Python爬虫学习笔记_DAY_32_Python爬虫之Excel表的读写【Python爬虫】
p.s.高产量博主,点个关注不迷路!
目录
I. 总述与目的导向
II. 安装相关库
III. Excel文件的读写操作
IV. 完整的Excel操作示例代码
V. 常见报错解决方案
I. 总述与目的导向
本篇是专栏【Python爬虫学习笔记】的最后一篇,主要围绕着一个小的遗留点:关于python读写Excel的方式,这在爬虫中用途也很广泛。
本篇将通过简单的实例对Excel的读写进行讲解,对比已有的同类文章所出现的内容过于复杂的问题,本文进行了优化,力求以简单的操作为切入点,介绍清楚python读写Excel的基本操作方法。
II. 安装相关库
首先,我们需要安装一下有关Excel读写的相关库:
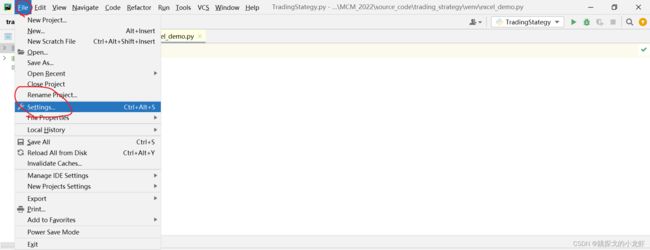
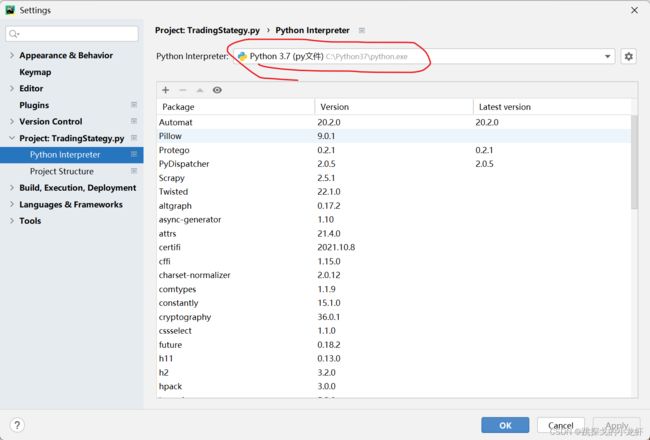
我们先创建一个python文件,并打开pycharm,查看一下自己的python解释器的位置:
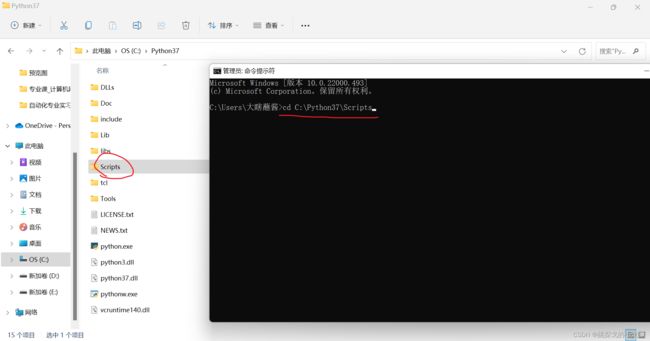
之后,我们进入该路径,找到路径下的scripts文件夹,打开终端,用终端进入该scripts文件夹:
最后,分别执行下面的两句安装指令,安装读和写Excel的库(两个都要执行):
pip install xlrdpip install xlsxwriterIII. Excel文件的读写操作
上面的两个库都安装成功之后,我们按照下面的顺序一点一点的介绍Excel的读写操作,进度不会太快,基础不是很好的朋友的也不需要担心:
1️⃣ 导入两个包:
第一部分,我们先介绍导入包的代码格式:
import xlrd
import xlsxwriter这里要注意一下,两个包的作用是不同的:
xlrd 这个包是当我们需要打开或者读出一个Excel文件时需要依赖的包,我们的写入操作是不需要它的。
xlsxwriter 这个包从拼写就可以看出它是专供写入Excel使用的包。
2️⃣ 创建一张空表:
接下来,我们演示一下如何创建一张新表:
import xlsxwriter
excel_file_writer = xlsxwriter.Workbook(r'./demo.xlsx')
excel_file_writer.close()我们可以发现,表的创建工作只需要xlsxwriter包即可,无关另一个包。它的过程是首先我们新建一个文件操作对象(excel_file_writer),并在创建时传入文件的路径和文件名称(注意后缀只能是"xlsx")。
另外,一定不要忘记最后执行close()函数,否则创建的表不会真正被保存在本地,也就是找不到创建的新表。
执行之后,我们就可以看到一张空表出现在指定的位置:

3️⃣ 向表中写入数据:
我们仍然以面向小白为主,以简单的例子切入。首先我们定义四个变量:
student_name_1 = 'Lobster'
grade_1 = 99
student_name_2 = 'Zhangsan'
grade_2 = 66这四个变量定义之后,我们现在想要把这四个数据放入一张Excel的工作表中,并按照下面的位置摆放:
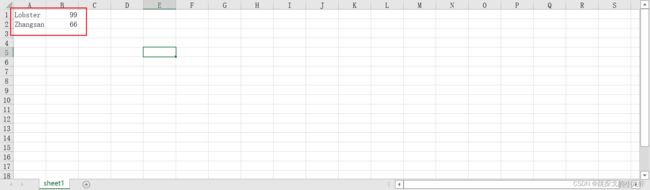
于是这个需求可以类比把大象塞入冰箱一样,先拆分一下,拆成两个动作:
(1) 新建一张工作表
(2) 向这张工作表写入上面的内容
这时候可能对Excel不熟悉的朋友有疑惑了,我们不是已经创建了一个Excel表?有这个疑惑的朋友,我稍作解释:我们新建的是一个Excel文件,一个Excel可以包含多张工作表,我们平时说的Excel表其实就是指的Excel的工作表,它是长这样的:
新建一张Excel工作表,我们需要执行下面这行代码:
excel_worksheet_writer = excel_file_writer.add_worksheet('sheet1')excel_worksheet_writer是我们定义的工作表操作对象,调用excel表操作对象excel_file_writer的add_worksheet()函数,传入的字符串代表我们新建的工作表的名称。
此时我们执行下面的四句代码,完成前面的四个变量的写入:
excel_worksheet_reader.write(0,0,student_name_1)
excel_worksheet_reader.write(0,1,grade_1)
excel_worksheet_reader.write(1,0,student_name_2)
excel_worksheet_reader.write(1,1,grade_2)之所以举例子用四个变量,是想更具体的展示写入函数write()的三个传参的意思:
write(工作表的行数,工作表的列数,写入的数据)
掌握了上面的基础写入操作,我们可以尝试一个爬虫中常用的循环写入列表数据的实例:
import xlsxwriter
excel_file_writer = xlsxwriter.Workbook(r'./demo.xlsx')
excel_worksheet_writer = excel_file.add_worksheet('sheet1')
student_name_list = ['a','b','c','d','e']
grade_list = [60,70,80,90,100]
for i in range(len(student_name_list)):
excel_worksheet_writer.write(i,0,student_name_list[i])
excel_worksheet_writer.write(i,1,grade_list[i])
excel_file_writer.close()上面定义了两个列表,在爬虫中,我们很多数据都是列表形式返回,因此上面的例子很具有实战意义,执行之后,我们在Excel表中能看到下面的数据:

4️⃣ 关联已存在的Excel工作表:
我们为了方便起见,直接拿上一步创建的Excel表作为读取的表样例,此时我们待读取的表的名称是"demo.xlsx",它的内容是这样的:
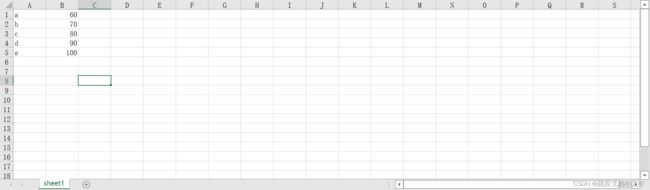
读取的第一步,我们要导入前面提到的作用于读取的一个python库:
import xlrd之后,我们类比写入操作,分析一下不难得出现在应该要创建一个Excel文件操作对象,这个对象关联一张已存在的excel表:
excel_file_reader = xlrd.open_workbook(r'./demo.xlsx')这一步,我们成功的定义了一个Excel文件操作对象,并与我们前面创建的"demo.xlsx"相关联。
接下来,还是参考写入的流程,那么我们要干的事情就又可以拆分成两步:
(1) 创建一个工作表操作对象,关联一张工作表
(2) 向这张工作表写入上面的内容
所以我们通过下面这行代码,实现新建一个工作表操作对象,并关联一张工作表(注意,整个讲述过程中,我有意在区分Excel表和Excel工作表,大家也一定要区分开,如果区分不开的朋友,回看上面的解释):
excel_worksheet_reader = excel_file_reader.sheets()[0]这里注意了,调用了sheets()函数后,后面有一个索引值,这个值代表了关联的是第几张工作表:
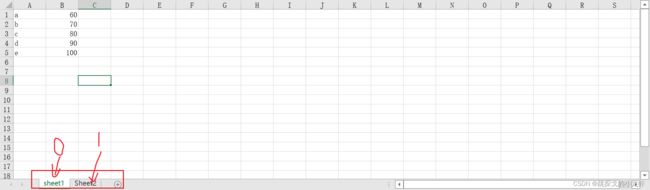
第一张表索引值是0,以此类推即可。
下面就剩下把数据读出去了,这又可以做一些简单的细分:
5️⃣ 按整行或整列读取:
下面的代码展示了按照整行/整理读取的方式,其中row_values代表按行读取,col_values代表案列读取:
row = excel_worksheet_reader.row_values(0)
col = excel_worksheet_reader.col_values(0)读取之后,我们打印一下看看它们分别是不是我们想要的结果:

可以看到,它的确分别打印了工作表的第一行和第一列,之后我们可以尝试修改参数为任意的行数、列数,并实现我们需要的任何需求(补充说明:与索引值类似,表的第一行、第一列的索引值也是从0开始的,后面以此类推。)
6️⃣ 读取的一些其他方式简单介绍:
如果是单看上面的内容,其实已经几乎能够满足我们需要的读取操作了,不过作为一篇全面介绍性文章,还是要把一些其他的读取方式进行简单介绍:
(1) 读取某一列的某几行:
col_ = excel_worksheet_reader.col_values(0,0,3)其中,第一个参数代表是第几列,第二个参数表示行的起始索引,第三个参数表示行的终止索引 + 1,也就是说上面这行代码最终读取的是 第0列的第0行至第2行(左闭右开区间)。
(2) 读取某一行的某几列:
row_ = excel_worksheet_reader.row_values(0,0,2)其中,第一个参数代表是第几行,第二个参数表示列的起始索引,第三个参数表示列的终止索引 + 1,也就是说上面这行代码最终读取的是 第0列的第0行至第1行(左闭右开区间)。
下面是上面两行代码的运行结果,大家可以对照上面展示的表内容,证明结果的确是正确的。

(3) 读取某一个单元格的内容:
cell_ = excel_worksheet_reader.cell(1,0).value调用的cell()函数,其中第一个参数代表行数,第二个参数代表了列数(行数和列数唯一确定一个数据),因此上面执行的代码把第1行第0列的数据存入变量cell_中,那么打印的结果应该是:

IV. 完整的Excel操作示例代码
最后,附上本次介绍所涉及的完整示例代码:
## 创建Excel表并写入内容部分
import xlsxwriter
excel_file_writer = xlsxwriter.Workbook(r'./demo.xlsx')
excel_worksheet_writer = excel_file_writer.add_worksheet('sheet1')
student_name_list = ['a','b','c','d','e']
grade_list = [60,70,80,90,100]
for i in range(len(student_name_list)):
excel_worksheet_writer.write(i,0,student_name_list[i])
excel_worksheet_writer.write(i,1,grade_list[i])
excel_file_writer.close()
## 读取Excel表的部分
import xlrd
excel_file_reader = xlrd.open_workbook('demo.xlsx')
excel_worksheet_reader = excel_file_reader.sheets()[0]
row = excel_worksheet_reader.row_values(0)
col = excel_worksheet_reader.col_values(0)
for i in row:
print(i)
for j in col:
print(j)
col_ = excel_worksheet_reader.col_values(0,0,3)
row_ = excel_worksheet_reader.row_values(0,0,2)
for i in col_:
print(i)
for j in row_:
print(j)
cell_ = excel_worksheet_reader.cell(1,0).value
print(cell_)V. 常见报错解决方案
在运行上面的Excel读取操作(写入应该不会有错误)时,可能会提示下面的错误信息:
File"C:\Python37\lib\site-packages\xlrd\__init__.py", line 170,in open_workbook raise XLRDError(FILE_FORMAT_DESCRIPTIONS[file_format]+'notsupported')xlrd.biffh.XLRDError: Excel xlsx file; not supported
这个错误的原因是安装的xlrd的版本太高,不再支持读取操作,因而解决的方案是卸载原来安装的xlrd,并安装指定版本:1.2.0的xlrd:
1️⃣ 到达之前提到的python解释器的位置,终端进入Scripts文件夹,先运行下面的卸载指令:
pip uninstall xlrd2️⃣ 运行下面这行指令,安装指定版本的xlrd:
pip install xlrd==1.2.0本专栏的新内容到此结束,如果有帮助,可以三连支持一下博主。
后面可能会整理一期合集,把所有的爬虫学习内容整合在一起!