论文阅读:(2020版)A Survey on Contextual Embeddings 综述:上下文嵌入
A Survey on Contextual Embeddings
综述:上下文嵌入
目录
- A Survey on Contextual Embeddings
- 综述:上下文嵌入
-
- 摘要
- 1 简介
- 2 目标词嵌入
- 3 上下文嵌入的预训练方法
-
- 3.1 通过语言建模进行无监督的预训练
- 3.2 监督目标
- 4 跨语言多语言上下文嵌入预训练
- 5 下游学习
-
- 5.1 下游使用上下文嵌入的方法
- 5.2 应对灾难性遗忘
- 5.3 多任务微调
- 6 模型压缩
- 7 分析上下文嵌入
- 8 当前的挑战
摘要
上下文嵌入(例如ELMo和BERT)超越了诸如Word2Vec之类的全局词表示,并在各种自然语言处理任务上实现了突破性的性能。上下文嵌入会根据每个词的上下文为其分配一个表示形式,从而捕获跨不同上下文的词用法,并对跨语言传递的知识进行编码。在此综述中,我们回顾了现有的上下文嵌入模型、跨语言多语言预训练、上下文嵌入在下游任务中的应用、模型压缩和模型分析。
1 简介
在现代自然语言处理系统中广泛使用无监督的大规模语料库训练的分布式词表示法(Turian et al., 2010; Mikolov et al., 2013; Pennington et al., 2014)。但是,这些方法只为每个词获取单个全局表示,而忽略了它们的上下文。与传统的词表示形式不同,上下文嵌入超越了词级语义,因为每个标注都与表示形式相关联,该表示形式是整个输入序列的函数。这些依赖于上下文的表示形式可以捕获多种语言上下文下词的许多句法和语义属性。先前的工作(Peters et al., 2018; Devlin et al., 2018; Yang et al., 2019; Raffel et al., 2019)表明,上下文嵌入在大规模无标注的语料库上进行预训练,可以在文本分类、问答和文本摘要等一系列自然语言处理任务中获得最先进的性能。进一步的分析(Liu et al., 2019a; Hewitt and Liang, 2019; Hewitt and Manning, 2019; Tenney et al., 2019a)表明上下文嵌入能够学习跨语言的有用且可转移的表示形式。
其余的综述部分安排如下。在第2节中,我们定义了上下文嵌入的概念。在第3节中,我们介绍了用于获取上下文嵌入的现有方法。在第4节中,我们介绍了在多语言语料库上进行上下文嵌入的预训练方法。在第5节中,我们描述了在下游任务中应用预训练的上下文嵌入的方法。在第6节中,我们详细介绍了模型压缩方法。在第7节中,我们综述了旨在识别通过上下文嵌入学习的语言知识的分析。在结束综述时,我们将在第8节中重点介绍未来研究的一些挑战。
2 目标词嵌入
考虑一个文本语料库,它表示为目标词序列S(t1,t2,…,tN)。词的分布式表示(Harris, 1954; Bengio et al., 2003)将每个标注 ti 与密集特征向量 hti 相关联。传统的词嵌入技术旨在学习全局词嵌入矩阵E∈RV×d,其中V是词汇量,d是维数。具体而言,E的每一行ei对应于词类型i在词汇表V中的全局嵌入。学习词嵌入的著名模型包括Word2vec(Mikolov et al., 2013)和Glove(Pennington et al., 2014)。另一方面,学习上下文嵌入的方法将每个标注ti与表示整个输入序列S的函数相关联,即hti = f(et1,et2,…,etN),其中每个输入标注tji通常首先映射在应用聚合函数 f 之前,将其还原为非上下文表示etj。与非上下文词嵌入相比,这些上下文依赖表示更适合捕获序列级语义(例如多义)。 f有许多模型架构,我们在这里进行回顾。我们首先描述用于学习可在下游任务中使用的上下文嵌入的预训练方法。
3 上下文嵌入的预训练方法
在很大程度上,预训练上下文嵌入可以分为无监督方法(例如语言建模及其变体)或监督方法(例如机器翻译和自然语言推理)。
3.1 通过语言建模进行无监督的预训练
学习分布式目标词嵌入的典型方法是通过语言建模。语言模型是目标词序列上的概率分布。给定N个目标词序列(t1,t2,…,tN),语言模型将序列的概率分解为:
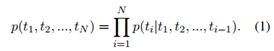
语言建模使用最大似然估计(MLE)(通常会受到正则化项的影响)来估计模型参数。从左到右的语言模型将ti的左上下文t1,t2,…,ti-1考虑在内,以估计条件概率。语言模型通常使用大规模的未标注语料库进行训练。条件概率是使用神经网络最常学习的(Bengio et al., 2003),并且已证明学习的表示形式可以转移到下游自然语言理解任务上(Dai and Le, 2015; Ramachandran et al., 2016)。
Precursor Models。 Dai and Le(2015)是我们知道的第一个使用语言建模和序列自动编码器来改善递归网络序列学习的工作。因此,可以将其视为现代上下文嵌入方法的先驱。该模型在数据集IMDB,Rotten Tomatoes, 20 Newsgroups和DBpedia上进行了预训练,然后对情感分析和文本分类任务进行了微调,与随机初始化的模型相比,该模型具有出色的性能。
Ramachandran et al.(2016)扩展了Dai and Le(2015),提出了一种预训练方法来提高序列到序列(seq2seq)模型的准确性。 seq2seq模型的编码器和解码器使用两种语言模型的预训练权重进行初始化。这些语言模型分别在News Crawl的英语或德语语料库上进行了机器翻译的训练,而两种语言模型都通过在英语Gigaword语料库中进行过训练的语言模型进行了抽象总结。这些预训练的模型分别在WMT英语→德语任务和CNN / Daily Mail语料库上进行了微调,无需进行预训练即可在基线上取得更好的结果。
以下几节的工作比Dai and Le(2015)和Ramachandran et al.(2016)的工作有所改进,其中包含新架构(例如Transformer)、更大的数据集和新的预训练目标。表1和表2显示了模型和预训练目标的摘要。


ELMo。ELMo模型(Peters et al., 2018)通过从双向语言模型中提取上下文相关表示来概括传统词嵌入。前向L层LSTM和后向L层LSTM分别用于编码左上下文和右上下文。在第j层,上下文表示是从左到右和从右到左表示的串联,获得N个隐藏表示(h1,j,h2,j,…,hN,j)长度为N。
为了在下游任务中使用ELMo,每个目标词k的(L + 1)层表示形式(包括全局词嵌入)被汇总为:
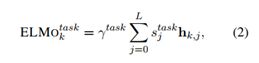
其中stask是用于将目标词k和γtask的(L + 1)层表示线性组合的softmax标准化的权重是一个特定任务的常数。
给定经过预训练的ELMo,可以很容易地将其合并到特定任务的体系结构中以提高性能。由于大多数监督模型在其最低层使用全局词表示xk,因此可以将这些表示与其相应的上下文相关表示ELMOtask k串联起来,从而获得==[xk; ELMOtask k]==,然后再将它们放入更高的层。
ELMo的有效性针对六个NLP问题进行了评估,包括问答、文本蕴涵和情感分析。
GPT,GPT2和Grover。 GPT(Radford et al., 2018)采用了两个阶段的学习范式:(a)使用语言建模目标的无监督预训练和(b)有监督的微调。目的是学习可转换为多种下游任务的通用表示形式。为此,GPT使用BookCorpus数据集(Zhu et al., 2015),该数据集包含7,000多种不同流派的书籍,用于训练语言模型。 Transformer体系结构(Vaswani et al., 2017)用于实现语言模型,与其他替代方案相比,该模型已被证明可以更好地捕获输入中的全局依赖。递归网络,并在一系列序列学习任务上表现出色,例如机器翻译(Vaswani et al., 2017)和文档生成(Liu et al., 2018)。为了在微调期间对具有多个序列的输入使用GPT,GPT会应用由遍历样式方法激发的特定任务的输入适应(Rockt¨aschel et al., 2015)。这些方法通过特殊标注将每个文本输入作为标注的单个连续序列进行预处理,这些特殊标注包括 [START](序列的开始),[DELIM](从文本输入中划定两个序列)和[EXTRACT](结束于输入序列)。在预训练的Transformer研究的12项任务中,有9项GPT优于特定任务的体系结构。
GPT2(Radford et al., 2019)主要遵循 GPT的架构,并在尽可能大和多样的数据集上训练语言模型,以便从不同的领域和背景中学习。为此,Radford et al. (2019)通过抓取Reddit的出站链接,创建了一个新的数据集,包含数百万个名为WebText的网页。作者认为,在大规模未标注语料库上训练的语言模型开始学习一些常见的受监督的NLP任务,例如问答、机器翻译和摘要,而没有任何明确的监督信号。为了验证这一点,在zero-shot设置下对十个数据集(例如,Children’s Book Test(Hill et al., 2015)、LAMBADA(Paperno et al., 2016)和 CoQA(Reddy et al.,2019))进行了测试。GPT2在某些任务上表现出色。例如,当以文档和问题为条件时,GPT2在CoQA数据集上的F1得分达到55,而无需使用任何带标签的训练数据。这与4个基准系统中的3个系统的性能相匹配或优于。由于 GPT2将文本分成字节并使用 BPE(Sennrich et al., 2016)来建立词汇量(而不是像以前的工作那样使用字符或词),因此尚不清楚改进的性能来自于模型还是新的输入表示。
Grover(Zellers et al., 2019)从Common Crawl创建了一个 新闻数据集RealNews,并预训练了一种语言模型以生成逼真的假新闻,该假新闻以包括域、日期、作者和标题的元数据为条件。他们进一步研究了可用于检测假新闻的鉴别器。证明对Grover的最佳防御方法是Grover本人,这说明了发布经过训练的模型以检测假新闻的重要性。
BERT。 ELMo(Peters et al., 2018)将前向和后向LSTM的表示连接在一起,而没有考虑左右上下文之间的相互作用。 GPT(Radford et al.,2018)和 GPT2(Radford et al.,2019)使用从左到右的解码器,其中每个目标词只能参与其左上下文。这些架构对于句子级任务来说是次优的,因为从两个方向合并上下文是至关重要的,例如,命名为实体识别和情感分析。
BERT提出了一种 掩码语言建模(MLM)目标,其中输入序列的某些标注被随机掩码,并且目标是以损坏的序列作为输入来预测这些掩码的位置。 BERT在预训练期间应用了 Transformer编码器来处理双向上下文。另外,BERT使用下一句预测(NSP)目标。给定两个输入句子,NSP预测第二个句子是否是第一个句子的实际下一个句子。 NSP的目标是改进诸如问答和自然语言推理之类的任务,这些任务需要对句子对进行推理。
与 GPT相似, BERT使用特殊目标词为每个输入序列获取单个连续序列。具体而言,第一个标注始终是特殊分类标注 [CLS],并且使用特殊标注 ==[SEP]==分隔句子对。 BERT采用预训练,然后进行微调。 ==[CLS]==的最终隐藏状态用于句子级任务,每个标注的最终隐藏状态用于目标词级任务。 BERT在11种自然语言处理任务上获得了最新的最新结果,例如将GLUE(Wang et al., 2018)得分提高到80.5%。
与 GPT2相似,目前还不清楚为什么 BERT会比以前的方法有所改进,因为与以前的方法相比,它使用不同的目标、数据集(Wikipedia和BookCorpus)和体系结构。对于此方面的部分见解,我们请读者参考( Raffel et al., 2019)以进行 单向和双向模型、传统语言建模和使用相同数据集的掩码语言建模之间的受控比较。
BERT 变体。最近的工作进一步研究并改善了BERT的目标和体系结构。
ERNIE(Sun et al., 2019b)取代了知识的随机掩码标注,它结合了知识掩码策略,包括 实体级掩码和短语级掩码。 ERNIE 2.0(Sun et al., 2019c)进一步包含了更多的预训练任务,例如 语义亲密性和话语关系。 SpanBERT(Joshi et al., 2019)概括了ERNIE,以掩盖随机跨度,而无需参考外部知识。 StructBERT(Wang et al., 2019b)提出了一个词结构目标,该目标随机地排列3-grams顺序进行重构,并提出了一个句子结构目标,该目标预测了两个连续段的顺序。
RoBERTa(Liu et al., 2019c)对已发布的 BERT模型进行了一些更改并取得了实质性的改进。所做的更改包括: (1)使用更大的批次和更多的数据对模型进行更长的训练;(2)取消NSP目标;(3)较长时间的训练;(4)在预训练过程中动态更改掩码位置。
ALBERT(Lan et al., 2019)提出了两种参数减少技术( 分解式嵌入参数化和跨层参数共享),以降低内存消耗并加快训练速度。此外,ALBERT认为NSP目标没有困难,因为负例是通过将来自不同文档的片段配对而创建的,这将主题预测和连贯性预测混合在一个任务中。 ALBERT而是使用 句子顺序预测(SOP)目标。 SOP通过取出两个连续的段获得正例,而通过反转同一文档中两个连续的段的顺序得到负例。
XLNet。 XLNet模型(Yang et al., 2019)指出了BERT的两个弱点:
1. BERT假设损坏目标词的条件独立性。例如,要建模概率p(t2 = cat,t6 = mat | t1 = The,t2 = [MASK],t3 = sat,t4 = on,t5 = the,t6 = [MASK]),BERT将其分解为p(t2 = cat | …)p(t6 = mat | …),其中t2和t6假定为条件独立的。
2.诸如[MASK]之类的符号是由BERT在预训练期间引入的,但是它们从未出现在实际数据中,从而导致了预训练和微调之间的差异。
XLNet提出了一种 基于置换语言建模(PLM)的新的 自回归方法(Uria et al., 2016),而没有引入任何新符号。 MLE目标的计算公式为:

对于每个序列, XLNet从所有置换ZN的集合中采样置换顺序z = [z1,z2,…,zN],其中|ZN| = N!。序列的概率根据z分解,其中第zj个目标词tzj根据排列顺序z取决于所有先前的目标词tz1, tz2, …, tzj。
XLNet进一步采用 two-stream self-attention和Transformer-XL(Dai et al., 2019)分别考虑目标位置zj和学习longrange依赖项。
由于ZN是阶乘的基数,单纯的优化将具有挑战性。因此, XLNet在部分输入上作条件,并生成其余输入以减小搜索空间的规模:
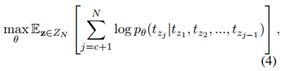
其中c是序列的切点。但是,由于损耗和体系结构的多种变化,直接将 XLNet与BERT进行比较比较棘手。
UniLM。UniLM(Dong et al., 2019)采用三个目标: (a)语言建模,(b)掩码语言建模和(c)序列到序列语言建模(seq2seq LM),用于预训练Transformer网络。为了在单个网络中实现三个目标, UniLM利用特定的自我关注掩码来控制预测条件所处的环境。例如, MLM可以处理其双向上下文,而 seq2seq LM可以处理源序列的双向上下文,而仅处理目标序列的左侧上下文。
ELECTRA。与 BERT相比, ELECTRA(Clark et al., 2019)提出了一种更有效的预训练方法。 ELECTRA并没有使用 ==[MASK]==破坏输入的某些位置,而是使用从小规模生成网络中采样的合理替代品来代替输入的某些标注。 ELECTRA训练鉴别器以预测损坏输入中的每个目标词是否已被生成器替换。然后,可以在下游任务中使用预训练的鉴别器进行微调,以改进生成器学习到的预训练表示。
MASS。尽管BERT在许多 自然语言理解任务上都达到了最先进的性能,但是BERT并不容易用于 自然语言生成。 MASS(Song et al., 2019)使用掩码序列对序列到序列模型进行预训练。更具体地说, MASS采用 编码-解码框架并扩展了MLM目标。编码器采用一个序列作为输入,其中连续标注被掩码,解码器自动回归预测这些被掩码的连续标注。MASS在各种零/低资源语言生成任务(包括神经机器翻译、文本摘要和会话响应生成)上,在没有预先训练或使用其他预先训练方法的情况下,实现了对基线的显著改进。
T5。 Raffel et al.,(2019)提出 T5(Text-to-Text Transfer Transformer),通过转换将自然语言理解和生成统一将数据转换为文本到文本格式并应用编码-解码框架。
T5通过清除 Common Crawl中的网页,引入了一个新的预训练数据集 Colossal Clean Crawled Corpus。 T5还从训练前的目标、体系结构、训练前的数据集和传递方法方面系统地比较了以前的方法。 T5采用文本填充目标(用单个掩码目标词替换文本范围),更长的训练,对 GLUE或SuperGLUE的多任务预训练,对每个单独的 GLUE和SuperGLUE任务的微调以及波束搜索。 ERNIE-GEN(Xiao et al., 2020年)是另一项使用文本填充的工作,其中每个被掩码跨度的标注都是非自回归地生成的。
为了进行微调,为了将输入数据转换为文本到文本的框架,T5使用解码器的目标词词汇作为预测标签。例如,标注“entailment”,“contradiction”和“neutral”被用作自然语言推理任务的标签。对于 回归任务(例如STS-B(Cer et al., 2017)),T5会将分数四舍五入到最接近的0.2的倍数,然后将结果转换为文字字符串表示形式(例如,将2.57转换为字符串“ 2.6” )。 T5还向每个输入序列添加了特定任务的前缀以指定其任务。例如,T5将前缀“translate English to German”添加到每个输入序列中,例如“ That is good.”,用于英语到德语的翻译数据集。
BART。 BART模型(Lewis et al., 2019)为预训练序列间模型引入了除MLM之外的其他噪声功能。首先,使用任意噪声函数破坏输入序列。然后,通过使用 teacher forcing训练的Transformer网络重构损坏的输入(Williams and Zipser,1989)。 BART评估了多种噪声功能,包括 目标词掩码、目标词删除、文本填充、文档旋转和句子改组(随机改组句子的词顺序)。通过同时使用句子改组和文本填充来获得最佳性能。 BART与RoBERTa在GLUE和SQuAD上的性能相匹配,并在各种文本生成任务上达到了最新的性能。
3.2 监督目标
在对下游任务进行微调之前,对 ImageNet数据集进行预训练(对图像中的对象进行监督)已成为计算机视觉社区的事实上的标准。受计算机视觉监督预训练的成功推动,一些工作(Conneau et al., 2017; McCann et al., 2017; Subramanian et al., 2018)利用 NLP中的数据丰富任务来学习可转移表示。
CoVe(McCann et al., 2017)表明,从机器翻译中学到的表示形式可以转移到下游任务中。 CoVe使用经过训练用于机器翻译的序列到序列模型的深层LSTM编码器来获得上下文嵌入。实验结果表明,通过CoVe嵌入来增强非上下文化的词表示(Mikolov et al., 2013; Pennington et al., 2014)可以改善许多常见的NLP任务的性能,例如 情感分析、问题分类、蕴含和问答。 InferSent(Conneau et al., 2017)从 SNLI上的预训练自然语言推理模型中获取上下文表示。 Subramanian et al.,(2018)使用多任务学习对 序列到序列模型进行预训练以获取一般表示,其中的任务包括 skip-thought(Kiros et al., 2015)、机器翻译、成分句法分析和自然语言推理。
4 跨语言多语言上下文嵌入预训练
跨语言多语言预训练旨在学习联合多语言表示形式,使知识能够从数据丰富的语言(如英语)转移到数据稀缺的语言(如罗马尼亚语)。基于是否使用联合训练和共享词汇,我们将先前的工作分为三类。
联合训练&共享词汇。 Artetxe and Schwenk(2019)使用 BiLSTM编码-解码框架和共享的93种语言的BPE词汇表。该框架使用 并行语料库(包括Europarl和Tanzil)进行了预训练。来自编码器的上下文嵌入用于使用英语语料库来训练下游任务的分类器。由于嵌入空间和编码器是共享的,因此无需进一步修改即可将所得分类器转移到93种语言中的任何一种。实验表明,这些分类器在跨语言自然语言推理、跨语言文档分类和并行语料库挖掘方面均具有竞争优势。
Rosita(Mulcaire et al.,2019)使用来自不同语言的文本对语言模型进行了预训练,显示了在 低资源语言上进行多语言学习的好处。
最近, BERT的作者开发了多语言的 BERT,它使用Wikipedia转储进行了预训练,具有100多种语言。
XLM(Lample and Conneau,2019)使用三种预训练方法来学习跨语言模型: (1)因果语言建模,其中训练模型以预测p(ti | t1,t2,…,ti− 1),(2)掩码语言建模和(3)翻译语言建模(TLM)。使用 并行语料库,并且源序列和目标序列中的目标词都被掩码以学习跨语言关联。 XLM在跨语言分类、无监督机器翻译和有监督机器翻译方面表现出色。 XLM-R(Conneau et al.,2019)通过使用超过2 TB的已过滤CommonCrawl数据在100种语言上训练基于 Transformer的掩码语言模型来扩展 XLM。 XLM-R表明,大规模的多语言预训练可为各种跨语言传输任务带来显着的性能提升。
联合训练&独立词汇。 Wu et al.,(2019)研究了预训练的多语言语言模型中跨语言结构的出现。发现即使跨单语语料库没有共享词汇,跨语言转移也是可能的,并且在不同语言的嵌入空间中存在普遍的潜在对称性。
独立训练&独立词汇。 Artetxe et al.,(2019)使用四步法获取多语言嵌入。假设我们有两种语言L1和L2的单语序列:(1)使用L1’s的单语数据用L1的词汇预训练BERT。(2)用词汇代替L1的词汇-L2的一部分,并使用L2’s的单语数据训练新的词汇嵌入,同时冻结其他参数。(3)使用L1中的标注数据对BERT模型进行下游任务的微调,同时冻结L1’s的词汇嵌入。(4)将精调的BERT替换为L2’s的词汇嵌入,以完成zero-shot传输任务。
5 下游学习
一旦 学习,上下文嵌入在下游用于各种学习问题时就表现出令人印象深刻的性能。在这里,我们描述了在下游使用上下文嵌入的方式,在下游学习期间可以避免忘记嵌入中的信息的方式以及如何将它们专用于多种学习任务。
5.1 下游使用上下文嵌入的方法
在下游任务中使用预训练的上下文嵌入的主要方法有三种: (1)基于特征的方法,(2)微调方法,(3)适配器方法。
基于特征。基于特征的一个示例是 ELMo使用的方法(Peters et al., 2018)。具体来说,如公式2所示,ELMo冻结了预训练上下文嵌入模型的权重,并形成其内部表示的线性组合。然后,将线性组合表示形式用作特定任务的体系结构的功能。基于特征的模型的优势在于,它们可以将最先进的手工架构用于特定任务。
微调。微调的工作方式如下:从预训练的上下文嵌入模型的权重开始,微调会对它们进行细微调整,以使它们专门用于特定的下游任务。一个工作流程对预先训练的模型应用最小的更改,以充分利用它们的参数。最直接的方法是 在预训练模型的顶部添加线性层(Devlin et al.,2018; Lan et al., 2019)。另一种方法(Radford et al., 2019; Raffel et al., 2019) 使用通用数据格式,而没有为下游任务引入新的参数。
要将预训练的模型应用于结构不同的任务(其中使用特定任务的体系结构),则尽可能多地使用预训练的 权重来初始化模型。例如, XLM(Lample和Conneau,2019年)应用了两个预训练的单语语言模型来分别初始化编码器和解码器以进行机器翻译,仅保留交叉注意权重被随机初始化。
适配器。 适配器(Rebuffi et al., 2017; Stickland and Murray,2019)是在预训练模型的各层之间添加的小模块,可以在多任务学习环境中进行训练。在调整这些 适配器模块时,已固定模型的参数是固定的。与为每个任务微调一个单独的预训练模型的先前工作相比,一个具有针对所有任务的共享适配器的模型通常需要更少的参数。
5.2 应对灾难性遗忘
学习下游任务很容易覆盖预训练的模型中的信息,这被广泛称为 灾难性遗忘(McCloskey and Cohen,1989; d’Autume et al., 2019)。先前的工作通过 (1)冻结层,(2)使用自适应学习率和(3)正则化来解决此问题。
冻结层。通过对神经网络进行分层训练(Hinton et al.,2006),在训练某些层而冻结其他层的情况下,可以潜在地减少微调过程中的遗忘。已经研究了不同的逐层调整时间表。 Long et al.,(2015年)冻结除顶层以外的所有层。 Felbo et al.,(2017)使用“chain-thaw”,可一次解冻并微调一次层。Howard and Ruder(2018)逐步从上到下逐层解冻所有图层。 Chronopoulou et al.,(2019)应用了一个三阶段的微调进度表:(a)对n epochs更新随机初始化的参数,(b)然后对预训练的参数(词嵌入除外)进行微调,(c)最后,全部参数已微调。
自适应学习率。减轻灾难性遗忘的另一种方法是使用自适应学习率。可以相信,经过预训练的模型的较低层倾向于捕获通用语言知识(Tenney et al., 2019a),Howar dand Ruder(2018)在进行微调时对较低层使用较低的学习率。
正则化。正则化将微调参数限制为接近预训练参数。Wiese et al.,(2017)最小化微调参数和预训练参数之间的欧几里得距离。Kirkpatrick et al.,(2017)使用Fisher信息矩阵来保护被确定为预训练模型必不可少的权重。
5.3 多任务微调
对下游任务的 多任务学习(Liu et al., 2019b; Wang et al., 2019a; Jozefowicz et al., 2016)获得了跨任务的一般表示,并在每个单独的任务上取得了出色的表现。
MT-DNN(Liu et al., 2019b)在所有GLUE任务上对 BERT进行了微调,将GLUE基准提高到82.7%。 MT-DNN还证明,与 BERT相比,多任务学习的表示在域自适应方面获得了更好的性能。
Wang et al.,(2019a)进一步研究了非GLUE任务,例如 skip-though和Reddit response生成,以进行多任务学习。
T5(Raffel et al., 2019)研究了多任务学习的各种设置,发现在对每个任务进行微调之前使用多任务学习效果最佳。
6 模型压缩
由于许多经过预训练的语言模型的内存占用和延迟都令人望而却步,因此将它们部署在资源受限的环境中是一项艰巨的任务。为了解决这个问题, 模型压缩(Cheng et al., 2017)在近年因缩小大型神经网络而广受欢迎,目前已被研究用于压缩上下文嵌入模型。压缩语言模型的工作利用 (1)低秩近似,(2)知识蒸馏和(3)权重量化,使其在嵌入式系统和边缘设备中可用。
低秩近似。学习低秩近似的方法试图将满秩模型权重矩阵压缩为低秩矩阵,从而减少模型参数的有效数量。由于嵌入矩阵通常占模型参数的很大一部分(例如BERTBase为21%),因此ALBERT(Lan et al., 2019)近似嵌入矩阵E ∈ RV ×d是两个较小矩阵E1 ∈ RV ×d′和E2 ∈ Rd′×d的乘积,其中d′≪d。
知识蒸馏。 Hinton et al.(2015)提出了一种称为“ 知识蒸馏”的方法,其中将teacher网络中编码的“知识”转移到student网络。 Hinton et al.(2015年)使用teacher网络输出的软目标概率,使用交叉熵损失来训练student网络。student网络比教师网络小,从而导致了更轻量级的模型,接近重量级teacher网络的准确性。 Tang et al.(2019)将BERT的知识提取到 单层BiLSTM中,从而获得了与ELMo相当的性能,但参数却减少了约100倍。 DistilBERT(Sanh et al., 2019)使用 MLM、蒸馏损失(Hinton et al., 2015)以及 teacher和student网络的嵌入矩阵之间的 余弦相似度来训练较小的 BERT模型。 BERT-PKD(Sun et al., 2019a)使用与BERTBase 和 BERTLarge相比层数更少的student BERT模型,并提出了两种方法(从最后k层学习和从每k层学习)将student层映射到层BERTBase 或 BERTLarge。使用 欧几里得距离调节器,从相应的层将student的隐藏状态保持与teacher的隐藏状态接近。 TinyBERT(Jiao et al., 2019)引入了一个两阶段学习框架,其中在预训练和微调阶段都进行蒸馏。
权重量化。量化方法着重于将权重参数映射到低精度整数和浮点数。 QBERT(Shen et al., 2019)提出了一种基于组的量化方案,其中,基于注意力头将参数分为几组,并使用基于Hessian的混合精度方法压缩模型。
7 分析上下文嵌入
尽管上下文嵌入方法在多种自然语言任务中具有令人印象深刻的性能,但通常不清楚为什么它们如此有效。为了对此进行研究,到目前为止,工作已经使用 (1)探测分类器和(2)可视化 。
探测分类器。大量的工作使用探测研究上下文嵌入。这些是受约束的分类器,旨在探索语法和语义信息是否以这些表示形式进行编码。
Liu et al.(2019a)设计了一系列目标词标注、分段和成对关系任务,以研究上下文嵌入的有效性。与大多数任务上的最新模型相比,上下文嵌入取得了竞争性的结果,但在某些细粒度的语言任务(例如合取识别)上却失败了。
Hewittand Manning(2019)提出了一种结构化探测,用于在上下文嵌入中查找语法。该模型尝试学习一种线性变换,在该线性变换下,标注之间的L2距离在语法分析树(如依赖树)中对这些标注之间的距离进行编码。
Tenney et al.,(2019a)发现BERT以可解释和可本地化的方式重新发现了传统的NLP管道。具体来说,它能够进行POS标注、解析、NER、语义角色和共指,并且这些是按顺序学习的。
Jawahar et al.,(2019)使用十个句子级别的探测任务(例如SentLen,TreeDepth),发现BERT在较早的层中捕获了短语级别的信息,并在更深的层中捕获了远程依赖信息。
可视化。另一工作是使用可视化来分析注意力和微调程序等。
Hao et al.(2019)在微调BERT时可视化损失情况和优化轨迹。可视化结果表明,在对下游任务进行预训练期间,BERT达到了良好的初始点,与随机初始化的模型相比,它可以导致更好的优化。
Kovaleva et al.,(2019)可视化BERT的注意力头部,发现了不同头部的有限注意力模式。这导致BERT的头是高度冗余的事实。手动禁用某些注意力头后,与使用全套注意力头的微调BERT模型相比,可以获得更好的性能。
Coenen et al.,(2019)对BERT嵌入的几何图形进行可视化和分析,发现BERT在非常细粒度的层次上区分了词义。还发现这些词义被编码在相对低维的子空间中。
8 当前的挑战
如果解决了许多关键挑战,这些挑战将改善未来的上下文嵌入。
更好的预训练目标。 BERT设计了MLM,以便在预训练期间利用双向信息。尚不清楚是否有同时更有效和有效的预训练目标。最近的一些工作侧重于设计新的训练方法(Clark et al., 2019)、噪声组合技术(Lewis et al., 2019)和多任务学习方法(Wang et al.,2019a)。
了解预训练模型中编码的知识。如上所述,已经提出了一系列方法(Tenney et al., 2019a,b; Hewitt和Manning,2019; Liu et al., 2019a)来探索通过探测进行的预训练模型的有效性。然而,由于它们使用的数据是如此高维度,因此受控实验仍然缺乏了解这些表象是否实际上编码了语言知识,或者探测恰巧学会了在这些语言任务上表现良好(Hewitt and Liang,2019)。Hewitt and Liang(Hewitt and Liang,2019)设计了控制任务,其中一个很好的探究是在语言任务上表现出色,而在控制任务上表现不佳。他们发现大多数现有探测都无法满足此条件。实际上,大多数探测使用浅分类器,这些浅分类器可能无法从上下文表示中提取相关信息。需要新的探测或更好的方法来理解上下文表示。
模型稳健性。将NLP模型部署到生产环境中时,对模型易受攻击的担忧越来越多。Wallace et al.,(2019)表明,可以发现导致普遍对抗的触发器会导致预训练模型的性能显着下降。此外,还出现了滥用预训练模型(例如生成假新闻)的担忧。迫切需要更好的方法来提高模型的鲁棒性。
序列的受控生成。预先训练的语言模型(Radford et al., 2018,2019)能够生成逼真的文本序列。然而,很难使这些模型适应产生特定域的序列(Keskar et al., 2019)或与人类共同知识相一致(Zellers et al., 2019)。因此,我们提倡对序列生成进行更细粒度控制的研究。