第6章 关系数据库理论
目录
6.1 问题的提出
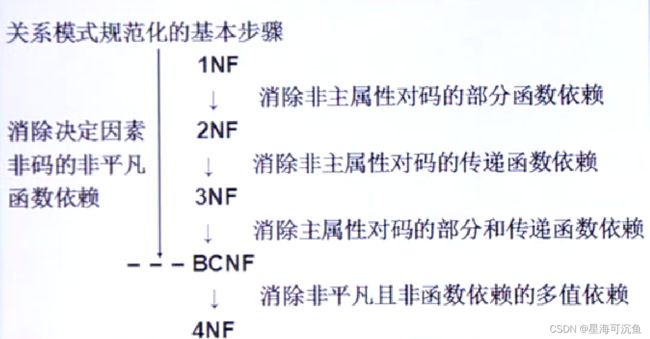
6.2 规范化
6.2.1 函数依赖
6.2.2 码
6.2.3 范式(重点内容)
6.2.4 2NF
6.2.5 3NF
6.2.6 BCNF
6.2.7 多值依赖
6.2.8 4NF
6.2.9 规范化小结
ps:
关于理论的部分,主要是来介绍 怎样去创建一个好的(运行效率高、数据冗余低)数据库。
6.1 问题的提出
1.关系模式的表示
关系模式有五个部分组成,是一个五元组:R(U,D,DOM,F)。
(1)关系名R是符号化的元组语义。
(2)U为一组属性。
(3)D为属性组U中的属性所来自的域。
(4)DOM为属性到域的映射。
(5)F为属性组U上的一组数据依赖。
ps:
R就是关系的名字,比如说以前的 Student( ...... )、Course( ...... )、SC( ...... )等。
U:SC( U、D......),这个U就代表了:Sno、Cno、Grade这些属性。
D:代表的是 取值范围,比如说 Sno 的取值范围是 整数 等等。
DOM:具体到取哪个的值,比如说 Sno=100,那么就称为 100是Sno属性到整数这个取值范围的映射。
【说明】
- 由于D、DOM与模式设计关系不大,因此在本章中把关系模式看做一个三元组:R
。 - 当且仅当U上的一个关系r满足F时,r称为关系模式R
的一个关系。 - 作为一个二维表(有行有列的表),关系要符合一个最基本的条件:每个分量必须是不可分开的数据项。满足了这个条件的关系模式就属于第一范式(1NF)。
 左边的就符合要求,是1NF;右边的不符合要求,不是1NF(要改成1NF可以把 价格去掉,数量、单价往上提——懂得都懂)。
左边的就符合要求,是1NF;右边的不符合要求,不是1NF(要改成1NF可以把 价格去掉,数量、单价往上提——懂得都懂)。
2.数据依赖(F)
数据依赖 是一个 关系内部 属性与属性之间的 一种约束关系,是通过 属性间 值的相等于否 体现出来的 数据间相互联系。
ps:
知道学生的学号Sno,可以推出学生的姓名,即 Sno->Sname;
知道Cno,可以推出Cname。
Sname和Cname 依赖于 Sno和Cno。
数值依赖的主要类型:
函数依赖(简称FD)、多值依赖(简称MVD)

3.函数依赖在现实生活中的体现
【例】描述一个学生关系,可以有学号、姓名、系名等属性。
一个学号只对应一个学生,一个学生只能在一个系里学习,“学号”确定后,学生的姓名及所在系的值就被唯一确定。

【例】建立一个描述 学校教务 的数据库。涉及的对象包括:学生的学号(Sno)、所在系(Sdept)、系主任姓名(Mname)、课程号(Cno)、成绩(Grade)。
假设学校教务的数据库模式 用一个单一的关系模式Student来表示,则该关系模式的属性集合为:
U={ Sno,Sdept,Mname,Cno,Grade } 。
现实世界的已知事实(语义):
- 一个系有若干学生,但一个学生只属于一个系;
- 一个系只有一名系主任;
- 一个学生可以选多门课,每门课有多个学生选修;
- 每个学生学习每一门课有一个成绩。
由此可以得到属性组U上的一组函数依赖F:
F={ Sno->Sdept,Sdept->Mname,(Sno,Cno) ->Grade }

4.函数依赖存在的问题
关系模式Student
(1)数据冗余
浪费大量的存储空间,每一个系主任的姓名重复出现,重复次数与该系所有学生的所有课程成绩出现次数相同。
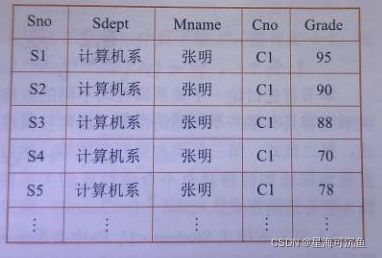
(2)更新异常
数据冗余,更新数据时,维护数据完整性代价大。比如说 某系更换系主任后,必须修改与该系学生有关的每一个元组,否则会出现数据不一致的异常。
(3)插入异常
如果一个系刚成立,尚无学生,则无法把这个系及其系主任的信息存入数据库。
(4)删除异常
如果某个系的学生都毕业了,则在删除该系学生信息的同时,这个系及其系主任的信息也丢掉了。
【说明】
- Student关系模式不是一个好的模式。一个“好”的模式应该不会发生插入异常、删除异常和更新异常,数据冗余应尽量少。
- 存在以上问题的原因 是由于在模式中的某些数据依赖引起的。
- 解决方法是用 规范化理论 改造关系模式 来消除其中不合适的数据依赖。
5.函数依赖的解决方式
把这个单一的模式分成三个关系模式:
S(Sno,Sdept,Sno->Sdept);
SC(Sno,Cno,Grade,(Sno,Cno)->Grade);
DEPT(Sdept,Mname,Sdept->Mname);
ps:
以上的三个就是关系模式 R(U,F)的具体实例。
我们在建立数据库的时候,一定要把一类事单独建一个表,不要让多种事情混杂在一个表里面。
这三个模式都不会发生插入异常、删除异常的问题,数据的冗余也得到了控制。
6.2 规范化
ps:
因为在设计数据库的时候没有设计好,存在各种各样的函数依赖,导致数据冗余度大,插入异常、删除异常、更新异常;下面就开始介绍 怎样把这些不好的数据库规范化。
6.2.1 函数依赖
【定义1】设R(U)是属性集U上的关系模式,X、Y是U的子集。若对于R(U)的任意一个可能的关系r,r中不可能存在两个元组在X上的属性值相等,而在Y上的属性值不等,则称 “ X函数确定Y ” 或 “ Y函数依赖于 ” X,记作 X->Y。
ps:
可以这样理解:
X表示Sno,Y表示Sname,关系r表示一张Student表;
Sno->Sname,给定一个学号100,查询出来的结果是 张三 ;
而不能是 现给定一个100,查询出来的结果是 张三,再给定一个学号100,查询出来的结果是 李四。
简单的来说,给定一个 学号,可以唯一确定一个姓名,这个就叫做函数依赖(学号->姓名)。
【例】前面的一个例子 Student(Sno,Sname,Ssex,Sage,Sdept)。
假设不允许重名,则有:
Sno -> Ssex,Sno -> Sage,Sno -> Sdept,Sno <--> Sname。
Sname -> Ssex,Sname -> Sage,Sname -> Sdept。
但Ssex 不能确定 Sage ,Ssex不能确定 Sdept。
ps:
一般来说,学号之类的编号(主码) 一定可以确定 关系中的其他属性。
一些术语和记号:
- X -> Y,但 Y⊊X 则称 X -> Y 是非平凡的函数依赖。
- X -> Y,但 Y⊆X 则称 X -> Y 是平凡的函数依赖。
- 若X -> Y,则 X 称为这个函数依赖的决定属性组,也称为决定因素。
- 若X -> Y,并且 Y -> X,则记为X <--> Y。
- 若Y 不函数依赖于X,则记为
 。
。
ps:
对于任一关系模式,平凡函数依赖都是必然成立的,若不特别声明,我们总是讨论非平凡函数的依赖。
举个例子:
比如说 Sno和Cno 是 Grade 的决定因素。

【定义2】在R(U)中,如果 X -> Y,并且对于X的任何一个真子集X',都有 X' ![]() Y,则称Y对X完全函数依赖,记作
Y,则称Y对X完全函数依赖,记作 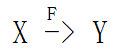 ;
;
若 X->Y,但Y不完全依赖于X,则称Y对X部分函数依赖,记作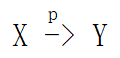 。
。
【例】在关系SC(Sno,Cno,Grade)中,
由于:Sno![]() Grade,Cno
Grade,Cno![]() Grade,
Grade,
因此,(Sno,Cno)![]() Grade
Grade
ps:
两个合起来才可以唯一确定,即 给出一个属性或属性组,可以唯一确定一条记录 的 叫做完全函数依赖。。
(Sno,Cno)![]() Sno
Sno
(Sno,Cno)![]() Cno
Cno
ps:
只要有一个可以推出来就可以了。
【定义3】在R(U)中,如果X->Y(Y⊊X),Y![]() X,Y->Z(Z⊊Y),则称Z对X传递函数依赖,记为
X,Y->Z(Z⊊Y),则称Z对X传递函数依赖,记为  。
。
【注意】如果Y->X,即X<-->Y,则Z直接依赖于X,而不是传递函数依赖。
【例】在关系Std(Sno,Sdept,Mname)中,有Sno->Sdept,Sdept->Mname,Mname传递依赖于Sno。
6.2.2 码
ps:
码 在不同的书里有不同的叫法,有的叫 码,有的叫 关键字,有的叫 键。
【定义4】设K为R![]() U,则K称为R的一个候选码。
U,则K称为R的一个候选码。
如果U部分函数依赖于K,即K![]() U,则K称为超码。候选码是最小的超码,即K的任意一个真子集都不是候选码。
U,则K称为超码。候选码是最小的超码,即K的任意一个真子集都不是候选码。
若关系模式R有多个候选码,则选定其中的一个作为主码。
ps:
比如说 Sno是学生表Student的码,(Sno,Cno)是选课表SC的码;
Studnet表里面(学生的姓名不重名),有Sno,Sname,Ssex......那么Sname和Sno这两个个属性可以叫做Student表的候选码;
任何一个候选码都可以当成一个主码,一个表里面只能有一个主码;
简单来说 超码 就是在主码或者是候选码的基础上 再扩展出来的,再加入其他的属性 。
主属性和非主属性
主属性:包含在任何一个候选码中的属性。
ps:
上述中的Student表 Sno只有一个属性,那么它就是主属性;SC表里面 (Sno,Cno)码有两个属性,那么Sno,Cno这两个属性都叫做主属性。
非主属性:不包含在任何候选码中的属性。
ps:
除了主属性以外的 属性,其他的都叫非主属性。
全码:整个属性组是码,称为全码。
ps:
整个属性组合起来,才可以确定一条记录的叫做全码。
【例】S(Sno,Sdept,Sage),单个属性Sno是码。Sno是主属性,Sdept、Sage是非主属性。
SC(Sno,Cno,Grade)中,(Sno,Cno)是码。 Sno、Cno是主属性,Grade是非主属
性。
【例】关系模型中R(P,W,A)
P:演奏者,W:作品,A:听众
一个演奏者可以演奏多个作品,某一作品可被多个演奏者演奏,听众可以欣赏不同演奏者的不同作品。
码为(P,W,A),三个属性组合起来才可以确定唯一一条记录,即全码。
【定义5】关系模式R中属性或属性组X并非R的码,但X是另一个关系模式的码,则称X是R的外部码,也称外码。
【例】SC(Sno,Cno,Grade)中,Sno不是码,Sno是S(Sno,Sdept,Sage)的码,则Sno是SC的外码。
主码与外码一起提供了表示关系间联系的手段。
ps:
在第3章 SQL语句的时候,在做连接的时候,有 SC.Sno=S.Sno,就相当于做了一个自然连接,把两张表通过Sno连接起来。
6.2.3 范式(重点内容)
ps:
简单来说,范式就是把数据库进行规范化,不同的范式对数据库的的函数依赖有不同的限制和要求。
范式是符合某一级别的关系模式的集合。关系数据库中的关系 必须满足一定的要求,满足不同程度要求的为不同范式。

ps:
BC范式是第三范式的一个扩充版本,到了BC范式数据库就比较优化了。
各种范式之间的联系:

某一关系模式R为第n范式,可简记为:R∈nNF。
规范化:是指一个低一级范式的关系模式 通过模式分解 可以转换为若干个 高一级范式的关系模式的集合,这种过程就叫 规范化。
6.2.4 2NF
【定义6】若关系模式R∈1NF,并且每一个非主属性都完全函数依赖与任何一个候选码,则R∈2NF。
ps:
意思就是说 给定一个候选码的值,就能推出一个非主属性来。
【例】S-L-C(Sno,Sdept,Sloc,Cno,Grade),Sloc为学生的住处,并且每一个系的学生住在同一个地方。S-L-C的码为(Sno,Cno)。则函数依赖有:
(Sno,Cno) ![]() Grade
Grade
Sno -> Sdept,(Sno,Cno)![]() Sdept
Sdept
Sno -> Sloc, (Sno,Cno)![]() Sloc
Sloc
Sdept - > Sloc
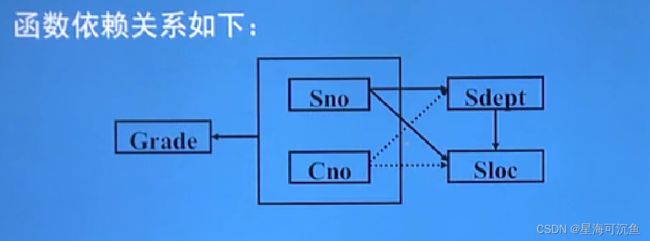
【说明】
- 图中虚线表示 部分函数依赖。
- 非主属性Sdept、Sloc并不完全依赖于码。
- 关系模式S-L-C不属于2NF。
一个关系模式不属于2NF,会产生以下问题:
(1)插入异常
如果插入一个新学生,但该学生未选课,即这个学生无Cno,由于插入元组时,必须给定 码值(Sno,Cno),因此插入失败。
(2)删除异常
如果S4只选了一门课C3,现在他不在选这门课了,删除C3后,整个元组的其他信息也被删除了。
(3)修改复杂
如果一个学生选了多门课,则Sdept,Sloc被存储了很多次。如果该省转系,则需要修改所有相关的Sdept和Sloc,造成修改的复杂化。
出现这种问题的原因:
例子类有两类非主属性:一类如Grade,它对码完全函数依赖,另一类如Sdept、Sloc,它们对码不是完全函数依赖。
解决方法:
用投影分解把关系模式S-L-C分解成两个关系模式。
S-L-C(Sno,Sdept,Sloc,Cno,Grade)分解为:
SC(Sno,Cno,Grade)。
S-L(Sno,Sdept,Sloc)。
ps:
S-L不能 仅仅分解出Sdept和Sloc(部分函数依赖的),否则就没有办法和SC连接了,所以还要拿出Sno 。
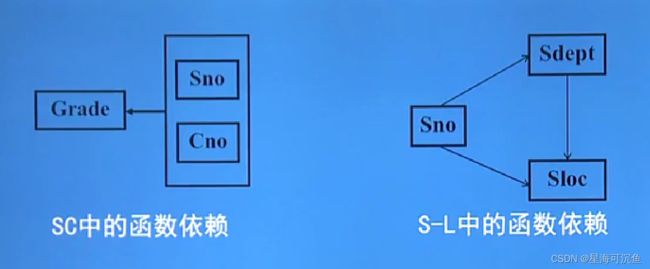 SC的码为(Sno,Cno),SL的码为Sno,这样使得非主属性对码都是完全函数依赖的了。
SC的码为(Sno,Cno),SL的码为Sno,这样使得非主属性对码都是完全函数依赖的了。
6.2.5 3NF
【定义7】设关系模式R![]() Z不成立,则称R
Z不成立,则称R
【例】SC没有传递依赖,因此SC∈3NF。
S-L中Sno->Sdept(Sdept![]() Sno),Sdept->Sloc,
Sno),Sdept->Sloc,
可得Sno Sloc。
Sloc。
解决的办法是将S-L(Sno,Sdept,Sloc)分解成:
S-D(Sno,Sdept)∈3NF。
D-L(Sdept,Sloc)∈3NF。
6.2.6 BCNF
BCNF由Boyce和Codd提出,比2NF更近了一步,但是还没有到4NF的地步。通常认为BCNF是修正的第三范式,有时也称为扩充的第三范式。
【定义8】设关系模式R
换言之,在关系模式R
BCNF的关系模式所具有的性质:
- 所有非主属性 都完全依赖于 每个候选码。
- 所有主属性 都完全依赖于 每个不包含它的候选码。
- 没有任何属性 完全依赖于 非码的任何一组属性。
如果一个关系数据库的所有模式都属于BCNF,那么在函数依赖范围内,它已实现了模式的彻底分解,达到了最高的规范化程度,消除了插入异常和删除异常。
【例】考察关系模式C(Cno,Cname,Pcno),它只有一个码Cno,没有任何属性对Cno部分依赖或传递依赖,所以C∈3NF。同时C中Cno是唯一的决定因素,所以C∈BCNF。
【例】关系模式S(Sno,Sname,Sdept,Sage),假定Sname也具有唯一性,那么S就有两个码,这两个码都有单个属性组成,彼此不相交。其他属性不存在对码的传递依赖与部分依赖,所以S∈3NF。同时S中除Sno、Sname外没有其他决定因素,所以S∈BCNF。
【例】关系模式SJP(S,J,P)中,S是学生,J表示课程,P表示名次。每一个学生选修每门课程的成绩有一定的名次,每门课程中每一名次只有一个学生(即没有并列名次)。
由语义可得到函数依赖:(S,J) -> P ;(J,P)->S,因此(S,J)与(J,P)都可作为候选码。
关系模式中 没有属性 对码传递依赖或部分依赖,故SJP∈3NF。
除(S,J)与(J,P)以外没有其他决定因素,所以SJP∈BCNF。
【例】关系模式STJ(S,T,J)中,S表示学生,T表示教师,J表示课程。每一教师只教一门课。每门有若干教师,某一学生选定某门课,就对应一个固定的教师。
由语义可得到函数依赖:(S,J)->T;(S,T)->J;T->J。
因为没有任何非主属性 对码 传递依赖或部分依赖,所以STJ∈3NF。
因为T是决定因素,而T不包含码,所以STJ∉BCNF。

【说明】
(1)对于不是BCNF的关系模式,仍然存在不合适的地方。非BCNF的关系模式也可以通过分解成为BCNF。例如,STJ可以分解为ST(S,T)与TJ(T,J),它们都是BCNF。
(2)3NF和BCNF是在函数依赖的条件下 对模式分解所能达到的 分离程度的测度。
一个模式中的关系模式 如果都属于BCNF,那么在函数依赖范畴内,它已实现了彻底的分离,以消除了插入和删除的异常。
3NF的“不彻底”性表现在 可能存在 主属性对码的部分依赖和传递依赖。
6.2.7 多值依赖
ps:
多值依赖 指的是 一对多的函数关系;前面写的都是 一对一的函数关系。
【例】学校中某一门课程有多个教师讲授,他们使用相同的一套参考书。每个教师也可以讲授多门课程,每种参考书可以供多门课程使用。
用关系模式Teaching(C,T,B)来表示课程C、教师T和参考书B之间的关系。非规范化关系如下:


Teaching具有唯一候选码(C,T,B),即全码。Teaching∈BCNF 。
以上关系存在以下问题:
- 数据冗余度大:有多少名任课教师,参考书就要存储多少次。
- 增加操作复杂:当某一课程增加一名任课教师时,该课程有多少本参照书,就必须插入多少个元组。
- 删除操作复杂:某一门课要去掉一本参考书,该课程有多少名教师,就必须删除多少个元组。
- 修改操作复杂:某一门课要修改一本参考书,该课程有多少名教师,就必须修改多少个元组。
【定义9】设R(U)是属性集U上的一个关系模式。X、Y、Z是U的子集,并且Z=U-X-Y。关系模式R(U)中多值依赖X->->Y成立,当且仅当对R(U)的任意关系r,给定的一对(x,z)值,有一组Y的值,这组值仅仅取决于x值而与z值无关。
【例】关系Teaching(C,T,B)中,对于C的每一个值,T有一组值与之对应,而不论B取何值。因此T多值依赖于C,即C->->T。
ps:

【平凡多值依赖】若X->->Y,而Z=∅,即Z为空,则称X->->Y为平凡的多值依赖,否则称X->->Y为非平凡的多值依赖。
【例】关系模式WSC(W,S,C)中,W表示仓库,S表示保管员,C表示商品。假设每个仓库有若干个保管员,有若干种商品。每个保管员保管所在仓库的所有商品,每种商品被所有保管员保管。
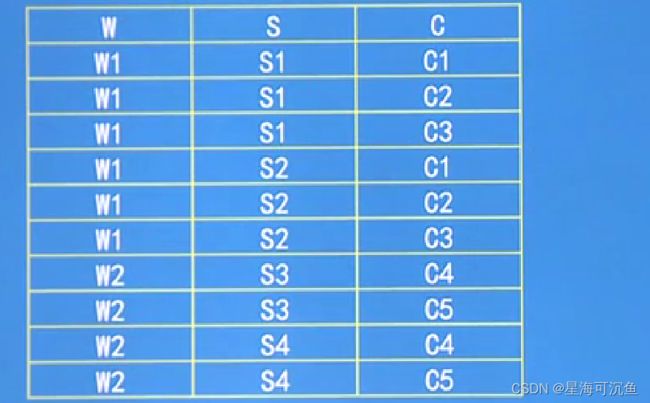
按照语义对于W的每一个值Wi,S有一个完整的集合与之对应而不问C取何值。所以W->->S。
用下图表示WSC关系:
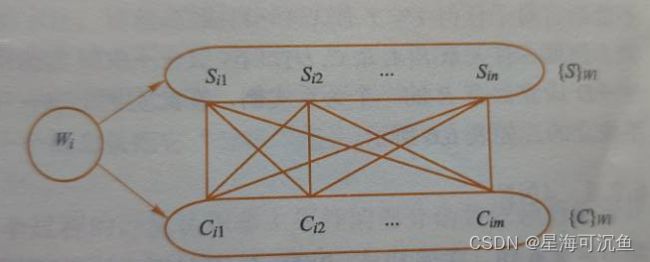
【说明】
- 对应W的某一个值Wi的全部S值记作{S}wi(表示此仓库工作的全部保管员)。
- 全部C值记作{C}wi(表示此仓库中存放的所有商品)。
- 应当有{S}wi中的每一个值和{C}wi中的每一个C值对应。
- 于是{S}wi与{C}wi之间正好形成一个完全二分图,故W->->S。
- 由于C与S的完全对称性,必然有W->->C成立。
多值依赖的性质:
(1)多值依赖具有对称性:若X->->Y,则X->->Z,其中Z=U-X-Y。
从上例容易看出,因为每个保洁员保管的所有商品,同时每种商品被所有保管员保管,显然若W->->S,必然有W->->C。
(2)多值依赖具有传递性:若X->->Y,Y->->Z,则X->->Z-Y。
(3)函数依赖是多值依赖的特殊情况:若X->Y,则X->->Y。
(4)若X->->Y,X->->Z,则X->->Y∪Z。
(5)若X->->Y,X->->Z,则X->->Y∩Z。
(6)若X->->Y,X->->Z,则X->->Y-Z,X->->Z-Y。
6.2.8 4NF
【定义10】关系模式R
【说明】
- 4NF是限制关系模式的 属性之间不允许有 非平凡且非函数依赖的 多值依赖。4NF所允许的 非平凡多值依赖 实际是函数依赖。
- 如果一个关系模式是4NF,则必为BCNF。
- 在关系WSC中,W->->S,W->->C,它们都是非平凡多值依赖。而W不是码,关系模式WSC的码是(W,S,C),即全码,因此WSC∉4NF。可以把WSC分解成WS(W,S),WC(W,C),WS∈4NF,WC∈4NF。
6.2.9 规范化小结
(1)在关系数据库中 ,对关系模式的基本要求是满足第一范式。
(2)规范化模式过低的关系 不一定能够很好的描述现实世界。可能存在插入异常、删除异常、修改异常、数据冗余等问题,解决方法就是对其进行规范化,转换成高级范式。
(3)一个低一级范式的关系模式,通过模式分解可以转化为若干个高一级范式的关系模式集合,这种过程就叫关系模式的规范化。
(4)关系数据库的规范化理论是数据库逻辑设计的工具。
(5)规范化思想
- 逐步消除数据依赖中不合适的部分,是模式中的各关系模式达到某种程度的“分离”。
- 采用“一事一地”的模式设计原则。让一个关系描述一个概念、一个实体或实体间的一种联系。若多于一个概念就把它“分离”出去。因此规范化实质上是概念的单一化。
(6)不能说规范化程度越高的关系模式就越好。必须对现实世界的实际情况和用户应用需求作进一步分析,确定一个合适的、能够反映现实世界的模式。
ps:
规范化的过程: