day09【内部类、数据结构、集合概述】
day09【内部类、数据结构、集合概述】
一、内部类
1.1 内部类概述
以前我们定义的类都是一个独立的整体,内部类即在一个类中又定义一个类;
我们知道类是用于描述事物的,比如人、电脑、汽车等;但是有些情况下一个事物中还包含有另一个独立的事物,如一台电脑有价格、颜色、品牌等属性,可其内部也有CPU、内存等独立的事物存在,CPU有价格、核心数、线程数、缓存大小等属性也需要描述;再比如一辆汽车有颜色、价格,其内部还有发动机,发动机又有转数、气缸数等属性;这个时候就需要采用内部类在一个类中再描述一件事物了;
1.2 内部类分类
内部类按定义的位置来分为:
- 成员内部内,类定义在了成员位置 (类中方法外称为成员位置)
- 局部内部类,类定义在方法内
1.2.1 成员内部类
1.2.1.1 定义语法
- 成员内部类 :定义在类中方法外的类
定义格式:
class 外部类{
// 成员变量
// 成员方法
class 内部类{
// 成员变量
// 成员方法
}
}
在描述事物时,若一个事物内部还包含其他事物,就可以使用内部类这种结构。比如,电脑类 Computer 中包含CPU类 CPU ,这时, CPU 就可以使用内部类来描述,定义在成员位置。
代码举例:
class Computer{ //外部类
class CPU{ //内部类
}
}
1.2.1.2 使用成员内部类
内部类可以直接访问外部类的成员,包括私有成员。
创建内部类对象格式:
外部类名.内部类名 对象名 = new 外部类型().new 内部类型();
访问演示,代码如下:
定义类:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Computer {
double price; // 价格
String color; // 颜色
String brand; // 品牌
public class CPU {
int core; // 核心数
int threads; // 线程数
public void run() {
System.out.println("价值" + price + "的电脑的CPU正在运行!");
}
}
}
测试类:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01 {
public static void main(String[] args) {
// 先创建外部类
Computer computer = new Computer();
computer.price = 8000;
// 通过外部类创建内部类
Computer.CPU cpu = computer.new CPU();
cpu.run();
}
}
1.2.1.3 内外类属性重名问题
内部类中可以访问外部类中的任意属性,但如果内部类与外部类属性重名该怎么办?
重新定义一个类:
package com.dfbz.demo02;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Computer {
double price = 8000;
public class CPU {
double price = 2500;
public void run() {
double price = 1000;
System.out.println("外部类的price: " + Computer.this.price); // 8000
System.out.println("内部类的price: " + this.price); // 2500
System.out.println("方法中的price: " + price); // 1000
}
}
}
测试类:
package com.dfbz.demo02;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01 {
public static void main(String[] args) {
// 使用匿名对象来创建内部类对象
Computer.CPU cpu = new Computer().new CPU();
cpu.run();
}
}
1.2.2 局部内部类
1.2.2.1 定义语法
- 局部内部类 :定义在方法中的类。
定义格式:
class 外部类名 {
数据类型 变量名;
修饰符 返回值类型 方法名(参数列表) {
// …
class 内部类 {
// 成员变量
// 成员方法
}
}
}
使用方式: 在定义好局部内部类后,直接就创建对象
1.2.2.2 使用局部内部类
内部类可以直接访问外部类的成员,包括私有成员。
代码示例:
package com.dfbz.demo03;
public class Demo01 {
public static void main(String[] args) {
Person p = new Person();
p.eat();
}
}
class Person {
private String name = "小灰";
public void eat() {
//筷子
class Chopsticks {
private int length;
public void use() {
//使用外部类变量
System.out.println(name + "在使用长为" + length + "的筷子吃饭");
}
public int getLength() {
return length;
}
public void setLength(int length) {
this.length = length;
}
}
Chopsticks c = new Chopsticks();
c.setLength(50);
c.use();
}
}
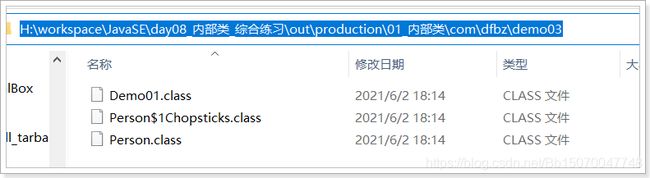
局部内部类编译后仍然是一个独立的类,编译后有$还有一个数字。
编译后类名为:Chinese$1Chopsticks.class
打开idea菜单栏,File > Project Structure,可以查看到项目的编译目录:
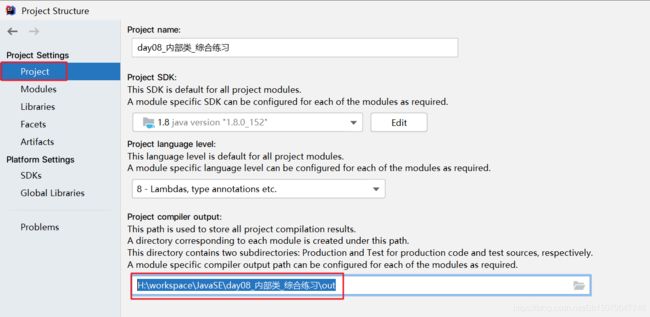
编译后的class文件:
1.3 匿名内部类
1.3.1 匿名内部类简介
我们在实现接口时必须定义一个类重写其方法,最终创建子类对象调用实现的方法;这一切的过程似乎我们只在乎最后一个步骤,即创建子类对象调用重写的方法;
可整个过程却分为如下几步:
1)定义子类
2)重写接口的方法
3)创建子类,最终调用重写的方法
- 定义接口:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro: 吃辣接口
*/
public interface Chili {
void chili();
}
- 定义人类来实现接口并且重写方法:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Person implements Chili {
@Override
public void chili() {
System.out.println("重庆朝天椒~");
}
}
- 测试类:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01 {
public static void main(String[] args) {
Person person = new Person();
person.chili();
}
}
我们的目的,最终只是为了调用方法,那么能不能简化一下,把以上三步合成一步呢?匿名内部类就是做这样的快捷方式。
1.3.2 匿名内部类的使用
- 语法:
new 父类名或者接口名(){
// 方法重写
@Override
public void method() {
// 执行语句
}
};
- 使用示例:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02 {
public static void main(String[] args) {
/*
相当于:
class Abc(匿名) implements Chili{
@Override
public void chili() {
System.out.println("湖南线椒~");
}
}
// 多态
Chili abc=new Abc();
*/
// 返回的一个Chili的子类(相当于定义了一个匿名的类,并且创建了这个匿名类的实例对象)
Chili abc = new Chili() { // abc是Chili接口的子类对象
// 重写抽象方法
@Override
public void chili() {
System.out.println("湖南线椒~");
}
};
Chili abc2 = new Chili() { // abc是Chili接口的子类对象
// 重写抽象方法
@Override
public void chili() {
System.out.println("湖南线椒~");
}
};
// 调用重写的方法
abc.chili();
}
}
1.3.3 匿名内部类的本质
- 定义一个没有名字的内部类
- 这个类实现了Chili接口
- 创建了这个没有名字的类的对象
上述代码类似于帮我们定义了一个类(匿名的),这个类重写了接口的抽象方法,然后为这个匿名的类创建了一个对象,用的是接口来接收(这里使用到了多态);
1.3.4 匿名内部类练习
- 定义一个Task接口,提供task任务方法:
package com.dfbz.demo02;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public interface Task {
void task();
}
- 定义一个Start启动类,内部包含一个任务Task:
package com.dfbz.demo02;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Start {
private Task task;
public Start(Task task) {
this.task = task;
}
public void run(){
//执行task任务
task.task();
}
}
- 不使用匿名内部类的方式测试:
1)先定义一个用于实现Task的一个子类,并实现抽象方法:
package com.dfbz.demo02;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class MyTask implements Task{
@Override
public void task() {
System.out.println("MyTask....");
}
}
2)创建MyTask的子类:
package com.dfbz.demo02;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo01 {
public static void main(String[] args) {
// 创建Task的子类对象
MyTask myTask = new MyTask();
// 当做参数传递给Start
Start start = new Start(myTask);
// 执行方法
start.run();
}
}
- 使用匿名内部类方式:
package com.dfbz.demo02;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02 {
public static void main(String[] args) {
/*
相当于:
class Xxx implements Task{
@Override
public void task() {
System.out.println("我是采用匿名内部类来实现的");
}
}
// 父类引用指向子类对象(多态)
Task xxx=new Xxx();
*/
Task xxx = new Task() {
@Override
public void task() {
System.out.println("我是采用匿名内部类来实现的");
}
};
Start start = new Start(xxx);
start.run();
}
}
二、数据结构
2.1 数据结构概述
数据结构是计算机存储、组织数据的方式;通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构的优良将直接影响着我们程序的性能;常用的数据结构有:数组(Array)、栈(Stack)、队列(Queue)、链表(Linked List)、树(Tree)、图(Graph)、堆(Heap)、散列表(Hash)等;
2.2 数据结构的分类
2.2.1 排列方式
1)集合
集合:数据结构中的元素之间除了“同属一个集合” 的相互关系外,别无其他关系;

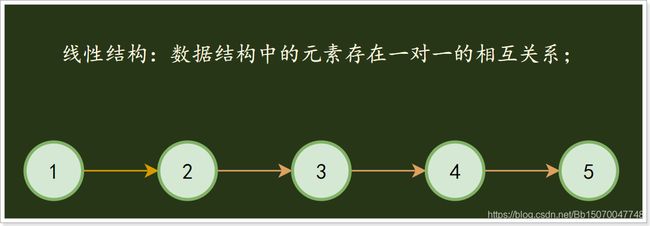
2)线性结构
线性结构:数据结构中的元素存在一对一的相互关系;
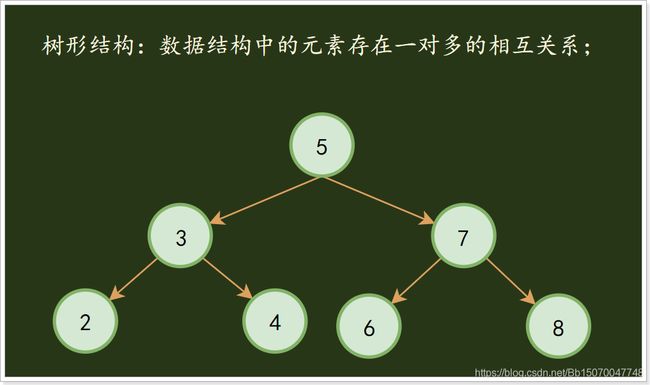
3)树形结构
树形结构:数据结构中的元素存在一对多的相互关系;
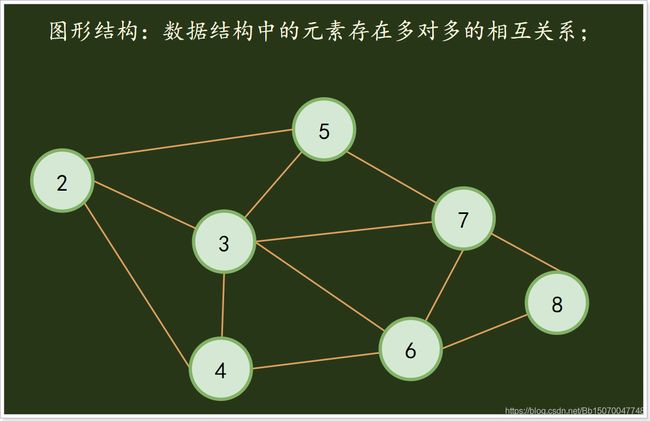
4)图形结构
图形结构:数据结构中的元素存在多对多的相互关系;
2.2.2 逻辑结构
数据结构按逻辑上划分为线性结构与非线性结构;
- 线性结构:有且仅有一个开始结点和一个终端结点,并且所有结点都最多只有一个直接前驱和一个直接后继。
典型的线性表有:链表、栈和队列。它们共同的特点就是数据之间的线性关系,除了头结点和尾结点之外,每个结点都有唯一的前驱和唯一的后继,也就是所谓的一对一的关系。
- 非线性结构:对应于线性结构,非线性结构也就是每个结点可以有不止一个直接前驱和直接后继。常见的非线性结构包括:树、图等。
2.3 数据结构的实现
2.2.1 数组
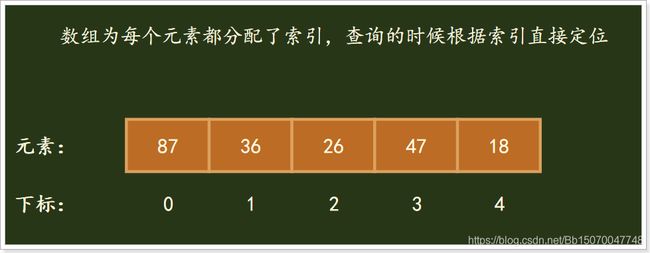
-
数组(Array):数组是有序元素的序列,在内存中的分配是连续的,数组会为存储的元素都分配一个下标(索引),此下标是一个自增连续的,访问数组中的元素通过下标进行访问;数组下标从0开始访问;
-
数组的优点是:查询速度快;
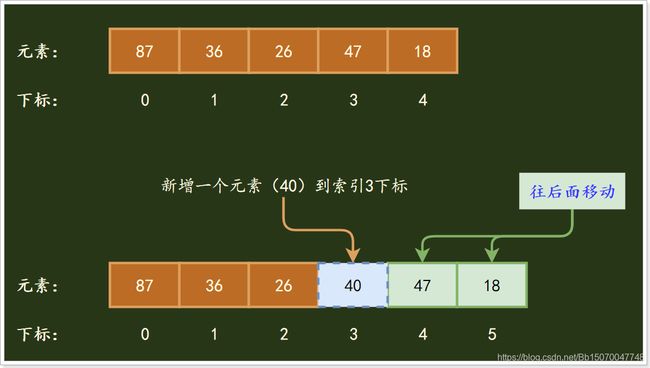
- 数组的缺点是:删除增加、删除慢;由于数组为每个元素都分配了索引且索引是自增连续的,因此一但删除或者新增了某个元素时需要调整后面的所有元素的索引;
新增一个元素40到3索引下标位置:
删除2索引元素:
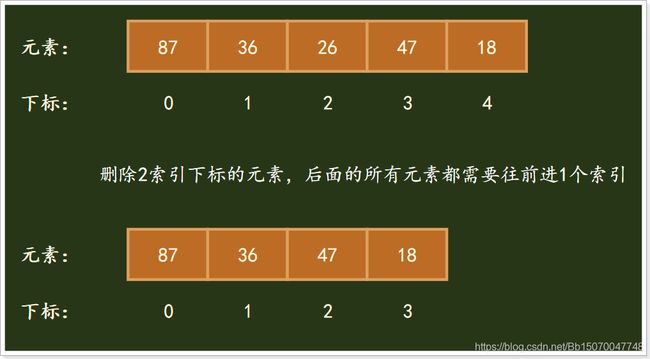
总结:数组查询快,增删慢,适用于频繁查询,增删较少的情况;
2.2.2 链表
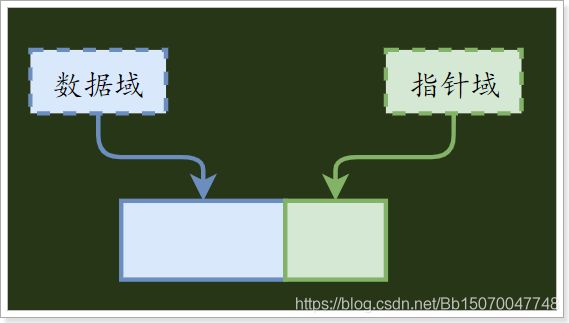
- 链表(Linked List):链表是由一系列节点Node(也可称元素)组成,数据元素的逻辑顺序是通过链表的指针地址实现,通常情况下,每个节点包含两个部分,一个用于存储元素的数据,名叫数据域,另一个则指向下一个相邻节点地址的指针,名叫指针域;根据链表的指向不同可分为单向链表、双向链表、循环链表等;我们本章介绍的是单向链表,也是所有链表中最常见、最简单的链表;
链表的节点(Node):
完整的链表:

- 链表的优点:新增节点、删除节点快;
在链表中新增一个元素:
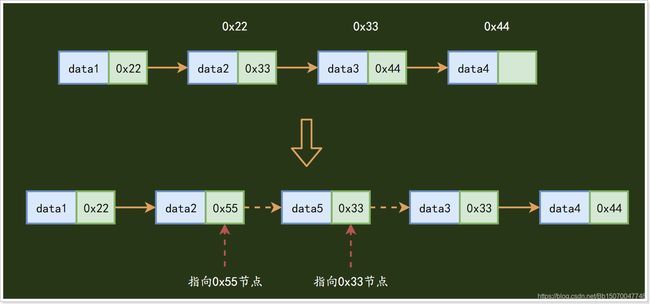
在单向链表中,新增一个元素最多只会影响上一个节点,比在数组中的新增效率要高的多;
在链表中删除一个元素:
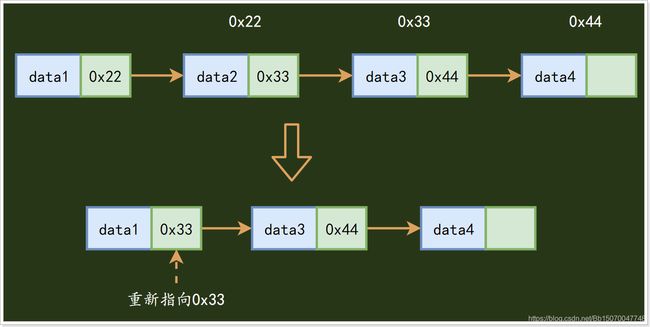
- 链表的缺点:
- 1)查询速度慢,查询从头部开始一直查询到尾部,如果元素刚好是在最尾部那么查询效率势必非常低;
- 2)链表相对于数组多了一个指针域的开销,内存相对占用会比较大;
总结:数据量较小,需要频繁增加,删除操作的场景,查询操作相对较少;
2.2.3 栈
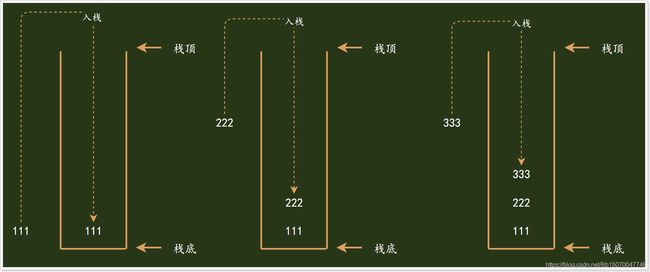
- 栈(Stack):是一种特殊的线性表,仅能在线性表的一端操作,栈顶允许操作,栈底不允许操作。 栈的特点是:先进后出从栈顶放入元素的操作叫入栈(压栈),取出元素叫出栈(弹栈)。
入栈操作:
出栈操作:
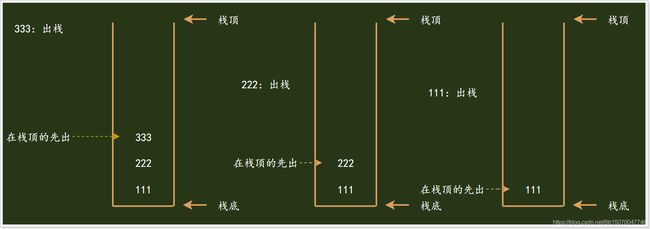
栈的特点:先进后出,Java中的栈内存就是一个栈的数据结构,先调用的方法要等到后调用的方法结束才会弹栈(出栈);
2.2.4 队列
- 队列(Queue):队列与栈一样,也是一种线性表,其限制是仅允许在表的一端进行插入,而在表的另一端进行删除。队列的特点是先进先出,从一端放入元素的操作称为入队,取出元素为出队;

队列的特点:先进先出;
2.2.5 树
树是一种数据结构,它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做 “树” 是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
- 1)每个节点有0个或多个子节点;
- 2)没有父节点的节点称为根节点;
- 3)每一个非根节点有且只有一个父节点;
- 4)除了根节点外,每个子节点可以分为多个不相交的子树;
- 5)右子树永远比左子树大,读取顺序从左到右;
树的分类有非常多种,平衡二叉树(AVL)、红黑树RBL(R-B Tree)、B树(B-Tree)、B+树(B+Tree)等,但最早都是由二叉树演变过去的;
二叉树的特点:每个结点最多有两颗子树
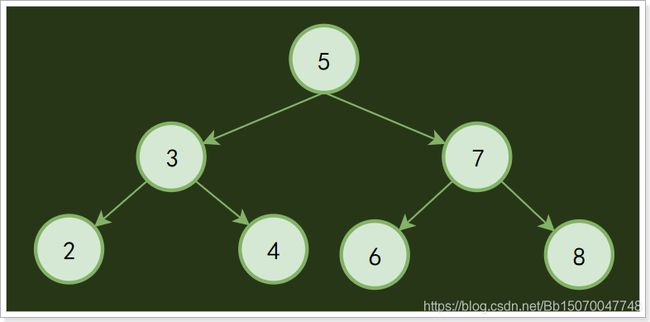
2.2.6 堆
- 堆(Heap):堆可以看做是一颗用数组实现的二叉树,所以它没有使用父指针或者子指针。堆根据“堆属性”来排序,“堆属性”决定了树中节点的位置。
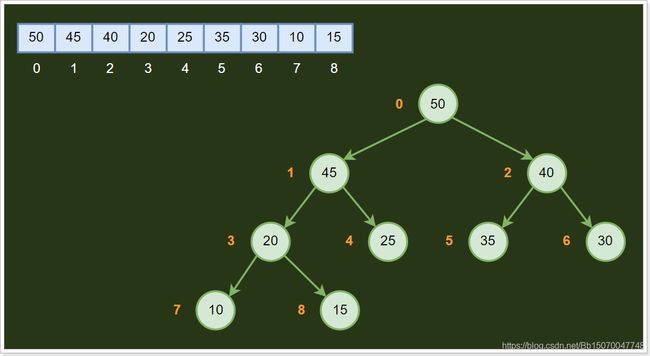
堆分为两种:大根堆和小根堆,两者的差别在于节点的排序方式。
-
大根堆:父节点的值比每一个子节点的值都要大。
-
小根堆:父节点的值比每一个子节点的值都要小。
这就是所谓的“堆属性”,并且这个属性对堆中的每一个节点都成立。
根据这一属性,那么最大堆总是将其中的最大值存放在树的根节点。而对于最小堆,根节点中的元素总是树中的最小值。堆属性非常有用,因为堆常常被当做优先队列使用,因为可以快速地访问到“最重要”的元素。
**tips:**堆的根节点中存放的是最大(大根堆)或者最小(小根堆)元素,但是其他节点的排序顺序是未知的。例如,在一个最大堆中,最大的那一个元素总是位于 index 0 的位置,但是最小的元素则未必是最后一个元素。–唯一能够保证的是最小的元素是一个叶节点,但是不确定是哪一个。
大小根堆数据结构图:
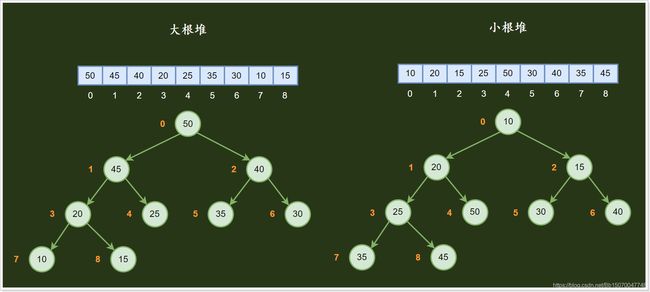
常见的堆有二叉堆、斐波那契堆等。
2.2.7 散列表
- 散列表(Hash),也叫哈希表,是根据键和值 (key和value) 直接进行访问的数据结构,通过key和value来映射到集合中的一个位置,这样就可以很快找到集合中的对应元素。它利用数组支持按照下标访问的特性,所以散列表其实是数组的一种扩展,由数组演化而来。
散列表首先需要根据key来计算数据存储的位置,也就是数组索引的下标;
- HashValue=hash(key)
散列表就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里,这种存储空间可以充分利用数组的查找优势来查找元素,所以查找的速度很快。
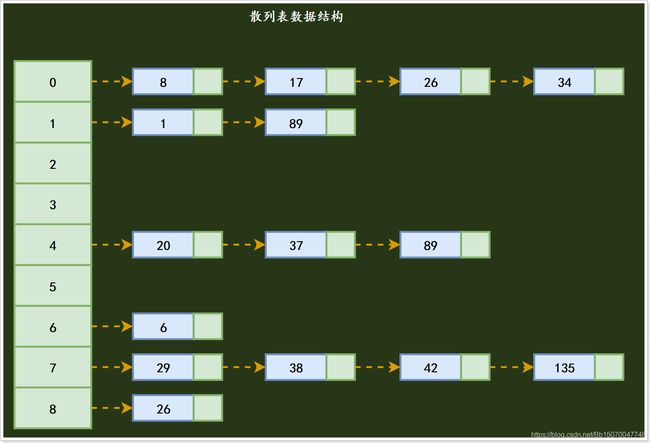
在散列表中,左边是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。
2.2.8 图
- 图(Graph):图是一系列顶点(元素)的集合,这些顶点通过一系列边连接起来组成图这种数据结构。顶点用圆圈表示,边就是这些圆圈之间的连线。顶点之间通过边连接。
图分为有向图和无向图:
- 有向图:边不仅连接两个顶点,并且具有方向;
- 无向图:边仅仅连接两个顶点,没有其他含义;
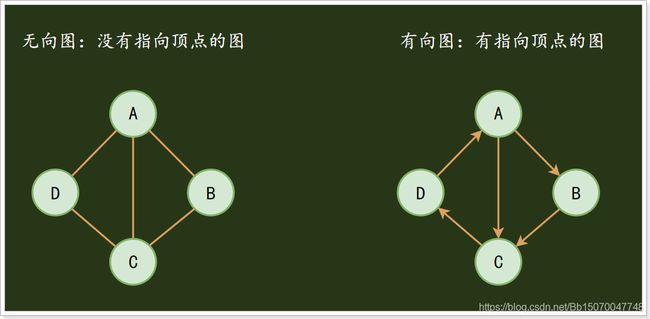
例如,我们可以把图这种数据结构看做是一张地图:
地图中的城市我们看做是顶点,高铁线路看做是边;很显然,我们的地图是一种无向图,以长沙到上海为例,经过的城市有长沙、南昌、杭州、上海等地;那么从上海也可以按照原有的路线进行返回;
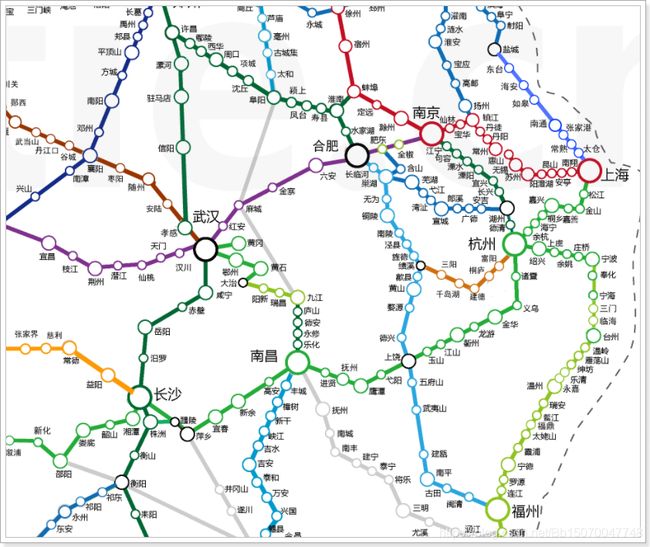
实现了图这种数据结构之后我们可以在此数据结构上做一些复杂的算法计算,如广度优先搜索算法、深度优先搜索算法等;
- 广度搜索:搜索到一个顶点时,先将此顶点的所有子顶点全部搜索完毕,再进行下一个子顶点的子顶点搜索;
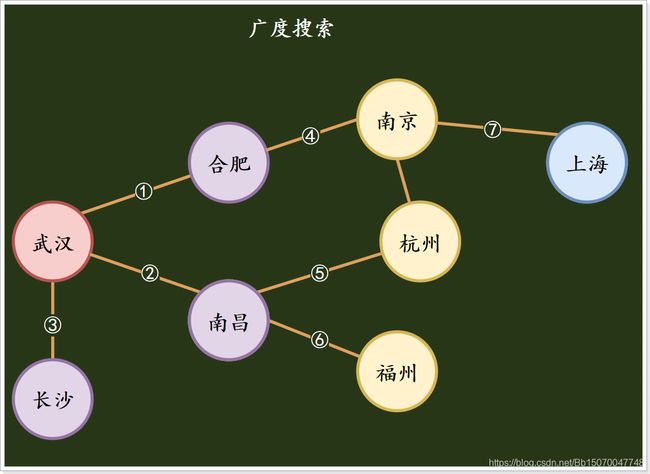
例如上图:以武汉为例进行广度搜索,
1)首先搜索合肥、南昌、长沙等城市;
2)通过合肥搜索到南京;
3)再通过南昌搜索到杭州、福州,
4)最终通过南京搜索到上海;完成图的遍历搜索;
不通过南京搜索到杭州是因为已经通过南昌搜索到杭州了,不需要再次搜索;
- 深度搜索:搜索到一个顶点时,先将此顶点某个子顶点搜索到底部(子顶点的子顶点的子顶点…),然后回到上一级,继续搜索第二个子顶点一直搜索到底部;
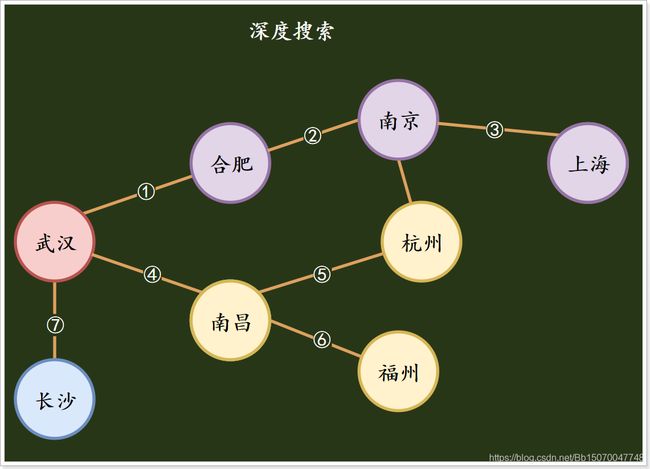
例如上图:以武汉为例进行深度搜索,
1)首先搜索合肥、南京、上海等城市;
2)回到武汉,进行第二子顶点的搜索,搜索南昌、杭州等地;
3)回到南昌,搜索福州;
4)回到武汉,搜索长沙;
图是一种比较复杂的数据结构,在存储数据上有着比较复杂和高效的算法,分别有邻接矩阵 、邻接表、十字链表、邻接多重表、边集数组等存储结构。我们本次了解到这里即可;
三、集合
3.1 集合概述
集合和我们之前学习的数组类似,也是用于存储元素的,也是一种容器;不同的是集合是一个可变长的容器,数组则在创建时候就分配好了大小,不可改变,此外集合的功能要比数组强大的多,底层实现也非常复杂,类型也非常多,不同类型的集合又提供不同的功能;
数组和集合的区别:
- 1)数组的长度是固定的,集合的长度是可变的。
- 2)数组中存储的是同一类型的元素,可以存储基本数据类型值。集合存储的都是对象。而且对象的类型可以不一致。在开发中一般当对象多的时候,使用集合进行存储;
- 3)集合的种类非常多,不同的集合底层采用的数据结构也大不相同,因此集合的功能更加丰富;
3.2 集合体系
集合分为两大类,一类是单列集合;一类是双列集合,两类的底层父接口下有非常多的实现类,不同的实现类,底层所采用的数据结构和算法都是不一样的;
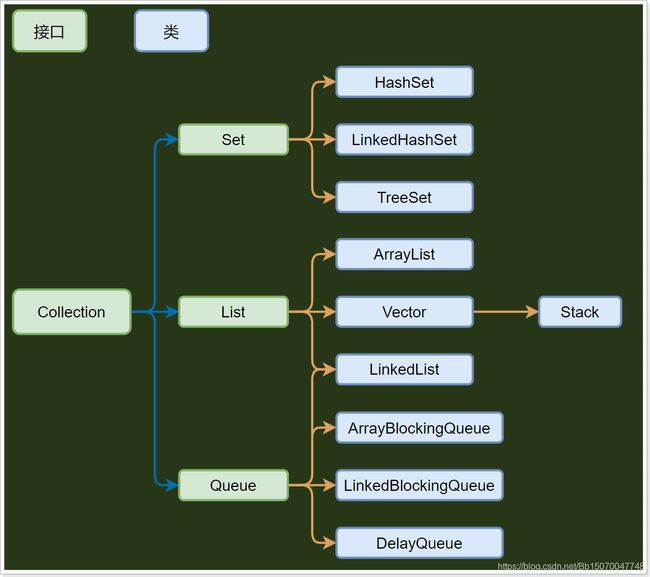
3.2.1 单列集合
单列集合的顶层父接口是java.util.Collection类,这个类中具备的方法下层接口或者类都会具备此方法;
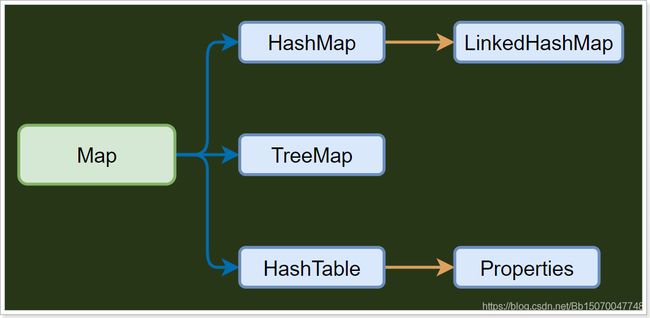
3.2.2 双列集合
双列集合的顶层接口是java.util.Map类;
3.3 Collection 集合
Collection是单列集合的根接口,Collection 接口有 3 种子类型集合: List、Set 和Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、ArrayBlockingQueue等;也就是说Collection中包含的方法这些类中都会具备;
3.3.1 常用方法
Collection是所有单列集合的父接口,因此在Collection中定义了单列集合(List和Set)通用的一些方法,这些方法可用于操作所有的单列集合。方法如下:
public boolean add(E e): 把给定的对象添加到当前集合中 。public void clear():清空集合中所有的元素。public boolean remove(E e): 把给定的对象在当前集合中删除。public boolean contains(E e): 判断当前集合中是否包含给定的对象。public boolean isEmpty(): 判断当前集合是否为空。public int size(): 返回集合中元素的个数。public Object[] toArray(): 把集合中的元素,存储到数组中。
使用示例:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
import java.util.ArrayList;
import java.util.Collection;
public class Demo01 {
public static void main(String[] args) {
// 创建集合对象
// 使用多态形式
Collection<String> cities = new ArrayList<String>();
// 添加功能 boolean add(String s)
cities.add("陕西西安");
cities.add("山西太原");
cities.add("河南郑州");
System.out.println(cities); // [陕西西安, 山西太原, 河南郑州]
// boolean contains(E e) 判断o是否在集合中存在
System.out.println("判断 山西太原 是否在集合中" + cities.contains("山西太原")); // true
//boolean remove(E e) 删除在集合中的o元素
System.out.println("删除河南郑州:" + cities.remove("河南郑州"));
System.out.println("操作之后集合中元素:" + cities);
// size() 集合中有几个元素
System.out.println("集合中有" + cities.size() + "个元素");
System.out.println("-------------------------");
// Object[] toArray()转换成一个Object数组
Object[] objects = cities.toArray();
// 遍历数组
for (int i = 0; i < objects.length; i++) {
System.out.println(objects[i]);
}
// void clear() 清空集合
cities.clear();
System.out.println("集合中内容为:" + cities); // []
// boolean isEmpty() 判断是否为空
System.out.println(cities.isEmpty()); // true
}
}
四、Iterator迭代器
4.1 Iterator接口
在程序开发中,经常需要遍历集合中的所有元素。针对这种需求,JDK专门提供了一个接口java.util.Iterator。Iterator接口也是Java集合中的一员,但它与Collection、Map接口有所不同,Collection接口与Map接口主要用于存储元素,而Iterator主要用于迭代访问(即遍历)Collection中的元素,因此Iterator对象也被称为迭代器。
迭代:即Collection集合元素的通用获取方式。在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,继续在判断,如果还有就再取出出来。一直把集合中的所有元素全部取出。这种取出方式专业术语称为迭代。
4.2 常用方法
public E next():返回迭代的下一个元素。public boolean hasNext():如果仍有元素可以迭代,则返回 true。
使用示例:
package com.dfbz.demo01;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo02 {
public static void main(String[] args) {
// 使用多态方式 创建对象
Collection<String> cities = new ArrayList<String>();
// 添加元素到集合
cities.add("黑龙江哈尔滨");
cities.add("吉林长春");
cities.add("辽宁沈阳");
//使用迭代器 遍历 每个集合对象都有自己的迭代器
Iterator<String> it = cities.iterator();
// 泛型指的是 迭代出 元素的数据类型
while (it.hasNext()) { //判断是否有迭代元素
String s = it.next();//获取迭代出的元素
System.out.println(s);
}
}
}
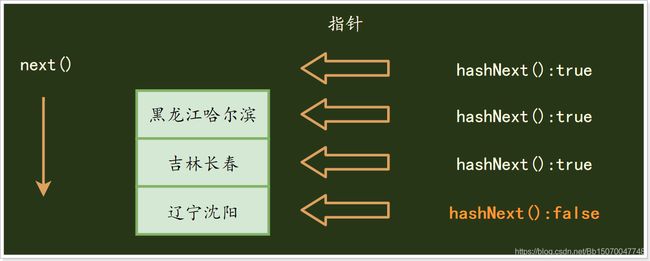
迭代器内部有个指针,默认指向第0行数据(没有指向任何数据),可以通过hashNext()方法来判断指针下一位指向的行是否有数据,通过next()方法可以让指针往下移动,通过hashNext()和next()方法我们可以利用while循环来变量整个迭代器的内容;
4.3 foreach
foreach也称增强for,是JDK1.5以后出来的一个高级for循环,专门用来遍历数组和集合的。它的内部原理其实是个Iterator迭代器,所以在遍历的过程中,不能对集合中的元素进行增删操作。
- 格式:
for(元素的数据类型 变量 : Collection集合或数组){
//写操作代码
}
- 遍历数组:
package com.dfbz.demo01;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo03 {
public static void main(String[] args) {
String[] cities = {"福建福州", "广东广州", "甘肃兰州", "河南郑州", "浙江杭州"};
// 使用增强for遍历数组
for (String city : cities) { //city代表数组中的每个元素
System.out.println(city);
}
}
}
- 遍历集合
package com.dfbz.demo01;
import java.util.ArrayList;
import java.util.Collection;
/**
* @author lscl
* @version 1.0
* @intro:
*/
public class Demo04 {
public static void main(String[] args) {
Collection<String> cities = new ArrayList<String>();
cities.add("宁夏银川");
cities.add("新建乌鲁木齐");
cities.add("西藏拉萨");
cities.add("青海西宁");
//使用增强for遍历
for (String city : cities) {//接收变量city代表 代表被遍历到的集合元素
System.out.println(city);
}
}
}
上一篇:day08【双列集合、异常】
下一篇:day10【单列集合、泛型】
目录:【JavaSE零基础系列教程目录】