David Silver RL课程笔记(一)
写在前面
RL入门小白,前一阵子看了一些关于RL的资料和书,包括周志华的《机器学习》西瓜书等,感觉对RL还是一知半解,不少概念理解并不深刻。最后还是决定看一遍David Silver大神的课,在这里结合自己的理解记一些课程笔记,主要是摘取部分个人认为的重点内容进行记录。一些重点名词、概念等会直接使用英文或者给出英文原文方便理解(顺便学下英语)。
感谢互联网感谢B站。
课程视频连接:https://www.bilibili.com/video/av45357759
课程配套资料:http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
(可以下载各讲的课件等资料)
概述
第一讲主要就是Reinforcement Learning(RL)的入门介绍了,主要讲了一些相关的概念,举了一些RL应用的例子,以及RL目前的一些问题(problem)。
第一讲主要分为5大部分。
- Admin
- About RL
- RL Problem
- Inside an RL Agent
- Problems within RL
PART 1 Admin
这部分就是讲了一些这门课的成绩计算balabala,介绍了两本书:
- An Introduction to RL,Sutton Barto,1998
http://www.incompleteideas.net/book/RLbook2018.pdf
很经典的RL课本了,2018版500多页,偏理论一些。 - Algorithms for RL,Szepesvari
https://sites.ualberta.ca/~szepesva/papers/RLAlgsInMDPs.pdf
偏向于公式推导,2018版不到100页。
PART 2 About RL
首先是强化学习(RL),也称增强学习,它跟监督学习、非监督学习的区别:
- 没有监督者(supervisor),只有奖励(reward)信息
- 反馈(feedback)是延后的,并不是即时反馈
- 时间很重要(time really matters),是一个动态的变化
- agent做出的action可能会影响后续的数据
然后举了一些RL应用的例子,如直升机做特技飞行、玩Atari游戏等,这里不再赘述。
PART 3 The RL Problem
这一部分David Silver重点介绍了RL的几个重要概念:
- Reward
- Agent & Environments
- State
再补充一个goal:
- Goal
下面我会结合我自己的理解进行解释这些概念。
Reward
reward用 R t R_t Rt 来表示,它是一个标量,表示agent在第 t t t 步做得有多好,agent的要干的活就是使得累计奖励最大。
agent’s job is to maximise cumulative reward
reward有正的也有负的,做得好,奖10分;做的不好,扣3分。
在这里就要说明的是:
最终的目标(goal)是要agent在每一步做出的action使得未来总奖励最大。(maximise total future reward)
当前的action可能对未来会有很重大的影响,而奖励又可能是延迟到来的。换言之,当前做了一个action使得当前得到的reward减少了,但是却能够给未来带来更大的reward。
也就是说,目光要放长远一些。
比如说,小时候纠结看电视还是要写作业,看电视我可以很开心,得到3分;但是写作业的话我就不开心,会得到0分;但是10点了爸妈回来了发现我没写作业就会揍我,-10分;要是写了作业就带我去玩+20分。那么选择写作业会使我当前的奖励变低但是会使最终的奖励最大,所以选择写作业是最优的。
Agent & Environments
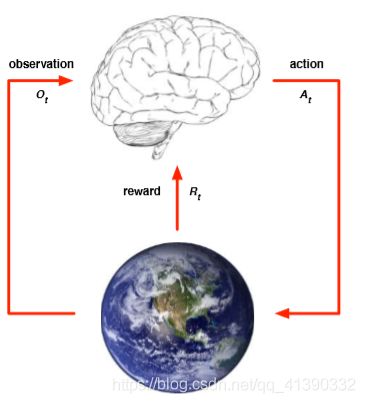
图中的大脑就是agent,地球则表示environment。实际上agent并不能直接感知到environment,他只能通过observation O t O_t Ot 来获知environment的状态。接着,agent根据算法/策略做出一个action A t A_t At ,那么environment受到action A t A_t At 后,【这里进入下一个step】发生了一定的变化(不一定是可见的)observation O t + 1 O_{t+1} Ot+1,并且返回给agent一个reward R t + 1 R_{t+1} Rt+1 。这里的 t t t 指的是step t ,即第 t 步。
每一个step,顺序应该是{ O t O_t Ot , R t R_{t} Rt , A t A_t At }
然后将过去干的所有事看做 History H t H_t Ht:
![]()
state可以看做是任何关于history的函数:
![]()
State
David Silve将state分为了3种:
- environment state
- agent state
- information state
environment state S t e S^e_{t} Ste 是环境(environment)的私有表征,不一定是agent可见的。
agent state S t a S^a_{t} Sta 实际上是agent要用于RL算法中的信息,可以是任何关于history的函数:
![]()
information state 这里就称为是马尔科夫状态(Markov State),它包含了所有过去(history)的有用信息。
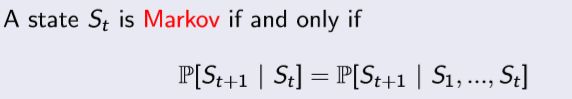
这里就是信息论的内容了。简单的说就是下一个状态只跟当前状态有关,跟以前的状态没有关系。知道当前状态就能够推断下一个状态,也就说当前状态这个信息已经包含了过去所有状态的信息了。
但是!怎么规定state呢?David Silver给出了一个很有趣的例子:
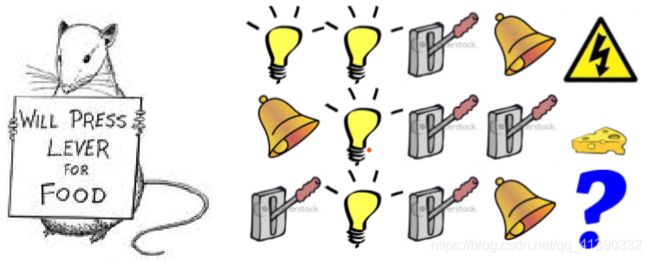
假定你是这个老鼠,当:
“灯亮、灯亮、拉闸、铃响”,然后被电了
“铃响、灯亮、拉闸、拉闸”,得到奶酪
“拉闸、灯亮、拉闸、铃响”,会怎么样?
我想的是会得到奶酪。
而当时上课的学生大部分选择被电了。
这里没有说有正确答案。
当state表示过去3个items时,也就是说“灯亮、拉闸、铃响”之后就会被电,那么第三种情况下就可能被电。
当state表示“拉闸”的次数时,比如第二种情况中,“拉闸”了两次,而第三种情况也是“拉闸”了两次,那么我也有可能获得奶酪。
那么万一这一整个序列其实是一个state呢?
David Silver还讲到了两种environment:这里不多讲
- Fully observable environment
- Partially observable environment
Fully observable environment 一般是马尔科夫决策过程(MPD)

Partially observable environment

Goal
这里根据课程讲到但ppt没有的,补充一下关于Goal(目标)的内容。
前面也提到了,goal的目标就是要agent在每一步做出的action使得未来总奖励最大。(maximise total future reward)
有时候一个问题里面会有好几个的小goal,可能不同的goal之间甚至会矛盾。比如说我接下来一小时要写学校作业或者去上课外班,我不知选哪个,那么就需要给定一个“偏好”,赋予不同的goal不同的权重。【下次等我想到一个更好的例子再修改】
PART 4 Inside an RL Agent
重头戏来了。
在RL的agent里面,主要包括下面三个部分:
- Policy
- Value function
- Model
并且给出一个走迷宫的例子。
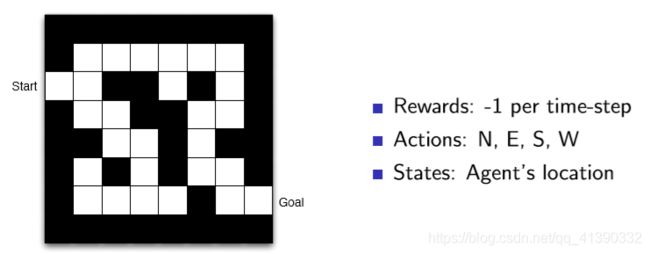
每走一步都会得到-1的reward,目标就是最快走到终点处(使得reward最大)。
Policy
策略(policy)就是一个state到action的映射,一般都是{state,action}的概率。
有确定性的策略(Deterministic policy):在某个state下我就选这个action。
![]()
以及随机的策略(Stochastic policy):在这个state下有不同的概率选择不同的action。
![]()
在迷宫游戏下,policy可能就是表示这样的箭头方向的某种数据结构。

Value function
中文一般称为值函数或者价值函数

值函数就是一个预测值,预测在未来将会得到多少reward,去估计state好不好,也就是去选择不同的action。
举个例子:
现在状态为state_0,我准备做下一步的动作了,那么哪一个更好呢?
那我就要去预测不同的动作会给我带来多少reward了。
假定采取action1 会到达state_1,得到奖励 r1;
假定采取action2 会到达state_2,得到奖励 r2;
如果r1>r2,那我肯定就要采取action1了。
这个时候value function V π ( s ) V_\pi(s) Vπ(s) 就是表示估计的下一个state的reward,然后比较,选择最大的那个。
这是一步的情况,有时候还要看未来很多步,前面也说了,目光要长远一点。所以会有下面这个式子:
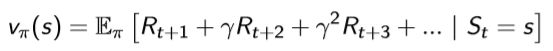
引入 γ \gamma γ 就是用来衡量时间长度。比如 γ = 0 \gamma=0 γ=0 ,等价于我就估计到下一步就行了;当 γ = 0.9 \gamma=0.9 γ=0.9 ,那么 γ 20 = 0.12 \gamma^{20}=0.12 γ20=0.12,实际上20步之后的reward的权重挺低的了,就不是那么重要了。
0 < γ < 1 0<\gamma<1 0<γ<1, γ \gamma γ 越小,表示更加注重最近几步的reward;
γ > 1 \gamma>1 γ>1, γ \gamma γ 越大,就表示重视后面的reward。
在迷宫游戏下,value function可能就是表示这样的箭头方向的某种数据结构。
最后一步的-1的意思就是我就差一步要到达目的地了,那么value function就是这一步的reward,也就是-1;同理倒数第2步的-2就是这个state的value function。
当我在中间某个位置(state)时,比如-15那个位置,我就去选择value function大的那个,即-14,那么下一步就要往上面走。
Model

别忘了model是agent里面的东西。
model其实就是agent对外部世界environment的感知和建模。这个建模不一定正确,它也不是必须的(如model-free类)。
![]()
这里这个 P P P 其实就是状态转移概率嘛。
![]()
这个 R R R 就是预测的下一步可以得到reward。
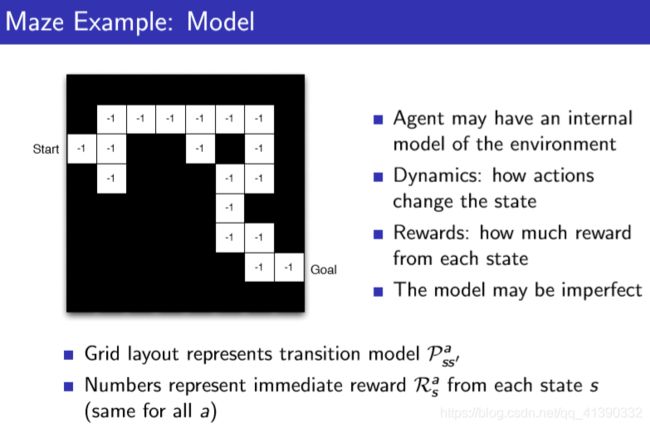
这里每一格的数字-1,表示就是每走一步的即时reward。
这一段格子轨迹就相当于转移概率的模型。
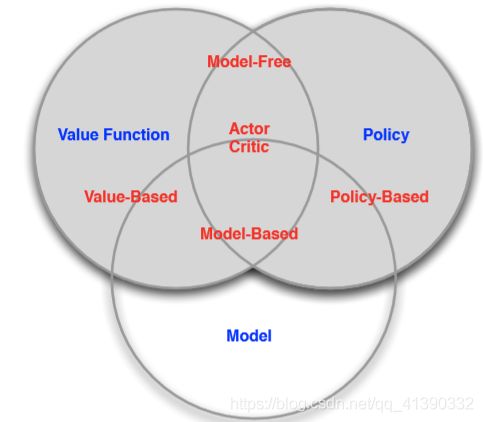
RL分类
那么根据这些元素,可以对RL算法进行分类。
根据优化的方式:
- value-based(基于值函数):根据值函数选择action
- policy-based(基于策略):不求值函数,直接依据策略行动
- actor-critic(演员-评论家):actor输出policy,critic输出值函数
根据有无model:
- model-free(免模型)
- model-based(有模型)
model-free(免模型):不去建立environment的模型,与environment进行交互,得到policy或者值函数去指导行动;
model-based(有模型):先建立模型(model),再去得到policy或者值函数。
它们之间的关系可以用下面这张图表示:
PART 5 Problems within RL
RL的几个问题:
- Learning and Planning
- Exploration and Exploitation
- Prediction and Control
Learning and Planning
RL:环境未知、agent通过与环境交互来改进策略
planning(计划):已知环境的模型,也就是知道状态转移概率。这种情况下agent可以不与外界交互,自己默默计算一下就可以建立一个状态转移的树状图来,去改进策略。
比如打扑克牌:
RL就是不知道游戏规则,慢慢摸索怎么去打牌,怎么打赢;
planning(计划)就是知道游戏规则了,只需要去找到最优策略了。
Exploration and Exploitation
即探索和利用的矛盾问题。

比如挖宝藏游戏吧,我已经探索了一部分区域,我知道某个地方A有宝藏。那么下一次我玩这个游戏,我就去这个地方A找宝藏,这就是利用(Exploitation),去得到已知的当前最优的reward;
但是说不定没去过的其他地方B还有更大的宝藏,但是这就需要去探索(Exploration)。如果去探索,我当前的reward就不是最大的,探索会牺牲掉一部分当前的reward。
RL需要去平衡这个探索-利用问题。经典方法就是 ϵ \epsilon ϵ-贪心法( ϵ \epsilon ϵ-Greedy)。
本质上RL是一个试错的过程。
Prediction and Control

Prediction(预测):用一个给定的策略去预测未来reward。
Control(控制):已知最优policy,直接得到最优的reward。
结束语
写完这一讲觉得真的好多……8000+字嗯。但是不自己整理一遍感觉都不是自己的。有些地方还有点模糊,因此没有展开。欢迎批评指正。