【R语言学习笔记】 二、R语言数据结构之向量
目录
-
- 一、数值型向量
- 二、 字符型向量
- 三、逻辑型向量
- 四、向量运算
- 五、向量的赋值
- 六、向量的访问
- 七、向量的排序
- 八、向量常用函数
-
- 取整函数
- 比较向量差异
- 判断向量各元素是否满足条件
- 向量中元素出现次数
- 其他常用函数
- 八、R中NA、NULL、NaN、Inf、-Inf的区别
- 九、小结

向量是R中最为基本的类型
一个向量中元素的类型必须相同,包括数值型、逻辑型、字符型、复数型。
注意:单个向量中的数据必须拥有相同的类型或模式(数值型、字符型或逻辑型)。
一、数值型向量
建立向量的方法(函数):
seq()或 “:” 若向量(序列)具有较为简单的规
seq(from , to, by, length.out, along.with)
#生成从from到to的向量,by为步长,length.out为生成元素的长度,along.with取赋予变量的长度为元素的个数;
rep()若向量(序列)具有较为复杂的规律
rep(x, times = 1, length.out = NA, each = 1)
#x:为一个向量(mode任意,包括list)
#times:数值型向量指定每个元素重复的次数,向量的长度为1时, 表示重复整个x
#length.out:输出向量的长度,简写len或者length
#each:x中的每一个元素重复的次数
c()若向量(序列)没有什么规律
c()为应用最广泛的向量构造函数,把所有对象连接起来形成新的向量。
x=c(42,7,64,9) #把所有对象连接起来形成新的向量
例子:


二、 字符型向量
paste (..., sep = " " , collapse = NULL)函数:把其输入的自变量(一个或多个R对象)连成字符串,中间用相应的分隔符.
…:表示一个或多个R可以被转化为字符型的向量sep: 分隔符,默认为空格collapse:可选,如果NULL,那么函数paste的返回值是自变量之间通过sep指定的分隔符连接后得到的一个字符型向量;如果为其指定了特定的值,那么自变量连接后的字符型向量会再被连接成一个字符串,之间通过collapse的值分隔。
> paste("Hello", "world")
[1] "Hello world"
#paste函数把它的自变量连成一个字符串,中间用空格分开
> paste(c("A", "B"), 1:3, sep = "")
[1] "A1" "B2" "A3"
#连接的自变量可以是向量,这时各对应元素连接起来,长度不相同时较短的向量被重复使用
> paste(c("A", "B"), 1:3, sep = "", collapse=",")
[1] "A1,B2,A3"
#同时使用了参数seq与collapse,结果只是返回一个元素
三、逻辑型向量
直接用例子加以说明:
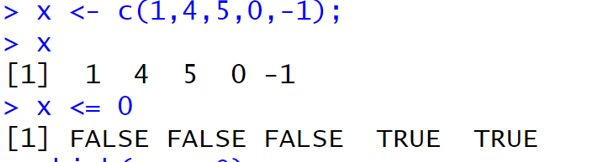
补充:逻辑运算符:

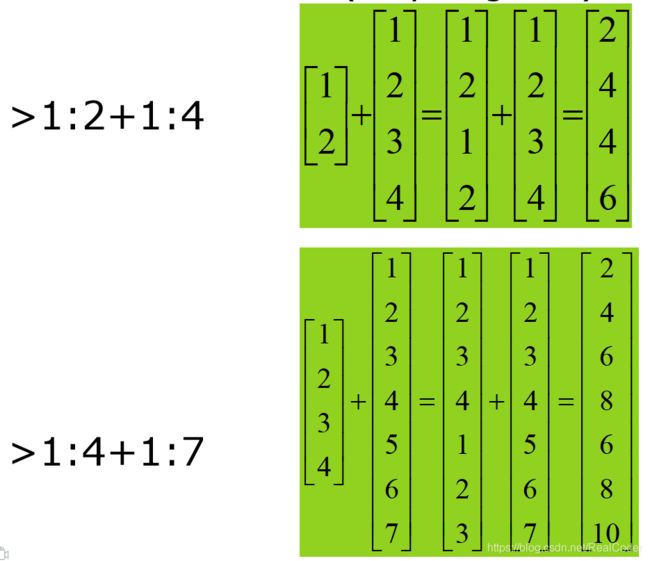
四、向量运算
向量运算采取广播机制
五、向量的赋值
创建一个含有五个数值的向量,这五个值分别为:
10, 4, 53, 6, 21
x <- c(10,4,53,6,21)
x = c(10,4,53,6,21)
赋值也可以用assign()实现:
assign("x", c(10,4,53,6,21))
六、向量的访问
-
中括号[]:
正的下标 提取向量中对应的元素
负的下标 去掉向量中对应的元素
逻辑下标 提出向量中元素的值满足条件的元素
注:R中向量的下标从1开始。 -
向量中元素的名字提取子集(
names函数用于设定名字)

七、向量的排序
在R中,和排序相关的函数主要有三个:
sort()、rank()和order()
sort(x)是对向量x进行排序,返回值排序后的数值向量。rank(x)是求秩的函数,它的返回值是这个向量中对应元素的“排名”
rank(x, na.last = TRUE, ties.method = c("average", "first", "random", "max", "min"))
x: rank 函数是对一维度数组、向量x 进行排序。
na.last: rank 将数据分为确定值与缺失值两种。缺失值可按先后排在确定值之间(na.last = FALSE), 也可排在之后(na.last = TRUE), 也可保留,不参与排序(na.last = "keep").
ties.method :针对相等的值处理方法
"average" 是相同元素都取该组中的平均水平,该水平可能是个小数。
"first",相同元素先者在前后者在后。
"max" 是相同元素都取该组中最好的水平,即通常所讲的并列排序。
"min" 是相同元素都取该组中最差的水平,可以增大序列的等级差异。
"random" 是相同元素随机编排次序。
order(x)返回对一个或多个向量进行排序,返回排序后的元素在x向量中的下标;
order(X, na.last=TRUE, decreasing=FALSE)
返回值: X排好序的下标向量
na.last 控制空值NA排在最前还是最后,默认最后
desceasing 控制升序还是降序排列
例如:

八、向量常用函数
取整函数
ceiling(x) #向上取整
floor(x) #向下取整
trunc(x) #截取整数部分, '向零截取'
round(x,digits=n) #将x舍入指定位的小数(四舍五入),默认无小数
signif(x,digits=n) #将x舍入指定位的有效数字(四舍五入),科学计数法

比较向量差异
intersect(x,y) #—向量交集
union(x,y) #—向量并集
setdiff(x,y) #—向量差异
setequal(x,y) #判断两个向量是否相等
判断向量各元素是否满足条件
x>5 #返回是否x中各元素满足条件
any(x>5) #x中任意元素满足条件,返回TRUE
all(x>5) #全体满足条件,返回TRUE
向量中元素出现次数
unique(x) #—去冗余,取唯一值
duplicated(x) #判断是否重复出现
table(x) #向量各元素出现的次数
其他常用函数
min(x) #—最小值
max(x) #—最大值
which.min() #—最小值位置
which.max() #—最大值位置
sum(x) #—求和
length(x) #—求长度
mean(x) #—均值
median(x) #—中位数
var(x) #—方差
sd(x) #—标准差
which(x==1) #—逻辑向量TRUE的位置
八、R中NA、NULL、NaN、Inf、-Inf的区别
- NA: 缺失数据即“Missing value”,是“not
available”的缩写;主要会在从文件或数据库读取
数据时遇到,或者将一个向量的长度扩展会出现NA值 - NULL:空值;一般被用在函数参数中,表示该参数没有被赋予任何值,或者某些函数返回值为Null
- NA与NULL的差别还是非常明显的。用一个比喻来讲,NA是已经挖好了一些坑,只是里面没有萝卜而已,这就是所谓的“缺失值”。而NULL则指的是“压根连坑都没有”
- NaN: 无意义的数即“not a number”,
例如sqrt(-2) - Inf: 正无穷大
- -Inf: 负无穷大



九、小结
向量生成函数:c(); rep(); seq();
逻辑运算符:&、 &&、|、||
向量的循环运算法则
向量的赋值
向量的访问
向量中元素的排序:sort()、rank()和order()
R语言取整函数:
ceiling();floor();trunc(); round(); signif();
两个对象比较:
identical();all.equal();
向量差异比较:
intersect(x,y) #交集 union(x,y)#并集
setdiff(x,y) #差异 setequal(x,y) #向量相等