Vision Transformer——ViT代码解读
官方提供的代码:https://github.com/google-research/vision_transformer
大佬复现的版本:https://github.com/lucidrains/vit-pytorch
对不起,我好菜,官方给的代码我确实看不懂啊,所以看了第二个版本的代码。第二个版本的代码超级受欢迎且易使用,我看的时候,Git repo已经被star 5.7k次。大家直接 pip install vit-pytorch就好。
所以作为初次接触vit的同学们来说,推荐看第二个版本,结构清晰明了。
1. 大佬复现版本给的使用案例
import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256, # 图像大小
patch_size = 32, # patch大小(分块的大小)
num_classes = 1000, # imagenet数据集1000分类
dim = 1024, # position embedding的维度
depth = 6, # encoder和decoder中block层数是6
heads = 16, # multi-head中head的数量为16
mlp_dim = 2048,
dropout = 0.1, #
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)
大家完全可以把这段代码copy-paste到自己的pycharm里,然后使用调试功能,一步步看ViT的每一步操作。
2. Transformer结构
进行6次for循环,有6层encoder结构。for循环内部依次使用multi-head attention和Feed Forward,对应Transformer的Encoder结构中多头自注意力模块和MLP模块。在自注意力后及feed forward后,有残差连接。
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x
PreNorm类代码如下,在使用multi-head attention和Feed Forward之前,首先对输入通过LayerNorm进行处理。
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
可以参考论文中的图:
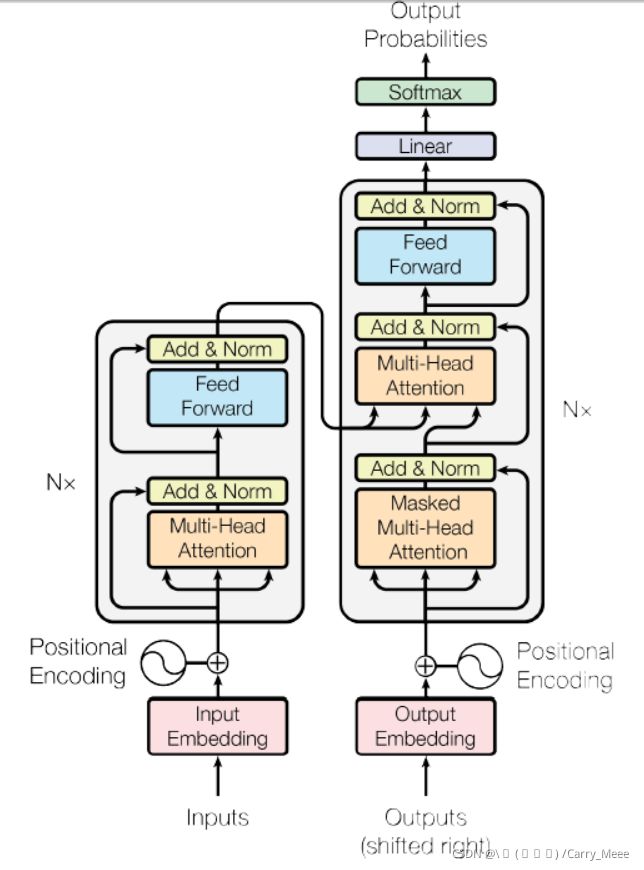
3. Attention
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1) # 首先生成q,k,v
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
torch.chunk(tensor, chunk_num, dim)函数的功能:与torch.cat()刚好相反,它是将tensor按dim(行或列)分割成chunk_num个tensor块,返回的是一个元组。
attention操作的整体流程:
- 首先对输入生成query, key和value,这里的“输入”有可能是整个网络的输入,也可能是某个hidden layer的output。在这里,生成的qkv是个长度为3的元组,每个元组的大小为(1, 65, 1024)
- 对qkv进行处理,重新指定维度,得到的q, k, v维度均为(1, 16, 65, 64)
- q和k做点乘,得到的dots维度为(1, 16, 65, 65)
- 对dots的最后一维做softmax,得到各个patch对其他patch的注意力得分
- 将attention和value做点乘
- 对各个维度重新排列,得到与输入相同维度的输出 (1, 65, 1024)
4. FeedForward
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim), # dim=1024, hidden_dim=2048
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
FeedForward模块共有2个全连接层,整个结构是:
- 首先过一个全连接层
- 经过GELU()激活函数进行处理
- nn.Dropout(),以一定概率丢失掉一些神经元,防止过拟合
- 再过一个全连接层
- nn.Dropout()
注意:GELU(x) = x * Φ(x), 其中,Φ(x)是高斯分布的累积分布函数 。
5. ViT操作流程
ViT的各个结构都写在了__init__()里,不再细讲,通过forward()来看ViT的整个前向传播过程(操作流程)。
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim),
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim)) # (1,65,1024)
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img): # img: (1, 3, 256, 256)
x = self.to_patch_embedding(img) # (1, 64, 1024)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b) # (1, 1, 1024)
x = torch.cat((cls_tokens, x), dim=1) # (1, 65, 1024)
x += self.pos_embedding[:, :(n + 1)] # (1, 65, 1024)
x = self.dropout(x) # (1, 65, 1024)
x = self.transformer(x) # (1, 65, 1024)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0] # (1, 1024)
x = self.to_latent(x)
return self.mlp_head(x)
整体流程:
- 首先对输入进来的img(256*256大小),划分为32*32大小的patch,共有8*8个。并将patch转换成embedding。(对应第26行代码)
- 生成cls_tokens (对应第28行代码)
- 将cls_tokens沿dim=1维与x进行拼接 (对应第29行代码)
- 生成随机的position embedding,每个embedding都是1024维 (对应代码14行和30行)
- 对输入经过Transformer进行编码(对应代码第32行)
- 如果是分类任务的话,截取第一个可学习的class embedding
- 最后过一个MLP Head用于分类。