机器学习是什么?我对机器学习的理解
第一次听到机器学习这个名词的时候,很恍惚,不知道它到底是什么?
我对机器学习的理解
- 机器学习是什么?
- 机器学习的工作流程是什么?
- 在机器学习中对于数据集的理解
- 数据分割
- 什么是特征工程?
-
- 特征工程分类
- 机器学习算法分类
-
- 监督学习
- 无监督学习
- 半监督学习
- 强化学习
- 什么是独立同分布?
- 模型评估
- 拟合
机器学习是什么?
简单的说机器学习就是模仿人的思维处理数据。
例如一份历史数据,我们需要把它训练成为一个模型,当有新的数据时,我们把新的数据输入模型中,以此来预测新数据的属性。
机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测。
机器学习的工作流程是什么?
获取数据(用户数据)——数据基本处理——特征工程——机器学习(模型训练)——模型评估(结果达到要求,上线服务;结果没达到要求,重新数据基开始本处理)——在线服务
在机器学习中对于数据集的理解
一行数据叫做——样本
一列数据叫做——特征
有的结果有特征值、目标值,有的结果没有目标值,只有特征值。
数据分割
在建立好模型之后,除了要进行模型训练,还要对数据进行测试,验证模型怎么样。
这个行为叫做数据的分割。
机器学习一般将数据集分为:训练集和测试集
测试数据:在模型检验时使用,用于评估模型是否有效
训练数据:用于训练,构建模型
测试数据和训练数据的划分比例:
什么是特征工程?
特征工程其实可以直接理解为对数据的进一步处理。
特征工程就是利用专业知识和技巧处理数据,使得特征能够在机器学习算法中发挥更好的作用。
它的意义就是:影响机器学习的效果。
行话:数据和特征决定了机器学习的上限,模型和算法只是逼近这个结果而已。
特征工程分类
特征提取、特征预处理、特征降维
- 特征提取:就是将任意数据例如文本或者图像转换为可用于机器学习的数字特征。
- 特征预处理:通过转换函数将特征数据转换成更适合算法模型的特征数据过程。
- 特征降维:指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程。
机器学习算法分类
监督学习
监督学习的输入数据由 特征值和目标值 组成
函数的输出可以是 连续的的值(称为回归),具体的某个值
也可以是有限个离散值(称为分类),具体什么类别
无监督学习
由特征值组成,没有目标值
输入数据没有被标记,也没有确定的结果,样本数据类别未知。
大概意思就是:对输入数据进行大概归类
监督学习和无监督学习 对比:
监督学习有特征值、目标值,无监督学习只有特征值,没有目标值
监督学习目标值分为连续和不连续,即回归和分类。
半监督学习
训练集同时包含有样本标记数据和无样本标记数据。
监督学习和半监督学习的 区别:
关于标记数据的多少和训练模型有没有用到没有标记过的数据。
强化学习
本质就是一个决策问题,并且可以做连续决策。
五个元素:agent、action、reward、environment、observation
监督学习和强化学习的区别:
监督学习:输出是之间的关系,告诉算法什么样的输入就会对应什么样的输出;期间做了比较坏的选择会立刻反馈给算法;输入是独立同分布的。
强化学习:输出是用来判断这个行为是好是坏的;结果反馈有延时,可能进行了好几步才知道前面哪一步的选择是好是坏;输入总是在变化,每当算法做出一个行为,就会影响到下一次决策的输出。
什么是独立同分布?
如果变量序列或者其他随机变量有相同的概率分布,并且相互独立,那么这些随机变量是独立同分布的。
我的理解:
独立:两个筛子,每一个掷出多少都互不相关,这叫独立。
如果我让两个筛子掷出来的和加起来是6,那么这两个筛子就不是独立的,是相关的。
同分布:两个都是6面的筛子,他们某一面被掷出来的概率都是六分之一,那么他们就是同分布的。
独立同分布:同时满足独立和同分布,即两个6面的筛子,每一面掷出来的概率都是六分之一,但每个筛子掷出来的多少互相没有关联,这叫独立同分布。
模型评估
分类模型评估和回归模型评估
分类模型评估
准确率:预测正确的数占样本总数的比例。
回归模型评估
均方根误差:RMSE,衡量回归模型误差率的常用公式,不过,仅能比较误差是相同单位的模型。
均方根误差(RMSE)
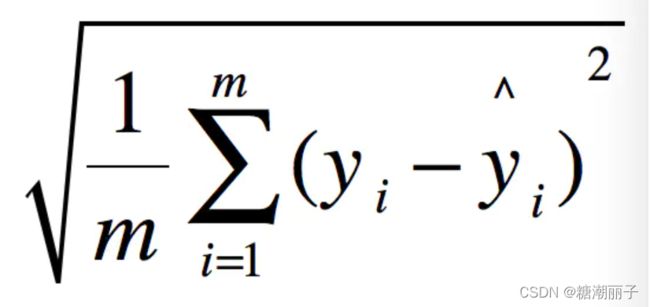
均方误差(MSE)
用 真实值-预测值 然后平方之后求和平均。
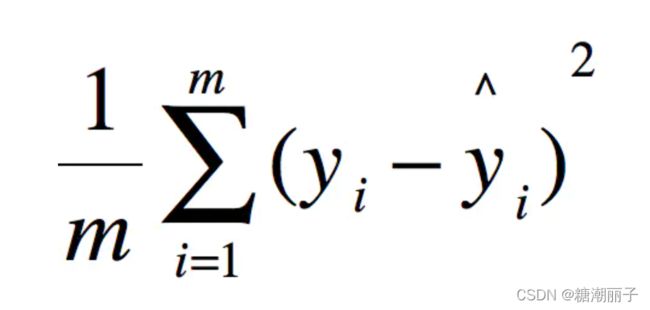
MAE(平均绝对误差)
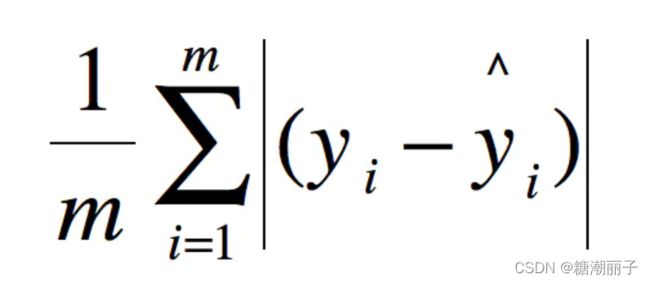
拟合
模型评估用于评测训练好的模型的表现效果,其表现效果大致可以分为两类:过拟合、欠拟合
欠拟合:模型学习的太粗糙,连训练集中的样本数据特征关系都没有学出来。
过拟合:所建的机器学习模型或者深度学习模型在训练样本中表现过于优越,导致在测试集中表现不佳。
都是些基本概念,其中还有很多需要补充的内容,我后续再补充进来。