R语言dplyr包超完整版函数指南
R语言dplyr包的使用
-
- 一、常用函数功能速查
- 二、常用函数详解
-
-
- iris数据集
- 1. 取子集
-
- filter/distinct
- slice
- select
- 2. 窗口函数
- 3. 连接合并
-
- left_join/right_join/inner_join/full_join
- bind_rows/bind_cols
- 4. 生成新变量
-
- mutate/transmute
- 5. 统计
-
- summarise
- 6. 整合
-
- arrange/group_by
- rename
- 7.语法
-
- tbl_df/glimpse
- %>%pipe
-
dplyr包是R语言一个用于高级数据处理的包,它对于每个基本需求都提供了一个函数,如取子集、连接、合并排序分组等等,很多函数与SQL的功能可以一一对应,对于复杂的数据集来说,dplyr包提供的函数更高效简洁。本文参考RSTUDIO以及R语言官方文档整理。
一、常用函数功能速查
dplyr对于数据处理的每个基本需求都提供了一个函数
| 类别 | 函数名 | 用途 |
|---|---|---|
| 1.取子集 | filter() | 根据条件选择行 |
| distinct() | 删除重复项 | |
| select() | 根据条件选择列 | |
| slice() | 切片 | |
| sample_n() | 对数据按个数取随机样本 | |
| sample_frac() | 对数据按比例取随机样本 | |
| 2.窗口函数 | dense_rank() | 得到排序值 |
| row_nunmber() | 得到排序值 | |
| percent_rank() | 0到1之间的数字,通过重新缩放min_rank为(0,1)之间 | |
| min_rank | 排序值 | |
| cume_dist() | 累积分布函数。所有小于或等于当前等级的值的比例 | |
| 3.连接合并 | left_join() | 左连接 |
| right_join() | 右连接 | |
| inner_join() | 内连接 | |
| full_join() | 全连接 | |
| bind_rows() | 按行连接 | |
| bind_cols() | 按列连接 | |
| 4.生成新变量 | mutate() | 在数据中生成新变量 |
| transmute() | 在数据中生成新变量 | |
| 5.统计 | summarise() | 对变量计算统计量 |
| summarise_each() | 按列计算统计量 | |
| 6.整合 | arrange() | 对行排序 |
| group_by() | 对数据分组 | |
| rename() | 重新命名 | |
| 7.语法 | tbl_df() | tibble型数据 |
| glimpse() | 描述数据结构 | |
| %>% | pipe管道函数,将左边的对象作为第一个参数传递到右边的函数中 |
二、常用函数详解
iris鸢尾花数据集是R语言自带的数据集,150条数据,5个变量,简单好用,接下来用这个数据集举例说明函数的用法。
iris数据集
| 变量名 | 含义 |
|---|---|
| Sepal.Length | 花萼长度 |
| Sepal.Width | 花萼宽度 |
| Petal.Length | 花瓣长度 |
| Petal.Width | 花瓣宽度 |
| Species | 种类,共三种 |
1. 取子集
filter/distinct
#选取符合条件的行
filter(iris,Species=='setosa')
#满足两个条件其中之一
filter(iris,Species=='setosa'|Sepal.Width<3)
#两个条件同时满足
filter(iris,Species=='setosa'&Sepal.Width<3)
filter(iris,Species=='setosa',Sepal.Width<3)
#删除重复行
distinct(iris)
slice
#切片函数,选取第5-8行
slice(iris,5:8)
#和tail(iris, 1)一样,选择最后一个
slice(iris, 1L)
slice(iris, n())
select
#选择函数,选择Sepal.Width列
select(iris,Sepal.Width)
#选择函数,除了Sepal.Width以外的列
select(iris,-Sepal.Width)
#选择Sepal.Width和Species这两列以及之间的列
select(iris,Sepal.Width:Species)
#选择列名以Se开始的列
select(iris,starts_with('Se'))
#选择列名符合某个规则的列,如以th结尾的列名,规则参照正则表达式
select(iris,matches("th$"))
#选择所有列
select(iris,everything())
#选择包含S的列名
select(iris,contains('S'))
2. 窗口函数
一个例子说明,dplyr中的窗口函数与sql用法一致。不同的排序函数只是处理并列情况的方式不一样
x <-c(10,20,30,40,40,50,60)
data.frame(x,row_number(x),
min_rank(x),
dense_rank(x),
cume_dist(x))
注意原始数据虽然大致按顺序从小到大排列,但是存在两个并列的40,下面是排序结果
| 原始数据x | row_number | min_rank | dense_rank | cume_dist |
|---|---|---|---|---|
| 10 | 1 | 1 | 1 | 0.1428571 |
| 20 | 2 | 2 | 2 | 0.2857143 |
| 30 | 3 | 3 | 3 | 0.4285714 |
| 40 | 4 | 4 | 4 | 0.7142857 |
| 40 | 5 | 4 | 4 | 0.7142857 |
| 50 | 6 | 6 | 5 | 0.8571429 |
| 60 | 7 | 7 | 6 | 1.0000000 |
- row_number函数:不考虑并列情况,直接按顺序排名
- min_rank函数:如果有并列名次的行,会占用下一名次的位置。
- dense_rank函数:如果有并列名次的行,不占用下一名次的位置。
3. 连接合并
left_join/right_join/inner_join/full_join
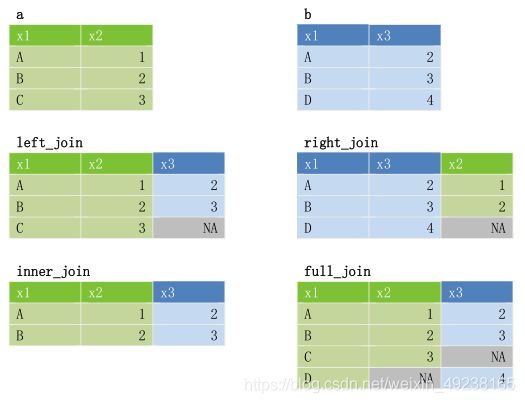
join类函数和sql的用法一致,用于两个数据集的连接,用一张图来说明连接的作用。假设有a、b两个数据集,如图所示。则不同的join将给出不同的效果
| function | 作用 |
|---|---|
| left_join() | 左连接,按照左表的关键字匹配,遇到右表没有对应的行时,自动填充NA,即向表a加入匹配的数据集b的记录 |
| right_join() | 右连接,按照右表的关键字匹配,向表b加入匹配的数据集a的记录 |
| inner_join() | 内连接,两个表都匹配的记录 |
| full_join() | 全连接,合并数据,保留所有记录 |
bind_rows/bind_cols
#类似rbind函数,按行合并
bind_rows(iris,iris)
iris数据150行5列,这个函数会生成300行5列的数据
#类似cbind函数,按列合并
bind_cols(iris,iris)
生成150行10列的数据
4. 生成新变量
mutate/transmute
#生成新变量V1,但不会改变原数据集,也不会保存
mutate(iris,V1=Sepal.Length/Sepal.Width)
#可以将其保存在newdata里面
newdata<-(iris,V1=Sepal.Length/Sepal.Width)
#对每列运行函数funs生成一个新变量,保留原变量的名字,生成全新数据
mutate_each(iris,funs = min_rank)
#只保留新变量V1
transmute(iris,V1=Sepal.Length/Sepal.Width)
5. 统计
summarise
#概述函数
summarise(iris,avg=mean(Sepal.Width))
>avg
<dbl>
3.057333
#对每列运用某个函数
summarise_each(iris,funs = mean)
>Sepal.Length Sepal.Width Petal.Length Petal.Width Species
5.843333 3.057333 3.758 1.199333 NA
我们可以看到经常需要用到参数funs,常用的统计函数如下
| function | 作用 |
|---|---|
| first/last | 第一个、最后一个 |
| nth | 第n个 |
| mean/max/mean/medain | 平均、最大最小、中位数 |
| var/sd/IQR | 方差、标准差、四分位数间距 |
| n | 元素个数 |
| n_distinct | 不同元素个数 |
6. 整合
arrange/group_by
#对数据按照Species进行整合
arrange(iris,Species)
#对数据按照Sepal.Width降序进行排序
arrange(iris,desc(Sepal.Width))
#对数据进行分组,效果一样
group_by(iris,Speicies)
group_by函数,一般和其他函数一起使用,如分组生成新变量,分组统计等等
rename
#select也可以改名,但只保留重命名的那一列
select(iris, petal_length = Petal.Length)
>petal_length
1.4
1.4
1.3
1.5
#rename保留所有变量,只是改了列名
rename(iris, petal_length = Petal.Length)
>Sepal.Width petal_length Petal.Width Species
5.1 3.5 1.4 0.2 setosa
4.9 3.0 1.4 0.2 setosa
4.7 3.2 1.3 0.2 setosa
4.6 3.1 1.5 0.2 setosa
#select可以将一组的变量一起重新命名
select(iris, obs = starts_with('S'))
>obs1 obs2 obs3
5.1 3.5 setosa
4.9 3.0 setosa
4.7 3.2 setosa
4.6 3.1 setosa
7.语法
tbl_df/glimpse
#tibble数据集和数据框类似
tbl_df(iris)
>Sepal.Length<dbl> Sepal.Width<dbl>Petal.Length<dbl> Petal.Width<dbl> Species<fctr>
5.1 3.5 1.4 0.2 setosa
4.9 3.0 1.4 0.2 setosa
4.7 3.2 1.3 0.2 setosa
4.6 3.1 1.5 0.2 setosa
5.0 3.6 1.4 0.2 setosa
5.4 3.9 1.7 0.4 setosa
#glimpse与str作用一样
glimpse(iris)
>Rows: 150
Columns: 5
$ Sepal.Length <dbl> 5.1, 4.9, 4.7, 4.6, 5.0, 5.4, 4.6, 5.0, 4.4, 4.9, 5.4, 4.8, 4....
$ Sepal.Width <dbl> 3.5, 3.0, 3.2, 3.1, 3.6, 3.9, 3.4, 3.4, 2.9, 3.1, 3.7, 3.4, 3....
$ Petal.Length <dbl> 1.4, 1.4, 1.3, 1.5, 1.4, 1.7, 1.4, 1.5, 1.4, 1.5, 1.5, 1.6, 1....
$ Petal.Width <dbl> 0.2, 0.2, 0.2, 0.2, 0.2, 0.4, 0.3, 0.2, 0.2, 0.1, 0.2, 0.2, 0....
$ Species <fct> setosa, setosa, setosa, setosa, setosa, setosa, setosa, setosa...
%>%pipe
- 管道函数,将左边的对象作为第一个参数传递到右边的函数中
- x%>%f(y) 等于 f(x,y)
- y%>%f(x,z) 等于f(x,y,z)
- 管道操作可以节省空间,让逻辑更清楚
#eg1
#以下两个表达式等价
sum(1,2)%>%sum(3)
sum(1,2,3)
#eg2
#取前五行
iris%>%head(5)
# Lambda expressions 随机取前几行,用大括号加入更长的语句,利用.传递数据
iris %>%
{
size <- sample(1:10, size = 1)
head(., size)
}
#eg3
#group_by经常和管道函数一起运用
#假设我们需要先按种类分组,再选取其中的两列,再按照条件选行
table1<-group_by(iris,Species)
table2<-select(table1,Petal.Width,Sepal.Width)
table3<-filter(table1,Sepal.Width>3)
#利用管道函数可以让选择的过程更清晰,无需建多个新表
iris%>%
group_by(Species)%>%
select(Petal.Width,Sepal.Width)%>%
filter(Sepal.Width>3)