小生不财-语义分割1:基于VGGNet模型的segnet讲解
语义分割
- 前言
- 一、什么是segnet模型
- 二、segnet模型代码实现
- 1.主干模型VGGnet
- 2.segnet模型的Decoder部分
- 代码测试
前言
语义分割也是图像领域一个重要的研究方向,而且目前应用范围越来越广,而且场景越来越丰富。下面从最简单的部分,来记录自己的学习过程。后续更新语义分割blog均使用斑马线的数据集进行测试。
一、什么是segnet模型
Segnet模型是一个比较基础的语义分割模型,其结构比较简单,在说其结构之前,我们先讲一下convolutional Encoder-Decoder的结构。其主要结构与自编码(Autoencoder)类似,通过编码解码复原图片上每一个点所属的类别。
下图主要是说明利用卷积层编码与解码的过程。
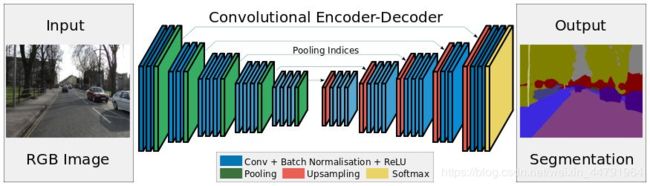
其主要结构如下图所示

由结构可以看到,其利用Encoder中提取了多次特征的f4进行处理,利用Decoder进行多次上采样Upsampling2D。最后得到一个具有一定hw的filter数量为n_classes的图层。为什么filter要用n_classes呢,因为其代表的就是每个像素点所属的种类。
用一句话概括就是 从主干模型中提取出卷积了多次,具有一定特征的层(典型的是hw经过了4次压缩后的层),然后利用UpSampling2D函数进行三次上采样,得到输出层(语句分割的结果)。
二、segnet代码实现
segnet代码主要分为两个部分
1.主干特征提取VGGnet
代码如下:
from tensorflow.keras.layers import *
IMAGE_ORDERING = 'channels_last'
def get_mobilenet_encoder(input_height=416, input_width=416, pretrained='imagenet'):
img_input = Input(shape=(input_height, input_width, 3))
# 将height=416 weight=416 大小的图片变为208 208 64
# 将卷积使用same时,采用使用0填充,计算公式为w/s w为图片的大小,s为步长,所以卷积之后结果不变
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(img_input)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = MaxPool2D((2, 2), strides=(2, 2), name='block1_pool')(x)
f1 = x
# 208 208 64 ->104 104 128
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = MaxPool2D((2, 2), strides=(2, 2), name='block2_pool1')(x)
f2 = x
# 第三次提取特征 128 128 128 -> 52 52 256
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = MaxPool2D((2, 2), strides=(2, 2), name='block3_pool')(x)
f3 = x
# 第四次特征提取 64 64 256->28 28 512
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = MaxPool2D((2, 2), strides=(2, 2), name='block4_pool')(x)
f4 = x
# 第五次特征提取
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
x = MaxPool2D((2, 2), strides=(2, 2), name='block5_pool')(x)
f5 = x
return img_input, [f1, f2, f3, f4, f5]
2.segnet的Decoder解码部分
这一部分对应着上面segnet模型中的解码部分。
其关键就是把获得的特征重新映射到比较大的图中的每一个像素点,用于每一个像素点的分类。
代码如下:
from tensorflow.keras.models import *
from tensorflow.keras.layers import *
from net.convert import get_mobilenet_encoder
IMAGE_ORDERING = 'channels_last'
# n_up为提取特征的次数,因为索引从0开始,所以这里设置成3
def segnet_decoder(f, n_classes, n_up=3):
o = f
# 标记数据来自哪里
# channels_last对应输入形状(batch, height, width, channels)
# channels_first对应输入尺寸为(batch, channels, height, width)。
# 默认为在Keras配置文件~ /.keras / keras.json中的image_data_format值。 如果你从未设置它,将使用 “channels_last”。
o = (ZeroPadding2D((1, 1), data_format=IMAGE_ORDERING))(o)
o = (Conv2D(512, (3, 3), padding='valid', data_format=IMAGE_ORDERING))(o)
o = (BatchNormalization())(o)
# 进行一次UpSampling2D,此时hw变为原来的1/8(注意:这里原来,是指输入图片的大小也就是416 416)
# 52,52,512
o = (UpSampling2D((2, 2), data_format=IMAGE_ORDERING))(o)
o = (ZeroPadding2D((1, 1), data_format=IMAGE_ORDERING))(o)
o = (Conv2D(256, (3, 3), padding='valid', data_format=IMAGE_ORDERING))(o)
o = (BatchNormalization())(o)
# 进行一次UpSampling2D,此时hw变为原来的1/4
# 104,104,256
for _ in range(n_up - 2):
o = (UpSampling2D((2, 2), data_format=IMAGE_ORDERING))(o)
o = (ZeroPadding2D((1, 1), data_format=IMAGE_ORDERING))(o)
o = (Conv2D(128, (3, 3), padding='valid', data_format=IMAGE_ORDERING))(o)
o = (BatchNormalization())(o)
# 进行一次UpSampling2D,此时hw变为原来的1/2
# 208,208,128
o = (UpSampling2D((2, 2), data_format=IMAGE_ORDERING))(o)
o = (ZeroPadding2D((1, 1), data_format=IMAGE_ORDERING))(o)
o = (Conv2D(64, (3, 3), padding='valid', data_format=IMAGE_ORDERING))(o)
o = (BatchNormalization())(o)
# 此时输出为h_input/2,w_input/2,nclasses 注意:这个时候必须把通道数调整到和分类类别一致,即通道数即为类别数
o = Conv2D(n_classes, (3, 3), padding='same', data_format=IMAGE_ORDERING)(o)
return o
# n_classes类别 encoder编码也就是特征提取
def _segnet(n_classes, encoder, input_height=416, input_width=416, encoder_level=3):
# encoder通过主干网络
img_input, levels = encoder(input_height=input_height, input_width=input_width)
# 获取hw压缩四次后的结果
feat = levels[encoder_level]
# 将特征传入segnet网络,通过segnet进行解码,feat提取的特征层,n_classes表示分类类别 n_up3表示第几个特征成
o = segnet_decoder(feat, n_classes, n_up=3)
# 将结果进行reshape
o = Reshape((int(input_height / 2) * int(input_width / 2), -1))(o)
o = Softmax()(o)
model = Model(img_input, o)
return model
# n_classes 代表类别,input_height input_width 图片大小
# encoder_level对应特征提取层,用到四层特征,序号从0开始所以这里是3
def mobilenet_segnet(n_classes, input_height=224, input_width=224, encoder_level=3):
model = _segnet(n_classes, get_mobilenet_encoder, input_height=input_height, input_width=input_width,
encoder_level=encoder_level)
model.model_name = "mobilenet_segnet"
return model
if __name__ == '__main__':
model = mobilenet_segnet(2, input_height=416, input_width=416)
model.summary()代码测试
直接运行segnet.py,然后会调用下面代码段
if __name__ == '__main__':
model = mobilenet_segnet(2, input_height=416, input_width=416)
model.summary()正常运行后的结果如下:

到这里就完成了基于VGGnet模型的segnet的搭建。
完整资源和代码:基于VGGnet模型的segnet斑马线划分-互联网文档类资源-CSDN下载