【长文详解】T5: Text-to-Text Transfer Transformer 阅读笔记
点击上方,选择星标或置顶,每天给你送干货 !
!
阅读大概需要72分钟
跟随小博主,每天进步一丢丢


作者:徐啸
知乎专栏:自然语言处理学习之旅
来自:机器学习算法与自然语言处理 公众号
https://zhuanlan.zhihu.com/p/89719631
写在前面
谷歌用一篇诚意满满(财大气粗)的基于实验的综述,试图帮助研究者们「拨开云雾见光明」。论文十分适合该领域的初学者通读,写的十分友好,不过由于涉及到的模型/技术很多,所以遇到不熟悉的部分还是需要自行了解。
本文是对 T5 论文[1]的阅读笔记,原文篇幅很长并且涉及很多模型与技术,我将其视为一份实验报告性质的综述,于是花了较长时间进行阅读与笔记的整理。不过这也导致本文很长(近 3w 字),想要快速阅读的朋友可以直接阅读 2 & 3.1 & 4 部分以及相关图表部分。论文的讨论可以参见该问题。本来想把自己的一些感想加上,不过最近出了ELECTRA,等看完一起写在新一篇笔记里吧。
论文的摘要以及 1-2 部分介绍了 Motivation、数据集的预处理操作、待评估的下游任务以及这些任务为了适应 Text-to-text 框架所需的相关处理。
第 3 部分是最长的实验部分,3.1 介绍了 Text-to-text 框架下使用的基线模型;3.2 介绍了现有的不同模型架构,并对无监督预训练的降噪目标和传统语言建模目标进行实验比较;3.3 对无监督降噪目标进行了细致研究,如图 5 所示,先对前缀语言建模、BERT-style 和 Deshuffling 三种方法进行选择(表 3 提供了各种方法的输入与输出),接着对 BERT-style 的降噪目标进行修改,对 MASS-style、Replace corrupted spans 和 Drop corrupted spans 进行实验,最后对 corruption rate 和 corruption span length 依次实验;3.4 比较了使用不同方法过滤后的 C4 数据集以及常用的预训练数据集,并对预训练数据集(是否重复)进行试验;3.5 对训练方式进行了探究,Baseline 是在无监督降噪任务上对模型的所有参数进行预训练,然后对在每个下游任务上分别对其进行了微调,并使用模型的不同参数设置(检查点)来评估性能,本节进一步的对微调方法、多任务学习方法以及两者的结合进行了实验探究;3.6 对增加计算成本获取性能提升的各种方式进行了探究;3.7 对第 3 部分进行了总结与细节分析。
第 4 部分是基于本文的实验研究以及Text-to-text 框架,对系统实验进行了总结,并对未来的研究进行展望。
如有疏漏之处,还望不吝赐教~
0. Abstract
迁移学习是一种在自然语言处理中强大的技术,模型首先要针对数据丰富的任务进行预训练,然后再针对下游任务进行微调。本文通过引入统一的框架来探索NLP迁移学习技术的前景:将问题都转换为 text-to-text 格式,并在数十种语言理解任务研究比较了预训练目标,架构,未标记的数据集,迁移方法和其他因素。结合实验所得以及 C4 数据集,在许多基准上获得了最新的结果,这些基准涵盖了摘要,问题回答,文本分类等等。
1. Introduction
训练机器学习模型以执行自然语言处理任务通常需要模型能够以适合下游学习的方式处理文本。可以将其大致视为发展通用知识,使模型可以“理解”文本。这些知识的范围从低级(例如单词的拼写或含义)到高级(例如大多数背包都无法容纳大号这样大的乐器)。
在这个迅速发展的领域中,快速的进步和多样的技术可能使不同算法的比较,理清新贡献的效果以及理解现有的迁移学习方法变得困难。为了获得更严谨的理解,我们提出了一种统一的迁移学习方法,使我们能够系统地研究不同的方法,并推动领域发展。
T5 的基本思想是将每个 NLP 问题都视为“text-to-text”问题,即将文本作为输入并生成新的文本作为输出,这允许将相同的模型、目标、训练步骤和解码过程,直接应用于每个任务。
本文的重点不在于提出新方法,而是提供该领域的全面见解。主要贡献在于对现有技术的调查,探索和比较,以及简单且强大的 text-to-text 框架。
2. Setup
介绍 Transformer 模型架构和待评估的下游任务,介绍了将每个问题视为 text-to-text 任务的方法,并描述了 “Colossal Clean Crawled Corpus” C4 数据集,模型和框架称为 “Text-to-Text Transfer Transformer” T5。
2.1 Model
本文研究的所有模型均基于 Transformer 架构。需要注意的是,Transformer 使用正余弦函数的位置编码,BERT 使用的是学习到的位置嵌入,而本文使用的是相对位置嵌入。
相对位置嵌入[2]不是对每个位置使用固定的嵌入,而是根据 self-attention 机制中的“key”和“query”之间的偏移量生成不同的学习嵌入。本文使用位置嵌入的简化形式——每个“嵌入”只是一个标量,被添加到用于计算注意力权重的相应 logit 中。为了提高效率还在模型的所有层之间共享位置嵌入参数,不过每个注意力头使用的是不同“套”位置嵌入。通常学习固定长度的嵌入,每个嵌入对应于一系列可能的key-query偏移量。在这项工作中,我们对所有模型使用 32 个嵌入,其数值范围的大小以对数方式增加,最大偏移量为128,超过此偏移量,所有相对位置使用同一嵌入。需要注意的是,某一给定层对超过 128 的相对位置不敏感,但是后续层可以通过组合来自先前层的局部信息来建立对更大偏移的敏感性。
2.2 The Colossal Clean Crawled Corpus
NLP 迁移学习中,之前的许多工作都是利用大型未标记数据集进行无监督学习。本文试图衡量这类未标记数据集的质量,特征和大小的影响。通过 Common Crawl 抓取网页文本数据,并使用下列启发式方法进行过滤:
只保留以终点符号(即句点,感叹号,问号或引号)为结尾的行
删除任何包含 List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words 中单词的网页
删除包含 Javascript 单词的行
删除出现“lorem ipsum”短语(即排版测试)的所有页面
删除所有包含大括号的页面
对数据集进行重复数据删除,当连续的三句话重复出现时只保留一个
使用 langdetect 工具过滤掉非英文的页面
2.3 Downstream tasks
本文的目的是评估通用语言学习能力,测试如下下游任务的性能:
文本分类:GLUE & SuperGLUE,是测试通用语言理解能力的文本分类任务的集合,包括句子可接受性判断、情绪分析、释义/句子相似度、自然语言推断、指代消解、完成句子、词义消歧和问题回答。
机器翻译:WMT English to German, French, and Romanian translation
文本摘要:CNN/Daily Mail abstractive summarization
智能问答:SQuAD question answering
本文将 GLUE (SuperGLUE也类似) 中所有任务的数据集在微调时连接起来,将所有任务视为一个任务,并且在 SuperGLUE 中加入了 Definite Pronoun Resolution (DPR) 数据集。本模型使用 SQuAD 数据集时是将问题和上下文喂入,并逐个令牌生成答案。机器翻译任务中也仅对英语数据进行预训练,这意味着模型需要学习生成目标语言的文本。
2.4 Input and output format
为了在上述各种任务上训练单个模型,需要在所有任务上保持一致的输入和输出格式。decaNLP[3] 将 10 项不同的任务都写成了 QA 的形式,进行训练与测试 (作者 Socher 在 CS224N里做了介绍,可以参见笔记或原视频),以文本到文本的格式来表达大多数NLP任务,输入上下文或条件文本后输出文本。
该框架为预训练和微调提供了一致的训练目标。具体来说,无论任务如何,都以最大可能性为目标训练模型并使用教师强制。为指定模型执行的任务,需要向原始输入序列添加特定于任务的(文本)前缀后再输入模型。

机器翻译:“That is good.” 英翻德,在输入句子前加上“translate English to German: ”的 prefix ,就会生成句子“Das ist gut.”
文本分类:输出与目标标签对应的单个单词。例如 NLI 任务中输出entailment、contradiction 或 neutral。如果输出的文本与该任务的标签都不符合,则视为错误(不过未在任何经过训练的模型中出现)
一些任务为了适应 Text-to-text 框架,需要进行调整:
STS-B。这是预测 1-5 之间的相似性得分的一项回归任务。作者发现大部分得分是以 0.2 为增量的,于是将分数四舍五入到最接近的 0.2 增量(2.57 四舍五入为 2.6)并将其转为字符串。测试时,如果模型输出字符串对应于 1-5 之间的数字,则转为浮点数进行判断,否则视为错误。这有效地将 STS-B 的回归问题转换为 21 类分类问题。
Winograd任务(WNLI、WSC 和 DPR)转换为一种更适合Text-to-text框架的格式。此类任务的示例是一段包含一个歧义代词的文本,歧义代词可以指代段落中不止一个名词短语。例如:“The city councilmen refused the demonstrators a permit because they feared violence.” 的 “they” 指代的是“city councilmen”还是“demonstrators”。模型将输入中的歧义代词用*包裹以突出:“The city councilmen refused the demonstrators a permit because *they* feared violence.” 并且要求模型输出答案 “city councilmen” 。WSC 数据集的样本由文章、歧义代词、候选名词及对应的 True/False 标签组成,这就无法知晓标签为 False 的样本的歧义代词所指代的名词是什么,因此只在标签为 True 的样本上进行训练(大约删除了 WSC 训练集的一半)。DPR 数据集则很适用上述格式。
WNLI 的训练集和验证集与 WSC 的训练集有很大重叠,为了防止验证集出现在训练集中,不训练 WNLI,并且由于其训练集和验证集之间是对抗的(dev=train+扰动且标签相反),所以也不汇报其验证集的结果。将示例从WNLI转换为上述“指称名词预测”变体的过程要复杂得多,参见附录B。
附录D中提供了研究的每个任务的预处理输入的完整示例。
3. Experiments
NLP 迁移学习的最新进展来自新的预训练目标、模型架构和未标记的数据集等。我们在本节中对这些技术进行了实验研究,希望弄清它们的贡献和重要性。对于更广泛的文献综述,参见 Ruder 等人 NAACL2019 的Tutorial (笔记及资源整理)。
实验每次通过调整某一方面并固定其他的方式来研究该方面的影响,这样的 coordinate descent 方法可能会忽视 second-order effects 二阶效应(例如在当前设置下的某种预训练目标效果不好,但在其他设置下很好,但由于如上实验方法,无法发现),但出于组合探索极其昂贵代价,会在未来的工作中探索。(谷歌都会觉得 prohibitively expensive~)
本文的目标是在保持尽可能多的因素不变的情况下,采用多种不同的方法比较各种任务的效果。为了实现此目标,在某些情况下我们没有完全复制现有方法而是测试本质上相似的方法。
3.1 Baseline
我们使用简单的降噪目标对标准 Transformer(2.1节)进行了预训练,然后分别对我们的每个下游任务进行了微调。我们将在以下小节中描述此实验设置的详细信息。
3.1.1 Model
对于我们的模型,我们使用 Vaswani 等人提出的标准 encoder-decoder Transformer[4]。尽管许多现代的NLP迁移学习方法都使用仅包含 encoder/decoder stack 的 Transformer 架构,我们发现使用标准的 结构在生成和分类任务上均取得了良好的效果。我们将在3.2 节中探讨不同模型架构的性能。

3.1.3 Vocabulary
本文使用 SentencePiece[7] 将文本编码为 WordPiece token。
对于所有实验使用 32,000 个 wordpiece 的词汇表。由于我们最终会微调英语到德语、法语和罗马尼亚语翻译的模型,因此词汇表需要涵盖这些非英语语言——将C4中使用的页面分类为德语,法语和罗马尼亚语。然后我们在10个部分的英语 C4 数据与1个部分的德语,法语或罗马尼亚语的数据的混合物(理解为10 + 3 -> 3*(10+1) 的意思?)上训练了SentencePiece模型。该词汇表在模型的输入和输出之间共享。因此词汇表使模型只能处理预定的固定语言集。
这里需要补充一下 SentencePiece 。基本单元介于字符与单词之间的模型称作 Subword Model 。Byte Pair Encoding 即 BPE,利用了n-gram频率来更新词汇库,而 WordPiece model使用贪心算法来最大化语言模型概率,即选取新的 n-gram 时都是选择使 perplexity 减少最多的n-gram。进一步的,SentencePiece model 将词间的空白也当成一种标记,可以直接处理sentence,而不需要将其 pre-tokenize 成单词,并且能带来更短的句子长度。[8][9]
3.1.4 Unsupervised objective

利用未标记的数据对模型进行预训练并且训练目标不包括标签,(不准确地说)但是却可以教给模型可推广的知识,这将对下游任务有用。NLP的早期迁移学习工作使用语言模型目标。但是,最近有研究表明,“denoising”目标产生了更好的性能,因此它们很快成为标准。降噪目标:训练模型以预测输入中丢失或损坏的令牌。受 BERT 的“masked language modeling”目标和“word dropout ”正则化技术(Decoder 输入为随机替换为 UNK)启发,设计目标如下(本文的 Denoising Objective指的是该目标):随机采样然后丢弃输入序列中15%的标记。所有丢弃令牌组成的连续片段都由单个标记令牌代替(图中的 for inviting 只对应一个标记令牌)。每个标记令牌都分配有该序列唯一的令牌ID。然后对应于所有丢失的令牌范围,目标由输入序列中使用的相同标记令牌加上最终的标记令牌来标记目标序列的末尾来定界(预测输入中的
3.1.5 Baseline performance
本节中使用上述基准实验过程进行实验,以了解预期的一系列下游任务性能。理想情况下,我们应将研究中的每个实验重复多次,以得到结果的置信区间,但由于实验太多过于昂贵,作为一种更便宜的选择,从零开始训练基线模型10次(即使用不同的随机初始化和数据集 shuffle ),并假设基本模型运行的方差也适用于每个实验变体。我们不希望所做的大多数更改会对运行间差异产生重大影响,因此,这应该可以合理地表明不同更改的重要性。另外,我们还评估了在不进行预训练的情况下,对所有下游任务进行 步训练(与用于微调的次数相同)的模型的性能,从而了解预训练对基线设置中的模型有多少有帮助。

需要注意的是 EnFr 对应的是 WMT 中的英语译成法语,这一任务下是否预训练的影响没有特别可观。这是一个足够大的数据集,从预训练中获得的收益往往很小,因此我们将这一任务包括在我们的实验中,以测试高资源体制下的迁移学习行为。
3.2 Architectures
3.2.1 Model structures
Attention masks:不同体系结构的主要区别因素是模型中不同注意力机制所使用的“掩码”。Transformer 中的自注意操作将一个序列作为输入,并输出相同长度的新序列。通过计算输入序列的加权平均值来生成输出序列的每个条目
 图3 是代表不同的注意力掩码矩阵。自我注意机制的输入和输出分别表示为x和y。第 i 行和第 j 列中的黑色单元表示在输出时间步骤 i 允许自我注意机制参与输入元素 j。白色单元格表示不允许自我注意机制参与相应的 i 和 j 组合。
图3 是代表不同的注意力掩码矩阵。自我注意机制的输入和输出分别表示为x和y。第 i 行和第 j 列中的黑色单元表示在输出时间步骤 i 允许自我注意机制参与输入元素 j。白色单元格表示不允许自我注意机制参与相应的 i 和 j 组合。
左:完全可见的掩码。输出的每个时间步会注意全部输入
中:因果掩码。防止第 i 个输出元素依赖于“未来”的任何输入元素
右:带前缀的因果掩码。使自我注意机制可以在输入序列的一部分上使用完全可见的掩码。
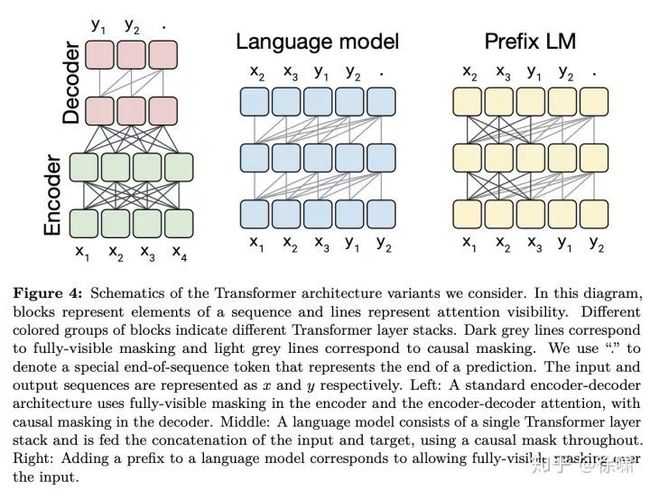 Transformer体系结构变体的示意图。方框代表序列的元素,线条代表注意力的可见度。不同颜色的块组指示不同的 Transformer 层块。深灰色线对应于完全可见的掩码,浅灰色线对应于因果的掩码。我们使用“·”表示表示预测结束的特殊序列结束标记。输入和输出序列分别表示为 x 和 y。
Transformer体系结构变体的示意图。方框代表序列的元素,线条代表注意力的可见度。不同颜色的块组指示不同的 Transformer 层块。深灰色线对应于完全可见的掩码,浅灰色线对应于因果的掩码。我们使用“·”表示表示预测结束的特殊序列结束标记。输入和输出序列分别表示为 x 和 y。
左:标准的编码器-解码器体系结构,在 encoder 和encoder-decoder 注意力中使用完全可见的掩码,在解码器中使用因果掩码。
中:语言模型由一个单独的 Transformer 层块组成,并通过使用因果掩码始终输入输入和目标的串联。
右:在语言模型中添加前缀并对这部分输入使用完全可见的掩码。
Encoder-decoder:图 4 左侧展示了编码器-解码器结构,编码器使用“完全可见”的注意掩码。这种掩码适用于注意“前缀”,即提供给模型的某些上下文,供以后进行预测时使用。BERT也使用了完全可见掩码,并在输入中附加了特殊的“分类”标记。然后,在与分类令牌相对应的时间步中,BERT的输出将用于对输入序列进行分类的预测。
Language model:Transformer 中的解码器用于自回归生成输出序列,即在每个输出时间步,都会从模型的预测分布中选取令牌,然后将选取的令牌再输入到模型中为下一个输出时间步做出预测。这样,可以将 Transformer 解码器用作语言模型,即仅训练用于下一步预测的模型。此架构的示意图如图 4 中间所示。实际上,针对NLP的迁移学习的早期工作使用这种架构并将语言建模目标作为一种预训练方法。
语言模型通常用于压缩或序列生成。但是,它们也可以简单地通过连接输入和目标而用于 text-to-text 框架中。例如,考虑英语到德语的翻译:如果我们有一个训练数据的输入句子为“ That good.”,目标为“Das ist gut.”,那么我们只需在连接的输入序列“translate English to German: That is good. Target: Das ist gut.” 上对模型进行语言模型训练(错位预测)即可。如果我们想获得此示例的模型预测,则向模型输入前缀“translate English to German: That is good. Target: ”,模型自回归生成序列的其余部分。通过这种方式,该模型可以预测给定输入的输出序列,从而满足 text-to-text 任务。这种方法最近被用来表明语言模型可以学会在无监督的情况下执行一些 text-to-text 的任务。
Prefix LM:在 text-to-text 设置中使用语言模型的一个基本且经常被提到的缺点是,因果掩码会迫使模型对输入序列的第 i 个输入的表示仅取决于直到 i 为止的输入部分。在该框架中,在要求模型进行预测之前,为模型提供了前缀/上下文(例如,前缀为英语句子,并且要求模型预测德语翻译)。使用完全因果掩码,前缀状态的表示只能取决于前缀的先前条目。因此,在预测输出的条目时,模型使用的前缀表示是不需要受到限制的,但却由于语言模型而使其前缀表示受到了限制。在序列到序列模型中使用单向递归神经网络编码器也存在类似问题。
只需更改掩码模式,就可以在基于Transformer的语言模型中避免此问题。在序列的前缀部分使用完全可见的掩码。图 3 和 4 的右边分别显示了此掩码模式和前缀LM的示意图。
在上述英语到德语的翻译示例中,将完全可见的掩码应用于前缀“translate English to German: That is good. Target: ”,而因果掩码将在训练期间用于预测目标“Das ist gut.”。在 Text-to-text 框架中使用 prefix LM 最初是由 Generating Wikipedia by Summarizing Long Sequences [10]提出的。最近有工作[11]展示了这种架构对多种 Text-to-text 任务均有效。
我们注意到,当遵循我们的 Text-to-text 框架时,prefix LM体系结构非常类似于分类任务的BERT。以 MNLI 基准为例,前提是“I hate pigeons.”,假设是“My feelings towards pigeons are filled with animosity.”,而正确的标签是“entailment”。为了将此示例输入语言模型,我们将其转换为序列“mnli premise: I hate pigeons. hypothesis: My feelings towards pigeons are filled with animosity. target: entailment”。在这种情况下,完全可见的前缀将对应于整个输入序列,直到单词“target:”,这可以看作类似于BERT中使用的“分类”令牌。因此,我们的模型将对整个输入具有完全的可见性,然后将通过输出单词“entailment”来进行分类。对于给定任务前缀(在这种情况下为“mnli”)的模型,该模型很容易学习输出有效的类标签。这样,prefix LM 和 BERT 架构之间的主要区别在于, 分类器简单地集成到 prefix LM 中的 Transformer 解码器的输出层中 。
3.2.2 Comparing different model structures
为了实验上比较这些体系结构变体,我们希望每个模型在某种意义上都是等效的:如果两个模型具有相同数量的参数,或者它们需要大致相同的计算量来处理给定的(输入序列,目标序列)对,则可以说是等效的。但不可能同时根据这两个标准将编码器-解码器模型与语言模型体系结构(包含单个Transformer块)进行比较。由于在编码器中具有L层且在解码器中具有L层的编码器-解码器模型具有与具有2L层的语言模型大约相同数量的参数。但是,相同的L + L编解码器模型将具有与仅具有 L 层的语言模型大约相同的计算成本,这是因为语言模型中的L层必须同时应用于输入和输出序列,而编码器仅应用于输入序列,而解码器仅应用于输出序列。所以存在参数量不同,但计算量几乎相同的情况。这些等价是近似的——由于对编码器的注意力,解码器中存在一些额外的参数,并且在注意力层中,序列长度为平方的计算量也很大。然而,实际上,我们观察到L层语言模型与L + L层编码器-解码器模型几乎相同的步长时间,这表明计算成本大致相当。
为了提供合理的比较方法,我们考虑了编码器-解码器模型的多种配置。我们将 大小的层块中的层数和参数分别称为 L 和 P 。
我们将使用 M 来指代L + L层编码器-解码器模型或仅L层的解码器模型处理给定输入目标对所需的FLOP数量。
总的来说,我们将进行比较:
在编码器中具有 L 层,在解码器中具有 L 层的编码器-解码器模型。该模型具有 2P 个参数和M FLOP的计算成本。
等效模型,但参数在编码器和解码器之间共享,即 P 个参数和 M FLOP计算成本。
在编码器和解码器中各具有 L / 2 层的编码器-解码器模型,提供 P 参数和 M/2 FLOP成本。
具有 L 层和 P 参数的纯解码器的语言模型,以及由此产生的M FLOP计算成本。
具有相同架构(因此具有相同数量的参数和计算成本),但对输入具有完全可见的自我注意力的解码器的前缀LM。
3.2.3 Objectives
基本语言建模目标以及第 3.1.4 节中描述的降噪目标作为无监督的目标。对于在进行预测之前先提取前缀的模型(编码器-解码器模型和前缀LM),我们从未标记的数据集中采样了一段文本,并选择一个随机点将其分为前缀和目标部分。对于标准语言模型,我们训练模型以预测从开始到结束的整个跨度。我们的无监督降噪目标是为 text-to-text 模型设计的;为了使其适应语言模型,我们将输入和目标连接起来,如3.2.1节所述。
3.2.4 Results

表 2 显示了我们比较的每种架构所获得的分数。对于所有任务,具有降噪目标的编码器-解码器架构表现最佳。此变体具有最高的参数计数(2P),但与仅使用P参数的解码器的模型具有相同的计算成本。令人惊讶的是,我们发现在编码器和解码器之间共享参数几乎同样有效。相反,将编码器和解码器堆栈中的层数减半会严重影响性能。ALBERT 还发现,在Transformer块之间共享参数是可以减少总参数数量而不牺牲太多性能的有效方法。XLNet 与具有降噪目标的共享编码器-解码器方法有些相似。我们还注意到,共享参数编码器-解码器的性能优于仅解码器的前缀LM,这表明增加编码器-解码器的显式注意是有益的。最后,我们确认了一个广为接受的观念,即与语言建模目标相比,使用降噪目标始终可以带来更好的下游任务性能。在以下部分中,我们将对无监督目标进行更详细的探讨。
3.3 Unsupervised objectives
选择无监督目标至关重要,因为它提供了一种机制:模型可以获取通用知识以应用于下游任务。这导致了各种各样的预训练目标的发展。在许多情况下,我们不会完全复制现有目标,而是将某些目标进行修改以适合我们的 Text-to-text 编码器/解码器框架;在其他情况下,我们将使用结合了多种常见方法的概念的目标。
总体而言,我们所有的目标都从未标记的文本数据集中提取一系列与令牌化文本范围相对应的令牌ID。对令牌序列进行处理以产生(损坏的)输入序列和相应的目标。然后,像往常一样训练模型,以最大可能性预测目标序列。
 3.3.1 讨论前三行,3.3.2 讨论后三行。这里的第六行应该是 I.i.d noise, drop spans。
3.3.1 讨论前三行,3.3.2 讨论后三行。这里的第六行应该是 I.i.d noise, drop spans。
表 3 : 以“Thank you for inviting me to your party last week .”作为输入文本,所有的目标都处理tokenized 的文本。词汇表将所有单词映射到单个token,(original text) 作为目标时,该模型的任务是重建整个输入文本。
3.3.1 Disparate high-level approaches
比较三种技术,这些技术受常用目标的启发,但其方法却大不相同。首先,我们引入 3.2.3 节中使用的 prefix LM 目标:将文本的范围分为两个部分,一个部分用作编码器的输入,另一部分用作解码器要预测的目标序列。其次,我们考虑一个受BERT的MLM启发的目标。MLM需要一段文本并破坏15%的令牌。90%的损坏令牌被替换为特殊的掩码令牌,而10%的令牌被替换为随机令牌。由于BERT是只有编码器的模型,因此其目标是在编码器的输出上重建原始序列。在编码器-解码器架构下,我们仅将整个未损坏的序列用作目标。请注意,这与我们仅使用损坏的令牌作为目标的基准目标不同。我们将在3.3.2节中比较这两种方法。最后,我们还考虑了一个基本 deshuffling 目标。此方法采用令牌序列,对其进行随机排序,然后将原始的经过随机排序的序列用作目标。我们在表3的前三行中提供了这三种方法的输入和目标的示例。
 对应表 3 中的前六行,同样的,表 5 的第四行应该是 drop corrupted spans
对应表 3 中的前六行,同样的,表 5 的第四行应该是 drop corrupted spans
表 4 中显示了这三个目标的性能。总的来说,尽管前缀语言建模目标在翻译任务上达到了类似的性能,但我们发现BERT风格的目标表现最佳。确实,实现BERT目标的动机是超越基于语言模型的预训练。相较于前缀语言建模和BERT风格的目标,Deshuffling 目标的性能要差得多。
3.3.2 Simplifying the BERT objective
基于上一节中的结果,我们现在将重点研究对BERT样式降噪目标的修改。该目标最初是作为针对分类和跨度预测而训练的仅编码器模型的预训练技术提出的。对其进行修改以使其在我们的编码器-解码器 Text-to-text 框架中表现更好或更有效。
首先,我们考虑BERT样式目标的一个简单变体,其中不包括随机令牌交换步骤。最终的目标只需用掩码令牌替换输入中15%的令牌,然后训练模型以重建原始的未损坏序列,此变体为“MASS-style”[12]目标。
其次,我们感兴趣的是看看是否有可能避免预测整个未损坏的文本跨度,因为这需要对解码器中的长序列进行自我关注。我们考虑了两种策略来实现此目的:
不是用掩码令牌替换每个损坏的令牌,而是用唯一的掩码令牌替换了每个连续的损坏令牌的范围。然后,目标序列变成“损坏的”跨度的串联,每个跨度都带有用于在输入中替换它的掩码标记的前缀。这是我们在基线中使用的预训练目标,如3.1.4节所述。
我们还考虑了一种变体,其中我们简单地从输入序列中完全删除损坏的令牌,并按顺序构造丢弃的令牌。表3的第五和第六行显示了这些方法的示例。
表 5 中显示了原始BERT-style的目标与这三个变体的比较。我们发现,在我们的设置中,所有这些变体的性能相似。唯一的例外是,drop corrupted tokens 在GLUE上的提升完全是由于CoLA的得分明显更高(60.04,而我们的基准平均值53.84,见表15)。这可能是由于CoLA需要对“给定句子在语法和句法上是否可接受”进行分类,并且“确定何时丢失标记”与“检测可接受性”密切相关。但是,与在SuperGLUE上将其替换为标记令牌相比,丢弃令牌的性能要差得多。不需要预测完整原始序列的两个变体(“replace corrupted spans” and “drop corrupted spans”)都具有潜在的吸引力,因为它们可使目标序列更短,从而使训练更快。展望未来,我们将探索用标记令牌替换损坏的跨度,并仅预测损坏的令牌(如我们的基准目标)的变体。
3.3.3 Varying the corruption rate

到目前为止,我们一直破坏了15%的令牌,即BERT中使用的值。同样,由于我们的 Text-to-text 框架与BERT的框架不同,因此需要查看不同的破坏率。我们在表6中比较了10%,15%,25%和50%的损坏率。总体而言,我们发现损坏率对模型的性能影响有限。唯一的例外是,最大的损坏率(50%)导致GLUE和SQuAD的性能显着下降。使用较大的破坏率还会导致目标更长,这可能会减慢训练速度。根据这些结果以及BERT设定的历史先例,未来将使用15%的破坏率。
3.3.4 Corrupting spans
现在,我们转向通过预测更短的目标来加快训练速度的目标。到目前为止,我们使用的方法是是否要破坏每个输入令牌的独立同分布的决策。如果多个连续标记已损坏,则将它们视为“span 跨度”,并使用单个唯一的掩码标记来替换整个跨度。用单个标记替换整个范围会导致将未标记的文本数据处理为较短的序列。由于我们使用的是独立同分布的损坏策略,并非总是会出现大量损坏的令牌的情况。因此,我们可以通过专门破坏令牌的跨度而不是破坏独立同分布的单个令牌来获得额外的加速。破坏跨度以前也曾被认为是BERT的预训练目标,发现它可以提高性能。
为了测试这个想法,我们考虑:专门破坏连续的,随机分布的令牌跨度。可以通过要破坏的令牌比例和破坏跨度的总数来参数化该目标。然后随机选择跨度长度以满足这些指定参数。例如,如果我们正在处理500个令牌的序列,并指定应损坏15%的令牌,并且应该有25个跨度,那么损坏令牌的总数将为500×0.15 = 75,平均跨度长度将为75/25 =3。请注意,给定原始序列长度和损坏率,我们可以通过平均跨度长度或跨度总数等效地参数化此目标。
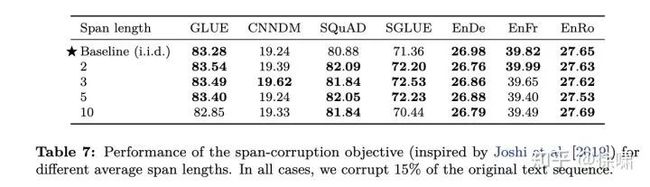
我们在表7中将跨度破坏目标与独立同分布的破坏目标进行比较。在所有情况下,破坏率均为15%,并使用平均跨度长度为2、3、5和10进行比较。同样,我们发现在这些目标之间差异有限,尽管平均跨度长度为10的版本在某些情况下稍逊于其他值。我们还特别发现,使用3的平均跨度长度略微(但显着)优于独立同分布目标(即第一行,随机选择 token 并将连续的 token 再视为 span 进行替换)的大多数非翻译基准。幸运的是,与独立同分布噪声方法相比,跨度破坏目标还提供了训练期间的一些加速,因为跨度损坏会产生较短的序列。
3.3.5 Discussion
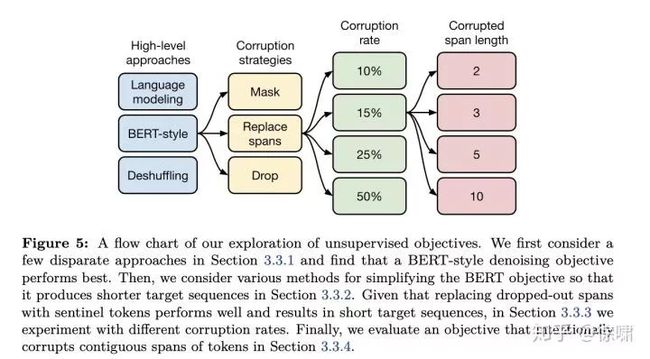
图 5 显示了在我们探索无监督目标过程中所做选择的流程图。总体而言,我们观察到的性能上最显着的差异是在预训练中,降噪目标的性能优于语言建模和Deshufling的变体。在我们探索的降噪目标的许多变体之间,我们没有观察到显着差异。但是,不同的目标(或目标的参数化)可能导致不同的序列长度,从而导致不同的训练速度。这意味着我们在此处考虑的降噪目标之间的选择应主要根据其计算成本进行。我们的结果还表明,与我们在此考虑的目标类似的其他目标探索可能不会导致我们所考虑的任务和模型有重大收获。相反,探索利用未标记数据的完全不同的方法可能是偶然的。
3.4 Pre-training dataset
本节将比较 C4 数据集的变体和其他潜在的预训练数据源。
3.4.1 Unlabeled datasets
第2.2节讲述了很多建立 C4 数据集时使用的启发式方法。除了将其与其他过滤方法和常见的预训练数据集进行比较之外,我们有兴趣测量这种过滤是否会改善下游任务的性能。为此,我们在以下数据集上进行预训练后比较基线模型的性能:
C4:作为基准,首先在我们发布的未标记数据集进行预训练。
Unfiltered C4:为了衡量我们在创建C4中使用的启发式过滤的效果,我们还生成了C4的替代版本,该版本放弃了过滤。请注意,我们仍然使用 langdetect 提取英文文本。结果,我们的“未过滤”变体仍包含一些过滤,因为 langdetect 有时会给不自然的英语文本分配低概率。
RealNews-like:使用了从新闻网站提取的文本数据。为了进行比较,我们额外过滤C4使其仅包括一个“RealNews”数据集对应的域的内容来生成另一个未标记的数据集。请注意,为便于比较,我们保留了C4中使用的启发式过滤方法。唯一的区别是,表面上我们忽略了任何非新闻内容。
WebText-like:WebText数据集仅使用提交到内容聚合网站 Reddit 且收到的“score”至少为3的网页内容。提交给Reddit的网页得分基于认可或反对网页的用户比例。使用Reddit分数作为质量信号的背后想法是,该网站的用户只会上传高质量的文本内容。为了生成可比较的数据集,我们首先尝试从C4中删除所有不是 OpenWebText[13] 列表中出现的URL。但是,由于大多数页面从未出现在Reddit上,因此内容相对较少,仅约 2 GB。为避免使用过小的数据集,因此我们从2018年8月至2019年7月从 Common Crawl 下载了12个月的数据,对 C4 和 Reddit 应用了启发式过滤,产生了一个17 GB的类似 WebText 的数据集,其大小与原始40GB的 WebText 数据集相类似。
Wikipedia:Wikipedia网站包含数以百万计的协作撰写的百科全书文章。该网站上的内容受严格的质量准则约束,因此已被用作可靠且纯净的自然文本来源。我们使用 TensorFlow Datasets[14] 的英文 Wikipedia 文本数据,其中省略了文章中的任何标记或参考部分。
Wikipedia + Toronto Books Corpus:使用来自 Wikipedia 的预训练数据的缺点是,它仅表示自然文本的一个可能域(百科全书文章)。为了缓解这种情况,BERT将来自维基百科的数据与多伦多图书公司进行了组合。TBC包含从电子书中提取的文本,它代表自然语言的不同领域。
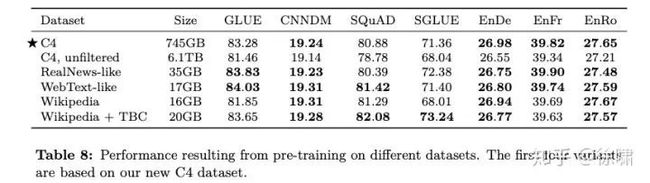
表 8 显示了每个数据集预训练后获得的结果。第一个明显的收获是,C4中删除启发式过滤会降低性能,并使未过滤的变体在每个任务中表现最差。除此之外,我们发现在某些情况下,具有更受限域的预训练数据集的性能优于多样化的C4数据集。例如,使用Wikipedia + TBC语料库产生的SuperGLUE得分为73.24,超过了我们的基准得分。这几乎完全归因于MultiRC的完全匹配得分从25.78(基准C4)提高到50.93(Wikipedia + TBC)(参见表15)。MultiRC是一个阅读理解数据集,其最大数据来源来自小说书,而这恰恰是TBC覆盖的领域。类似地,使用类似RealNews 的数据集进行预训练可使 ReCoRD 的精确匹配得分从68.16提高到73.72,ReCoRD是测量新闻文章阅读理解的数据集。最后一个例子是,使用来自Wikipedia的数据在 SQuAD上获得了显着(但并没那么突出)的收益,SQuAD是一个使用来自 Wikipedia 的段落的问题解答数据集。这些发现背后的主要教训是,对域内未标记的数据进行预训练可以提高下游任务的性能。如果我们的目标是预训练可以快速适应来自任意领域的语言任务的模型,这将不足为奇,但也不令人满意。
仅在单个域上进行预训练的一个缺点是所得的数据集通常要小得多。类似地,虽然在我们的基准设置中类似WebText的变体在性能上类似或优于C4数据集,并且基于Reddit的过滤所产生的数据集比C4小约 40 倍,但它是基于Common Crawl的 12 倍以上数据而建立的。在以下部分中,我们将研究使用较小的预训练数据集是否会引起问题。
3.4.2 Pre-training dataset size
本文创建C4的方法旨在能够创建非常大的预训练数据集。对大量数据的访问使我们能够对模型进行预训练,而无需重复样本。目前尚不清楚在预训练期间重复样本是会对下游性能有所帮助还是有害,因为我们的预训练目标本身就是随机的,并且可以帮助防止模型多次看到相同的数据。

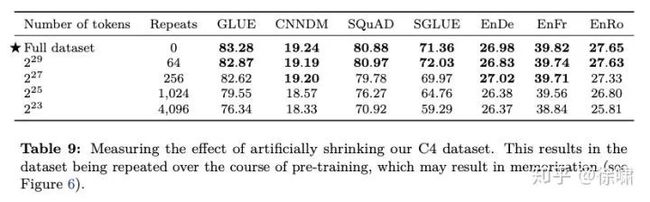
最终的下游性能如表9所示,随着数据集大小缩小而下降。我们怀疑这可能是由于该模型开始记住预训练数据集。为了测量这是否成立,我们在图6中绘制了每种数据集大小的训练损失。的确,随着预训练数据集的大小缩小,该模型获得的训练损失明显较小,这表明可能存在记忆。

我们注意到,当预训练数据集仅重复 64 次时,这些影响是有限的。这表明一定程度的重复预训练数据可能不会有害。但是,考虑到额外的预训练可能是有益的(我们将在第3.6节中显示),并且获取额外的未标记数据既便宜又容易,我们建议尽可能使用大型的预训练数据集。
3.5 Training strategy
到目前为止,我们已经考虑了以下设置:在无监督的任务上对模型的所有参数进行预训练,然后对个别有监督的任务进行微调。 尽管这种方法很简单,但现在已经有了各种用于在下游/监督任务上训练模型的替代方法。在本节中,除了在多个任务上同时训练模型的方法之外,我们还比较了用于微调模型的不同方案。
3.5.1 Fine-tuning methods
有人认为,微调模型的所有参数可能会导致结果欠佳,尤其是在资源匮乏的情况下。文本分类任务的迁移学习的早期结果提倡仅微调小型分类器的参数。 这种方法不太适用于我们的编码器-解码器模型,因为必须训练整个解码器以输出给定任务的目标序列 。相反,我们专注于两种替代的微调方法,这些方法仅更新编码器-解码器模型的参数的子集。
第一种:“adapter layers”[15]的动机是在微调时保持大多数原始模型固定不变。适配器层是附加的dense-ReLU-dense块,这些块在变压器的每个块中的每个预先存在的前馈网络之后添加。这些新的前馈网络的设计使其输出维数与其输入相匹配。这样就可以将它们插入网络,而无需更改结构或参数。进行微调时,仅更新适配器层和层归一化参数。这种方法的主要超参数是前馈网络的内部维数 d ,它改变了添加到模型中的新参数的数量。我们用 d 的各种值进行实验。
第二种替代性微调方法是“gradual unfreezing”[6]。在逐步解冻过程中,随着时间的流逝,越来越多的模型参数会进行微调。逐步解冻最初应用于包含单个块层(a single stack of layers)的语言模型体系结构。在此设置中,微调开始时仅更新最后一层的参数,然后在训练了一定数量的更新之后,就会更新包括倒数第二层的参数,依此类推,直到整个网络的参数都在微调。为了使这种方法适应我们的编码器-解码器模型,我们从顶部开始逐渐并行地解冻编码器和解码器中的层。由于我们的输入嵌入矩阵和输出分类矩阵的参数是共享的,因此我们会在整个微调过程中对其进行更新。

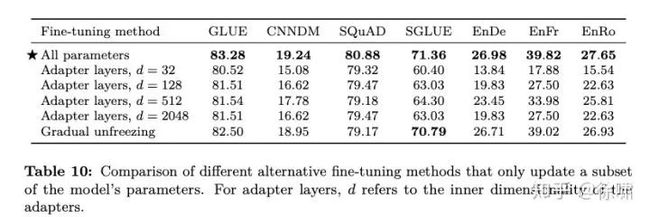
表 10 显示了这些微调方法的性能比较。对于适配器层,我们使用32、128、512、2048的内部尺寸 d 。根据过去的结果我们发现像 SQuAD 这样的资源较少的任务在 d 较小的情况下效果很好,而资源较高的任务则需要较大的维度才能实现合理的性能。这表明,adapter layers 可能是一种在较少参数上进行微调的有前途的技术,只要将维度适当地缩放到任务大小即可。请注意,在我们的案例中,我们通过将 GLUE 和 SuperGLUE 的各自的子数据集连接起来,将它们分别视为一个“任务”,因此,尽管它们包含一些资源较少的数据集,但组合的数据集足够大,因此需要较大的 d 值。我们发现, 尽管在微调过程中确实提供了一定的加速,但全局解冻会在所有任务中造成轻微的性能下降。通过更仔细地调整解冻时间表,可以获得更好的结果。
3.5.2 Multi-task learning
到目前为止,我们已经在单个无监督学习任务上对我们的模型进行了预训练,然后在每个下游任务上分别对其进行了微调。另一种方法称为“多任务学习”,在多个任务上同时训练模型。这种方法通常的目标是训练可以同时执行许多任务的单个模型,即该模型及其大多数参数在所有任务之间共享。我们在某种程度上放松了这一目标,而是一次研究了针对多个任务进行训练的方法,以便最终产生对每个任务都执行良好的独立参数设置。例如, 我们可能会针对多个任务训练一个模型,但是在报告性能时,我们可以为每个任务选择不同的检查点 。与目前为止我们所考虑的 pre-train-then-fine-tune 方法相比,这放松了多任务学习框架的要求并使之处于更稳定的基础上。我们还注意到,在我们统一的 Text-to-text 框架中,“多任务学习”仅对应于将数据集混合在一起。相比之下,大多数将多任务学习应用于NLP的应用都会添加特定于任务的分类网络,或者为每个任务使用不同的损失函数。
正如Arivazhagan等人指出,在多任务学习中一个非常重要的因素是模型应该在每个任务的多少数据进行训练。我们的目标是不对模型进行 under- or over-train 过少训练或过度训练——也就是说,我们希望模型从给定任务中看到足够的数据以使其能够很好地执行任务,但又不想看到太多数据以致于记住训练集。
如何准确设置每个任务的数据比例取决于各种因素,包括数据集大小,学习任务的“难度”(即模型在有效执行任务之前必须看到多少数据),正则化等。
另一个问题是潜在的“任务干扰”或“负向转移”,在一个任务上实现良好的性能会阻碍在另一任务上的性能。鉴于这些问题,我们先探索各种设置每个任务的数据比例的策略。Wang [16]等人进行了类似的探索。
Examples-proportional mixing: 模型适应给定任务的速度的主要因素是任务数据集的大小。因此,设置混合比例的自然方法是根据每个任务数据集的大小按比例进行采样。这等效于串联所有任务的数据集并从组合数据集中随机采样示例。但是请注意,我们引入了无监督降噪任务,该任务使用的数据集比其他所有任务的数量级大。因此,如果我们仅按每个数据集的大小按比例进行采样,该模型看到的绝大多数数据将是无标签的,并且所有监督任务都会缺乏训练(under-train)。即使没有无监督的任务,某些任务(例如WMT英语到法语)也很大,以至于它们同样会占据大多数批次。为了解决这个问题,我们在计算比例之前对数据集的大小设置了人为的“限制”。具体来说,第N个任务的每个数据集中的示例数为 ,则,然后我们将训练期间从第 m 个任务采样的概率设置为  ,其中 K 为人工数据集大小限制。
,其中 K 为人工数据集大小限制。

Equal mixing:在这种情况下,我们以相等的概率从每个任务中抽取示例。具体来说,每个批次中的每个示例都是从我们训练的数据集中随机抽样的。这很可能是次优策略,因为该模型将在资源不足的任务上快速过拟合,而在资源过多的任务上不充分拟合。我们主要将其作为参考当比例设置不理想时可能出现的问题。
为了将这些混合策略在相同的基础上与我们的基线 pre-train-then-fine-tune 结果进行比较,我们以相同的总步数训练了多任务模型: 

总的来说,我们发现多任务训练的效果不如预训练后对大多数任务进行微调。特别是“均等”的混合策略会导致性能急剧下降,这可能是因为低资源任务过度拟合,高资源任务没有看到足够的数据,或者模型没有看到足够的未标记数据以学习通用语言能力。对于Examples-proportional mixing的示例,我们发现对于大多数任务,K 都有一个“最佳点”,在该点上模型可以获得最佳性能,而K值较大或较小都会导致性能变差。(对于我们考虑的K值范围)WMT英语到法语的翻译是个例外,这是一项资源非常丰富的任务,它总是受益于更高的混合比例。最后,我们注意到 Temperature-scaled mixing 提供了一种从大多数任务中获得合理性能的方法,其中 T = 2 在大多数情况下表现最佳。在以下部分中,我们将探讨缩小多任务训练与 pre-train-then-fine-tune 方法之间差距的方法。
3.5.3 Combining multi-task learning with fine-tuning
回想一下,我们正在研究多任务学习的宽松版本:我们在混合任务上训练单个模型,但允许使用模型的不同参数设置(检查点)来评估性能(注意,预训练时是只有单一无监督任务的)。我们可以通过考虑以下情况来扩展此方法:模型同时针对所有任务进行预训练,然后针对有监督的单个任务进行微调。这是“MT-DNN”[17]使用的方法,该方法在推出时就达到了GLUE和其他基准的最新性能。
首先,模型在 Examples-proportional mixing 的人工混合数据集上预训练模型,然后在每个单独的下游任务上对其进行微调。 这有助于我们衡量在预训练期间是否将监督任务与无监督目标一起包括在内,可以使模型对下游任务有一些有益的早期暴露 。我们也希望,可能在许多监督源中进行混合可以帮助预训练的模型在适应单个任务之前获得更为通用的“技能”(宽松地说)。
为了直接测量这一点,我们考虑第二个变体,其中我们在相同的混合数据集上对模型进行预训练,只是从该预训练混合物中省略了一项下游任务。然后,我们在预训练中遗漏的任务上对模型进行微调。对于我们考虑的每个下游任务,我们都会重复此步骤。我们称这种方法为“leave-one-out”多任务训练。这模拟了真实的设置,在该设置中,针对未在预训练中看到的任务微调了预训练模型。
因此,对于第三个变体,我们对所有考虑的监督任务进行预训练。

我们在表 12 中比较了这些方法的结果。为进行比较,我们还包括基线和标准多任务学习的结果。我们发现,多任务预训练后的微调可以使性能与我们的基准相当。这表明在多任务学习之后使用微调可以帮助减轻第 3.5.2 节中描述的不同混合比率之间的某些权衡。有趣的是,“leave-one-out”训练的性能仅稍差一些,这表明针对各种任务训练的模型仍然可以适应新任务(即多任务预训练可能不会产生严重的任务干扰)。最后,除了翻译任务外,在所有情况下,有监督的多任务预训练的表现都明显较差。这可能表明翻译任务从(英语的)无监督预训练中受益较少,而无监督预训练则是其他任务中的重要因素。
3.6 Scaling
机器学习研究的“惨痛教训”认为,利用额外计算的通用方法最终会胜过依赖于人类专业知识的方法。最近的结果表明,这可能适用于NLP中的迁移学习,例如一再证明的扩大规模可以提高性能。但是,有多种可能的缩放方法,包括使用更大的模型,训练模型更多步骤以及进行组合。在本节中,我们通过解决以下前提“获得了 4 倍的计算能力该如何使用它?”来比较这些不同的方法

模型查看 4 倍数据的另一种方法是将批处理大小增加 4 倍。由于更有效的并行化,这有可能导致更快的训练。但是,以 4 倍大的批次大小进行训练会产生与以 4 倍多的步骤进行训练不同的结果。我们包括一个额外的实验,在该实验中,我们将基线模型训练的批次大小提高了 4 倍,以比较这两种情况。
我们认为,在许多基准测试中,通常的做法是通过使用集成模型进行训练和评估来获得额外的性能。这提供了利用附加计算的正交方式。为了将其他缩放方法与集成发放进行比较,我们还测量了 4 个分别进行预训练和微调的模型的集成的性能。我们将整个集成模型中的 logits 取平均,然后将它们输入到 output softmax nonlinearity 中,以获得汇总预测。代替预先训练 4 个单独的模型,更便宜的选择是采用一个预先训练的模型并产生4个单独的微调版本。虽然这不会占用我们的全部 4 倍计算预算,但我们还包括此方法,以查看它是否比其他缩放方法具有竞争优势。
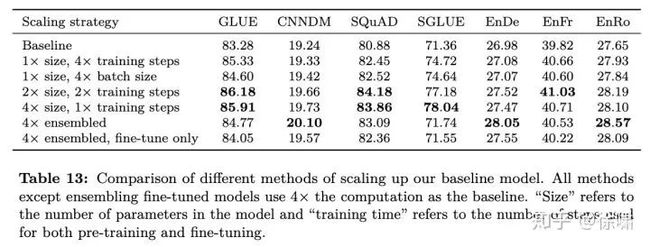
表 13 中显示了应用这些各种缩放方法后获得的性能。毫不奇怪,增加训练时间和/或模型大小会持续改善基线。在进行 4 倍步数训练或使用 4 倍大批量大小的训练之间,尽管两者都是有益的,但没有明显的赢家。通常,与仅增加训练时间或增加批处理大小相比,增加模型大小会导致额外的性能提升。在我们研究的任何任务上,训练一个 2 倍大的模型达到 2 倍长和训练一个4 倍大模型之间,我们没有观察到很大的区别。这表明增加训练时间和增加模型大小可以是提高性能的补充手段。我们的结果还表明,集成提供了一种通过规模来改善性能的正交有效方法。在某些任务中(CNN/DM,EnDe 以及 EnRo ),集成了 4 个完全独立训练的模型,其性能明显优于其他缩放方法。预训练但分别进行微调的集成模型也使性能大大超过了基线,这以更便宜的方式提高性能。唯一的例外是SuperGLUE,在这两种方法中,两种方法都不比基线有明显改善。
我们注意到,不同的缩放方法需要与不同的性能进行权衡。例如,使用较大的模型可能会使下游的微调和推断变得更加昂贵。相反,如果将一个较小的模型进行较长时间的预训练,如果将其应用于许多下游任务,则可以有效地摊销该成本。另外,我们注意到,集成 N 个单独的模型与使用具有 N 倍高的计算成本的模型具有相似的成本。因此,在缩放方法之间进行选择时,一定要考虑模型的最终用途。
3.7 Putting it all together
现在,我们利用系统研究的见解来确定我们可以在流行的NLP基准上提高性能的程度。我们也有兴趣通过在大量数据上训练更大的模型来探索NLP迁移学习的当前限制。我们从基线训练方法开始,进行以下更改:
Objective:我们将独立同分布的降噪目标替换为第3.3.4节中描述的 span-corruption 目标,这是受 SpanBERT[18]启发。具体来说,我们使用平均跨度长度 3 ,破坏原始序列的15%。我们发现,该目标产生了略微更好的性能(表 7) ,并且由于目标序列长度较短,其计算效率略高。
Longer training:我们的基线模型使用相对较少的预训练步骤(BERT的 1⁄4 倍,XLNet的 1⁄16 倍,RoBERTa的 1⁄64)。幸运的是,C4足够大,我们可以训练更长的时间而无需重复数据(这可能是有害的,如3.4.2节所示)。我们在3.6节中发现,额外的预训练确实可以提供帮助,并且增加批次大小和增加训练步骤数量都可以带来这一好处。因此,我们以  个长度为512的序列的批次大小对模型进行了100万步的预训练,相当于总共约 1 万亿个预训练令牌(大约是我们基准的 32 倍)。
个长度为512的序列的批次大小对模型进行了100万步的预训练,相当于总共约 1 万亿个预训练令牌(大约是我们基准的 32 倍)。
在3.4.1节中,我们显示了在类似RealNews,WebText和Wikipedia + TBC数据集上的预训练在一些下游任务上优于在C4上的预训练。
但是,这些数据集变体非常小,以至于在对1万亿令牌进行预训练的过程中,它们会重复数百次。
由于我们在3.4.2节中表明了这种重复可能是有害的,因此我们选择继续使用C4数据集。
Model sizes:在3.6节中,我们还展示了如何扩大基准模型大小以提高性能。但是,在有限用于微调或推理的计算资源的设置下,使用较小的模型可能会有所帮助。基于这些因素,我们训练了各种尺寸的模型:

Multi-task pre-training:在3.5.3节中,我们显示了在微调之前对无监督任务和有监督任务的多任务混合进行预训练以及仅对无监督任务进行了预训练。这是“MT-DNN”[17]提倡的方法。它还具有实际的好处,即能够在整个训练期间(而不只是在微调期间)监视“下游”性能。因此,我们在最后一组实验中使用了多任务预训练。我们假设接受较长时间训练的较大模型可能会从较大比例的未标记数据中受益,因为它们更可能过度拟合较小的训练数据集。但是,我们还注意到,第3.5.3节的结果表明,在多任务预训练后进行微调可以减轻因选择未标记数据的次优比例而可能引起的一些问题。基于这些想法,在使用标准 example-proportional mixing(在第3.5.2节中介绍)之前,我们将以下人工数据集大小替换为未标记的数据:Small 710,000,Base 2,620,000,Large 8,660,000,3B 33,500,000和11B 133,000,000。对于所有模型变体,我们还在预训练期间将WMT EnFr 和 EnDe 的数据集的有效数据集大小限制为 100 万个示例。
Fine-tuning on individual GLUE and SuperGLUE tasks:到目前为止,在 GLUE 和 SuperGLUE 上进行微调时,我们已将这两个基准测试中的所有数据集分别连接在一起,因此我们仅对GLUE和SuperGLUE各微调一次模型。这种方法使我们的研究在逻辑上更加简单,但是我们发现与单独微调任务相比,这在某些任务上牺牲了少量的性能。微调各个任务的潜在问题(可以通过一次训练所有任务来缓解)可能会导致我们对资源不足的任务过拟合。例如,  个长度为 512 个序列的批处理大小将导致整个数据集在许多低资源的 GLUE 和 SuperGLUE 任务的每次批处理中出现多次。
个长度为 512 个序列的批处理大小将导致整个数据集在许多低资源的 GLUE 和 SuperGLUE 任务的每次批处理中出现多次。
因此,在 GLUE 和 SuperGLUE 任务的微调期间,我们使用 8 个长度为 512 个序列的较小批处理大小。
我们还会每 1000 步而不是每 5,000 步保存检查点,以确保可以访问在模型过拟合之前的模型参数。
我们针对 GLUE / SuperGLUE 混合以及每个任务分别都微调了模型。
然后,我们根据每个任务的验证集性能,从混合微调或单个任务微调中选择最佳检查点。
具体来说,我们使用在 GLUE 或 SuperGLUE 混合物上微调的 STS-B,QQP,RTE,BoolQ,COPA和MultiRC的模型,并对所有其他任务使用经过单独微调的模型。
Beam search:我们所有以前的结果都是使用贪婪解码来报告的。对于具有较长输出序列的任务,我们发现使用波束搜索可以提高性能。具体来说,对于WMT翻译和CNN / DM摘要任务,我们使用 4 的beam width和 的长度损失。
Test set:由于这是我们的最后一组实验,我们对测试集而不是验证集报告结果。对于CNN/Daily Mail,我们使用的数据集分布的标准测试集。对于 WM T任务,这对应于对英语-德语使用 newstest2014,对英语-法语使用 newstest2015 和对英语-罗马尼亚语使用 newstest2016 。对于 GLUE 和 SuperGLUE ,我们使用基准评估服务器来计算官方测试集分数。对于 SQuAD ,在测试集上进行评估需要在基准服务器上运行推理。不幸的是,该服务器上的计算资源不足以从我们最大的模型中获得预测。结果,我们改为继续报告SQuAD验证集的性能。幸运的是,在 SQuAD 测试集上性能最高的模型也在验证集上报告了结果,因此我们仍然可以与现在的最新技术进行比较。
除了上述更改之外,我们使用与基线相同的训练过程和超参数(AdaFactor优化器,用于预训练的 inverse square root 计划,用于微调的恒定学习率,dropout 正则化,词汇表等)。作为参考,这些详细信息在第2节中进行了描述。
最后一组实验的结果显示在表 14 中。总的来说,我们在考虑的24个任务中的 17 个上达到了最先进的性能。不出所料,我们最大的模型(参数为110亿)在所有任务的模型大小变体中表现最佳。我们的T5-3B模型变体确实在一些任务上超越了现有技术,但是将模型大小扩展到110亿个参数是实现我们最佳性能的最重要因素。现在,我们分析每个基准的结果。
我们的 GLUE 平均得分为 89.7。有趣的是,在某些任务(CoLA,RTE和WNLI)上,我们的性能大大优于以前的最新技术,而在其他任务(QNLI和MRPC)上,我们的性能则明显差。RTE和 WNLI 是机器性能历来落后于人类性能的两项任务,分别为93.6和95.9。我们在 QNLI 上的表现较差,可能是由于以下事实:该任务上的大多数最佳模型使用特殊的成对排名公式,该公式在进行预测时会整合来自多个样本的信息。但是,我们在未在 QNLI 上使用这种方法的模型的表现优于其他模型。在参数数量方面,我们的 11B 模型变量是已提交给 GLUE 基准测试的最大模型。但是,大多数得分最高的模型都使用大量的集成和计算来产生预测。例如,实现了先前技术水平的 ALBERT 的变体使用的模型在大小和架构上与我们的3B变体相似(尽管由于巧妙的参数共享,其参数大大减少了)。为了在GLUE上产生更好的性能,ALBERT作者根据任务将“from 6 to 17”个模型组合在一起。这可能导致使用 ALBERT 集成进行预测要比使用 11B 变体进行计算更加昂贵。
对于 SQuAD,我们在精确匹配和 F1 指标上均比以前的最新技术高出约一个点。SQuAD 是建立于三年前的长期基准,最近的改进仅使最新技术水平提高了一个百分点。我们注意到,当在测试集上报告结果时,它们通常基于一组模型和/或利用外部数据集来扩充小型SQuAD训练集。精确匹配和 F1 指标在SQuAD上的人类表现估计分别为82.30和91.22 ,因此尚不清楚在此基准上进行进一步的改进是否有意义。
对于 SuperGLUE,我们对最新技术进行了大幅度改进(从84.6的平均得分提高到88.9)。SuperGLUE 的设计任务是“超出当前最先进系统的范围,但可以由大多数受过大学教育的英语语言使用者解决”。我们的人类表现几乎达到了89.8。有趣的是,在阅读理解任务(MultiRC和ReCoRD)上,我们的表现远远超出了人类的表现,这表明用于这些任务的评估指标可能偏向于机器做出的预测。在另一方面,人类在两个 COPA 和 WSC 的准确率为100%,比我们的模型中的表现好得多。这表明,仍然存在语言上的任务是我们的模型难以完善的,尤其是在资源匮乏的环境中。
在任何WMT翻译任务中,我们都没有达到最先进的性能。这可能部分是由于我们使用了仅英语的未标记数据集。我们还注意到,在这些任务上,大多数最佳结果都使用了backtranslation,这是一种复杂的数据增强方案。在资源匮乏的英语到罗马尼亚语基准方面的最新技术还使用了其他形式的跨语言无监督训练。我们的结果表明,规模和英语预训练可能不足以匹配这些更复杂的方法的性能。更具体地说,英语到德语 newstest2014 的最佳结果使用了 WMT2018 更大的训练集,很难直接与我们的结果进行比较。
最后,尽管在 ROUGE-2-F 得分上仅达到相当高的水平,但在 CNN/Daily Mail 上,我们获得了最先进的性能。已经显示,对 ROUGE 分数的改进不一定对应于更连贯的摘要。此外,尽管将CNN/Daily Mail作为抽象摘要的基准,但已证明纯粹的提取方法行之有效。也有人认为,以最大可能性训练的生成模型易于产生重复的摘要。尽管存在这些潜在问题,我们发现我们的模型确实能够生成连贯且基本正确的摘要。我们在附录 C 中提供了一些未经特别挑选的验证集示例。
4 Reflection
完成我们的系统研究后,我们首先总结一些最重要的发现。我们的研究结果提供了一些我们认为更有希望的研究途径的高层次的观点。总而言之,我们概述了一些我们认为可以为进一步发展该领域提供有效方法的主题。
4.1 Takeaways
Text-to-text:我们的 Text-to-text 框架提供了一种简单的方法,可以在各种文本任务上使用相同的损失函数和解码步骤训练单个模型。我们展示了如何将该方法成功地应用于生成任务,例如抽象摘要,分类任务(例如自然语言推断),甚至回归任务(例如STS-B)。尽管简单,但我们发现Text-to-text框架的性能与特定于任务的体系结构的性能是可比的,并且在与规模结合时产生了最佳的结果。
Architectures:尽管有关NLP的迁移学习的一些工作已考虑了Transformer的体系结构变体,但我们发现原始的编码器/解码器形式在我们的 Text-to-text 框架中效果最好。尽管编码器/解码器模型使用的参数是“仅编码器”(例如BERT)或“仅解码器”(语言模型)体系结构的两倍,但其计算成本却相似。我们还表明,在编码器和解码器中共享参数不会导致性能下降,并且使得总参数数量减半。
Unsupervised objectives:总体而言,我们发现大多数训练模型以重建随机损坏文本的“denoising”目标在 Text-to-text 框架中的性能相似。因此,我们建议使用可产生短目标序列的目标,以便无监督的预训练在计算上更加有效。
Datasets:我们引入了“Colossal Clean Crawled Corpus” C4,其中包含来自Common Crawl web dump的启发式清理的文本。 将 C4 与使用额外过滤的数据集进行比较时,我们发现对域内未标记数据的训练可以提高一些下游任务的性能。但是,约束到单个域通常会导致数据集较小。我们分别表明,当未标记的数据集足够小以至于在预训练过程中重复多次时,性能可能会下降。这促使使用大量不同的数据集(如C4)来进行通用语言理解任务。
Training strategies:我们发现尽管更新所有参数最昂贵,但是在微调期间更新预训练模型的所有参数的基本方法优于旨在更新较少参数的方法。 我们还尝试了多种方法来一次在多个任务上训练模型,这在我们的Text-to-text框架中仅对应于在构建批处理时混合来自不同数据集的示例。多任务学习中的主要问题是设置要继续训练的每个任务的比例。我们最终没有找到一种设置混合比例的策略,该策略与无监督的预训练和有监督的微调的基本方法的性能相匹配。但是,我们发现,在对各种任务进行预训练后进行微调可以产生与无监督预训练相当的性能。
Scaling:我们比较了利用额外计算的各种策略,包括在更多数据上训练模型,训练更大的模型以及使用一组模型。我们发现每种方法都可以显着提高性能,尽管通过在较少的步骤上训练更大的模型通常比在较小的模型上训练更多的数据要好。我们还表明,与单个模型相比,一组集成模型可以提供实质上更好的结果,后者提供了一种利用附加计算的正交方式。从同一预训练模型进行分别微调所构成的集成模型的效果要比所有模型分别进行预训练和微调的效果差,不过仍远胜于单个模型。
Pushing the limits:我们结合了上述见解,并训练了更大的模型(最多 110 亿个参数),从而在我们考虑的许多基准测试中均获得了最新的结果。对于无监督训练,我们从C4数据集中提取文本并应用降噪目标,该目标会破坏连续范围的令牌。在对单个任务进行微调之前,我们对多任务混合进行了预训练。总体而言,我们的模型已针对超过1万亿 tokens 进行了训练。为了促进结果的复制,扩展和应用,我们发布了每个 T5 变体的代码,C4 数据集和预训练的模型权重。
4.2 Outlook
The inconvenience of large models:我们的研究得出的不令人惊讶但重要的结果是,较大的模型往往表现更好。用于运行这些模型的硬件不断变得更便宜和更强大的事实表明,扩大规模可能仍然是实现更好性能的有前途的方法。但是,在某些应用程序和场景中,总是存在使用较小或较便宜的模型有帮助的情况,例如在执行客户端推断或联合学习时。相关地,迁移学习的一种有益用途是在低资源任务上获得良好性能的可能性。低资源任务通常(根据定义)发生在缺乏资产以标记更多数据的环境中。因此,低资源应用程序通常也对计算资源的访问受到限制,这可能会导致额外的成本。因此,我们提倡研究使用更便宜的模型实现更强性能的方法,以便将迁移学习应用于影响最大的地方。这些方面目前的一些工作包括 distillation 蒸馏,parameter sharing 参数共享和 conditional computation 条件计算。
More efficient knowledge extraction:回想一下,预训练的目标之一是(宽松地说)为模型提供通用的“知识”,以提高其在下游任务上的性能。 这项工作中的方法是训练模型去噪损坏的文本范围(也是目前普遍采用的)。我们怀疑这种简单化的技术可能不是传授模型通用知识的非常有效的方法。 更具体地说,能够获得良好的微调性能而无需先对 1 万亿文本标记训练我们的模型将很有用。这些方面的一些并行工作通过预训练模型以区分真实文本和机器生成的文本来提高效率。
Formalizing the similarity between tasks:我们观察到,对未标记的域内数据进行预训练可以提高下游任务的性能(第3.4节)。这一发现主要依赖于基本观察,例如 SQuAD 是使用来自Wikipedia 的数据创建的。对预训练任务和下游任务之间的“相似性”提出更为严格的概念将很有用,这样我们就可以在使用何种类型的无标签数据来源方面做出更原则性的选择。在计算机视觉领域,沿着这些思路开展了一些早期的实证研究。更好地了解任务的关联性也可以帮助选择有监督的预训练任务,这已被证明对 GLUE 基准测试很有帮助。
Language-agnostic models:我们失望地发现 English-only 的预训练在我们研究的翻译任务上未能达到最新的结果。我们也有兴趣去避免需要指定某种语言的预先编码的词汇表的准备困难。为了解决这些问题,我们有兴趣进一步研究与语言无关的模型,即无论文本的语言如何,都能执行给定 NLP 任务且性能良好的模型。鉴于英语不是世界上大多数人口的母语,所以这是一个特别相关的问题。
本文的动机是最近针对 NLP 的迁移学习的大量工作。在我们开始这项工作之前,这些进步已经实现了基于学习的方法尚未被证明有效的环境中的突破。我们很高兴能够继续保持这种趋势,例如通过在 SuperGLUE 基准测试上接近人类水平的性能来完成这一任务,这项任务专为现代的迁移学习pipeline 而设计。我们的结果源于简单,统一的Text-to-text框架,新的C4数据集以及系统研究的见解。此外,我们提供了该领域的经验概述以及展望。我们很高兴看到后续工作能够使用迁移学习实现通用语言理解的目标。
参考
^T5 论文 https://arxiv.org/abs/1910.10683
^相对位置嵌入 https://arxiv.org/abs/1803.02155
^decaNLP https://arxiv.org/abs/1806.08730
^Transformer https://arxiv.org/abs/1706.03762
^AdaFactor https://arxiv.org/abs/1804.04235
^abUniversal Language Model Fine-tuning for Text Classification https://arxiv.org/abs/1801.06146
^SentencePiece https://arxiv.org/abs/1808.06226
^Subword模型 https://zhuanlan.zhihu.com/p/69414965
^深入理解NLP Subword算法:BPE、WordPiece、ULM https://zhuanlan.zhihu.com/p/86965595
^Generating Wikipedia by Summarizing Long Sequences https://arxiv.org/abs/1801.10198
^Unified Language Model Pre-training for Natural Language Understanding and Generation https://arxiv.org/abs/1905.03197
^MASS https://arxiv.org/abs/1905.02450
^OpenWebText https://github.com/jcpeterson/openwebtext
^wikipedia dataset https://www.tensorflow.org/datasets/catalog/wikipedia
^Parameter-Efficient Transfer Learning for NLP https://arxiv.org/abs/1902.00751
^Can you tell me how to get past sesame street? sentence-level pretraining beyond language modeling. https://www.aclweb.org/anthology/P19-1439/
^abMulti-Task Deep Neural Networks for Natural Language Understanding https://arxiv.org/abs/1901.11504
^SpanBERT https://arxiv.org/abs/1907.10529
方便交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐阅读:
【ACL 2019】腾讯AI Lab解读三大前沿方向及20篇入选论文
【一分钟论文】IJCAI2019 | Self-attentive Biaffine Dependency Parsing
【一分钟论文】 NAACL2019-使用感知句法词表示的句法增强神经机器翻译
【一分钟论文】Semi-supervised Sequence Learning半监督序列学习
【一分钟论文】Deep Biaffine Attention for Neural Dependency Parsing
详解Transition-based Dependency parser基于转移的依存句法解析器
经验 | 初入NLP领域的一些小建议
学术 | 如何写一篇合格的NLP论文
干货 | 那些高产的学者都是怎样工作的?
一个简单有效的联合模型
近年来NLP在法律领域的相关研究工作

让更多的人知道你“在看”
