如何优雅的“对战”面试官关于JVM的内存模型以及GC垃圾回收机制
知其然,先知其所以然。
这一周重构了半年前做的项目代码,简直像在看我小学的作文
,还好借此时间重构了。
所以每天都没有时间......
昨天!!!我的下一个项目需求又来鸟~~
但我还是会抽时间写技术分享的

一周一个小问题

持久层是mybaits plus,一个分页查询。
问题:自身打印的sql和返回值存在差异。
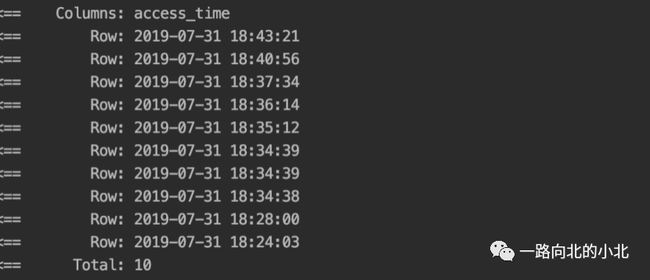
结果它给我返回全是2019-08-01的。满脸问号❓❓❓❓❓
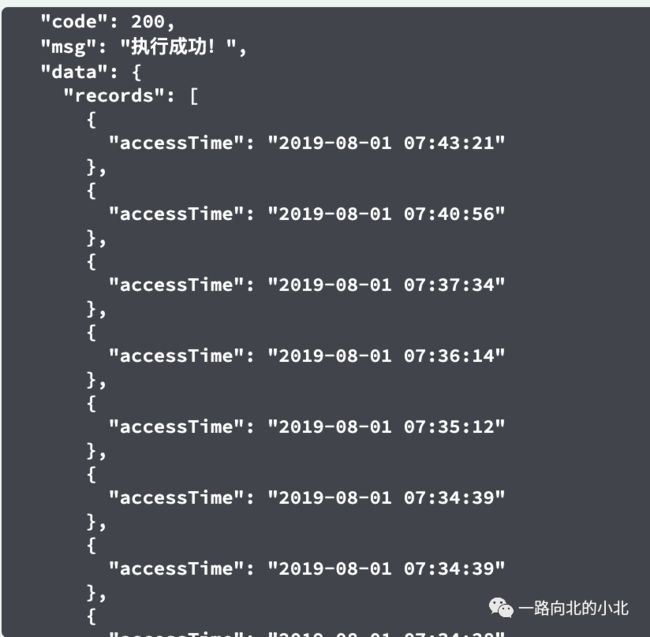
并且我还把sql放在数据库查询,也是正常的。
那这里肯定就有同学会说,接收值错误的呗。这不很明显吗
其实并没有,我直接返回的mapper.selectPage(page,wrapper),也就是没有接收值再返回.
(当然这里要提一下,如果多个地方用到同一个方法,并且这个方法是需要计算的,那还是需要定义一个变量接收值的,减少不必要的二次计算。)
再来看一下我的Model类的中,一个在数据库为DateTime类型的字段,

LocalDateTime类型,MyBatis从3.4.5版本就开始完全支持这种类型了。
同时这也是JDK8的新特性,目的就是干掉之前的Date。至于为什么,一语即可到破天机,线程安全!!
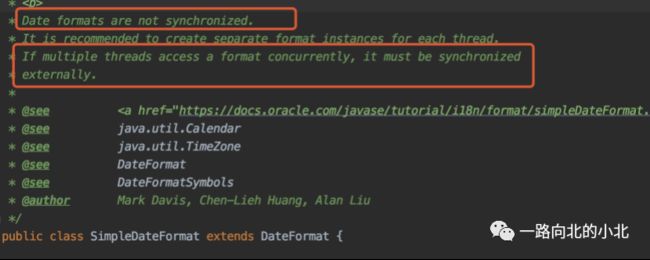
Date是非线程安全的,必须通过其它方式来保证线程安全。
而LocalDateTime是线程安全的。
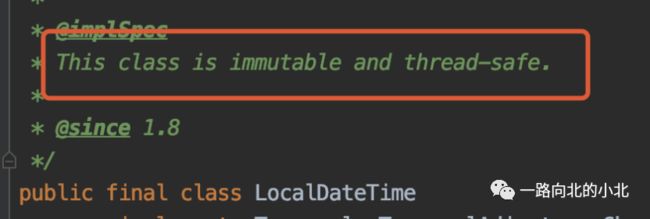
其次还有一点,Date基本上都会和SimpleDateFormat联合使用,来format格式,但SimpleDateFormat它本身也是非线程安全的。
取而代之的也是JDK8的新特性之——DateTimeFormatter
简单说完了LocalDateTime的介绍,接着来解决上面的问题,LocalDateTime默认是不包含时区信息的,会取当前服务器时间的时区。如果没有设置指定时区,mysql默认的时区UTC。
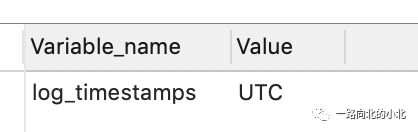
解决办法:
在配置文件中数据库连接串添加serverTimezone=GMT%2B8即可,时区转换。
JVM内存结构模型
![]()
接下来进入正题,JVM的内存结构和GC垃圾回收机制绝对是面试中重中之重,如果一个面试官上来问了这两个问题,你没有回答好,那这场面试基本就已经结束了,剩下的都是拖时长 。
。
那有的同学问了,你这么清楚,你是面试过很多人还是被很多人面试过?
emmmm.....其实都没有,我游荡在博客、掘金、牛客等等各大有技术栈的产品,也看过很多热门的面试过程分享,基本上这些问题都会被提及。
那又有的同学要问了,了解这些怎么融合在实战中,我们公司的业务最多就是CRUD外加面向百度开发。其实都一样,我有幸了解过阿里、京东、百度那产品中心可不都是CRUD,哪有那么多大数据新技术的东西做。
所以,不要觉得用不到而忽略了一些有必要学习的东西。

唠叨完毕,先看一张图,我画的应该还可以。
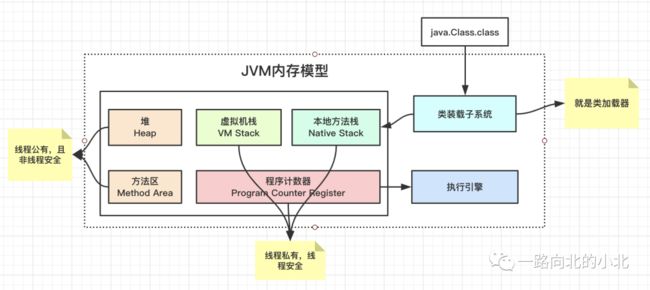
JVM内存结构就是上图中的五个区域:堆、方法区、虚拟机栈(其实也就线程栈)、本地方法栈以及程序计数器。先把类装载子系统和执行引擎放一边。
-
堆和方法区都是线程公有的,并且非线程安全。
-
线程栈、本地方法栈、程序计数器都是线程私有,并且线程安全。
内存每个区域存放的元素
堆:存放新创建的对象实例(就是new出来的对象)和数组。占用内存最大,所以也是GC垃圾回收的重点。
WfModel wfModel = new WfModel();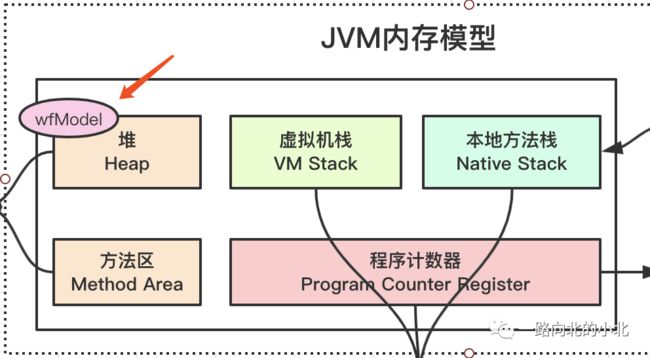
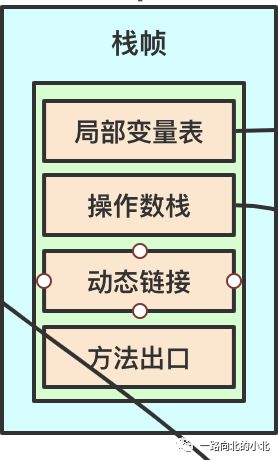
栈:准确的来说是线程栈,存放每个线程的栈帧,每个栈帧又包含局部变量表、操作数栈、动态链接、方法出口。
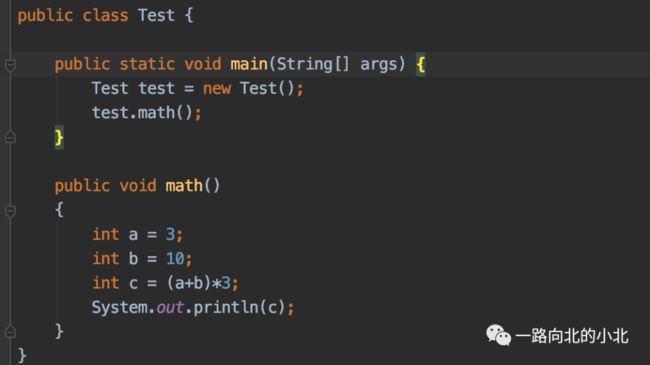
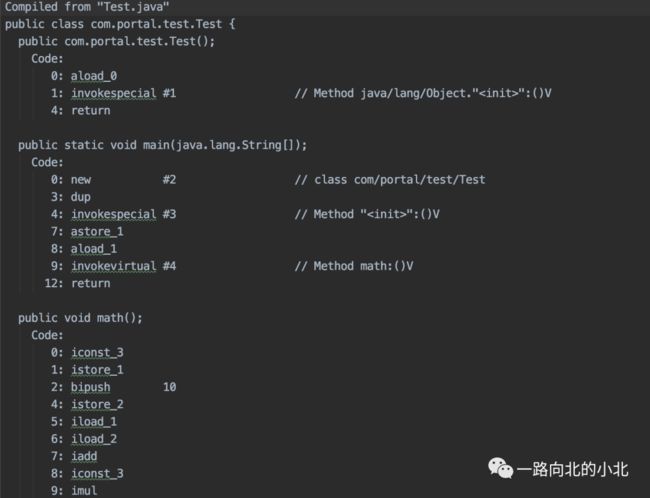
JVM执行的是编译过的class文件,二进制流的十六进制代码,没必要花时间区研究那个,我们反汇编看一下。
通过java命令 :javap -c Test.class > Test.txt ,其实这种方式也可以看个大概,只是一些指令的意思,可以在官方搜索。
局部变量表:所属的内存空间是在编译期间分配的,在方法运行期间不会改变局部变量表的大小。
操作数栈:存放的就是反汇编之后每行代码的指令,这里和寄存器很类似。寄存器是从内存里提取一条指令,而操作数栈是从JVM里取一条指令。
动态链接:存放通过类型指针找到被调用方法在jvm指令码中的内存地址指针。
方法出口:存放该方法调用者的内存地址指针。
方法区:存放常量、静态变量、加载过的类信息、编译之后的代码等等。
private int RESULT_CODE = 200;private static final String message = "成功!";
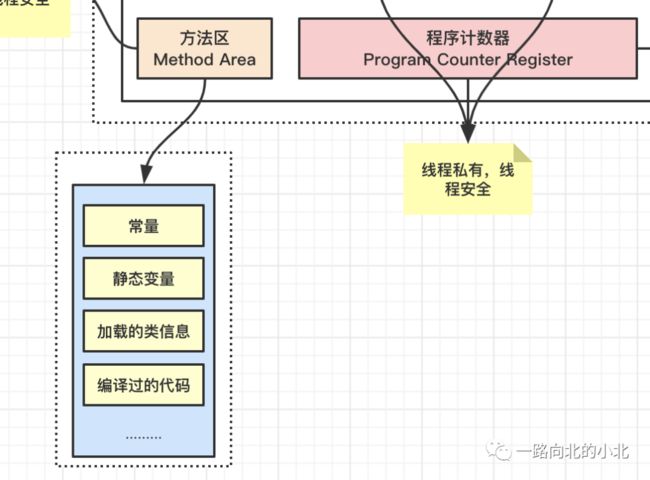
本地方法栈:功能和特点类似于栈,只不过调用的是本地方法。Java Thread.java 源码中有这么一行代码:
private native void start0();这就是本地方法,因为Java底层是C语言开发的,(底层的代码好像是在openjdk源码中,记不清了....),是与操作系统直接交互的。
程序计数器:当前线程所执行的字节码行号指示器,执行下一条将要执行的指令代码。每个线程都有自己独立的计数器,为了确保线程上下文切换后能恢复到正确的执行位置,不能每次都从头来吧?
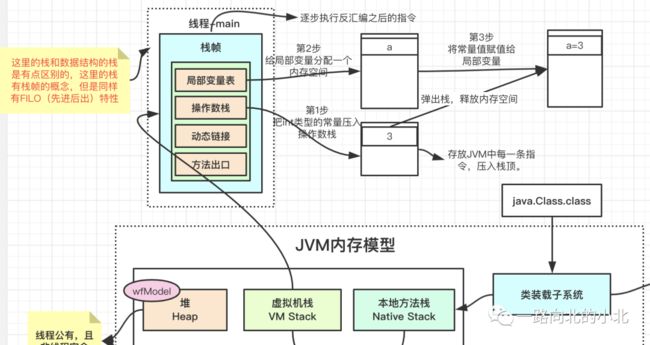
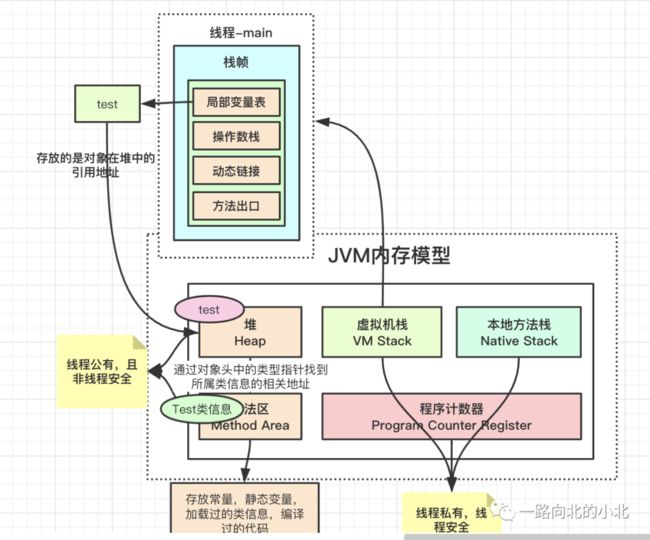
每个独立的区域说完了存放的元素,再看一下它们直接有什么关系呢?看下图
先创建一个Test对象,通常对象的实例是存放在堆中,但栈-栈帧-局部变量表中也会存放test,不过这个test存放的是对象在堆中的引用地址,也可以说指针,不然JVM怎么知道谁是谁的呢?同样的堆和方法区之间关系也存在依赖关系,JVM:“我得知道这个对象是哪个类的吧?”,对象头中其实包含很多东西的,这里只提及一个“类型指针”,堆就是通过对象头的类型指针找到所属类的地址。
GC垃圾回收机制
说完了JVM内存结构再来聊聊GC垃圾回收,首先三联问,GC回收是对什么回收?什么时候回收?怎么回收?
对什么回收?
上面提了一下,堆是整个JVM内存结构中占用内存空间最大的区域,所以GC回收主要就是针对于堆的回收。当然对于方法区也有一些回收,回收一些废弃的常量和无用的类,主要还要针对堆回收来说一说。
在什么时候回收?
首先堆分为新生代和老年代,新生代又分为Eden区和Survivor区,Survivor区又分为From和To区,文字难以理解,没关系,我又画了一幅图,简单理解一下。
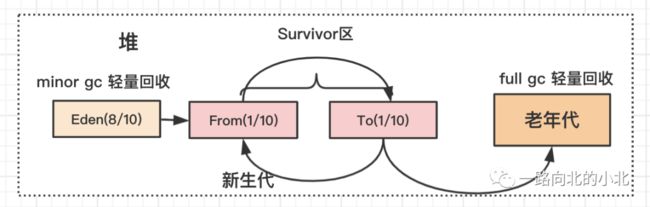
同时,堆肯定是有内存大小的限制的,不能无限的占用内存,总会有一个尽头,那最后肯定就会OOM的,所以才有了GC垃圾回收机制,将已经“死”了对象回收并释放内存空间,从而保证程序的正常使用。
在什么时候回收?
“对象已“死”(对象不在被引用并且它本身没有被其它对象引用),GC就会回收。”
“哎,那怎么才能知道这个对象是否已“死”呢?”
这里其实有两种方式,第一种方式已经被弃用了,所以也就不说了,避免增加记忆负担。就来说说第二种,可达性分析算法。
可达性分析算法:通过把一系列“GC Roots”对象作为起点,从这些节点开始向下搜索,节点经过的路径称为引用链。
“你又来这种文字游戏,又是照抄网上的东西,看不懂记不住啊!!!”
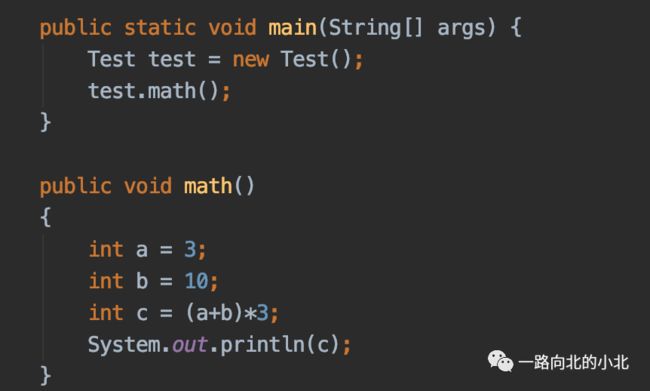
好,那就举个例子:还是按照上面的代码来看。
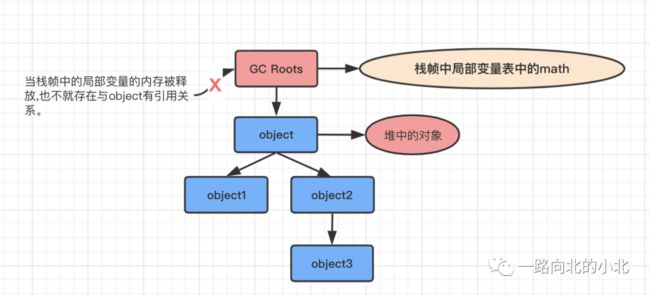
拓展小知识:
我们通常的开发中多数使用的都是强引用,就是Test test = new Test();这种方式宁愿发生OOM。也不会回收这些对象。还有一种方式叫软引用,SoftReference
怎么回收?
还是先看张我画的图,画图真的费时间。
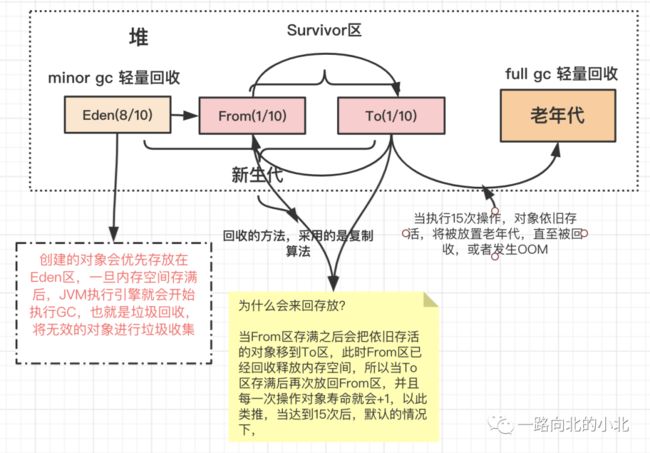
需要注意的是,一些大对象(长字符串或数组)可能会直接存放到老年代。
通过GC垃圾回收算法来进行回收,垃圾算法有三种:
-
标记-清除算法(Mark - Sweep)
-
最基础的垃圾回收算法,分为两个阶段,标记和清除
-
标记:标记出所有需要回收的对象 (可达性分析)
-
清除:清除被标记的对象所占用的空间
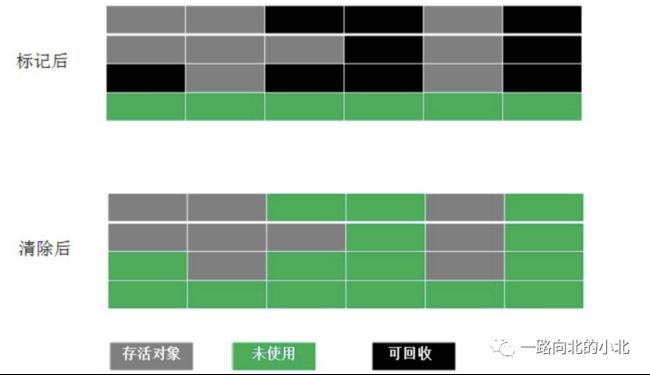
缺点:效率比较低,标记清除后会出现大量不连续的碎片,碎片太多的话导致给大对象分配内存空间时不够用而不得不触发一次GC回收
2. 复制算法—— 新生代算法
按内存容量将内存分为等大小的两块,每次只使用其中的一块,当这一块内存满后将还存活的对象复制到另一块上,把已使用的内存清除掉。
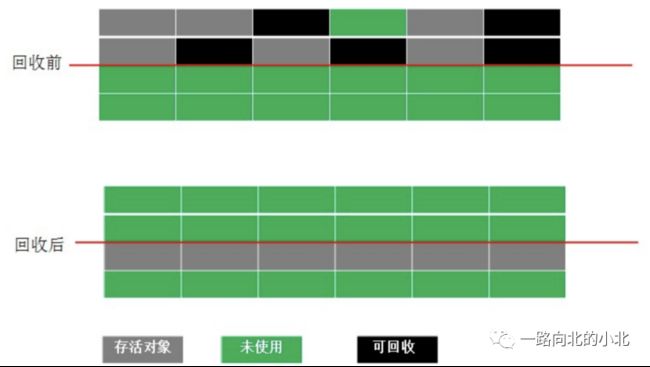
缺点:这种算法虽然实现简单,内存效率高,不易产生碎片,但是最大的问题是原有内存空间被压缩了一半,且对象存活增多的话,此算法会大大的降低。
3.标记-整理 ——老年代算法
标记:标记所有需要回收的对象
整理:将存活对象移向内存一端,然后清除其它边界外的对象。
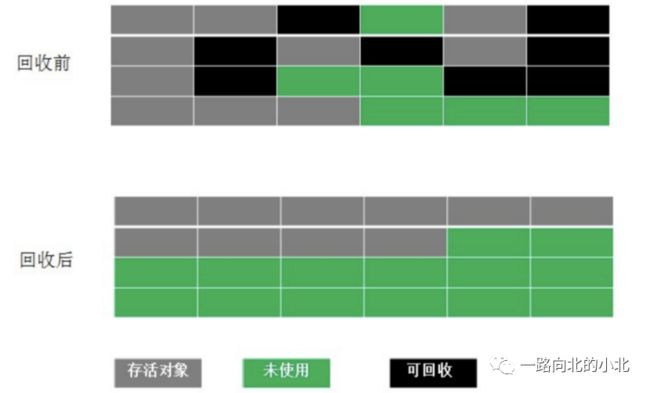 这些算法针对堆的结构来理解其实很有记忆点。
这些算法针对堆的结构来理解其实很有记忆点。
最后我写了一个死循环,不断的创建对象,然后通过java自带的监视工具(jvisualvm)看一下JVM内存空间的占用情况。(这个工具也是jvm调优常用的工具)
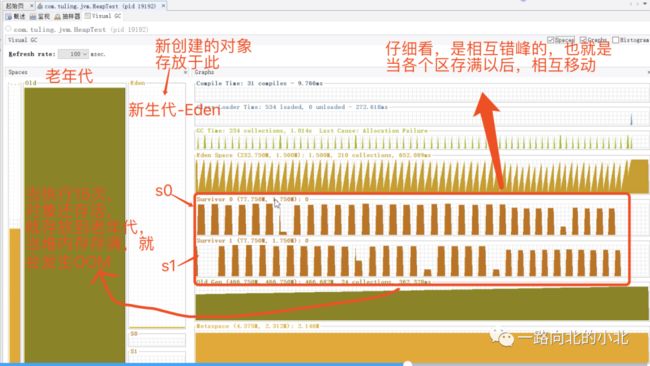
好啦,本篇到此就结束啦,不足之处欢迎指出,祝各位周末愉快~
THE END
![]()