数据挖掘实战:二手车交易价格预测
赛题数据
数据来自某交易平台的二手车交易记录,总数据量超过40w,包含31列变量信息,其中15列为匿名变量。从中抽取15万条作为训练集,5万条作为测试集A,5万条作为测试集B,同时会对name、model、brand和regionCode等信息进行脱敏。
字段表
| Field | Description |
|---|---|
| SaleID | 交易ID,唯一编码 |
| name | 汽车交易名称,已脱敏 |
| regDate | 汽车注册日期,例如20160101,2016年01月01日 |
| model | 车型编码,已脱敏 |
| brand | 汽车品牌,已脱敏 |
| bodyType | 车身类型:豪华轿车:0,微型车:1,厢型车:2,大巴车:3,敞篷车:4,双门汽车:5,商务车:6,搅拌车:7 |
| fuelType | 燃油类型:汽油:0,柴油:1,液化石油气:2,天然气:3,混合动力:4,其他:5,电动:6 |
| gearbox | 变速箱:手动:0,自动:1 |
| power | 发动机功率:范围 [ 0, 600 ] |
| kilometer | 汽车已行驶公里,单位万km |
| notRepairedDamage | 汽车有尚未修复的损坏:是:0,否:1 |
| regionCode | 地区编码,已脱敏 |
| seller | 销售方:个体:0,非个体:1 |
| offerType | 报价类型:提供:0,请求:1 |
| creatDate | 汽车上线时间,即开始售卖时间 |
| price | 二手车交易价格(预测目标) |
| v系列特征 | 匿名特征,包含v0-14在内15个匿名特征 |
评测标准
MAE(Mean Absolute Error)。
结果提交
SaleID,price
150000,687
150001,1250
150002,2580
150003,1178
1. 导入函数工具箱
import numpy as np
import pandas as pd
import warnings
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.special import jn
from IPython.display import display, clear_output
import time
warnings.filterwarnings('ignore')
%matplotlib inline
## 模型预测的
from sklearn import linear_model
from sklearn import preprocessing
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor
## 数据降维处理的
from sklearn.decomposition import PCA,FastICA,FactorAnalysis,SparsePCA
import lightgbm as lgb
import xgboost as xgb
## 参数搜索和评价的
from sklearn.model_selection import GridSearchCV,cross_val_score,StratifiedKFold,train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error
2. 数据读取
## 通过Pandas对于数据进行读取
Train_data = pd.read_csv('used_car_train_20200313.csv', sep=' ')
TestA_data = pd.read_csv('used_car_testA_20200313.csv', sep=' ')
## 输出数据的大小信息
print('Train data shape:',Train_data.shape)
print('TestA data shape:',TestA_data.shape)
Train data shape: (150000, 31)
TestA data shape: (50000, 30)
2.1 数据简要浏览
## 通过.head() 简要浏览读取数据的形式
Train_data.head()
| SaleID | name | regDate | model | brand | bodyType | fuelType | gearbox | power | kilometer | ... | v_5 | v_6 | v_7 | v_8 | v_9 | v_10 | v_11 | v_12 | v_13 | v_14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 736 | 20040402 | 30.0 | 6 | 1.0 | 0.0 | 0.0 | 60 | 12.5 | ... | 0.235676 | 0.101988 | 0.129549 | 0.022816 | 0.097462 | -2.881803 | 2.804097 | -2.420821 | 0.795292 | 0.914762 |
| 1 | 1 | 2262 | 20030301 | 40.0 | 1 | 2.0 | 0.0 | 0.0 | 0 | 15.0 | ... | 0.264777 | 0.121004 | 0.135731 | 0.026597 | 0.020582 | -4.900482 | 2.096338 | -1.030483 | -1.722674 | 0.245522 |
| 2 | 2 | 14874 | 20040403 | 115.0 | 15 | 1.0 | 0.0 | 0.0 | 163 | 12.5 | ... | 0.251410 | 0.114912 | 0.165147 | 0.062173 | 0.027075 | -4.846749 | 1.803559 | 1.565330 | -0.832687 | -0.229963 |
| 3 | 3 | 71865 | 19960908 | 109.0 | 10 | 0.0 | 0.0 | 1.0 | 193 | 15.0 | ... | 0.274293 | 0.110300 | 0.121964 | 0.033395 | 0.000000 | -4.509599 | 1.285940 | -0.501868 | -2.438353 | -0.478699 |
| 4 | 4 | 111080 | 20120103 | 110.0 | 5 | 1.0 | 0.0 | 0.0 | 68 | 5.0 | ... | 0.228036 | 0.073205 | 0.091880 | 0.078819 | 0.121534 | -1.896240 | 0.910783 | 0.931110 | 2.834518 | 1.923482 |
5 rows × 31 columns
2.2 数据信息查看
## 通过 .info() 简要可以看到对应一些数据列名,以及NAN缺失信息
Train_data.info()
RangeIndex: 150000 entries, 0 to 149999
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 SaleID 150000 non-null int64
1 name 150000 non-null int64
2 regDate 150000 non-null int64
3 model 149999 non-null float64
4 brand 150000 non-null int64
5 bodyType 145494 non-null float64
6 fuelType 141320 non-null float64
7 gearbox 144019 non-null float64
8 power 150000 non-null int64
9 kilometer 150000 non-null float64
10 notRepairedDamage 150000 non-null object
11 regionCode 150000 non-null int64
12 seller 150000 non-null int64
13 offerType 150000 non-null int64
14 creatDate 150000 non-null int64
15 price 150000 non-null int64
16 v_0 150000 non-null float64
17 v_1 150000 non-null float64
18 v_2 150000 non-null float64
19 v_3 150000 non-null float64
20 v_4 150000 non-null float64
21 v_5 150000 non-null float64
22 v_6 150000 non-null float64
23 v_7 150000 non-null float64
24 v_8 150000 non-null float64
25 v_9 150000 non-null float64
26 v_10 150000 non-null float64
27 v_11 150000 non-null float64
28 v_12 150000 non-null float64
29 v_13 150000 non-null float64
30 v_14 150000 non-null float64
dtypes: float64(20), int64(10), object(1)
memory usage: 35.5+ MB
## 通过 .columns 查看列名
Train_data.columns
Index(['SaleID', 'name', 'regDate', 'model', 'brand', 'bodyType', 'fuelType',
'gearbox', 'power', 'kilometer', 'notRepairedDamage', 'regionCode',
'seller', 'offerType', 'creatDate', 'price', 'v_0', 'v_1', 'v_2', 'v_3',
'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12',
'v_13', 'v_14'],
dtype='object')
TestA_data.info() #查看每一列类型和缺失值情况
RangeIndex: 50000 entries, 0 to 49999
Data columns (total 30 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 SaleID 50000 non-null int64
1 name 50000 non-null int64
2 regDate 50000 non-null int64
3 model 50000 non-null float64
4 brand 50000 non-null int64
5 bodyType 48587 non-null float64
6 fuelType 47107 non-null float64
7 gearbox 48090 non-null float64
8 power 50000 non-null int64
9 kilometer 50000 non-null float64
10 notRepairedDamage 50000 non-null object
11 regionCode 50000 non-null int64
12 seller 50000 non-null int64
13 offerType 50000 non-null int64
14 creatDate 50000 non-null int64
15 v_0 50000 non-null float64
16 v_1 50000 non-null float64
17 v_2 50000 non-null float64
18 v_3 50000 non-null float64
19 v_4 50000 non-null float64
20 v_5 50000 non-null float64
21 v_6 50000 non-null float64
22 v_7 50000 non-null float64
23 v_8 50000 non-null float64
24 v_9 50000 non-null float64
25 v_10 50000 non-null float64
26 v_11 50000 non-null float64
27 v_12 50000 non-null float64
28 v_13 50000 non-null float64
29 v_14 50000 non-null float64
dtypes: float64(20), int64(9), object(1)
memory usage: 11.4+ MB
2.3 数据统计信息浏览
## 通过 .describe() 可以查看数值特征列的一些统计信息
Train_data.describe()
| SaleID | name | regDate | model | brand | bodyType | fuelType | gearbox | power | kilometer | ... | v_5 | v_6 | v_7 | v_8 | v_9 | v_10 | v_11 | v_12 | v_13 | v_14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 150000.000000 | 150000.000000 | 1.500000e+05 | 149999.000000 | 150000.000000 | 145494.000000 | 141320.000000 | 144019.000000 | 150000.000000 | 150000.000000 | ... | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 | 150000.000000 |
| mean | 74999.500000 | 68349.172873 | 2.003417e+07 | 47.129021 | 8.052733 | 1.792369 | 0.375842 | 0.224943 | 119.316547 | 12.597160 | ... | 0.248204 | 0.044923 | 0.124692 | 0.058144 | 0.061996 | -0.001000 | 0.009035 | 0.004813 | 0.000313 | -0.000688 |
| std | 43301.414527 | 61103.875095 | 5.364988e+04 | 49.536040 | 7.864956 | 1.760640 | 0.548677 | 0.417546 | 177.168419 | 3.919576 | ... | 0.045804 | 0.051743 | 0.201410 | 0.029186 | 0.035692 | 3.772386 | 3.286071 | 2.517478 | 1.288988 | 1.038685 |
| min | 0.000000 | 0.000000 | 1.991000e+07 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.500000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -9.168192 | -5.558207 | -9.639552 | -4.153899 | -6.546556 |
| 25% | 37499.750000 | 11156.000000 | 1.999091e+07 | 10.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 75.000000 | 12.500000 | ... | 0.243615 | 0.000038 | 0.062474 | 0.035334 | 0.033930 | -3.722303 | -1.951543 | -1.871846 | -1.057789 | -0.437034 |
| 50% | 74999.500000 | 51638.000000 | 2.003091e+07 | 30.000000 | 6.000000 | 1.000000 | 0.000000 | 0.000000 | 110.000000 | 15.000000 | ... | 0.257798 | 0.000812 | 0.095866 | 0.057014 | 0.058484 | 1.624076 | -0.358053 | -0.130753 | -0.036245 | 0.141246 |
| 75% | 112499.250000 | 118841.250000 | 2.007111e+07 | 66.000000 | 13.000000 | 3.000000 | 1.000000 | 0.000000 | 150.000000 | 15.000000 | ... | 0.265297 | 0.102009 | 0.125243 | 0.079382 | 0.087491 | 2.844357 | 1.255022 | 1.776933 | 0.942813 | 0.680378 |
| max | 149999.000000 | 196812.000000 | 2.015121e+07 | 247.000000 | 39.000000 | 7.000000 | 6.000000 | 1.000000 | 19312.000000 | 15.000000 | ... | 0.291838 | 0.151420 | 1.404936 | 0.160791 | 0.222787 | 12.357011 | 18.819042 | 13.847792 | 11.147669 | 8.658418 |
8 rows × 30 columns
TestA_data.describe()
| SaleID | name | regDate | model | brand | bodyType | fuelType | gearbox | power | kilometer | ... | v_5 | v_6 | v_7 | v_8 | v_9 | v_10 | v_11 | v_12 | v_13 | v_14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 50000.000000 | 50000.000000 | 5.000000e+04 | 50000.000000 | 50000.000000 | 48587.000000 | 47107.000000 | 48090.000000 | 50000.000000 | 50000.000000 | ... | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 | 50000.000000 |
| mean | 174999.500000 | 68542.223280 | 2.003393e+07 | 46.844520 | 8.056240 | 1.782185 | 0.373405 | 0.224350 | 119.883620 | 12.595580 | ... | 0.248669 | 0.045021 | 0.122744 | 0.057997 | 0.062000 | -0.017855 | -0.013742 | -0.013554 | -0.003147 | 0.001516 |
| std | 14433.901067 | 61052.808133 | 5.368870e+04 | 49.469548 | 7.819477 | 1.760736 | 0.546442 | 0.417158 | 185.097387 | 3.908979 | ... | 0.044601 | 0.051766 | 0.195972 | 0.029211 | 0.035653 | 3.747985 | 3.231258 | 2.515962 | 1.286597 | 1.027360 |
| min | 150000.000000 | 0.000000 | 1.991000e+07 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.500000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -9.160049 | -5.411964 | -8.916949 | -4.123333 | -6.112667 |
| 25% | 162499.750000 | 11203.500000 | 1.999091e+07 | 10.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 75.000000 | 12.500000 | ... | 0.243762 | 0.000044 | 0.062644 | 0.035084 | 0.033714 | -3.700121 | -1.971325 | -1.876703 | -1.060428 | -0.437920 |
| 50% | 174999.500000 | 52248.500000 | 2.003091e+07 | 29.000000 | 6.000000 | 1.000000 | 0.000000 | 0.000000 | 109.000000 | 15.000000 | ... | 0.257877 | 0.000815 | 0.095828 | 0.057084 | 0.058764 | 1.613212 | -0.355843 | -0.142779 | -0.035956 | 0.138799 |
| 75% | 187499.250000 | 118856.500000 | 2.007110e+07 | 65.000000 | 13.000000 | 3.000000 | 1.000000 | 0.000000 | 150.000000 | 15.000000 | ... | 0.265328 | 0.102025 | 0.125438 | 0.079077 | 0.087489 | 2.832708 | 1.262914 | 1.764335 | 0.941469 | 0.681163 |
| max | 199999.000000 | 196805.000000 | 2.015121e+07 | 246.000000 | 39.000000 | 7.000000 | 6.000000 | 1.000000 | 20000.000000 | 15.000000 | ... | 0.291618 | 0.153265 | 1.358813 | 0.156355 | 0.214775 | 12.338872 | 18.856218 | 12.950498 | 5.913273 | 2.624622 |
8 rows × 29 columns
3. 特征与标签构建
3.1 提取数值类型特征列名
numerical_cols = Train_data.select_dtypes(exclude = 'object').columns
print(numerical_cols)
Index(['SaleID', 'name', 'regDate', 'model', 'brand', 'bodyType', 'fuelType',
'gearbox', 'power', 'kilometer', 'regionCode', 'seller', 'offerType',
'creatDate', 'price', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6',
'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13', 'v_14'],
dtype='object')
3.2 构建训练和测试样本
## 选择特征列
feature_cols = [col for col in numerical_cols if col not in ['SaleID','name','regDate','creatDate','price','model','brand','regionCode','seller']]
feature_cols = [col for col in feature_cols if 'Type' not in col]
## 提前特征列,标签列构造训练样本和测试样本
X_data = Train_data[feature_cols]
Y_data = Train_data['price']
X_test = TestA_data[feature_cols]
print('X train shape:',X_data.shape)
print('X test shape:',X_test.shape)
X train shape: (150000, 18)
X test shape: (50000, 18)
## 定义了一个统计函数,方便后续信息统计
def Sta_inf(data):
print('_min',np.min(data))
print('_max:',np.max(data))
print('_mean',np.mean(data))
print('_ptp',np.ptp(data))
print('_std',np.std(data))
print('_var',np.var(data))
3.3 统计标签的基本分布信息
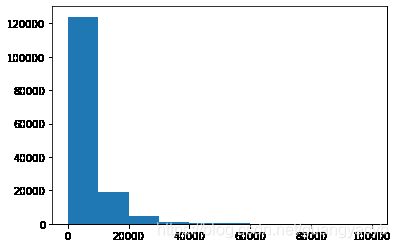
print('Sta of label:')
Sta_inf(Y_data)
Sta of label:
_min 11
_max: 99999
_mean 5923.327333333334
_ptp 99988
_std 7501.973469876635
_var 56279605.942732885
## 绘制标签的统计图,查看标签分布
plt.hist(Y_data)
plt.show()
plt.close()
3.4 缺省值用-1填补
X_data = X_data.fillna(-1)
X_test = X_test.fillna(-1)
4. 模型训练与预测
4.1 利用xgb进行五折交叉验证查看模型的参数效果
## xgb-Model
xgr = xgb.XGBRegressor(n_estimators=120, learning_rate=0.1, gamma=0, subsample=0.8,\
colsample_bytree=0.9, max_depth=7) #,objective ='reg:squarederror'
scores_train = []
scores = []
## 5折交叉验证方式
sk=StratifiedKFold(n_splits=5,shuffle=True,random_state=0)
for train_ind,val_ind in sk.split(X_data,Y_data):
train_x=X_data.iloc[train_ind].values
train_y=Y_data.iloc[train_ind]
val_x=X_data.iloc[val_ind].values
val_y=Y_data.iloc[val_ind]
xgr.fit(train_x,train_y)
pred_train_xgb=xgr.predict(train_x)
pred_xgb=xgr.predict(val_x)
score_train = mean_absolute_error(train_y,pred_train_xgb)
scores_train.append(score_train)
score = mean_absolute_error(val_y,pred_xgb)
scores.append(score)
print('Train mae:',np.mean(score_train))
print('Val mae',np.mean(scores))
Train mae: 622.8365678300579
Val mae 714.0856745005866
4.2 定义xgb和lgb模型函数
def build_model_xgb(x_train,y_train):
model = xgb.XGBRegressor(n_estimators=150, learning_rate=0.1, gamma=0, subsample=0.8,\
colsample_bytree=0.9, max_depth=7) #, objective ='reg:squarederror'
model.fit(x_train, y_train)
return model
def build_model_lgb(x_train,y_train):
estimator = lgb.LGBMRegressor(num_leaves=127,n_estimators = 150)
param_grid = {
'learning_rate': [0.01, 0.05, 0.1, 0.2],
}
gbm = GridSearchCV(estimator, param_grid)
gbm.fit(x_train, y_train)
return gbm
4.3 切分数据集(Train,Val)进行模型训练,评价和预测
## Split data with val
x_train,x_val,y_train,y_val = train_test_split(X_data,Y_data,test_size=0.3)
print('Train lgb...')
model_lgb = build_model_lgb(x_train,y_train)
val_lgb = model_lgb.predict(x_val)
MAE_lgb = mean_absolute_error(y_val,val_lgb)
print('MAE of val with lgb:',MAE_lgb)
print('Predict lgb...')
model_lgb_pre = build_model_lgb(X_data,Y_data)
subA_lgb = model_lgb_pre.predict(X_test)
print('Sta of Predict lgb:')
Sta_inf(subA_lgb)
Train lgb...
MAE of val with lgb: 685.4365823513536
Predict lgb...
Sta of Predict lgb:
_min -519.1502598641224
_max: 88575.10877210615
_mean 5922.982425989068
_ptp 89094.25903197027
_std 7377.297141258001
_var 54424513.11041347
print('Train xgb...')
model_xgb = build_model_xgb(x_train,y_train)
val_xgb = model_xgb.predict(x_val)
MAE_xgb = mean_absolute_error(y_val,val_xgb)
print('MAE of val with xgb:',MAE_xgb)
print('Predict xgb...')
model_xgb_pre = build_model_xgb(X_data,Y_data)
subA_xgb = model_xgb_pre.predict(X_test)
print('Sta of Predict xgb:')
Sta_inf(subA_xgb)
Train xgb...
MAE of val with xgb: 705.3490605572383
Predict xgb...
Sta of Predict xgb:
_min -90.51186
_max: 88906.555
_mean 5925.287
_ptp 88997.07
_std 7369.0444
_var 54302816.0
4.4 进行两模型的结果加权融合
## 这里我们采取了简单的加权融合的方式
val_Weighted = (1-MAE_lgb/(MAE_xgb+MAE_lgb))*val_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*val_xgb
val_Weighted[val_Weighted<0]=10 # 由于我们发现预测的最小值有负数,而真实情况下,price为负是不存在的,由此我们进行对应的后修正
print('MAE of val with Weighted ensemble:',mean_absolute_error(y_val,val_Weighted))
MAE of val with Weighted ensemble: 680.3431035587981
sub_Weighted = (1-MAE_lgb/(MAE_xgb+MAE_lgb))*subA_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*subA_xgb
## 查看预测值的统计进行
plt.hist(Y_data)
plt.show()
plt.close()

4.5 输出结果
sub = pd.DataFrame()
sub['SaleID'] = X_test.index
sub['price'] = sub_Weighted
sub.to_csv('./sub_Weighted.csv',index=False)
sub.head()
| SaleID | price | |
|---|---|---|
| 0 | 0 | 39005.192073 |
| 1 | 1 | 384.560646 |
| 2 | 2 | 7818.745048 |
| 3 | 3 | 11812.956312 |
| 4 | 4 | 566.835466 |
继续思考与学习
为什么删除掉某些列,画图观察某些列和最终价格的关系
价格与saleID(价格与交易名称也可仿照画出):
# -*- coding: UTF-8 -*-
plt.scatter(Train_data.SaleID, Train_data.price)
plt.ylabel("price") # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title("saleid")
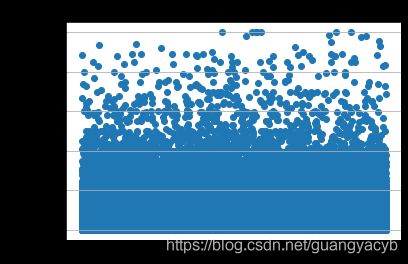
可以看到没有明显规律
价格与注册时间(creatDate类似分析):
# -*- coding: UTF-8 -*-
plt.scatter(Train_data.regDate, Train_data.price)
plt.ylabel("price") # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title("regDate")
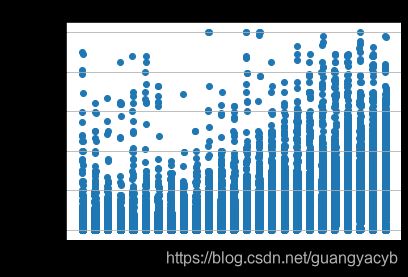
这里看到越新的车子价格有递增的趋势,是否要删掉该特征值得商榷
价格与销售个体
# -*- coding: UTF-8 -*-
plt.scatter(Train_data.seller, Train_data.price)
plt.ylabel("price") # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title("seller")
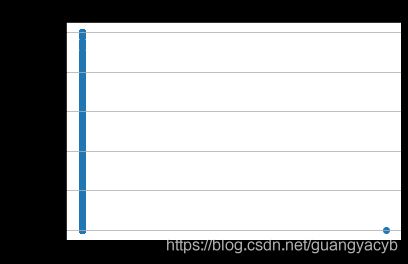
可以看到个体销售基本占据了所有,而且价格分布也是比较广泛,所以不适合作为特征。
价格与车身类型(燃油类型类似)
# -*- coding: UTF-8 -*-
plt.scatter(Train_data.bodyType, Train_data.price)
plt.ylabel("price") # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title("bodyType")

缺失值有没有更好的处理方法
从数据看到缺失值的列有:
model 149999 non-null float64
bodyType 145494 non-null float64
fuelType 141320 non-null float64
gearbox 144019 non-null float64
只有gearbox保留了,看下gearbox的分布:
# -*- coding: UTF-8 -*-
plt.scatter(Train_data.gearbox, Train_data.price)
plt.ylabel("price") # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title("gearbox")
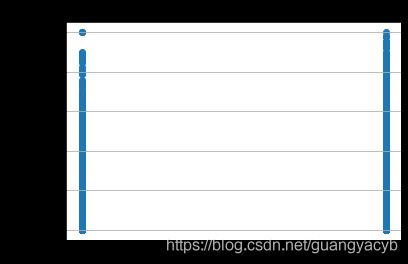
这里看到变速箱在(0,1)之间,而缺失值却用-1来补,会不会有问题?
Train_data.price[Train_data.gearbox == 0].plot(kind='kde')
Train_data.price[Train_data.gearbox == 1].plot(kind='kde')
plt.xlabel("price")# plots an axis lable
plt.ylabel("proba")
plt.legend(('auto:1', 'manual:0'),loc='best') # sets our legend for our graph.
这里是不同变速箱的价格分布

xgb和lgb算法学习
xgboost 学习:提升树(boosting tree)(含公式推导)
- 交叉验证的使用,用于选择模型的参数
- 用其他回归方法尝试
Datawhale赛事专题学习资料
零基础入门数据挖掘 - 二手车交易价格预测赛事专题分享
ps:供大家参考学习,具体还需要亲身实践
Baseline方案
基本方案介绍,提供方式notebook及视频讲解。
点此直达
从0到1打比赛流程
赛题理解、数据分析、特征工程、模型训练等通用流程进行学习,提供方式notebook或视频。
- 赛题理解
- 数据分析
- 特征工程
- 建模调参
- 模型融合