python DataFrame数据生成
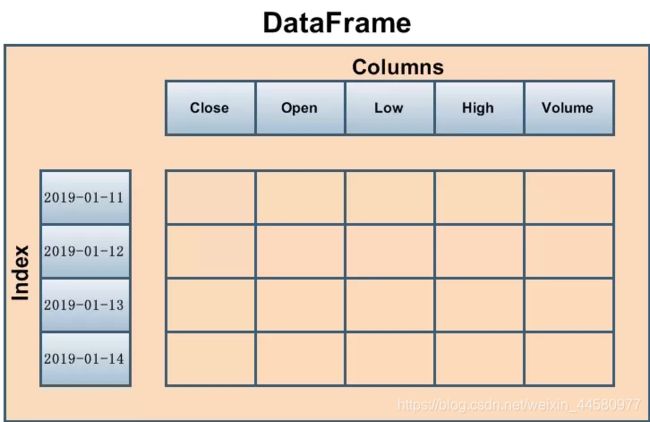
前言: DataFrame是一个表格型的数据结构,既有行索引 index也有列索引columns,创建DataFrame的基本方法为df = pd.DataFrame(data, index=index,columns=columns),其中data参数的数据类型可以支持由列表、一维ndarray或Series组成的字典、字典组成的字典、二维ndarray等。如下图所示,基本上可以把DataFrame看成是Excel的表格形态:
接下来我们根据创建DataFrame的基本要求将data、index、columns这三个参数准备就绪。
关于列索引columns,我们将收盘价定义为“close”,涨跌幅定义为“price range”。
行索引index在此处表示为交易日期,Pandas提供了强大的处理日期数据的功能,我们使用pandas.date_range()生成DatetimeIndex格式的日期序列,其中参数包括:起始时间start、结束时间end、时期数量periods、日期间隔频率freq='M’月、'D’天、‘W’、周、'Y’年等等,此处生成从2010-01-01开始的1000个日期的时间序列,如下所示:
import pandas as pd
#生成日时间序列
dd=pd.date_range('2010-01-01',freq='D',periods=1000)
print(f'生成日时间序列:\n{dd}')
"""
生成日时间序列:
DatetimeIndex(['2010-01-01', '2010-01-02', '2010-01-03', '2010-01-04',
'2010-01-05', '2010-01-06', '2010-01-07', '2010-01-08',
'2010-01-09', '2010-01-10',
...
'2012-09-17', '2012-09-18', '2012-09-19', '2012-09-20',
'2012-09-21', '2012-09-22', '2012-09-23', '2012-09-24',
'2012-09-25', '2012-09-26'],
dtype='datetime64[ns]', length=1000, freq='D')"""
"""
关于data参数的类型,我们通过np.random.normal()返回的数据类型为’numpy.ndarray’,属于data参数支持的数据类型,于是我们将data、 index和columns三个参数传入创建DataFrame的方法中,就可以生成DataFrame格式的股票交易数据。此处以ndarray组成的字典形式创建DataFrame,字典每个键所对应的ndarray数组分别成为DataFrame的一列,共享同一个 index ,例程如下所示:
df_stock = pd.DataFrame({'close': stock_data, 'price range': pct_change}, index=dd)
print(f'股价交易数据:\n {df_stock.head()}')#打印前5行数据
"""
股价交易数据:
close price range
2010-01-01 10.59 NaN
2010-01-02 8.52 -0.20
2010-01-03 9.03 0.06
2010-01-04 10.33 0.14
2010-01-05 10.10 -0.02
"""
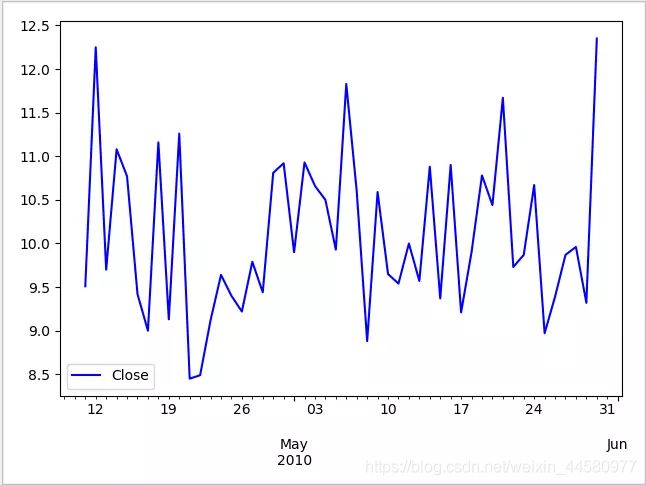
当我们得到了DataFrame格式的股票交易数据之后,就可以利用Pandas强大数据分析功能处理我们的数据,在后续的小节中会陆续介绍其中的各种方法。此处我们先通过Pandas封装的matplotlib绘图功能,绘制其中50个交易日收盘价曲线,用可视化的方式了解下随机漫步的股价走势,如下所示:
import matplotlib.pyplot as plt
#绘制收盘价
df_stock.close[100:150].plot(c='b')
plt.legend(['Close'],loc='best')
plt.show()
以上就是Pandas的核心—DataFrame数据结构的生成讲解。