yolov4 网络结构解析
YOLO V4 — 网络结构和损失函数解析(超级详细!) - 知乎 (zhihu.com)
1.前言
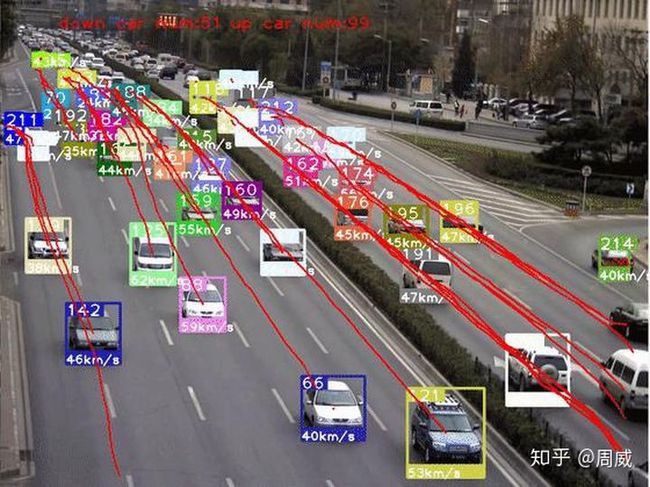
最近用YOLO V4做车辆检测,配合某一目标追踪算法实现车辆追踪+轨迹提取等功能,正好就此结合论文和代码来对YOLO V4做个解析。先放上个效果图(半成品),如下:
话不多说,现在就开始对YOLO V4进行总结。
YOLO V4的论文链接在这里,名为《YOLOv4: Optimal Speed and Accuracy of Object Detection》,相信大家也是经常看到这几个词眼:大神接棒、YOLO V4来了、Tricks 万花筒等等。
没错,通过阅读YOLO V4的原文,我觉得它更像一篇目标检测模型Tricks文献综述,可见作者在目标检测领域的知识(炼丹技术)积累之多。
从本质上,YOLO V4就是筛选了一些从YOLO V3发布至今,被用在各式各样检测器上,能够提高检测精度的tricks,并以YOLO V3为基础进行改进的目标检测模型。YOLO V4在保证速度的同时,大幅提高模型的检测精度(当然,这是相较于YOLO V3的)。

上图可以看出来,虽然检测精度不如EfficientDet这种变态,但是速度上是遥遥领先的,说明YOLO V4并没有忘记初心(速度和精度的trade off,我YOLO才是佼佼者)!
其实我是比较推荐大家看看YOLO V4原文的,就当炼丹手册来看也是挺好的,如果你懒得看,那这里我贴出来一张图,就是最终YOLO V4的炼丹配方,如下:

YOLO V4炼丹配方
这么一看,这炼丹配方多清晰呀,和YOLO V3对比,主要做了以下改变:
- 相较于YOLO V3的DarkNet53,YOLO V4用了CSPDarkNet53
- 相较于YOLO V3的FPN,YOLO V4用了SPP+PAN
- CutMix数据增强和马赛克(Mosaic)数据增强
- DropBlock正则化
- 等等
这技巧太多了,着实让人数不过来。按照惯例,我喜欢结合代码对模型进行解析,论文的话看个思路,实现的细节还是在代码中体现的较具体。原作者YOLO V4的代码是基于C++的,如下:
YOLO V4 C++(原版)github.com
这个解析起来太麻烦了,我找了个看起来不麻烦的,基于Keras+Tensorflow的,如下:
YOLO V4 Keras版本github.com
本次YOLO V4论文和代码解析也将基于这个版本的进行的啦!
后面的内容将按照以下步骤进行介绍。
- (1)YOLO V4的网络结构
- (2)YOLO V4的损失函数
- (3)一些Tricks的具体代码实现
2. YOLO V4的网络结构
这里我先给出YOLO V4的总结构图,如下(这里感谢评论区细心网友指正,之前那个结构图有点错误,现已修正)

主要有以下三部分组成
- BackBone:CSPDarknet53
- Neck:SPP+PAN
- HEAD:YOLO HEAD
接下面将逐个分析!
2.1 BackBone:CSPDarknet53
目前做检测器MAP指标的提升,都会考虑选择一个图像特征提取能力较强的backbone,且不能太大,那样影响检测的速度。YOLO V4中,则是选择了具有CSP(Cross-stage partial connections)的darknet53,而是没有选择在imagenet上跑分更高的CSPResNext50,

原因很简单,如上表,作者说:
For instance, our numerous studies demonstrate that the CSPResNext50 is
considerably better compared to CSPDarknet53 in terms of object classification on the ILSVRC2012 (ImageNet) dataset [. However, conversely, the CSPDarknet53 is
better compared to CSPResNext50 in terms of detecting objects on the MS COCO dataset
意思就是结合了在目标检测领域的精度来说,CSPDarknet53是要强于 CSPResNext50,这也告诉了我们,在图像分类上任务表现好的模型,不一定很适用于目标检测(这不是绝对的!)。
那么这个带有CSP结构的Darknet53,到底长什么样呢?如果对CSP结构感兴趣的,欢迎点击原文链接。
这里我们直接从代码上看看这个CSPDarknet53什么样子,定义如下
def darknet_body(x):
'''Darknent body having 52 Convolution2D layers'''
x = DarknetConv2D_BN_Mish(32, (3,3))(x)
x = resblock_body(x, 64, 1, False)
x = resblock_body(x, 128, 2)
x = resblock_body(x, 256, 8)
x = resblock_body(x, 512, 8)
x = resblock_body(x, 1024, 4)
return x如果把堆叠的残差单元(resblock_body)看成整体的话,那么这个结构和Darknet53以及ResNet等的确差别不大,特别是resblock_body的num_blocks为【1,2,8,8,4】和darknet53一模一样。
那么我们解析一下resblock_body的定义,如下:
def resblock_body(x, num_filters, num_blocks, all_narrow=True):
'''A series of resblocks starting with a downsampling Convolution2D'''
# Darknet uses left and top padding instead of 'same' mode
preconv1 = ZeroPadding2D(((1,0),(1,0)))(x)
preconv1 = DarknetConv2D_BN_Mish(num_filters, (3,3), strides=(2,2))(preconv1)
shortconv = DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (1,1))(preconv1)
mainconv = DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (1,1))(preconv1)
for i in range(num_blocks):
y = compose(
DarknetConv2D_BN_Mish(num_filters//2, (1,1)),
DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (3,3)))(mainconv)
mainconv = Add()([mainconv,y])
postconv = DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (1,1))(mainconv)
route = Concatenate()([postconv, shortconv])
return DarknetConv2D_BN_Mish(num_filters, (1,1))(route)这么一看,和传统的ResBlock差别就出来了,为了大家更清晰地了解结构,我把这个残差单元的结构绘制出来,如下:

对照代码和上面的图片,可以比较清晰地看出来这个CSP残差单元和DarkNet/ResNet的残差单元的区别了。当然了,图上的DarknetConv2D_BN_Mish模块定义如下
- (1) DarknetConv2D_BN_Mish
def DarknetConv2D_BN_Mish(*args, **kwargs):
"""Darknet Convolution2D followed by BatchNormalization and LeakyReLU."""
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
Mish())- (2) DarknetConv2D
def DarknetConv2D(*args, **kwargs):
"""Wrapper to set Darknet parameters for Convolution2D."""
darknet_conv_kwargs = {}
darknet_conv_kwargs['kernel_initializer'] = keras.initializers.RandomNormal(mean=0.0, stddev=0.01)
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)至此,YOLO V4的backbone部分就讲解完毕了。
2.2 Neck:SPP+PAN & Head:YOLO HEAD
目标检测模型的Neck部分主要用来融合不同尺寸特征图的特征信息。常见的有MaskRCNN中使用的FPN等,这里我们用EfficientDet论文中的一张图来进行说明。

可见,随着人们追求检测器在COCO数据集上的MAP指标,Neck部分也是出了很多花里胡哨的结构呀。
本文中的YOLO V4就是用到了SPP(Spatial pyramid pooling)+PAN(Path Aggregation Network,上图的结构b)。
在YOLO V4 Keras代码中,通常将YOLO HEAD(图片上的橙色块)紧接在SSP+PAN后面。为了便于说明,这里我们根据总图上的process1-5与三个YOLO HEAD ,对SSP+PAN+YOLO HEAD 部分进行解析。
(1) 其中process1的代码实现为:
y19 = DarknetConv2D_BN_Leaky(512, (1,1))(darknet.output)
y19 = DarknetConv2D_BN_Leaky(1024, (3,3))(y19)
y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)
maxpool1 = MaxPooling2D(pool_size=(13,13), strides=(1,1), padding='same')(y19) #(19,19)
maxpool2 = MaxPooling2D(pool_size=(9,9), strides=(1,1), padding='same')(y19) #(19,19)
maxpool3 = MaxPooling2D(pool_size=(5,5), strides=(1,1), padding='same')(y19) #(19,19)
y19 = Concatenate()([maxpool1, maxpool2, maxpool3, y19])
y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)
y19 = DarknetConv2D_BN_Leaky(1024, (3,3))(y19)
y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)显而易见,该进程接受CSPDarknet53最终的输出,返回变量y19(如总图上process1所示),这里我们也给出图示,如下:

Process1
(2) process2 代码如下
y19_upsample = compose(DarknetConv2D_BN_Leaky(256, (1,1)), UpSampling2D(2))(y19)
#38x38 head
y38 = DarknetConv2D_BN_Leaky(256, (1,1))(darknet.layers[204].output)
y38 = Concatenate()([y38, y19_upsample])
y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)
y38 = DarknetConv2D_BN_Leaky(512, (3,3))(y38)
y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)
y38 = DarknetConv2D_BN_Leaky(512, (3,3))(y38)
y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)即先将上述的y19进行上采样至大小38x38,然后再和CSPDarknet53的204层输出进行堆叠,最后通过一系列DarknetConv2D_BN_Leaky模块,获得特征图y38。
(3) process3
process3的代码接受y_38上采样后的特征图 y38_upsample以及darknet网络的第131层输出作为输入,从而获得特征图y_38,如下:
y38_upsample = compose(DarknetConv2D_BN_Leaky(128, (1,1)), UpSampling2D(2))(y38)
y76 = DarknetConv2D_BN_Leaky(128, (1,1))(darknet.layers[131].output)
y76 = Concatenate()([y76, y38_upsample])(4)YOLO HEAD 1
紧接在process3之后,代码中使用简单的5+2层卷积层对上面的y76进行输出。其实这里的卷积层就是图中橙色区域YOLO HEAD1 ,在后面的y38_output和y19_output的输出过程中仍能够看到。其中代码如下:
#YOLO HEAD 1
y76 = DarknetConv2D_BN_Leaky(128, (1,1))(y76)
y76 = DarknetConv2D_BN_Leaky(256, (3,3))(y76)
y76 = DarknetConv2D_BN_Leaky(128, (1,1))(y76)
y76 = DarknetConv2D_BN_Leaky(256, (3,3))(y76)
y76 = DarknetConv2D_BN_Leaky(128, (1,1))(y76)
#76x76 output
y76_output = DarknetConv2D_BN_Leaky(256, (3,3))(y76)
y76_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(y76_output)该网络最后使用1x1卷积输出最大的一张特征图y76_output,维度为(76,76,num_anchor*(num_classes+5))。对应结构图中最大的输出特征图(最右边的淡蓝色特征图)。
(5) process4的代码如下:
#38x38 output
y76_downsample = ZeroPadding2D(((1,0),(1,0)))(y76)
y76_downsample = DarknetConv2D_BN_Leaky(256, (3,3), strides=(2,2))(y76_downsample)
y38 = Concatenate()([y76_downsample, y38])这一步骤比较关键,PAN和FPN的差异在于,FPN是自顶向下的特征融合,PAN在FPN的基础上,多了个自底向上的特征融合。具体自底向上的特征融合,就是process4完成的,可以看到该步骤先将y76下采样至38x38大小,再和y38堆叠,作为YOLO HEAD2的输入。
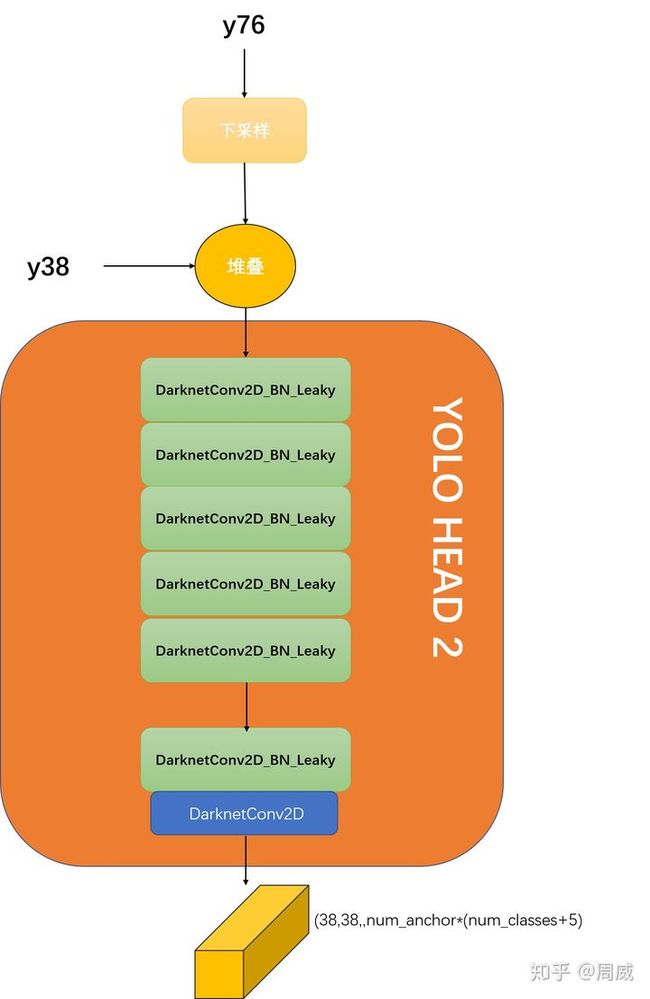
(6)YOLO HEAD 2
类似于YOLO HEAD 1,YOLO HEAD2也进行一系列卷积运算,获得维度大小为(38,38,num_anchor*(num_classes+5))的输出y38_output,其中代码如下:
#YOLO HEAD 2
y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)
y38 = DarknetConv2D_BN_Leaky(512, (3,3))(y38)
y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)
y38 = DarknetConv2D_BN_Leaky(512, (3,3))(y38)
y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)
y38_output = DarknetConv2D_BN_Leaky(512, (3,3))(y38)
y38_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(y38_output)其中process4和YOLO HEAD2如下图所示。
(7) Process5代码如下
#19x19 output
y38_downsample = ZeroPadding2D(((1,0),(1,0)))(y38)
y38_downsample = DarknetConv2D_BN_Leaky(512, (3,3), strides=(2,2))(y38_downsample)
y19 = Concatenate()([y38_downsample, y19])Process5和process4进程类似,不多赘述。后面接上YOLO HEAD 3。
(8)YOLO HEAD 3
和YOLO HEAD 1以及YOLO HEAD 2定义几乎类似,YOLO HEAD 3定义如下:
y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)
y19 = DarknetConv2D_BN_Leaky(1024, (3,3))(y19)
y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)
y19 = DarknetConv2D_BN_Leaky(1024, (3,3))(y19)
y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)
y19_output = DarknetConv2D_BN_Leaky(1024, (3,3))(y19)
y19_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(y19_output)YOLO HEAD 3输出为(19,19,num_anchor*(num_classes+5))的特征图y19_output。
3. YOLO V4的损失函数
YOLO V4原文中提到,在进行bounding box regression的时候,以往的目标检测模型(比如YOLO V3)等,都是直接根据预测框和真实框的中心点坐标以及宽高信息设定MSE(均方误差)损失函数或者BCE损失函数的。为了方便大家理解,下面给出了YOLO V3的总损失函数(前三行分别为BCE和MSE损失函数)。
可以看出,前两行就是用在bounding box regression的对位置x,y的损失函数(采用了BCE),第三行就是对宽高w,h的损失函数(采用了MSE)。有关该损失函数的具体解析可以见我文章《YOLO V3 深度解析 (下)》,这里就不进行赘述。
4.1 IOU损失函数理论部分
鉴于MSE存在的一些问题,比如原文中提到
However, to directly estimate the coordinate values of each point of the BBox is to treat these points as independent variables, but in fact does not consider the integrity of the object itself.
意思就是MSE损失函数将检测框中心点坐标和宽高等信息作为独立的变量对待的,但是实际上他们之间是有关系的。从直观上来说,框的中心点和宽高的确存在着一定的关系。所以解决方法是使用IOU损失代替MSE损失。
接着作者就IOU损失依次提到了以下的一些的损失函数。
- (1)IOU损失
- (2)GIOU损失
- (3)DIOU损失
- (4)CIOU损失
(1)IOU损失
其中IOU损失定义非常简单,即1与预测框A和真实框B之间交并比的差值
但是这样该损失函数会有一些问题,该损失函数只在bounding box重叠的时候才管用,在他们没有重叠情况下,将不会提供滑动梯度。(这句话摘自论文《Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression》)
(2)GIOU损失
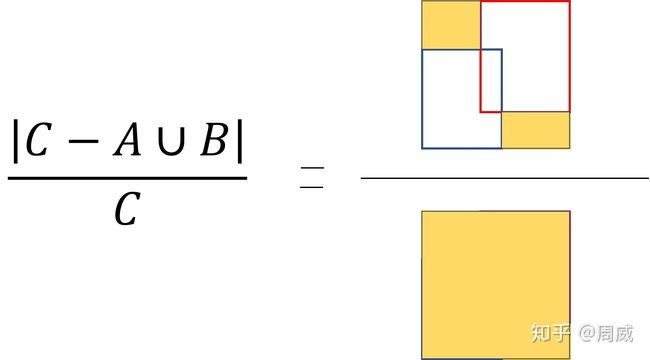
其实GIOU的全称叫做 :generalized IoU loss。提出来是为了缓解上述IOU损失在检测框不重叠时出现的梯度问题。定义也是比较简单的,就在在原来的IOU损失的基础上加上一个惩罚项,公式如下:
上式中A是预测框,B是真实框,C是A和B的最小包围框,A,B,C的关系具体如下图所示。

A,B,C含义
那么该惩罚项的意思就是下图右边黄色区域的比值。
惩罚项含义
虽然GIOU可以解决检测框非重叠造成的梯度消失问题,但是他还存在以下的限制,这里我们依旧是参考CIOU论文中的内容。

GIOU回归过程
上图中绿色为真实框,黑色为先验框Anchor,蓝色为预测框。预测框是以先验框为基础进行位置移动和大小缩放的。可以看出来,GIOU首先尝试增大预测框的大小,使得它能够与真实框有所重叠(如上图中间所示),然后才能进行上述公式中 的计算。那么这样做的话,会消耗大量的时间在预测框尝试与真实框接触上,这会影响损失的收敛速度。所以DIOU和GIOU的提出解决了上述GIOU的问题。
(3)DIOU
DIOU和CIOU都出自论文《Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression》。作者说他直接在IOU损失的基础上加了一个简单的惩罚项,用来最小化两个检测框中心点的标准化距离,这样可以加速损失的收敛过程。如下图所示为GIOU和DIOU的对比。
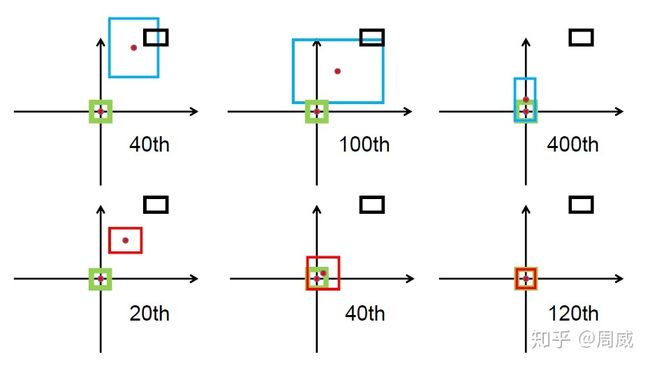
红色框是DIOU损失中的预测框。可以很明显的看出,DIOU的收敛速度较GIOU更快。
那么有关DIOU的定义是怎么样的呢?下面给出公式定义:
相比于IOU损失,DIOU损失也多出了一个惩罚项 。该惩罚项具体的参数含义为
- A : 预测框 B:真实框
- : 预测框中心点坐标 :真实框中心点坐标
- 是欧式距离的计算
- c 为 A , B 最小包围框的对角线长度
我给出了下图,便于大家理解。

所以两个框距离越远,DIOU越接近2,距离越近,DIOU越接近0。
提出DIOU还不够,作者进一步地提出了CIOU(Complete IoU Loss)。
(4)CIOU
CIOU作者考虑的更加全面一些,DIOU考虑到了两个检测框的中心距离。而CIOU考虑到了三个几何因素,分别为
- (1)重叠面积
- (2)中心点距离
- (3)长宽比
这里仔细观察,会发现,CIOU比DIOU多了一个长宽比的信息,那么CIOU的公式定义如下:
那么这个 对长宽比的惩罚项了。论文中提到, 是一个正数, 用来测量长宽比的一致性(v measures the consistency of aspect ratio)。具体定义如下:


上述公式中,参数说明如下:
- 和 为真实框的宽、高
- 和 为预测框的宽、高
若真实框和预测框的宽高相似,那么 为0,该惩罚项就不起作用了。所以很直观地,这个惩罚项作用就是控制预测框的宽高能够尽可能快速地与真实框的宽高接近。
那么至此,有关YOLO V4损失函数的理论部分就说完了。
4.2 IOU损失函数的实战部分
说完了上述四个IOU理论部分,我们回归其在YOLO V4框架中的位置并进行解析。结合keras的代码,如下为CIOU损失函数的定义。
def bbox_ciou(boxes1, boxes2):
'''
计算ciou = iou - p2/c2 - av
:param boxes1: (8, 13, 13, 3, 4) pred_xywh
:param boxes2: (8, 13, 13, 3, 4) label_xywh
:return:
举例时假设pred_xywh和label_xywh的shape都是(1, 4)
'''
# 变成左上角坐标、右下角坐标
boxes1_x0y0x1y1 = tf.concat([boxes1[..., :2] - boxes1[..., 2:] * 0.5,
boxes1[..., :2] + boxes1[..., 2:] * 0.5], axis=-1)
boxes2_x0y0x1y1 = tf.concat([boxes2[..., :2] - boxes2[..., 2:] * 0.5,
boxes2[..., :2] + boxes2[..., 2:] * 0.5], axis=-1)
'''
逐个位置比较boxes1_x0y0x1y1[..., :2]和boxes1_x0y0x1y1[..., 2:],即逐个位置比较[x0, y0]和[x1, y1],小的留下。
比如留下了[x0, y0]
这一步是为了避免一开始w h 是负数,导致x0y0成了右下角坐标,x1y1成了左上角坐标。
'''
boxes1_x0y0x1y1 = tf.concat([tf.minimum(boxes1_x0y0x1y1[..., :2], boxes1_x0y0x1y1[..., 2:]),
tf.maximum(boxes1_x0y0x1y1[..., :2], boxes1_x0y0x1y1[..., 2:])], axis=-1)
boxes2_x0y0x1y1 = tf.concat([tf.minimum(boxes2_x0y0x1y1[..., :2], boxes2_x0y0x1y1[..., 2:]),
tf.maximum(boxes2_x0y0x1y1[..., :2], boxes2_x0y0x1y1[..., 2:])], axis=-1)
# 两个矩形的面积
boxes1_area = (boxes1_x0y0x1y1[..., 2] - boxes1_x0y0x1y1[..., 0]) * (
boxes1_x0y0x1y1[..., 3] - boxes1_x0y0x1y1[..., 1])
boxes2_area = (boxes2_x0y0x1y1[..., 2] - boxes2_x0y0x1y1[..., 0]) * (
boxes2_x0y0x1y1[..., 3] - boxes2_x0y0x1y1[..., 1])
# 相交矩形的左上角坐标、右下角坐标,shape 都是 (8, 13, 13, 3, 2)
left_up = tf.maximum(boxes1_x0y0x1y1[..., :2], boxes2_x0y0x1y1[..., :2])
right_down = tf.minimum(boxes1_x0y0x1y1[..., 2:], boxes2_x0y0x1y1[..., 2:])
# 相交矩形的面积inter_area。iou
inter_section = tf.maximum(right_down - left_up, 0.0)
inter_area = inter_section[..., 0] * inter_section[..., 1]
union_area = boxes1_area + boxes2_area - inter_area
iou = inter_area / (union_area + K.epsilon())
# 包围矩形的左上角坐标、右下角坐标,shape 都是 (8, 13, 13, 3, 2)
enclose_left_up = tf.minimum(boxes1_x0y0x1y1[..., :2], boxes2_x0y0x1y1[..., :2])
enclose_right_down = tf.maximum(boxes1_x0y0x1y1[..., 2:], boxes2_x0y0x1y1[..., 2:])
# 包围矩形的对角线的平方
enclose_wh = enclose_right_down - enclose_left_up
enclose_c2 = K.pow(enclose_wh[..., 0], 2) + K.pow(enclose_wh[..., 1], 2)
# 两矩形中心点距离的平方
p2 = K.pow(boxes1[..., 0] - boxes2[..., 0], 2) + K.pow(boxes1[..., 1] - boxes2[..., 1], 2)
# 增加av。加上除0保护防止nan。
atan1 = tf.atan(boxes1[..., 2] / (boxes1[..., 3] + K.epsilon()))
atan2 = tf.atan(boxes2[..., 2] / (boxes2[..., 3] + K.epsilon()))
v = 4.0 * K.pow(atan1 - atan2, 2) / (math.pi ** 2)
a = v / (1 - iou + v)
ciou = iou - 1.0 * p2 / enclose_c2 - 1.0 * a * v
return ciou以上,代码原作者也是做了一个非常详细的代码注释呀。可以看出,该函数定义和理论部分一致,特别是最后一行代码,和我们理论部分说的一模一样哈。
ciou = iou - 1.0 * p2 / enclose_c2 - 1.0 * a * v该CIOU函数定义被用在求解总损失函数上了,我们知道YOLO V3的损失函数主要分为三部分,分别为:
- (1)bounding box regression损失
- (2)置信度损失
- (3)分类损失
YOLO V4相较于YOLO V3,只在bounding box regression做了创新,用CIOU代替了MSE,其他两个部分没有做实质改变。其代码分别定义如下:
(1)bounding box regression损失
def loss_layer(conv, pred, label, bboxes, stride, num_class, iou_loss_thresh):
conv_shape = tf.shape(conv)
batch_size = conv_shape[0]
output_size = conv_shape[1]
input_size = stride * output_size
conv = tf.reshape(conv, (batch_size, output_size, output_size,
3, 5 + num_class))
conv_raw_prob = conv[:, :, :, :, 5:]
pred_xywh = pred[:, :, :, :, 0:4]
pred_conf = pred[:, :, :, :, 4:5]
label_xywh = label[:, :, :, :, 0:4]
respond_bbox = label[:, :, :, :, 4:5]
label_prob = label[:, :, :, :, 5:]
ciou = tf.expand_dims(bbox_ciou(pred_xywh, label_xywh), axis=-1) # (8, 13, 13, 3, 1)
input_size = tf.cast(input_size, tf.float32)
# 每个预测框xxxiou_loss的权重 = 2 - (ground truth的面积/图片面积)
bbox_loss_scale = 2.0 - 1.0 * label_xywh[:, :, :, :, 2:3] * label_xywh[:, :, :, :, 3:4] / (input_size ** 2)
ciou_loss = respond_bbox * bbox_loss_scale * (1 - ciou) # 1. respond_bbox作为mask,有物体才计算xxxiou_loss(2)置信度损失
# 2. respond_bbox作为mask,有物体才计算类别loss
prob_loss = respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=label_prob, logits=conv_raw_prob)(3)分类损失
# 3. xxxiou_loss和类别loss比较简单。重要的是conf_loss,是一个focal_loss
# 分两步:第一步是确定 grid_h * grid_w * 3 个预测框 哪些作为反例;第二步是计算focal_loss。
expand_pred_xywh = pred_xywh[:, :, :, :, np.newaxis, :] # 扩展为(?, grid_h, grid_w, 3, 1, 4)
expand_bboxes = bboxes[:, np.newaxis, np.newaxis, np.newaxis, :, :] # 扩展为(?, 1, 1, 1, 150, 4)
iou = bbox_iou(expand_pred_xywh, expand_bboxes) # 所有格子的3个预测框 分别 和 150个ground truth 计算iou。 (?, grid_h, grid_w, 3, 150)
max_iou = tf.expand_dims(tf.reduce_max(iou, axis=-1), axis=-1) # 与150个ground truth的iou中,保留最大那个iou。 (?, grid_h, grid_w, 3, 1)
# respond_bgd代表 这个分支输出的 grid_h * grid_w * 3 个预测框是否是 反例(背景)
# label有物体,respond_bgd是0。 没物体的话:如果和某个gt(共150个)的iou超过iou_loss_thresh,respond_bgd是0;如果和所有gt(最多150个)的iou都小于iou_loss_thresh,respond_bgd是1。
# respond_bgd是0代表有物体,不是反例; 权重respond_bgd是1代表没有物体,是反例。
# 有趣的是,模型训练时由于不断更新,对于同一张图片,两次预测的 grid_h * grid_w * 3 个预测框(对于这个分支输出) 是不同的。用的是这些预测框来与gt计算iou来确定哪些预测框是反例。
# 而不是用固定大小(不固定位置)的先验框。
respond_bgd = (1.0 - respond_bbox) * tf.cast(max_iou < iou_loss_thresh, tf.float32)
# 二值交叉熵损失
pos_loss = respond_bbox * (0 - K.log(pred_conf + K.epsilon()))
neg_loss = respond_bgd * (0 - K.log(1 - pred_conf + K.epsilon()))
conf_loss = pos_loss + neg_loss
# 回顾respond_bgd,某个预测框和某个gt的iou超过iou_loss_thresh,不被当作是反例。在参与“预测的置信位 和 真实置信位 的 二值交叉熵”时,这个框也可能不是正例(label里没标这个框是1的话)。这个框有可能不参与置信度loss的计算。
# 这种框一般是gt框附近的框,或者是gt框所在格子的另外两个框。它既不是正例也不是反例不参与置信度loss的计算。(论文里称之为ignore)最后对上述的三个损失取个平均即可,如下
ciou_loss = tf.reduce_mean(tf.reduce_sum(ciou_loss, axis=[1, 2, 3, 4])) # 每个样本单独计算自己的ciou_loss,再求平均值
conf_loss = tf.reduce_mean(tf.reduce_sum(conf_loss, axis=[1, 2, 3, 4])) # 每个样本单独计算自己的conf_loss,再求平均值
prob_loss = tf.reduce_mean(tf.reduce_sum(prob_loss, axis=[1, 2, 3, 4])) # 每个样本单独计算自己的prob_loss,再求平均值至此,结合代码,有关YOLO V4损失函数的实战部分也就说完了!
4.小结
有关YOLO V4的网络结构和损失函数就讲到这里。感谢大家批评指正!
编辑于 01-21