机器学习笔记——逻辑回归算法(Logistic Regression)
机器学习笔记——逻辑回归算法(Logistic Regression)
- 正名
-
- 分类算法
- 回归算法思考分类问题
- 逻辑回归函数
- 逻辑回归函数
-
- 逻辑回归分类函数的理解
- 决策边界
-
- example (1)
- example (2)
- 如何选择表达函数?
- 逻辑回归函数成本函数
-
- (1)恶性肿瘤的分析
- (2)良性肿瘤的分析
- 优化写法
- 逻辑回归函数的梯度下降优化算法
-
- 线性回归的梯度下降法和逻辑回归的梯度下降法是一样的吗?
- 小技巧
-
- 线性回归的监控是否收敛 同样适用逻辑回归
- 特征缩放 / 归一化 同样适用逻辑回归
- 逻辑回归算法的高级优化
- 灵活应用逻辑回归函数:
正名
避免一个误区:看这个名字逻辑回归算法(Logistic Regression)不要以为这是个回归算法,这是个分类算法。
分类算法

分类算法中,求得的Y值要么是0,要么是1,所以这是个分类问题。
回归算法思考分类问题
如果用回归算法的思路考虑从分类问题的话,就会得到下面的结果:

最后得到的Y值要么是大于1的,要么是小于0的,从某种角度,这也算是一种分类结果:
(1) 对于>1的,就将分类结果划为:Y=1;
(2) 对于<0的,就将分类结果划为:Y=0;
某种角度可以这么理解,但是对于 >1的,或者 对于<0的的数据集,可取值得范围可能跑到无穷大或者去穷小了,这个就会带来麻烦,所以引出了逻辑回归函数:
逻辑回归函数
如下:
![]()
这个函数的取值范围在:0到1之间。这样对分类结果的判断就方便很多。为什么真么说?再往下看看,常规的逻辑回归函数是指的什么?如下:

上面就是常说的逻辑回归函数的图像,右侧是表征函数,就是 Sigmoid 函数,这个函数值使得Y值最后的取值范围在0-1之间。
通过取中间值:0.5,可以做简单的分类:
(1) 对于>0.5的,就将分类结果划为:Y=1;
(2) 对于<0.5的,就将分类结果划为:Y=0;
所以,看重点 可以这么考虑:
基本上提到 逻辑回归函数你就认为是Sigmoid 函数,而提到 Sigmoid 函数你就逻辑回归函数就可以了,这个思维定势要建立。
重点的事情说一遍:
逻辑回归函数= Sigmoid 函数
Sigmoid 函数=逻辑回归函数
重点的事情说两遍:

这样是不是好理解了很多了?好了到了这里,我们基本明白了逻辑回归函数是分类函数的原因了,那好,让我们继续。。。。
逻辑回归函数
逻辑回归分类函数的理解
再细细地理解一下,
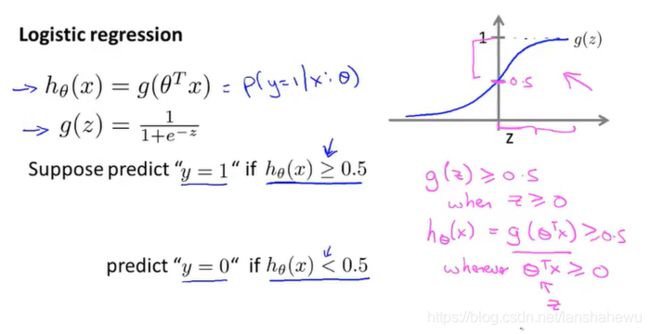
当g(x)=0.5时,自变量Z=0,当Z > 0 时,g(x) > 0.5,就可以理解为达到分类目的了(如下图),将分类结果划分为:Y=1
同样的,当Z < 0 时,g(x) < 0.5,将分类结果划分为:Y=0;

通过以上这些,我们可以更好理解逻辑回归函数(Logistic Regression)中假设函数是如何做出预测的。
决策边界
看到这里是不是对这个Sigmoid函数有了更多的认识了,是不是觉得很有意思了?不着急,先通过一个例子品味一下:
example (1)
左边是数据集,右侧是做出的假设函数:

手动对其分类,如下图,中间品红色的直线即时分类边界,也就是决策边界(Decision Boundary)
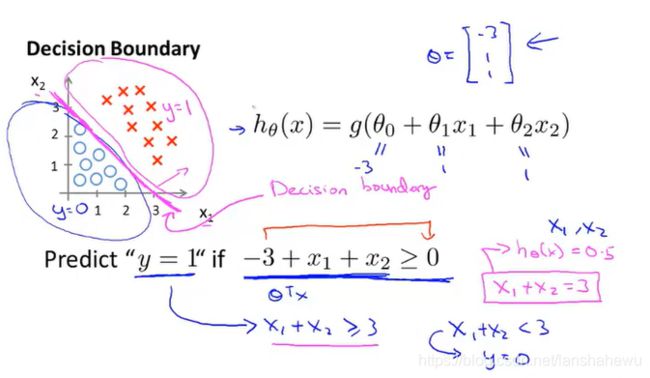
中间的品红色的直线表达式:x+y=3;
这里要注意,这里提出的决策边界的定义是假设函数的属性,不是数据集的属性。
example (2)
再来看一个例子:
图中品红色的圆就是这里的决策边界;
当然了,你还可以有很多其他的决策边界,但是前提是你得知道经典函数的图像,比如下面的:


还有这个小心心:

这些个类似的函数图像,网上很多,一搜一大堆,需要哪个,看着结果类似,把函数表达式拿过来用就阔以了。
如何选择表达函数?
对于给出的m组训练数据,n个特征,已知的 Sigmoid 函数,如下图:

我们如何选择θ?也就是如何选择我们的表达函数?再具体一点,就是前面我放的那么多经典函数图像?
先看看线性回归表达式

如果将这个表达式放到逻辑回归函数中,会出现非凸函数的情况导致在局部聚敛而不是在最佳优化点,

如上图左边,有很多局部最优点,这不是我们想要的,我们要的是右边的结果,一个平滑的凸函数,可以方便找到全局最优点的情况。
逻辑回归函数成本函数
这就引出了我们要在逻辑回归函数中要用到的成本函数了:

看看它的图像:

右侧是推导过程,不难,自己推一下,挺有意思的。这个图像代表的含义还是很有意思的。
(1)恶性肿瘤的分析

这里继续之前的示例:判断肿瘤是良性(g=1)还是恶性(g=0)的,我们来看一下上图中的含义:
这个图象是针对:前提是肿瘤是恶性的,如何来理解图片:
(1)当h(x)➡1时,成本函数(Cost Function)趋于0,也就是这个肿瘤是恶性肿瘤(h(x)=1)概率(Cost Function)为 0 .
(2)当h(x)➡0时,成本函数(Cost Function)趋于无穷大,也就是这个肿瘤是良性肿瘤(h(x)=0)概率(Cost Function)非常大,完全不可能是恶性的。
(3)如果算法错了肿么办?这里个里面是这么做的,用了惩罚过程,看图(这个过程不知道我讲清楚没,也许还需要再提炼):
就是说,如果确实是恶性肿瘤(Y=1),但是算法算出来的结果是良性(h(x)➡0)(就是说算法算出这个肿瘤为恶性的概率为0),与结果相去甚远,这个时候成本函数(Cost Function)的值是趋于无穷大,也就是说,这时候会用一个特别大的代价来惩罚这个算法结果。
(2)良性肿瘤的分析

这个的理解,结合前面的说法,只强调最后,如果计算错了,就是说肿瘤确实是良性(Y=1)的,但是计算的结果确是恶性(h(x)=1)的,这个时候,成本函数(Cost Function)的值是趋于无穷大,也就是说,这时候会用一个特别大的代价来惩罚这个算法结果。
整个过程最好还是在理解一下。
以上是对单个样本的分析,就是说我们仅对良性的或者恶性的肿瘤做了单独的分析,那么在实际中,给你的分析对象,你是不知道是良性的还是恶性的,所以,我们需要对整个表达做合并仅个人理解,后面若有理解上的更新,会再回来更新。
优化写法
如下图

推导过程:

用不同的颜色,分别理解,还是相对简单的。
逻辑回归函数的梯度下降优化算法
结合前面的优化写法,这里给出了梯度下降法在这里的应用:

注意:权重更新的时候,是对所有的 θ 同步更新。如下图所示。记得,这里的 θ 表达式是一个向量哦。

看到这里,问题来了
线性回归的梯度下降法和逻辑回归的梯度下降法是一样的吗?
这里一定要注意,这里的假设函数(Hypothesis) h(x)的定义是不一样的哦,

图中,蓝色的是线性回归的假设函数(hypothesis),这是线性回归中使用的函数;红色的是逻辑回归的假设函数(hypothesis),这可是个Sigmoid函数哦。这里的定义是不一样的哦。好好体会一下。
小技巧
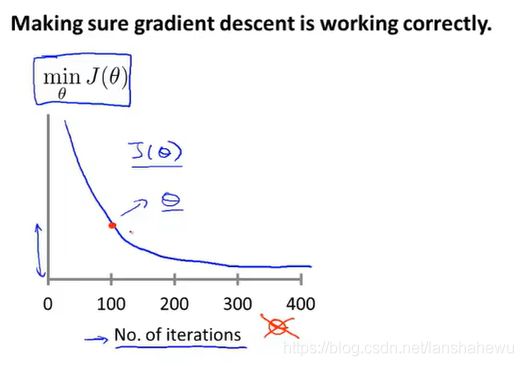
线性回归的监控是否收敛 同样适用逻辑回归
画出迭代次数与成本函数值的变化关系,观察是否收敛
特征缩放 / 归一化 同样适用逻辑回归

特征缩放:就是说,手里要分析的特征值,其范围相差较大,那么需要一些技巧将这些特征值的取值范围都放在大致相同的范围内,这样便于做对比。

特征缩放和归一化不需要太精确,就可以使得梯度下降的速度更快,意味着迭代次数更少。
逻辑回归算法的高级优化

这里面提到的一些高级优化算法有很多优点:
1、自动选择学习率,而不是人工调整。你可以理解为(其实就是)这些算法有一些只能内循环,他们通过这些内循环自动更新学习率,甚至是每一次的 α 都不一样!
2、比梯度下降法更快的效率
缺点看一下:
算法很繁琐。
建议:
如若遇到逻辑回归算法,在采用的高级优化算法的时候(通常是面对的是一个很大的机器学习的问题),直接调用软件库中的函数,拿来用即可!
灵活应用逻辑回归函数:
直接看图

将问题分解,一部分一部分解决。

PS:此学习笔记为学习斯坦福吴恩达机器学习视频笔记。