):
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
class Decoder(nn.Module):
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
可以应用在对话系统、生成式任务中。
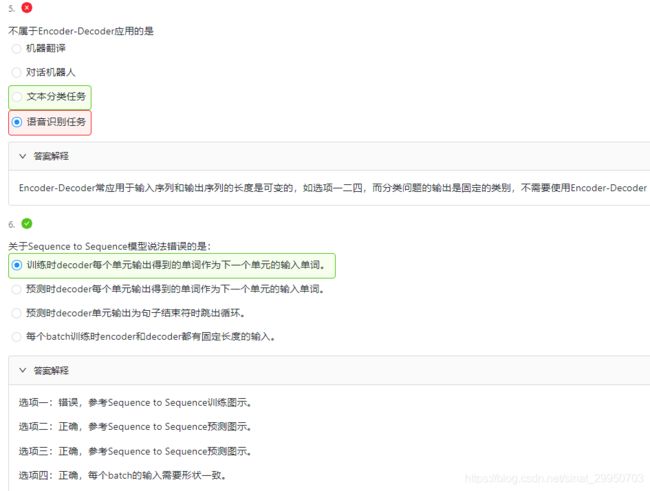
2.Sequence to Sequence模型


Encoder
class Seq2SeqEncoder(d2l.Encoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
self.num_hiddens=num_hiddens
self.num_layers=num_layers
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size,num_hiddens, num_layers, dropout=dropout)
def begin_state(self, batch_size, device):
return [torch.zeros(size=(self.num_layers, batch_size, self.num_hiddens), device=device),
torch.zeros(size=(self.num_layers, batch_size, self.num_hiddens), device=device)]
def forward(self, X, *args):
X = self.embedding(X) # X shape: (batch_size, seq_len, embed_size)
X = X.transpose(0, 1) # RNN needs first axes to be time 将batch_size与seq_len作调换
# state = self.begin_state(X.shape[1], device=X.device)
out, state = self.rnn(X)
# The shape of out is (seq_len, batch_size, num_hiddens).
# state contains the hidden state and the memory cell
# of the last time step, the shape is (num_layers, batch_size, num_hiddens)
return out, state
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8,num_hiddens=16, num_layers=2)
X = torch.zeros((4, 7),dtype=torch.long) # 假设输入4句话,每句话 7 个单词
output, state = encoder(X)
output.shape, len(state), state[0].shape, state[1].shape # len(state)表示包含记忆细胞Ct和隐藏状态Ht
'''
(torch.Size([7, 4, 16]), 2, torch.Size([2, 4, 16]), torch.Size([2, 4, 16]))
'''
Decoder
class Seq2SeqDecoder(d2l.Decoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size,num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens,vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
X = self.embedding(X).transpose(0, 1)
out, state = self.rnn(X, state)
# Make the batch to be the first dimension to simplify loss computation.
out = self.dense(out).transpose(0, 1)
return out, state
decoder = Seq2SeqDecoder(vocab_size=10, embed_size=8,num_hiddens=16, num_layers=2)
state = decoder.init_state(encoder(X))
out, state = decoder(X, state)
out.shape, len(state), state[0].shape, state[1].shape
'''
(torch.Size([4, 7, 10]), 2, torch.Size([2, 4, 16]), torch.Size([2, 4, 16]))
'''
损失函数
def SequenceMask(X, X_len,value=0): # X_len 是有效长度
maxlen = X.size(1)
mask = torch.arange(maxlen)[None, :].to(X_len.device) < X_len[:, None]
X[~mask]=value # X_len 后面部分用 value值填充,默认为0
return X
X = torch.tensor([[1,2,3], [4,5,6]])
SequenceMask(X,torch.tensor([1,2])) # 假设X的一维有效长度为1,二维有效长度为2。则X最终保留的是1和4 5
'''
tensor([[1, 0, 0],
[4, 5, 0]])
'''
X = torch.ones((2,3, 4))
SequenceMask(X, torch.tensor([1,2]),value=-1)
'''
tensor([[[ 1., 1., 1., 1.],
[-1., -1., -1., -1.],
[-1., -1., -1., -1.]],
[[ 1., 1., 1., 1.],
[ 1., 1., 1., 1.],
[-1., -1., -1., -1.]]])
'''
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss): # 对交叉熵损失进行改写
# pred shape: (batch_size, seq_len, vocab_size)
# label shape: (batch_size, seq_len)
# valid_length shape: (batch_size, )
def forward(self, pred, label, valid_length):
# the sample weights shape should be (batch_size, seq_len)
weights = torch.ones_like(label) # label每个位置都为1,SequenceMask会把非有效位置标为0,保留有效位置的损失
weights = SequenceMask(weights, valid_length).float()
self.reduction='none'
output=super(MaskedSoftmaxCELoss, self).forward(pred.transpose(1,2), label)
return (output*weights).mean(dim=1)
loss = MaskedSoftmaxCELoss()
# torch.ones((3, 4, 10)):3个句子,每个句子4个单词,单词表10。 每个单词位置都有 10个单词的每个单词对应的得分
# torch.ones((3,4):3个句子,只有4个正确的单词
# torch.tensor([4,3,0]):每个句子的有效长度 分别为4 3 0
loss(torch.ones((3, 4, 10)), torch.ones((3,4),dtype=torch.long), torch.tensor([4,3,0]))
'''
tensor([2.3026, 1.7269, 0.0000])
'''
训练
def train_ch7(model, data_iter, lr, num_epochs, device): # Saved in d2l
# model是整个Seq2SeqEncoder Seq2SeqDecoder
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
tic = time.time()
for epoch in range(1, num_epochs+1):
l_sum, num_tokens_sum = 0.0, 0.0
for batch in data_iter:
optimizer.zero_grad()
X, X_vlen, Y, Y_vlen = [x.to(device) for x in batch]
Y_input, Y_label, Y_vlen = Y[:,:-1], Y[:,1:], Y_vlen-1
Y_hat, _ = model(X, Y_input, X_vlen, Y_vlen)
l = loss(Y_hat, Y_label, Y_vlen).sum()
l.backward()
with torch.no_grad():
d2l.grad_clipping_nn(model, 5, device)
num_tokens = Y_vlen.sum().item()
optimizer.step()
l_sum += l.sum().item()
num_tokens_sum += num_tokens
if epoch % 50 == 0:
print("epoch {0:4d},loss {1:.3f}, time {2:.1f} sec".format(
epoch, (l_sum/num_tokens_sum), time.time()-tic))
tic = time.time()
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.0
batch_size, num_examples, max_len = 64, 1e3, 10
lr, num_epochs, ctx = 0.005, 300, d2l.try_gpu()
src_vocab, tgt_vocab, train_iter = d2l.load_data_nmt(
batch_size, max_len,num_examples)
encoder = Seq2SeqEncoder(
len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(
len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = d2l.EncoderDecoder(encoder, decoder)
train_ch7(model, train_iter, lr, num_epochs, ctx)
'''
epoch 50,loss 0.093, time 38.2 sec
epoch 100,loss 0.046, time 37.9 sec
epoch 150,loss 0.032, time 36.8 sec
epoch 200,loss 0.027, time 37.5 sec
epoch 250,loss 0.026, time 37.8 sec
epoch 300,loss 0.025, time 37.3 sec
'''
测试
def translate_ch7(model, src_sentence, src_vocab, tgt_vocab, max_len, device):
src_tokens = [src_sentence.lower().split(' ')]
src_len = len(src_tokens)
if src_len < max_len:
src_tokens += [src_vocab.pad] * (max_len - src_len)
enc_X = torch.tensor(src_tokens, device=device)
enc_valid_length = torch.tensor([src_len], device=device)
# use expand_dim to add the batch_size dimension.
enc_outputs = model.encoder(enc_X.unsqueeze(dim=0), enc_valid_length)
dec_state = model.decoder.init_state(enc_outputs, enc_valid_length)
dec_X = torch.tensor([tgt_vocab.bos], device=device).unsqueeze(dim=0)
predict_tokens = []
for _ in range(max_len):
Y, dec_state = model.decoder(dec_X, dec_state)
# The token with highest score is used as the next time step input.
dec_X = Y.argmax(dim=2)
py = dec_X.squeeze(dim=0).int().item()
if py == tgt_vocab.eos:
break
predict_tokens.append(py)
return ' '.join(tgt_vocab.to_tokens(predict_tokens))
for sentence in ['Go .', 'Wow !', "I'm OK .", 'I won !']:
print(sentence + ' => ' + translate_ch7(
model, sentence, src_vocab, tgt_vocab, max_len, ctx))
'''
Go . => va !
Wow ! => !
I'm OK . => ça va .
I won ! => j'ai gagné !
'''
3.Beam Search 集束搜索
维特比算法:选择整体分数最高的句子(搜索空间太大)
贪心搜索 greedy search:对每个时间步,都找到单词表里得分最高的输出。缺点是只找到局部最优解

beam search 集束搜索:如图所示当单词表为5个,beam为2,每个时间步搜寻最优的两个
第一次查找:A C 最优
第二次查找:AB CE 最优
第三次查找:ABD CED 最优
…

二.注意力机制与Seq2seq模型
在“编码器—解码器(seq2seq)”⼀节⾥,解码器在各个时间步依赖相同的背景变量(context vector)来获取输⼊序列信息。当编码器为循环神经⽹络时,背景变量来⾃它最终时间步的隐藏状态。将源序列输入信息以循环单位状态编码,然后将其传递给解码器以生成目标序列。然而这种结构存在着问题,尤其是RNN机制实际中存在长程梯度消失的问题,对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息,所以随着所需翻译句子的长度的增加,这种结构的效果会显著下降。
与此同时,解码的目标词语可能只与原输入的部分词语有关,而并不是与所有的输入有关。例如,当把“Hello world”翻译成“Bonjour le monde”时,“Hello”映射成“Bonjour”,“world”映射成“monde”。在seq2seq模型中,解码器只能隐式地从编码器的最终状态中选择相应的信息。然而,注意力机制可以将这种选择过程显式地建模。

1.注意力机制框架


import math
import torch
import torch.nn as nn
import os
def file_name_walk(file_dir):
for root, dirs, files in os.walk(file_dir):
# print("root", root) # 当前目录路径
print("dirs", dirs) # 当前路径下所有子目录
print("files", files) # 当前路径下所有非目录子文件
file_name_walk("/home/kesci/input/fraeng6506")
'''
dirs []
files ['_about.txt', 'fra.txt']
'''
Softmax屏蔽
在深入研究实现之前,我们首先介绍softmax操作符的一个屏蔽操作。【跟上文的SequenceMask函数相似的作用】
def SequenceMask(X, X_len,value=-1e6):
maxlen = X.size(1)
#print(X.size(),torch.arange((maxlen),dtype=torch.float)[None, :],'\n',X_len[:, None] )
mask = torch.arange((maxlen),dtype=torch.float)[None, :] >= X_len[:, None]
#print(mask)
X[mask]=value
return X
def masked_softmax(X, valid_length):
# X: 3-D tensor, valid_length: 1-D or 2-D tensor
softmax = nn.Softmax(dim=-1)
if valid_length is None:
return softmax(X)
else:
shape = X.shape
if valid_length.dim() == 1:
try:
valid_length = torch.FloatTensor(valid_length.numpy().repeat(shape[1], axis=0))#[2,2,3,3]
except:
valid_length = torch.FloatTensor(valid_length.cpu().numpy().repeat(shape[1], axis=0))#[2,2,3,3]
else:
valid_length = valid_length.reshape((-1,))
# fill masked elements with a large negative, whose exp is 0
X = SequenceMask(X.reshape((-1, shape[-1])), valid_length)
return softmax(X).reshape(shape)
masked_softmax(torch.rand((2,2,4),dtype=torch.float), torch.FloatTensor([2,3]))
'''
tensor([[[0.5423, 0.4577, 0.0000, 0.0000],
[0.5290, 0.4710, 0.0000, 0.0000]],
[[0.2969, 0.2966, 0.4065, 0.0000],
[0.3607, 0.2203, 0.4190, 0.0000]]])
'''
超出2维矩阵的乘法

2.点积注意力

# Save to the d2l package.
class DotProductAttention(nn.Module):
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# query: (batch_size, #queries, d)
# key: (batch_size, #kv_pairs, d)
# value: (batch_size, #kv_pairs, dim_v)
# valid_length: either (batch_size, ) or (batch_size, xx)
def forward(self, query, key, value, valid_length=None):
d = query.shape[-1]
# set transpose_b=True to swap the last two dimensions of key
scores = torch.bmm(query, key.transpose(1,2)) / math.sqrt(d)
attention_weights = self.dropout(masked_softmax(scores, valid_length))
print("attention_weight\n",attention_weights)
return torch.bmm(attention_weights, value)
测试
现在我们创建了两个批,每个批有一个query和10个key-values对。我们通过valid_length指定,对于第一批,我们只关注前2个键-值对,而对于第二批,我们将检查前6个键-值对。因此,尽管这两个批处理具有相同的查询和键值对,但我们获得的输出是不同的。
atten = DotProductAttention(dropout=0)
keys = torch.ones((2,10,2),dtype=torch.float)
values = torch.arange((40), dtype=torch.float).view(1,10,4).repeat(2,1,1)
atten(torch.ones((2,1,2),dtype=torch.float), keys, values, torch.FloatTensor([2, 6]))
'''
attention_weight
tensor([[[0.5000, 0.5000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000]],
[[0.1667, 0.1667, 0.1667, 0.1667, 0.1667, 0.1667, 0.0000, 0.0000,
0.0000, 0.0000]]])
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],
[[10.0000, 11.0000, 12.0000, 13.0000]]])
'''
3.多层感知机注意力

# Save to the d2l package.
class MLPAttention(nn.Module):
def __init__(self, units,ipt_dim,dropout, **kwargs):
super(MLPAttention, self).__init__(**kwargs)
# Use flatten=True to keep query's and key's 3-D shapes.
self.W_k = nn.Linear(ipt_dim, units, bias=False)
self.W_q = nn.Linear(ipt_dim, units, bias=False)
self.v = nn.Linear(units, 1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, valid_length):
query, key = self.W_k(query), self.W_q(key)
#print("size",query.size(),key.size())
# expand query to (batch_size, #querys, 1, units), and key to
# (batch_size, 1, #kv_pairs, units). Then plus them with broadcast.
features = query.unsqueeze(2) + key.unsqueeze(1)
#print("features:",features.size()) #--------------开启
scores = self.v(features).squeeze(-1)
attention_weights = self.dropout(masked_softmax(scores, valid_length))
return torch.bmm(attention_weights, value)
测试
尽管MLPAttention包含一个额外的MLP模型,但如果给定相同的输入和相同的键,我们将获得与DotProductAttention相同的输出
atten = MLPAttention(ipt_dim=2,units = 8, dropout=0)
atten(torch.ones((2,1,2), dtype = torch.float), keys, values, torch.FloatTensor([2, 6]))
'''
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],
[[10.0000, 11.0000, 12.0000, 13.0000]]], grad_fn=)
'''
总结
注意力层显式地选择相关的信息。
注意层的内存由键-值对组成,因此它的输出接近于键类似于查询的值。
4.引入注意力机制的Seq2seq模型
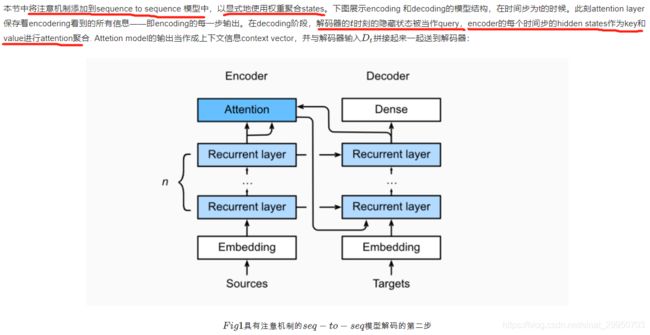
下图展示了seq2seq机制的所以层的关系,下面展示了encoder和decoder的layer结构

import sys
sys.path.append('/home/kesci/input/d2len9900')
import d2l
解码器

class Seq2SeqAttentionDecoder(d2l.Decoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
self.attention_cell = MLPAttention(num_hiddens,num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size+ num_hiddens,num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens,vocab_size)
def init_state(self, enc_outputs, enc_valid_len, *args):
outputs, hidden_state = enc_outputs
# print("first:",outputs.size(),hidden_state[0].size(),hidden_state[1].size())
# Transpose outputs to (batch_size, seq_len, hidden_size)
return (outputs.permute(1,0,-1), hidden_state, enc_valid_len)
#outputs.swapaxes(0, 1)
def forward(self, X, state):
enc_outputs, hidden_state, enc_valid_len = state
#("X.size",X.size())
X = self.embedding(X).transpose(0,1)
# print("Xembeding.size2",X.size())
outputs = []
for l, x in enumerate(X):
# print(f"\n{l}-th token")
# print("x.first.size()",x.size())
# query shape: (batch_size, 1, hidden_size)
# select hidden state of the last rnn layer as query
query = hidden_state[0][-1].unsqueeze(1) # np.expand_dims(hidden_state[0][-1], axis=1)
# context has same shape as query
# print("query enc_outputs, enc_outputs:\n",query.size(), enc_outputs.size(), enc_outputs.size())
context = self.attention_cell(query, enc_outputs, enc_outputs, enc_valid_len)
# Concatenate on the feature dimension
# print("context.size:",context.size())
x = torch.cat((context, x.unsqueeze(1)), dim=-1)
# Reshape x to (1, batch_size, embed_size+hidden_size)
# print("rnn",x.size(), len(hidden_state))
out, hidden_state = self.rnn(x.transpose(0,1), hidden_state)
outputs.append(out)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.transpose(0, 1), [enc_outputs, hidden_state,
enc_valid_len]
现在我们可以用注意力模型来测试seq2seq。为了与上一节中的模型保持一致,我们对vocab_size、embed_size、num_hiddens和num_layers使用相同的超参数。结果,我们得到了相同的解码器输出形状,但是状态结构改变了。
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8,
num_hiddens=16, num_layers=2)
# encoder.initialize()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8,
num_hiddens=16, num_layers=2)
X = torch.zeros((4, 7),dtype=torch.long)
print("batch size=4\nseq_length=7\nhidden dim=16\nnum_layers=2\n")
print('encoder output size:', encoder(X)[0].size())
print('encoder hidden size:', encoder(X)[1][0].size())
print('encoder memory size:', encoder(X)[1][1].size())
state = decoder.init_state(encoder(X), None)
out, state = decoder(X, state)
out.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape
# batch size=4
# seq_length=7
# hidden dim=16
# num_layers=2
# encoder output size: torch.Size([7, 4, 16])
# encoder hidden size: torch.Size([2, 4, 16])
# encoder memory size: torch.Size([2, 4, 16])
'''
(torch.Size([4, 7, 10]), 3, torch.Size([4, 7, 16]), 2, torch.Size([2, 4, 16]))
'''
三.Transformer


在接下来的部分,我们将会带领大家实现Transformer里全新的子结构,并且构建一个神经机器翻译模型用以训练和测试。
import os
import math
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import sys
sys.path.append('/home/kesci/input/d2len9900')
import d2l
# 这块是复制了Seq2seq小节中 masked softmax 实现,这里就不再赘述了。
def SequenceMask(X, X_len,value=-1e6):
maxlen = X.size(1)
X_len = X_len.to(X.device)
#print(X.size(),torch.arange((maxlen),dtype=torch.float)[None, :],'\n',X_len[:, None] )
mask = torch.arange((maxlen), dtype=torch.float, device=X.device)
mask = mask[None, :] < X_len[:, None]
#print(mask)
X[~mask]=value
return X
def masked_softmax(X, valid_length):
# X: 3-D tensor, valid_length: 1-D or 2-D tensor
softmax = nn.Softmax(dim=-1)
if valid_length is None:
return softmax(X)
else:
shape = X.shape
if valid_length.dim() == 1:
try:
valid_length = torch.FloatTensor(valid_length.numpy().repeat(shape[1], axis=0))#[2,2,3,3]
except:
valid_length = torch.FloatTensor(valid_length.cpu().numpy().repeat(shape[1], axis=0))#[2,2,3,3]
else:
valid_length = valid_length.reshape((-1,))
# fill masked elements with a large negative, whose exp is 0
X = SequenceMask(X.reshape((-1, shape[-1])), valid_length)
return softmax(X).reshape(shape)
# Save to the d2l package.
class DotProductAttention(nn.Module):
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# query: (batch_size, #queries, d)
# key: (batch_size, #kv_pairs, d)
# value: (batch_size, #kv_pairs, dim_v)
# valid_length: either (batch_size, ) or (batch_size, xx)
def forward(self, query, key, value, valid_length=None):
d = query.shape[-1]
# set transpose_b=True to swap the last two dimensions of key
scores = torch.bmm(query, key.transpose(1,2)) / math.sqrt(d)
attention_weights = self.dropout(masked_softmax(scores, valid_length))
return torch.bmm(attention_weights, value)
1. 多头注意力层


class MultiHeadAttention(nn.Module):
def __init__(self, input_size, hidden_size, num_heads, dropout, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = DotProductAttention(dropout)
self.W_q = nn.Linear(input_size, hidden_size, bias=False)
self.W_k = nn.Linear(input_size, hidden_size, bias=False)
self.W_v = nn.Linear(input_size, hidden_size, bias=False)
self.W_o = nn.Linear(hidden_size, hidden_size, bias=False)
def forward(self, query, key, value, valid_length):
# query, key, and value shape: (batch_size, seq_len, dim),
# where seq_len is the length of input sequence
# valid_length shape is either (batch_size, )
# or (batch_size, seq_len).
# Project and transpose query, key, and value from
# (batch_size, seq_len, hidden_size * num_heads) to
# (batch_size * num_heads, seq_len, hidden_size).
query = transpose_qkv(self.W_q(query), self.num_heads)
key = transpose_qkv(self.W_k(key), self.num_heads)
value = transpose_qkv(self.W_v(value), self.num_heads)
if valid_length is not None:
# Copy valid_length by num_heads times
device = valid_length.device
valid_length = valid_length.cpu().numpy() if valid_length.is_cuda else valid_length.numpy()
if valid_length.ndim == 1:
valid_length = torch.FloatTensor(np.tile(valid_length, self.num_heads))
else:
valid_length = torch.FloatTensor(np.tile(valid_length, (self.num_heads,1)))
valid_length = valid_length.to(device)
output = self.attention(query, key, value, valid_length)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
def transpose_qkv(X, num_heads):
# Original X shape: (batch_size, seq_len, hidden_size * num_heads),
# -1 means inferring its value, after first reshape, X shape:
# (batch_size, seq_len, num_heads, hidden_size)
X = X.view(X.shape[0], X.shape[1], num_heads, -1)
# After transpose, X shape: (batch_size, num_heads, seq_len, hidden_size)
X = X.transpose(2, 1).contiguous()
# Merge the first two dimensions. Use reverse=True to infer shape from
# right to left.
# output shape: (batch_size * num_heads, seq_len, hidden_size)
output = X.view(-1, X.shape[2], X.shape[3])
return output
# Saved in the d2l package for later use
def transpose_output(X, num_heads):
# A reversed version of transpose_qkv
# 从X:(batch_size x num_heads, seq_len, hidden_size)到(batch_size, seq_len, hidden_size x num_heads)
X = X.view(-1, num_heads, X.shape[1], X.shape[2])
X = X.transpose(2, 1).contiguous()
return X.view(X.shape[0], X.shape[1], -1)
cell = MultiHeadAttention(5, 9, 3, 0.5)
X = torch.ones((2, 4, 5))
valid_length = torch.FloatTensor([2, 3])
cell(X, X, X, valid_length).shape
'''
torch.Size([2, 4, 9])
'''
2.基于位置的前馈网络FFN
Transformer 模块另一个非常重要的部分就是基于位置的前馈网络(Feed-Forward Networdks,FFN),它接受一个形状为(batch_size,seq_length, feature_size)的三维张量。Position-wise FFN由两个全连接层组成,他们作用在最后一维上。因为序列的每个位置的状态都会被单独地更新,所以我们称他为position-wise,这等效于一个1x1的卷积。
下面我们来实现PositionWiseFFN:
# Save to the d2l package.
class PositionWiseFFN(nn.Module):
def __init__(self, input_size, ffn_hidden_size, hidden_size_out, **kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.ffn_1 = nn.Linear(input_size, ffn_hidden_size)
self.ffn_2 = nn.Linear(ffn_hidden_size, hidden_size_out)
def forward(self, X):
return self.ffn_2(F.relu(self.ffn_1(X)))
与多头注意力层相似,FFN层同样只会对最后一维的大小进行改变;除此之外,对于两个完全相同的输入,FFN层的输出也将相等。
ffn = PositionWiseFFN(4, 4, 8)
out = ffn(torch.ones((2,3,4)))
print(out, out.shape)
'''
tensor([[[ 0.2040, -0.1118, -0.1163, 0.1494, 0.3978, -0.5561, 0.4662,
-0.6598],
[ 0.2040, -0.1118, -0.1163, 0.1494, 0.3978, -0.5561, 0.4662,
-0.6598],
[ 0.2040, -0.1118, -0.1163, 0.1494, 0.3978, -0.5561, 0.4662,
-0.6598]],
[[ 0.2040, -0.1118, -0.1163, 0.1494, 0.3978, -0.5561, 0.4662,
-0.6598],
[ 0.2040, -0.1118, -0.1163, 0.1494, 0.3978, -0.5561, 0.4662,
-0.6598],
[ 0.2040, -0.1118, -0.1163, 0.1494, 0.3978, -0.5561, 0.4662,
-0.6598]]], grad_fn=) torch.Size([2, 3, 8])
'''
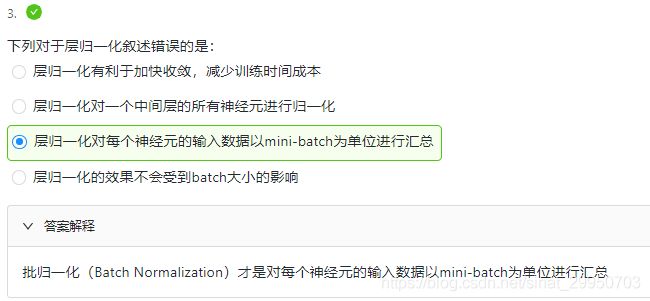
3.Add and Norm
除了上面两个模块之外,Transformer还有一个重要的相加归一化层,它可以平滑地整合输入和其他层的输出,因此我们在每个多头注意力层和FFN层后面都添加一个含残差连接的Layer Norm层。这里 Layer Norm 与7.5小节的Batch Norm很相似,唯一的区别在于Batch Norm是对于batch size这个维度进行计算均值和方差的,而Layer Norm则是对最后一维进行计算。层归一化可以防止层内的数值变化过大,从而有利于加快训练速度并且提高泛化性能。
layernorm = nn.LayerNorm(normalized_shape=2, elementwise_affine=True)
batchnorm = nn.BatchNorm1d(num_features=2, affine=True)
X = torch.FloatTensor([[1,2], [3,4]])
print('layer norm:', layernorm(X))
print('batch norm:', batchnorm(X))
'''
layer norm: tensor([[-1.0000, 1.0000],
[-1.0000, 1.0000]], grad_fn=)
batch norm: tensor([[-1.0000, -1.0000],
[ 1.0000, 1.0000]], grad_fn=)
'''
# Save to the d2l package.
class AddNorm(nn.Module):
def __init__(self, hidden_size, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.norm = nn.LayerNorm(hidden_size)
def forward(self, X, Y):
return self.norm(self.dropout(Y) + X)
由于残差连接,X和Y需要有相同的维度。
add_norm = AddNorm(4, 0.5)
add_norm(torch.ones((2,3,4)), torch.ones((2,3,4))).shape
'''
torch.Size([2, 3, 4])
'''
4.位置编码
与循环神经网络不同,无论是多头注意力网络还是前馈神经网络都是独立地对每个位置的元素进行更新,这种特性帮助我们实现了高效的并行,却丢失了重要的序列顺序的信息。为了更好的捕捉序列信息,Transformer模型引入了位置编码去保持输入序列元素的位置。
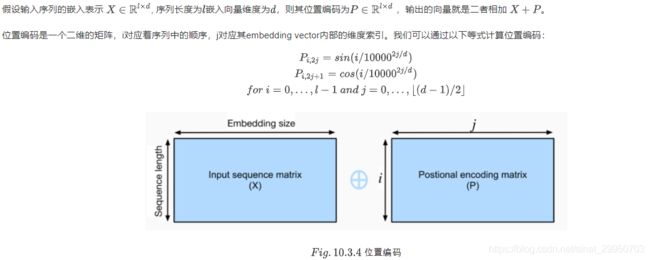
class PositionalEncoding(nn.Module):
def __init__(self, embedding_size, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
self.P = np.zeros((1, max_len, embedding_size))
X = np.arange(0, max_len).reshape(-1, 1) / np.power(
10000, np.arange(0, embedding_size, 2)/embedding_size)
self.P[:, :, 0::2] = np.sin(X)
self.P[:, :, 1::2] = np.cos(X)
self.P = torch.FloatTensor(self.P)
def forward(self, X):
if X.is_cuda and not self.P.is_cuda:
self.P = self.P.cuda()
X = X + self.P[:, :X.shape[1], :]
return self.dropout(X)
5.编码器
我们已经有了组成Transformer的各个模块,现在我们可以开始搭建了!编码器包含一个多头注意力层,一个position-wise FFN,和两个 Add and Norm层。对于attention模型以及FFN模型,我们的输出维度都是与embedding维度一致的,这也是由于残差连接天生的特性导致的,因为我们要将前一层的输出与原始输入相加并归一化。
class EncoderBlock(nn.Module):
def __init__(self, embedding_size, ffn_hidden_size, num_heads,
dropout, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = MultiHeadAttention(embedding_size, embedding_size, num_heads, dropout)
self.addnorm_1 = AddNorm(embedding_size, dropout)
self.ffn = PositionWiseFFN(embedding_size, ffn_hidden_size, embedding_size)
self.addnorm_2 = AddNorm(embedding_size, dropout)
def forward(self, X, valid_length):
Y = self.addnorm_1(X, self.attention(X, X, X, valid_length))
return self.addnorm_2(Y, self.ffn(Y))
# batch_size = 2, seq_len = 100, embedding_size = 24
# ffn_hidden_size = 48, num_head = 8, dropout = 0.5
X = torch.ones((2, 100, 24))
encoder_blk = EncoderBlock(24, 48, 8, 0.5)
encoder_blk(X, valid_length).shape
'''
torch.Size([2, 100, 24])
'''
![]()
class TransformerEncoder(d2l.Encoder):
def __init__(self, vocab_size, embedding_size, ffn_hidden_size,
num_heads, num_layers, dropout, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.embedding_size = embedding_size
self.embed = nn.Embedding(vocab_size, embedding_size)
self.pos_encoding = PositionalEncoding(embedding_size, dropout)
self.blks = nn.ModuleList()
for i in range(num_layers):
self.blks.append(
EncoderBlock(embedding_size, ffn_hidden_size,
num_heads, dropout))
def forward(self, X, valid_length, *args):
X = self.pos_encoding(self.embed(X) * math.sqrt(self.embedding_size))
for blk in self.blks:
X = blk(X, valid_length)
return X
# test encoder
encoder = TransformerEncoder(200, 24, 48, 8, 2, 0.5)
encoder(torch.ones((2, 100)).long(), valid_length).shape
'''
torch.Size([2, 100, 24])
'''
6.解码器
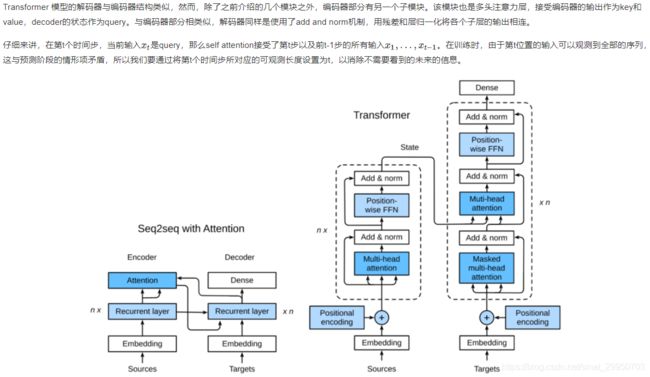
class DecoderBlock(nn.Module):
def __init__(self, embedding_size, ffn_hidden_size, num_heads,dropout,i,**kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention_1 = MultiHeadAttention(embedding_size, embedding_size, num_heads, dropout)
self.addnorm_1 = AddNorm(embedding_size, dropout)
self.attention_2 = MultiHeadAttention(embedding_size, embedding_size, num_heads, dropout)
self.addnorm_2 = AddNorm(embedding_size, dropout)
self.ffn = PositionWiseFFN(embedding_size, ffn_hidden_size, embedding_size)
self.addnorm_3 = AddNorm(embedding_size, dropout)
def forward(self, X, state):
enc_outputs, enc_valid_length = state[0], state[1]
# state[2][self.i] stores all the previous t-1 query state of layer-i
# len(state[2]) = num_layers
# If training:
# state[2] is useless.
# If predicting:
# In the t-th timestep:
# state[2][self.i].shape = (batch_size, t-1, hidden_size)
# Demo:
# love dogs ! [EOS]
# | | | |
# Transformer
# Decoder
# | | | |
# I love dogs !
if state[2][self.i] is None:
key_values = X
else:
# shape of key_values = (batch_size, t, hidden_size)
key_values = torch.cat((state[2][self.i], X), dim=1)
state[2][self.i] = key_values
if self.training:
batch_size, seq_len, _ = X.shape
# Shape: (batch_size, seq_len), the values in the j-th column are j+1
valid_length = torch.FloatTensor(np.tile(np.arange(1, seq_len+1), (batch_size, 1)))
valid_length = valid_length.to(X.device)
else:
valid_length = None
X2 = self.attention_1(X, key_values, key_values, valid_length)
Y = self.addnorm_1(X, X2)
Y2 = self.attention_2(Y, enc_outputs, enc_outputs, enc_valid_length)
Z = self.addnorm_2(Y, Y2)
return self.addnorm_3(Z, self.ffn(Z)), state
decoder_blk = DecoderBlock(24, 48, 8, 0.5, 0)
X = torch.ones((2, 100, 24))
state = [encoder_blk(X, valid_length), valid_length, [None]]
decoder_blk(X, state)[0].shape
'''
torch.Size([2, 100, 24])
'''
对于Transformer解码器来说,构造方式与编码器一样,除了最后一层添加一个dense layer以获得输出的置信度分数。下面让我们来实现一下Transformer Decoder,除了常规的超参数例如vocab_size embedding_size 之外,解码器还需要编码器的输出 enc_outputs 和句子有效长度 enc_valid_length。
class TransformerDecoder(d2l.Decoder):
def __init__(self, vocab_size, embedding_size, ffn_hidden_size,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.embedding_size = embedding_size
self.num_layers = num_layers
self.embed = nn.Embedding(vocab_size, embedding_size)
self.pos_encoding = PositionalEncoding(embedding_size, dropout)
self.blks = nn.ModuleList()
for i in range(num_layers):
self.blks.append(
DecoderBlock(embedding_size, ffn_hidden_size, num_heads,
dropout, i))
self.dense = nn.Linear(embedding_size, vocab_size)
def init_state(self, enc_outputs, enc_valid_length, *args):
return [enc_outputs, enc_valid_length, [None]*self.num_layers]
def forward(self, X, state):
X = self.pos_encoding(self.embed(X) * math.sqrt(self.embedding_size))
for blk in self.blks:
X, state = blk(X, state)
return self.dense(X), state
7.训练
import zipfile
import torch
import requests
from io import BytesIO
from torch.utils import data
import sys
import collections
class Vocab(object): # This class is saved in d2l.
def __init__(self, tokens, min_freq=0, use_special_tokens=False):
# sort by frequency and token
counter = collections.Counter(tokens)
token_freqs = sorted(counter.items(), key=lambda x: x[0])
token_freqs.sort(key=lambda x: x[1], reverse=True)
if use_special_tokens:
# padding, begin of sentence, end of sentence, unknown
self.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3)
tokens = ['', '', '', '']
else:
self.unk = 0
tokens = ['']
tokens += [token for token, freq in token_freqs if freq >= min_freq]
self.idx_to_token = []
self.token_to_idx = dict()
for token in tokens:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
else:
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
else:
return [self.idx_to_token[index] for index in indices]
def load_data_nmt(batch_size, max_len, num_examples=1000):
"""Download an NMT dataset, return its vocabulary and data iterator."""
# Download and preprocess
def preprocess_raw(text):
text = text.replace('\u202f', ' ').replace('\xa0', ' ')
out = ''
for i, char in enumerate(text.lower()):
if char in (',', '!', '.') and text[i-1] != ' ':
out += ' '
out += char
return out
with open('/home/kesci/input/fraeng6506/fra.txt', 'r') as f:
raw_text = f.read()
text = preprocess_raw(raw_text)
# Tokenize
source, target = [], []
for i, line in enumerate(text.split('\n')):
if i >= num_examples:
break
parts = line.split('\t')
if len(parts) >= 2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
# Build vocab
def build_vocab(tokens):
tokens = [token for line in tokens for token in line]
return Vocab(tokens, min_freq=3, use_special_tokens=True)
src_vocab, tgt_vocab = build_vocab(source), build_vocab(target)
# Convert to index arrays
def pad(line, max_len, padding_token):
if len(line) > max_len:
return line[:max_len]
return line + [padding_token] * (max_len - len(line))
def build_array(lines, vocab, max_len, is_source):
lines = [vocab[line] for line in lines]
if not is_source:
lines = [[vocab.bos] + line + [vocab.eos] for line in lines]
array = torch.tensor([pad(line, max_len, vocab.pad) for line in lines])
valid_len = (array != vocab.pad).sum(1)
return array, valid_len
src_vocab, tgt_vocab = build_vocab(source), build_vocab(target)
src_array, src_valid_len = build_array(source, src_vocab, max_len, True)
tgt_array, tgt_valid_len = build_array(target, tgt_vocab, max_len, False)
train_data = data.TensorDataset(src_array, src_valid_len, tgt_array, tgt_valid_len)
train_iter = data.DataLoader(train_data, batch_size, shuffle=True)
return src_vocab, tgt_vocab, train_iter
import os
import d2l
# 平台暂时不支持gpu,现在会自动使用cpu训练,gpu可以用了之后会使用gpu来训练
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
embed_size, embedding_size, num_layers, dropout = 32, 32, 2, 0.05
batch_size, num_steps = 64, 10
lr, num_epochs, ctx = 0.005, 250, d2l.try_gpu()
print(ctx)
num_hiddens, num_heads = 64, 4
src_vocab, tgt_vocab, train_iter = load_data_nmt(batch_size, num_steps)
encoder = TransformerEncoder(
len(src_vocab), embedding_size, num_hiddens, num_heads, num_layers,
dropout)
decoder = TransformerDecoder(
len(src_vocab), embedding_size, num_hiddens, num_heads, num_layers,
dropout)
model = d2l.EncoderDecoder(encoder, decoder)
d2l.train_s2s_ch9(model, train_iter, lr, num_epochs, ctx)
'''
cpu
epoch 50,loss 0.048, time 53.3 sec
epoch 100,loss 0.040, time 53.4 sec
epoch 150,loss 0.037, time 53.5 sec
epoch 200,loss 0.036, time 53.6 sec
epoch 250,loss 0.035, time 53.5 sec
'''
model.eval()
for sentence in ['Go .', 'Wow !', "I'm OK .", 'I won !']:
print(sentence + ' => ' + d2l.predict_s2s_ch9(
model, sentence, src_vocab, tgt_vocab, num_steps, ctx))
'''
Go . => !
Wow ! => !
I'm OK . => ça va .
I won ! => j'ai gagné !
'''
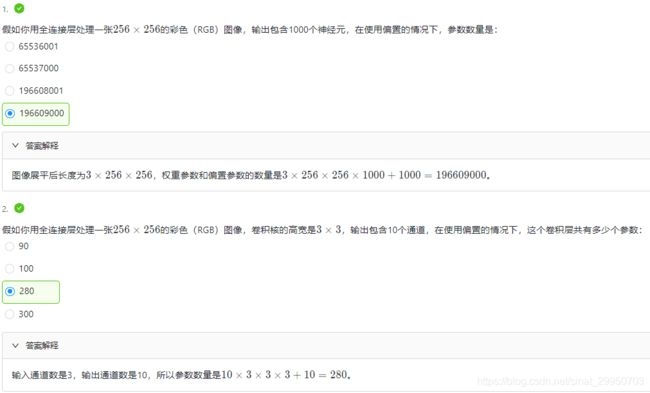
四.卷积神经网络基础
因 四五六章节知识较基础; 故 略
五.LeNet
略
六.卷积神经网络进阶
略
课后习题
机器翻译及相关技术

注意力机制与Seq2seq模型


Transformer

卷积神经网络基础

leNet

卷积神经网络进阶


