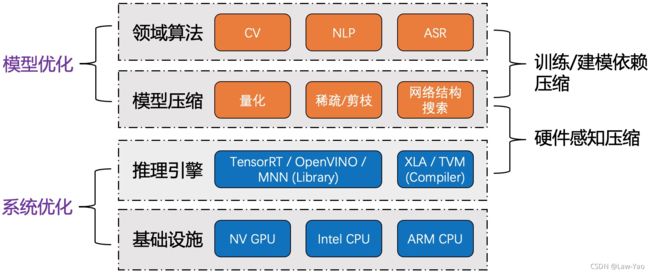
Bert/Transformer模型压缩与优化加速
前言
Bert/Transformer结构及其变体,已成为自然语言处理 (NLP)、语音识别 (ASR)等领域的主流序列建模结构。并且,相比于卷积操作的局部特征提取能力、以及平移不变性,Self-Attention/Cross-Attention的全局Context信息编码或长时依赖建模能力,能够使图像/视觉模型具备更强的相关性建模能力(更好的全局视野)、与动态建模能力(领域或样本适应性)。因此在计算机视觉领域 (CV),Vision Transformer模型结构 (如ViT、Deit、Swin-Transformer、PVT、SegFormer与DETR等)也日益流行、方兴未艾。然而,Transformer模型的高计算复杂度与参数量,限制了模型的推理部署(包括服务端与移动端应用),其计算、存储与运行时内存等资源开销都成为限制因素(存在大量密集计算算子、与访存算子,如BatchMatMul、LayerNorm、Transpose/Reshape等)。例如,从标准Transformer layer的Tensor处理结构来看,MHA的Context特征计算与特征长度的平方、Embedding特征维度成正比:
- Standard Self-Attention (X=Y) / Cross-Attention (X!=Y):

- Standard FFN:

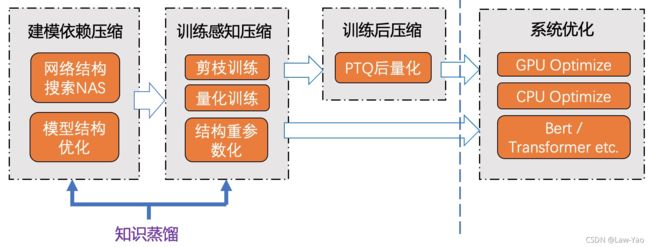
本文从以下几个维度举例说明,解析Bert/Transformer模型的加速方法,体现了从建模依赖、数据依赖到硬件依赖的优化层次:
- 模型结构精简化与知识蒸馏;
- 模型量化 (Quantization);
- 网络结构搜索 (NAS: Network Architecture Search);
- 计算图优化 (计算图等价变换);
- 推理优化引擎 (Faster Transformer / Torch-TensorRT / AICompiler);
模型结构精简化与知识蒸馏
Lite-Transformer
参考文献: https://arxiv.org/abs/2004.11886
Lite Transformer是一种融合卷积与Self-Attention操作的、高效精简的Transformer结构,可应用于NMT、ASR等序列生成任务。其核心是长短距离注意力结构 (LSRA:Long-Short Range Attention),能够有效融合卷积与Attention机制。LSRA将输入Embedding沿Feature维度split成两部分,其中一部分通过GLU (Gate Linear Unit)、一维卷积,用以提取局部Context信息;而另一部分依靠Self-attention,完成全局相关性信息编码。一维卷积的引入,能够减轻计算量与参数量。Lite Transformer核心结构如下,首先将FFN的宽度摊平 (flatten),其次引入LSRA以替换Self-Attention:


SAN-M
参考文献: https://arxiv.org/abs/2006.01713
SAN-M表示Self-Attention与DFSMN记忆单元的融合,是一种Transformer ASR模型。DFSMN适合捕获局部信息,Self-Attention模块具备较强的长时依赖建模能力,因此二者存在互补性。SAN-M通过将两个模块的特性融合在一起,实现了优势互补。Biasic Sub-layer表示包含了SAN-M的Self-Attention模块,DFSMN添加在values后面,其输出与Multi-head Attention (MHA)相加:


MiniLM (知识蒸馏)
参考文献: https://arxiv.org/abs/2002.10957
针对NLP任务,深度自注意力知识蒸馏 (Deep Self-Attention Distillation),通过迁移Teacher model最后一层Self-Attention模块的Attention score信息与Value relation信息,可有效实现Student model的诱导训练。只迁移最后一层的知识,能够直接迁移语义信息,显得简单有效、训练速度更快;而且相比于层间特征迁移,不需要手动设计Teacher-student之间的层对应关系。Attention score信息与Value relation信息的知识迁移如下:
- Attention score transfer:

- Value relation transfer:
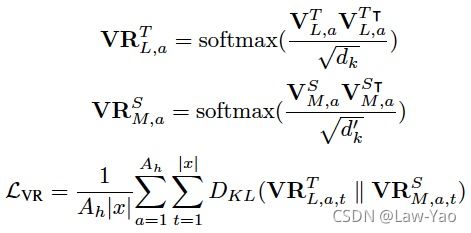

- 若选择的Self-attention layer为LSRA,除了在Multi-head Attention (MHA)分支迁移Attention score与Value relation;在CNN分支需要迁移Feature map的信息,这里主要计算AT loss:
式中Fs,j表示学生网络里第j个网络层的特征输出,Ft,j表示Teacher network里第j个group的特征输出。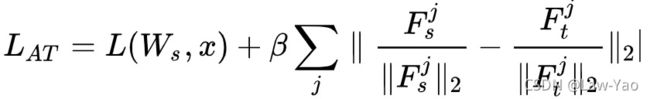
Switch-Transformer
参考文献:https://arxiv.org/abs/2101.03961
针对内容理解与生成、以及多模态特征表征等AI任务,基于MoE(Mixture of Experts)单元的大模型的参数规模不断扩展(Switch-Transformer是其中的典型代表之一),但大模型对算力的需求、被MoE的稀疏激活(Sparse activation)或动态路由(Dynamic routing)机制有效缓解。MoE单元属于典型的Sample驱动型结构设计,使得MoE-based模型具备良好的动态建模能力(动态卷积、Self-Attention等亦如是),因此MoE能够非常好的适应多任务/多模态、甚至在线实时的场景应用需求。Switch-Transformer的MoE单元结构如下,具体执行过程包括动态路由(Dynamic routing)、数据分派(Data dispatch)、专家计算(Expert computation)与结果合并(Result combine):

多模态与CLIP应用
具体参考:
随笔记录——不同模态信号、表征与应用_AI Flash-CSDN博客
模型量化 (Quantization)
Transformer ASR模型压缩
参考文献: https://arxiv.org/abs/2104.05784
针对Transformer ASR,文章提出了联合随机稀疏与PTQ量化 (KL量化、ADMM与混合精度设置)的压缩策略,整体实现了10倍压缩,且绝对精度损失约0.5%。总体流程如下:
- 模型稀疏化,更新Weight重要性,渐进式增加稀疏度:
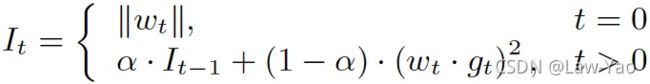
- KL量化,计算Activation量化参数:
![]()
- ADMM,优化Weight量化参数:

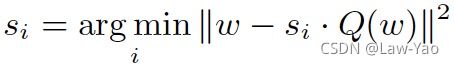
- 混合精度量化设置,减少量化误差:
![]()

此外,针对Transformer模型的量化,需要讨论全网络INT8量化与计算的意义:
- 全网络INT8量化:
- 同时减少计算密集算子与访存密集算子的开销;
- 实现模型压缩,INT8模型是FP32模型的1/4;
- Fully INT8 Attention Path:
- 基本的全INT8通路:
- Dense layer的输入与输出均为INT8 Tensor;
- Reshape与Transpose的操作对象为INT8 Tensor,节省内存开销:
- Dense+Reshape+Transpose、与Transpose+Reshape+Dense可以实现Op fusion;
- BatchMatMul、Softmax的操作对象保留为FP32 Tensor,确保模型预测精度;
- 基本的全INT8通路:
- Encoder的Self-Attention:
- X=Y;
- Decoder的Self-Attention:
- X=Y,Batch_size=Batch_size * Beam_size,Seq_len=1;
- k_dense与v_dense的输出会添加到Cache,按照INT8类型搬运数据,可节省访存开销:

PTQ for Vision Transformer
参考文献: https://arxiv.org/abs/2106.14156
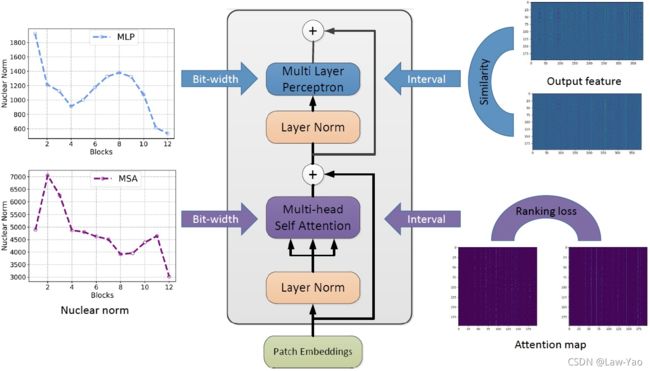
针对Vision Transformer的PTQ量化,分别针对FFN与Self-Attention,提出了Similarity-aware Quantization与Ranking-aware Quantization:
- Similarity-aware Quantization: 基于优化方式确定Weight与Activation量化的最优量化参数,并以Pearson相似度作为Target loss;


- Ranking-aware Quantization: 在相似度Loss基础之上,叠加Attention map的Ranking loss作为约束,以准确感知不同Attention map的重要性排序,确保Self-attention量化的有效性(优先保留重要Attention map的信息);


PTQ4ViT
参考博客文章:
PTQ4ViT: Vision Transformer的PTQ方法与框架_AI Flash-CSDN博客
Q-Bert
参考文献:https://arxiv.org/abs/1909.05840
针对NLP任务(MNLI、SQuAD等),Q-Bert是首个实现Bert模型混合精度量化的QAT算法。Bert模型是由Embedding layer、Encoder layer以及Task-specific output layer构成的前馈结构模型,且Encoder layer包含了MHA与FFN等子模块。
不同的Bert layer体现了不同的量化敏感度(Quantization Sensitivity),配以不同的量化比特数,直接决定了量化后模型的预测精度。通常Bert的Embedding layer与Output layer的量化敏感度相对较高,故Embedding layer会配以较高的量化比特数(如8bits),Output layer则保留为FP32浮点实现。另外,尽管不同Encoder layer的结构相一致,但由于对Context信息编码的贡献有所区别,因此表现出不同的量化敏感性。
-
量化敏感度与混合精度量化:Q-Bert采用线性均匀量化方式(min-max量化),并通过Dense layer的Hessian信息(二阶梯度)定义其量化敏感度:

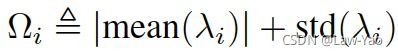
式中Hessian矩阵特征值(Top eigenvalues)的均值,反映了针对同一个下游任务(相同训练数据分布),不同Dense layer的量化敏感度;Hessian矩阵特征值的标准差,反映了针对不同的下游任务(不同训练数据分布),Dense layer量化敏感度的占比。然后,基于不同Dense layer的量化敏感度排序,可确定Bert模型的混合精度量化配置,并进一步执行QAT微调训练。
-
Group-wise量化:为了进一步提高量化后模型的精度,将MHA的Q、K、V与O权重矩阵按Attention heads分成不同的Group,每个Group定义各自的量化范围(min-max范围),从而更精细的保证不同Group的量化分辨率。而每个Group又可以根据实际需求、进一步划分为不同的Sub-group,以满足更为苛刻的部署精度需求:
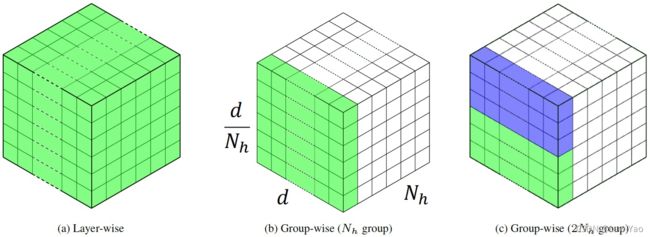
网络结构搜索 (NAS)
AdaBert
参考文献: https://arxiv.org/abs/2001.04246
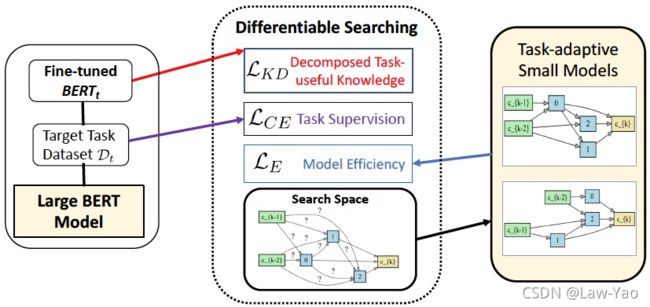
针对NLP任务,AdaBert通过可微分搜索、与知识蒸馏,实现卷积类型的NLP模型搜索:
- 搜索空间:类似于DARTS的Cell设计,实现搜索空间的构造;区别于Vanilla CNN,DARTS的Cell单元结构体现出了非规整性,可能不利于实际推理引擎的加速;

- 搜索策略:基于Gumbel Softmax实现网络结构的随机采样(类似于FBNet)、与可微分搜索,并且采样概率随着训练的进行、逐渐锐化,逼近Argmax采样;另外,基于FLOPS与Model size构造了Efficiency-aware Loss,作为搜索训练的资源约束,实现Hardware-aware搜索;
- 知识蒸馏:多层次、任务相关的知识迁移;
DynaBert
参考文献: https://arxiv.org/abs/2004.04037
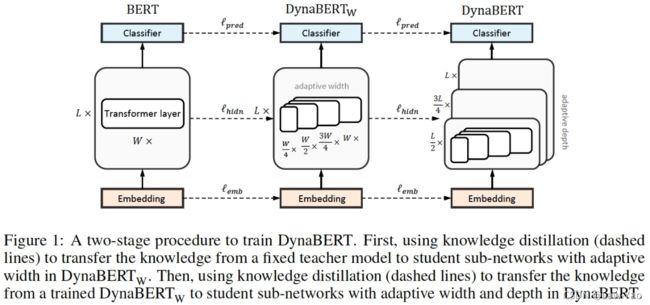
针对NLP任务,DynaBert模型压缩策略可实现多个维度的压缩搜索(主要是Width与Depth维度)。DynaBert是一种动态可伸缩性质的One-shot NAS:首先基于预训练Bert模型(或其变体),进行多维度正则化训练;正则化训练之后,按照不同的资源约束需求,能够进行网络参数的裁剪、以获得子网络,并进行子网络的微调训练;从正则训练、到子网络微调,可协同知识蒸馏训练,进一步保持子网络的预测精度。主要步骤描述如下:
- 第一步:基于Neuron与Attention head的重要性,执行参数重排(Weight Re-wiring):

- 第二步:多阶段微调训练,实现宽度、与深度方向的自适应正则化:
NAS-Bert
参考博客文章:
NAS-Bert——确保One-shot与Task-agnostic_AI Flash-CSDN博客
Evolved Transformer
参考文献: https://arxiv.org/abs/2004.11886
针对序列生成任务,基于NAS搜索获得的Transformer结构:
- 搜索空间:包括两个Stackable cell,分别包含在Transformer encoder与Transformer decoder。每个Cell由NAS-style block组成, 可通过左右两个Block转换输入Embedding、再聚合获得新的Embedding,进一步输入到Self-Attention模块。
- 搜索策略:基于EA (Evolutional Aligorithm)的搜索策略;
网络结构如下,融合了一维卷积与Attention的特点:
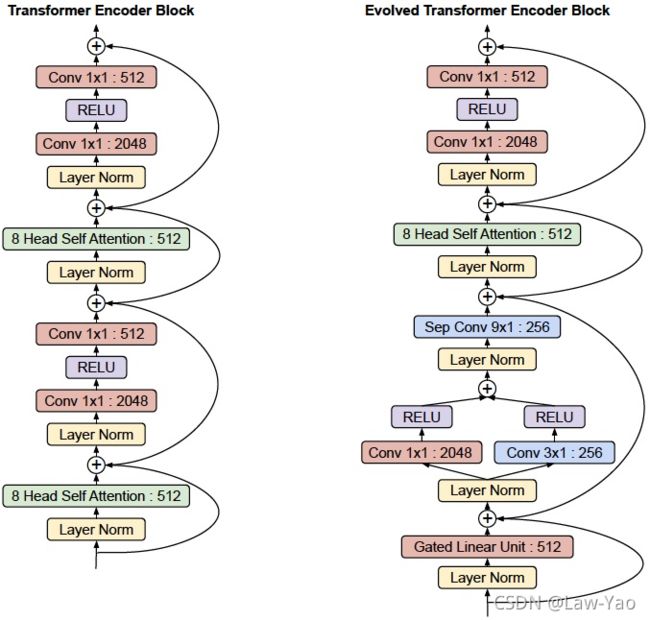
HAT: Hardware-aware Transformer
参考文献: https://arxiv.org/abs/2005.14187
对Transformer模型进行网络结构搜索时,通常会面临两个关键问题:
- FLOPS不能完全代表Transformer模型的计算速度/实际执行效率,即只能间接反映硬件平台特性;
- 不同硬件设备上,与计算硬件或计算库相适配的最优Transformer结构不尽相同;
针对序列生成任务,HAT (Hardware-aware Transformer)从搜索空间、搜索策略与搜索预测三方面加以分析:
- 搜索空间:Encoder-decoder Attention的任意连接方式,以及Transformer layer内部结构(网络深度、Attention head数目、Width等);
- 搜索策略:训练了SuperTransformer作为超网络,并在超网络预训练之后,结合资源约束,通过进化搜索算法(EA: Evolutional Algorithm)寻找最优子网络;不同于权重共享型NAS (如FBNet、SPOS等),HAT是一种动态可伸缩类型的One-shot NAS;
- 搜索预测:单独、离线训练了MLP回归模型作为Cost model或Predicter,用于预测不同子网络结构(Architecture embedding)、在指定硬件平台上的执行速度 (GPU或CPU latency),并且回归预测效果良好(以相关性系数作为Metric)。搜索预测的好处在于:一方面可直接、有效获取硬件平台特性,作为超网络预训练的资源约束;另一方面,在训练或搜索阶段,无需在硬件平台上测量推理延迟,提升搜索效率,从而有利于跨平台模型结构搜索;
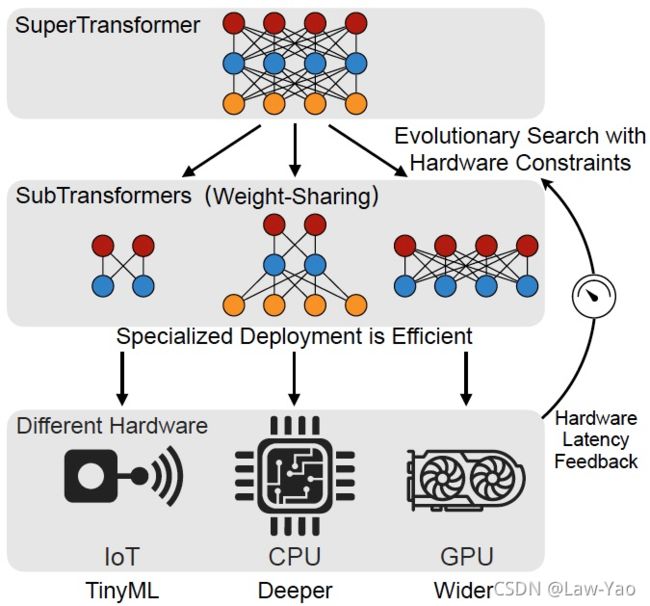

AutoFormer
参考文献: https://arxiv.org/abs/2107.00651
针对Vision Transformer的结构搜索,AutoFormer提出的Weight entanglement,在不额外增加Block choice的前提下,通过通道宽度、网络深度、Attention head数目等多个维度的调整,实现了Vision Transformer模型的动态可伸缩预训练与结构搜索。Weight entanglement的做法,类似于BigNAS、FBNet-v2的通道搜索,都不会额外增加通道维度的权重参数量。相比于手工设计的CNN模型(ResNet、ResNext、DenseNet)与Vision Transformer模型(ViT、Deit),AutoFormer模型在相同资源开销条件下、能够获得最好的识别精度。

AutoFormer总体思路如上图所示,是一种基于Weight entanglement的动态可伸缩搜索方法,其搜索维度包括Attention heads、通道宽度与网络深度。下面从搜索空间、搜索策略与搜索效率这些维度加以分析:
- 搜索空间:Embedding dimension、Q-K-V dimension、Attention heads、MLP ratio与Network depth;根据不同的资源约束,分别设置Supernet-tiny、Supernet-small与Supernet-base三个基本的Template model;
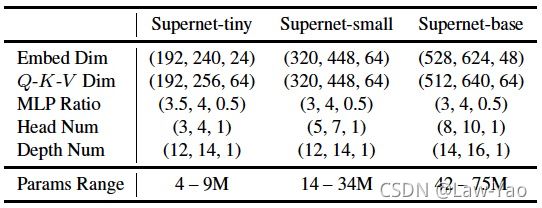
- 搜索策略:基于Weight entanglement的One-shot NAS,完成超网络预训练之后,通过进化算法执行子网络搜索。包含l个网络层的子网络结构可按下式表示,表示第i层的Block结构,表示相应的权重参数:

而每个Block结构,都是按照Weight entanglement原则从超网络采样获得,下式表示n个动态选择范围:
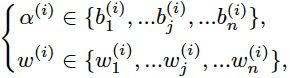
![]()

- 搜索效率:按照权重共享形式、完成超网络预训练,训练效率高、且收敛速度快;另外,由于没有引入额外的Block choice,因此训练时的Memory cost较低;
AutoFormerV2
具体参考:
ViT结构优化——Searching the Search Space (S3 NAS)_AI Flash-CSDN博客
计算图优化
LINM
LINM (Loop-invariant Node Motion)是一种计算图等价变换技术,通过将Transformer模型涉及的自回归解码 (Auto-regressive Decoding)的重复计算逻辑 (Encoder-decoder Attention的k/v计算、cache gather等)移至While-loop之外,在确保计算功能不变的情况下,实现计算效率的提升:
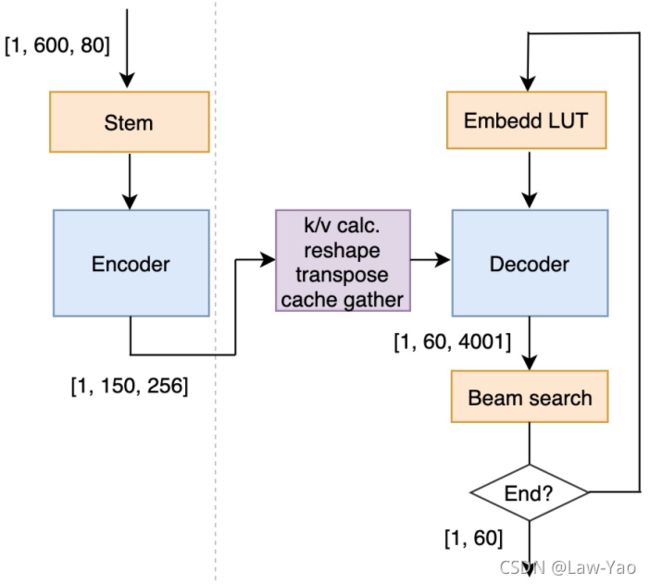
计算图等价变换是在Graph-level执行的、确保计算结果不变的性能优化策略,其总体原则包括:
-
首先,寻找更具效率的等价计算形式,比如Flops更低、或对后端引擎/硬件更为友好;
-
其次,在计算量(如Flops)相当的情况下,寻找访存交换量、或Kernel launch数量更低的等价计算形式,以提升计算强度(参考Roofline model的定义);
MatMul替换为卷积
如果推理引擎的卷积算子具备很高的计算效率,并且为了避免一些不必要的访存算子开销,可以按如下计算图等价变换,将Dense layer替换为Conv1D layer:

QKV计算合并
MHA (Multi-head Attention)模块在计算Attention map与Context编码特征之前,需要基于输入Tensor计算QKV矩阵、并Split成多份Heads。可通过计算图等价变换,将QKV计算合并到同一个Dense layer,能够充分利用NPU或GPU的并发计算特性:
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.sample_num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]推理优化引擎
Faster Transformer
GitHub链接:https://github.com/NVIDIA/FasterTransformer
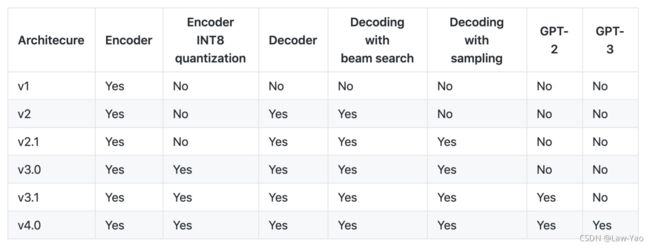
Faster Transformer是NVIDIA针对标准BERT/Transformer做的推理优化库,其发布时间线:
- 1.0版本:
- 2019年7月,开源了FasterTransformer 1.0,针对 BERT中的Transformer Encoder进行优化和加速;
- 面向BERT分类、自然语言理解场景;
- 底层由CUDA和cuBLAS实现,支持FP16和FP32计算,FP16可充分利用Volta和Turing架构的Tensor Core计算单元;
- 提供C++ API、TF Op与TensorRT Plugin三种接口;
- 参考资料;
- 2.0版本:
- 2020年2月,新增对Transformer decoder的优化和加速,包括decoder与decoding两种加速模式;
- 面向生成式场景,如NMT、文本内容生成与ASR等;
- 底层由CUDA和cuBLAS实现,支持FP16和FP32计算模,FP16可充分利用Volta和Turing架构的 Tensor Core计算单元;
- 提供C++ API、TF Op与TensorRT Plugin三种接口;
- 参考资料;
- 2.1版本:
- 2020年6月,引入Effective Transformer优化;通过remove_padding的支持,提高计算与访存效率;
- 并新增PyTorch Op接口;
- 参考资料;
- 3.0版本:
- 2020年9月,新增BERT encoder的INT8量化加速支持;
- 仅支持Turing架构GPU;
- 同时支持PTQ与QAT方法,提供了TF量化工具;
- 相比于FP16计算,约20~30%加速,但存在精度损失风险;
- 3.1版本:
- 2020年12月,新增对PyTorch使用INT8推理的支援;
- 在Turing以后的GPU上,FP16的性能比3.0提升了 10% ~ 20%;
- INT8的性能比3.0最多提升了70%;
- 4.0版本:
- 2021年4月,新增对GPT-3等百亿/千亿级参数规模模型的多机多卡推理加速能力;
- 新增FP16 fused MHA算子,同时支持Volta与Turing架构的GPU;
- 以及对解码端Kernel的优化,可以省略已完成语句的计算,节省计算资源;
- 参考资料;
- 支持矩阵:
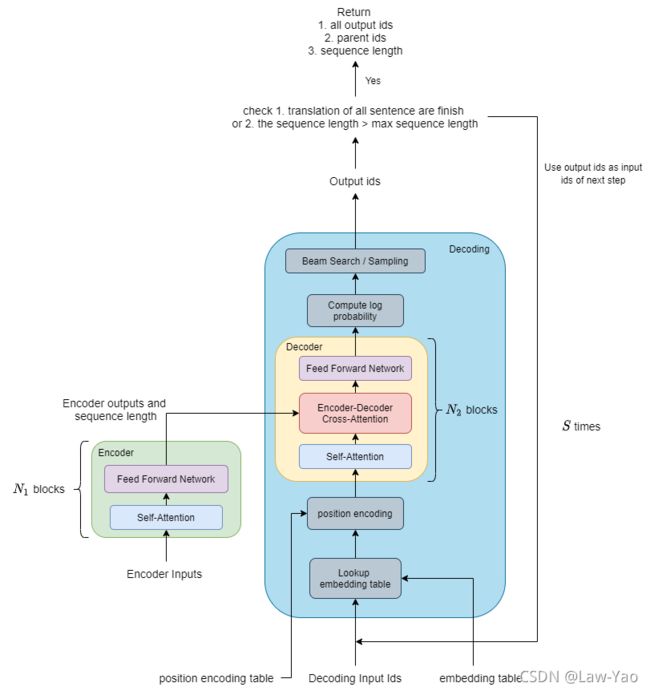
Transformer计算图表示,主要包含三个部分的表示:
- Encoder layer;
- Decoder layer;
- Decoding logic;
Torch-TensorRT
参考博客文章:
深度学习模型压缩与优化加速(Model Compression and Acceleration Overview)_AI Flash-CSDN博客_深度学习模型压缩
AICompiler
基于AICompiler(AI编译优化),可通过Op fusion方式 (算子融合),提升Transformer模型的执行效率。Op fusion具备的好处主要是:1)首先,将多个零碎算子合并成计算功能等价的一个大算子,可减少密集的Kernel launch开销 (CUDA核函数启动);2)其次,由于相邻算子之间存在内存读写开销,Op fusion可有效减少密集的内存访问开销;3)最终通过算子实现的自动寻优、与代码生成 (CodeGen),可自动生成优化的可执行代码。
总结
深度学习领域的高性能计算,总结为如下公式:
高性能计算 = 高效率算法 + 模型压缩 + 系统/硬件优化
可以单独的强调其中一种优化策略,或者实现多种选项的联合优化(例如Hardware-aware NAS,压缩与编译联合优化等),以满足实际应用场景的部署需求。在工业界,包括阿里淘系MNN、阿里云PAI、华为昇腾计算、Open AI Lab的Tengine、百度EasyDL等平台,在该领域均构建了相对完善的软硬件技术栈,为开放、普惠的AI应用提供了坚实基础。