Interactive Sketch-Based Normal Map Generation with Deep Neural Networks
Interactive Sketch-Based Normal Map Generation with Deep Neural Networks
视频:
https://m.weibo.cn/5716001168/4531729966307512
疑惑:
Normal Map—>法向图 or 法线贴图
Sketch—>素描 or 草图
mask–>掩膜
不对的地方多多指点
文献笔记
- 摘要
- 1.引言
- 2.相关工作
-
- 2.1基于素描的建模
- 2.2图像转换
- 3.方法
-
- 3.1 目标函数
- 3.2网络设计
- 3.3 用户交互
- 4. 实验
- 5. 讨论

图 1:我们的方法的整体工作流程。我们提出的生成器网络将单张输入素描转换成法线贴图,其中仅使用很少或不使用用户干预。这里我们使用了 RGB 通道来表示 3D 法线分量。所生成的法线贴图可用于多种应用,比如重设表面光照、纹理贴图等。比如这里我们将法线贴图用于冯氏着色(Phong shading)。
摘要
高质量法向图(normal map)是用于表示复杂形状的重要媒介。
在本论文中,我们提出了一种使用深度学习技术生成法线贴图的交互式系统。我们的方法使用了生成对抗网络(GAN),能为素描输入生成高质量的法线贴图。
此外,我们还能通过整合用户在所选择的点上指定的法线来提升我们系统的交互能力。我们的方法可以实时生成高质量法线贴图。
我们进行了全面的实验,结果表明了我们的方法的有效性和稳健性。我们还进行了全面的用户研究,结果表明:在用户感知方面,与其它方法相比,我们的方法所生成的法线贴图与基本真值(ground truth)之间的差异更小。
1.引言
法线贴图(normal map)在学术研究和商业生产中都有至关重要作用。对于形状重建、表面编辑、纹理贴图和拟真表面渲染等很多图形应用而言,法线贴图非常重要。表面法线贴图是形状的高阶微分信息,因此在设计流程的早期阶段不易被人准确推理得到。此外,手工设计法线贴图是一个繁琐的过程,通常需要大量的资源投入才能得到高质量的结果。对于精细的形状,因为形状的复杂性,特别是对于新手设计师来说,手工方法是比较麻烦的。在商业生产上,专业人士需要花费数小时才能手工生成精致的法向贴图,这很大程度上限制了生产效率。
在各种表示方法中,素描(sketch)能让设计师比较直观地传达自己的设计概念,因为这种方式有很好的多样性、灵活性、简洁性和效率。这也是一种用于展现形状和其它几何信息的常用媒介。使用素描将 3D 信息传递到 2D 域中是人们常常使用的自然方法。因为表面法线是编码 3D 信息的最直接的方法之一,所以「素描到法线」是将 2D 概念投射到 3D 空间的主要释义方法,这在卡通着色、数字表面建模、游戏场景增强等方面有广泛的应用。根据素描自动推导法线贴图有望成为图形设计师的有用工具。
近些年来,研究界已经见证了深度神经网络在各种不同领域的优良能力。深度神经网络已经成为了很多问题背后的常用解决方案,尤其是与图像相关的难题。具体而言,基于 GAN 的方法已经在一系列图像生成问题上取得了出色的表现。更具体来说,对于基于引导的(guidance-based)图像生成,GAN 在传统的深度学习方法的基础上表现出了显著的提升。因为法线信息和素描曲线在图像域中都有良好的表征,所以根据素描推导法线贴图可以采用深度神经网络来实现。
在本论文中,我们提出了一种交互式的生成系统,其使用了一个深度神经网络框架来根据输入素描生成法线贴图。在我们的系统中,素描到法线贴图生成问题被当作了一个图像转译问题——使用一个基于 GAN 的框架将素描图像「转译」成法线贴图图像。为了增强输入素描和所生成的法线贴图之间的对应关系,我们整合了一种条件 GAN 框架,其可以根据条件引导(conditional guidance)[20] 来生成和判别图像。我们在生成器中使用了 U-net [24] 架构来在生成过程中传递平滑的信息流,从而进一步提升像素层面的对应关系。我们在我们的实现中使用了 Wasserstein 距离,以为网络更新提供更有效的引导和降低训练过程的不稳定性。
因为素描是形状的高度简化的表示,所以对于单张输入素描,可能会有多种形状释义或可能的法线贴图。我们依靠用户来解决这种模糊性问题。**为了做到这一点,我们提供了一个用户界面,让用户可以直接在输入素描中提供特定点的法线信息,从而引导法线贴图生成。**这样的界面也能扩大法线贴图的设计选择范围。我们的系统非常高效,可以根据输入素描和点提示信息实时地生成法线贴图。
我们进行了广泛的定量和定性实验并与其它方法进行了比较,结果表明了我们的方法的有效性。我们在三种类别的数据上进行了评估,并与 pix2pix [14] 和 Lun et al. [19] 等其它方法进行了比较,结果表明我们的方法在生成低误差法线贴图方面能力出色。在输入素描的变化不断增多的实验中,通过逐步增多提示点并评估我们方法的稳健性,我们验证了该方法的用户交互能力。我们的方法也可以根据全新的人工绘制的素描而得到看起来合理的结果。用户研究进一步证明了我们的方法在用户感知方面的优势。
2.相关工作
2.1基于素描的建模
基于素描建模的研究是一个活跃的范围,有很多研究者致力于这一领域,并提出了卓有成效的工作。 具体来说,从素描中重建三维形状或中间体已经有了多年的研究,但仍然引起了计算机图形学和视觉研究人员的广泛关注它的不适定问题性质和挑战(例如,草图的严重形状变形,尤其是用户未经绘图培训而造成的变形)。小注不适定问题:一个输入图像会对应多个合理输出图像,而这个问题可以看作是从多个输出中选出最合适的那一个。
传统上, 传统上,研究人员定义了综合规则,将二维素描变成三维形状。例如:…
…,不同于上述方法,我们不需要明确的规则来将几何信息编码到用户输入中。 网络不会产生类似通货膨胀的中间形状,而是直接学习从素描域到法向贴图域的潜在规则,这保留了更多的几何特征 并产生更复杂的形状。
随着深度学习技术的发展,基于学习的方法已经成为解决形状综合问题的有效工具。 利用深层神经网络强大的推理能力,解决了许多问题。例如:…
… 而我们的方法直接将草图转换为正常的地图来表示形状,而不需要其他几何中间体的帮助,类似于Lun等人生成法向贴图的方法,我们的目标是生成精细的法线贴图,从草图输入中编码详细的几何信息。然而,Lun等人的[19]方法与深度图和二进制mask一起生成法相贴图,与我们的单目标法相贴图生成相比,这导致了不准确
2.2图像转换
传统的图像转换效果是通过基于手工分离局部图像表示的机制实现的。如:图像合成,图像类比,图像去噪等。…
…
我们的方法为详细的对象模型生成正常的映射,而不是用于粗场景表面的正常映射或用于场景理解的语义标签。Isola等人提出了pix2pix[14],为图像到图像的转换提供了一个通用框架,其目标与我们的工作非常相似,即将图像从输入表示转换为所需的表示。具体来说,我们的方法是使用深度神经网络将输入素描转换为法向图,就像pix2pix一样,采用图像到图像的转换方式
3.方法
法向图和草图都可以在二维图像中得到很好的表示, 因此,我们将法向图生成问题类比到图像到图像的转换过程。 从本质上讲,我们的图像到图像转换的目标是两个图像表示域中的分布变换问题,因此我们选择了一个GAN框架来解决这个问题.
3.1介绍函数
3.2介绍网络框架
3.3 介绍用户交互的基本信息
3.1 目标函数

使用条件设置,生成器g和判别器d的数据分布试图近似成为条件分布。对于图像的转换移问题,输入图像引导网络生成输出图像非常直观,是将素描图信息融入到我们的方法中的一种有效方法。

x代表素描图,y为相应的法向图,z是与生成器G添加的潜在空间具有相同维度的随机噪声向量。Ps代表素描图域,pn代表法向图域,pr代表随机噪声分布。
最初的GAN会造成梯度消失,所以我们将loss函数改为: 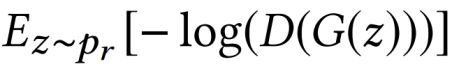 使G最大化生成的样本被确定为真实样本的可能性。然而,Arjovsky和Bottou[1]证明了优化该目标函数等于最小化KullbackLeibler散度(KLD)同时最大化Jensen-Shannon散度(JSD),但事实上KLD和JSD方向相同。
使G最大化生成的样本被确定为真实样本的可能性。然而,Arjovsky和Bottou[1]证明了优化该目标函数等于最小化KullbackLeibler散度(KLD)同时最大化Jensen-Shannon散度(JSD),但事实上KLD和JSD方向相同。
由于JSD和KLD无法计算GAN训练的输入和输出分布,我们采用WGAN,使用Wassertstein distance提高目标函数分布计算。这个函数如下:
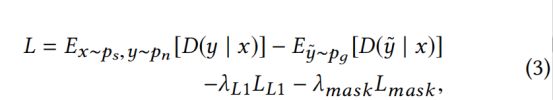
其中y生成的法向图。该法向图又是关于来自生成法向图域pg的输入素描图x 。以往的GANS方法发现,将G损失与传统损失相混合是有益的。例如:L1或者L2 loss。因此,我们再增加两部分,Ll1和Lmask:

对于用户在某些点指定的法线,我们添加了mask loss,以进一步确保输入信息传递给输出(详情见3.3)。这里选择L1 loss是因为L2loss会导致结果模糊。 L1 loss计算生成的图像和真实图像之间的差异,而mask loss更多地关注用户选择的像素距离。
3.2网络设计
图2为网络结构,其中素描图 为3个通道(RGB),二进制点的mask(指示用户指定提示的位置,1通道图像),最终为H(height)*W(width)*4维的输入,送入生成器G(16层网络)。对于辨别器D,每层包含卷积,batch normalization(批量归一化)和leak ReLU。对于生层器G,我们采用Encoder-Decoder结构,这是许多基于图像的问题的共同选择,首先提取信息 然后根据提取的输入的低维表示来推断和输出正常信息。
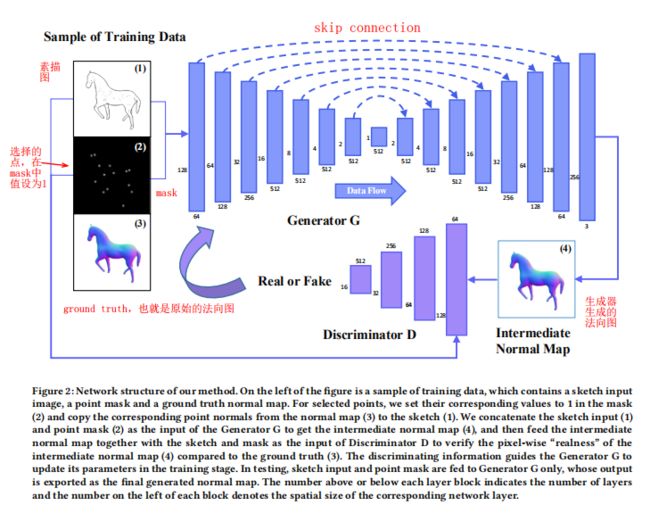
图 2:① 我们的方法的网络结构。在图左边是一个训练数据样本,其包含一张素描输入图像、一个点掩膜(point mask)和基本真值的法线贴图。
② 对于被选择的点,我们将其在mask (2) 中对应的值设为 1,并将来自法向图 (3) 的对应点法线复制到素描 (1) 中。
③ 我们将素描输入 (1) 和点mask (2) 连接起来作为生成器 G 的输入,以求取中间的法向图 (4);
④ 然后再将该中间法线贴图与素描图和mask一起作为判别器 D 的输入,以判别中间法线贴图 (4) 与ground truth (3) 相比在像素层面上的真实性。这个判别信息可在训练阶段引导生成器 G 更新自己的参数。
⑤ 在测试阶段,素描输入和点mask只作为生成器 G 的输入,其输出会被导出为最终所生成的法线贴图。
⑥ 每个层模块之上或之下的数字表示层的数量,每个模块左侧的数字表示相应网络层的空间大小。(应该就是encoder时:图像分辨率逐渐减小,通道数逐渐增加。decoder相反)
输入通过逐步下采样层到瓶颈层(bottleneck layer), 在添加随机噪声向量后,开始上采样过程, 所有输入信息通过网络中的所有层。编码器元素类似于判别器D的设置,解码器层由ReLU、反卷积、批归一化和dropout单元组成。经过编码器和解码器处理后,我们添加了一个Tanh函数来生成最终的结果。对于网络培训,我们在实现中使用RMSProp优化器。
尽管低层细节在输入和输出上有所不同,但高层结构是一致的,在设计网络时也要考虑到这一点。对于图像转换问题,我们希望通过跨层传递低级信息来指导生成[14]。因此,我们将U-NET[24]合并到G中。具体地说,连接是在生成器G中的批处理归一化之后添加到每个层i和层n-i之间的,其中n是g中的总层数。每个跳跃连接(skip connection)只是将第i层的所有通道与第N-I层的通道连接起来。
3.3 用户交互
为了合并用户点提示,将两个额外的损失与3式中的Wasserstein损失一起添加进一步规范成果的产生。用户可以用我们的用户界面直接给输入草图中的一个特定点分配一个法向,如图3所示。将具有法向信息(指定RGB颜色)的选定点添加到草图输入中,并将对应点的二进制mask设置为1。在训练过程的每一次迭代中,在初始mask和素描图通过生成器后,我们可以得到一个生成的预结果,然后在预先结果中用用户指定的提示替换mask位置的值,以确保不仅点位置,而且它的相邻区域呈现指定的法向。

图 3:我们的用户界面。用户可以在画板(右侧)选择位置,然后使用法线空间(左侧)为它们分配所需的法线。
然后,我们用高斯核对掩膜进行平滑处理,以确保相邻像素对应于点提示(hint)。对于mask loss,我们首先用L1方式将生成的图像与真实图像进行区分,然后用filtered mask对残差(剩余)图像进行逐像素生成(下式6中的⊙),最后得到生成结果的平均输入点损失:

为了在训练数据的准备中模拟用户指定的特定点的法向,我们采用了张等人的方法。 对于每幅图像,输入点的数目由概率p=1/8的几何分布生成。 每个点位置都是从二维高斯分布中采样,法向映射区域为:
![]()
其值得H和W是法向图的高和宽。
为了确保产生的法向图有明显的边界,我们也从非正态区域((即:对应白色像素))的另一个概率为p的几何分布中得到点提示。添加点提示不仅可以实现法线图的交互控制,而且可以加速网络的收敛过程,因为用户指定点的法线在训练阶段起到额外的指导作用。训练数据输入示例如图2所示。
4. 实验
后续补充
5. 讨论
最后,我们提出了一种法线贴图生成的交互式方法。条件GAN框架的实现对潜在表示进行了编码,并将潜在空间表示解码为法线贴图。通过采用U-net网络结构,我们的网络呈现出平滑的数据转换。沃瑟斯坦距离(Wasserstein distance)的结合为网络训练过程提供了精确的梯度信息。用户指定的点提示允许更直接地控制正常地图,并有效地消除草图表示的模糊性。 通过定性和定性实验证明了该技术的有效性。我们的方法优于pix2pix和Lun等人的任何一个方案。

图12 不太成功的案例:长颈鹿的一只腿是不相连的,椅子的后面区域是凌乱的,球体的表面法线分布不均匀,并且在手提椅子的后面区域。
尽管在许多情况下性能良好,但我们的方法在某些情况下表现不佳。在图12 ,我们可以看到,我们的方法在复杂的草图区域和精细的区域产生明显的视觉瑕疵。在绘制的草图之外还会生成带有补丁的瑕疵,其中包含错误预测的法线。。这是基于gan的方法中常见的现象,可以通过添加更多的用户输入提示来解决。用于大面积不均匀的法线,我们还可以考虑利用一些后处理技术来减少瑕疵。此外,测试结果高度依赖于训练数据,为跨类生成提供了相对较差的结果,如前所述。 对于用户指定的点提示, 由于法向图是三维形状的高度结构化表示,用户不能任意分配远离潜在候选点的正常点。
未来的一个方向可能是探索GAN训练技术,以提高我们当前网络的能力,减少生成结果中的瑕疵。由于目前的方法只能生成光滑的法线贴图,另一个可能的方向可以是后期处理技术,根据用户的设计在生成的法线贴图中添加更多的细节。我们当前的用户界面支持用户指定的点提示,为了更紧凑的用户交互,合并基于笔画的常规分配可能会很有趣。
参考:https://www.jiqizhixin.com/articles/042004