【论文阅读+翻译】Context-Aware Residual Module for Image Classification
如有侵权,联系删除
【2021ICPR】
Context-Aware Residual Module for Image Classification
用于图像分类的上下文感知残差模块
论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9412503
【摘要】
注意模块在众多视觉任务中取得了巨大的成功。然而,现有的视觉注意模块普遍考虑单一尺度的特征,不能充分利用其多尺度的语境信息。同时,多尺度空间特征表示在广泛的应用中显示出了其卓越的性能。然而,多尺度特征总是以分层的方式表示,即不可能在粒度水平上了解它们的上下文信息。针对上述问题,本文提出了一种用于图像分类的上下文感知残差模块。它包括一个新颖的多尺度通道注意模块MSCAM,通过考虑自身尺度及其周围场的视觉特征来学习精炼的通道权重;以及一个多尺度空间感知模块MSSAM,进一步捕捉更多的空间信息。这两个模块中的任何一个或两个都可以插入到任何具有短残差连接的基于CNN的骨干图像分类体系中,以获得上下文感知增强特征。在包括CIFAR10、CIFAR100、Tiny-ImageNet和ImageNet在内的公共图像识别数据集上的实验一致表明,我们提出的模块的性能显著优于广泛使用的最先进的方法,如ResNet以及MobileNet和SqueezeeNet的轻量级网络。
关键词:上下文感知;多尺度;残差网络;通道注意;图像分类
【介绍】
卷积神经网络在许多视觉任务中得到了广泛的应用,并以其最先进的性能在这些任务中取得了重大进展。它成功应用的关键因素之一是通过卷积算子层学习由粗到细的多尺度特征的自然能力。然而,目前大多数CNN架构[1-9]仅以分层的方式表示多尺度特征,并对这些特征一视同仁,这限制了CNN的进一步改进。
注意机制[10-12]可以根据需要将注意力更多地集中在整个特征空间的特定部分或特定特征上,在现代CNN特别是计算机视觉任务中发挥着重要作用。由于它们有能力区分哪些特征是重要的并强调哪些区域是重要的,这些网络取得了改进的目标识别性能。然而,所有这些方法都只考虑了单尺度视觉知觉领域的注意机制。==通常,在自然场景中,视觉模式是多尺度的,即我们需要从不同的尺度来回答什么和什么地方对于特征地图本身以及它周围的背景信息是重要的。==例如,当一项任务是识别一只猫时,圆形特征是否有意义取决于它是在猫的脸状区域还是杯状区域。
实际上,多尺度信息在深度学习中得到了广泛的应用。早期的CNN通过从粗到细的卷积算子层学习多尺度特征[1-5]。然后提出了一种基于多分支并行捕获多尺度特征的网络[13-16]。另一种网络提出使用多尺度核来扩大接受域[17-18]。这些不同形式的多尺度表示在视觉识别、语音识别等方面都取得了优异的表现,显示出了强大的识别能力。受到上述工作的启发,本文提出了一种通用的、灵活的多尺度上下文感知残差模块,该模块可以插入到现有的主干图像分类体系中,以获得上下文感知增强特征。具体来说,我们有以下主要贡献:
(1)提出了一种新的多尺度信道注意模块MSCAM,该模块通过考虑信道自身尺度和周围场的视觉特征来学习信道的细化权重。
(2)多尺度空间感知模块MSSAM的设计是为了在粒度级别上进一步捕获其多尺度上下文信息,可以与MSCAM结合,然后通过短残差连接插入任何基于CNN的骨干图像分类体系(单独或组合),以获得上下文感知增强特征。
(3)该模块在多个公共数据集上进行了评估,取得了比广泛使用的最先进的方法(包括ResNet、Xception以及MobileNet和SqueezeeNet等轻量级网络)更好的结果。例如,ResNet50+MSCAM的准确率和参数数量都优于ResNet101。
【相关工作】
A. Network engineering
网络工程是当前最重要的视觉研究之一,设计良好的主干结构是提高网络性能的基本途径。
最初,为了设计一个好的主干架构,研究者们尝试设计更深入的CNN以获得更好的性能。具体来说,从AlexNet[1]开始,大量卷积神经网络(CNNs),如VGGNet[2]、GoogLeNet[3]、ResNet[4]、DenseNet[5],试图通过堆叠更多卷积层来提取更丰富的多尺度特征,进一步提高网络性能。
除了深度,一些CNN,如WideResNet[6]和PyramidNet[7],证明了宽度也是提高CNN性能的一个重要因素。此外,ResNeXt[8]和Xception[9]的最新CNN数据进一步表明,基数性也可以使CNN具有较强的表示能力。CNN体系结构的所有这些进展都显示出一种更有效的多尺度表示的趋势。
B. 注意力机制
受人类感知的启发,最近的研究试图在各种基于CNN的视觉任务中引入注意机制[10-12]。SENet[10]的开创性工作之一,提出了一种基于通道注意力的挤压-激励策略来细化瓶颈层中的特性。接下来,为了生成注意感知特征,进一步提高CNN的性能,CBAM[11]结合了通道注意和空间注意,而剩余注意网络[12]结合了通道注意、空间注意和混合注意。虽然这些注意模块能够即插即用,有效提高网络性能,但仍然缺少能够逐步细化通道信息的上下文信息和能够充分利用空间特征进行图像分类的多尺度信息。
【提出的方法】
上下文信息对于通道信息的感知和空间特征的捕捉都非常重要。因此在本节中,我们提出了一种新的多尺度通道注意模块MSCAM来感知多尺度上下文信息,设计了一种多尺度空间感知模块MSSAM来进一步捕捉更多的空间信息,并介绍了如何将这两个模块结合并插入到一个分类网络中。
A. MSCAM,multi-scale channel attention module(多尺度通道注意模块)
SE网络块SENet(squeeze-and-excitation block):
通过精确的建模卷积特征各个通道之间的作用关系来改善网络模型的表达能力。为了达到这个期望,作者提出了一种能够让网络模型对特征进行校准的机制,使网络从全局信息出发来选择性的放大有价值的特征通道并且抑制无用的特征通道。

SE网络模块可以随着在网络层任意插入而自动适应网络模型的需求,如上图。SE网络模块能够以一种未知的方式(因为现在神经网络的具体原理机制还是黑匣子)对特征组进行权值奖惩,加强了所在位置的特征图组的表达能力,在之后的网络层,SE网络模块会不断的特化,并且以一个高度特化类别的方式对所在不同深度的SE网络模块的输入进行相应,因此在整个网络模型中,特征组图的调整的优点能够通过SE网络模块不断地累计。
SENet其实就是一个通道注意模块,给一个权值,加强或减弱某通道的表达能力,只关注单一的视觉知觉领域,而本文的MSCAM仅是在此基础上改为了多尺度的而已,通过不同尺度的感知来理解和判断输入图像中什么是有意义的。
参考文献:
[1] Hu. J, Shen. L, Sun. G, “Squeeze-and-excitation networks,” in IEEE
conference on computer vision and pattern recognition (CVPR), 2018, pp.
7132-7141.
MSCAM(多尺度通道注意模块),图a为挤压-激励块,图b为MSCAM

c为通道数,h和w是特征图的高和宽
图1 (a)为挤压-激励块(squeeze-and-excitation block)[10]实现的传统通道注意模块(CAM,channel attention module)。可以看出,CAM利用特征的通道间关系生成通道注意图。在这里,它只关注单一的视觉知觉领域。而在自然场景[19]中,视觉模式是多尺度的,我们需要通过不同尺度的感知来理解和判断输入图像中什么是有意义的。例如,我们需要依靠脸作为背景来更好地分辨杏仁状物体是眼睛还是叶子,以及它是否有意义。基于此,我们提出了一种新的多尺度通道注意模块MSCAM,该模块通过考虑多尺度上下文信息的视觉特征来学习精细化的通道权重。
MSCAM通过以下步骤构建其多尺度通道关注特征:
Step 1. 引入变尺寸金字塔池化操作(pyramid pooling operation)[20],提取不同的子区域,融合不同金字塔尺度下的特征,获取其上下文信息。最粗的一层是h/2 w /2平均池生成大规模的周边信息,而接下来的金字塔层是h/4 w/4平均池生成其周边信息,最后一层是输入特征的副本。池大小为H/2和H/4的多级核在表示上能保持合理的差距,以上三种不同层次的金字塔池化操作使得既能保留原始特征又能获取其上下文信息成为可能。
金字塔池化操作(pyramid pooling operation):
卷积是不具有尺度不变性的,只是类似Spatial pyramid pooling(空间金字塔池化)的结构给网络带来了不同尺度下优良的效果

上图最中间的模块。可以看到经过一个CNN提取特征后,经过不同大小的pooling,生成不同分辨率feature map。这里的CNN提取特征层是Resnet-101。最中间的conv都是1x1的,改变通道数目,然后进行上采样,网络的效果非常不错,证明了编码器中多尺度的重要性。pyramid pooling是提取出了不同尺度下最精炼的细节,抓得住重点,最后做一个结合,确实能达到非常好的效果。
参考文献:
[1]Zhao. H, Shi. J, Qi. X et al, “Pyramid scene parsing network,” in IEEE
conference on computer vision and pattern recognition (CVPR), 2017, pp.
2881-2890.
参考博文:
[1] Spatial pyramid pooling回顾_THE XING-CSDN博客
[2] 空间金字塔池化Spatial pyramid pooling net,用于语义分割_醒了的追梦人的博客-CSDN博客
Step 2. 对三尺度的金字塔池化输出采用三种挤压-激励操作(图a结构)[10],计算通道权重,提取不同尺度的精细化特征。
Step 3. 通过上采样(up-sampling)和连接(concatenation)操作,采用组合操作来合并不同尺度的细化特征。
Step 4. 通过标准的1*1卷积层卷积得到输出的多尺度通道注意特征图。
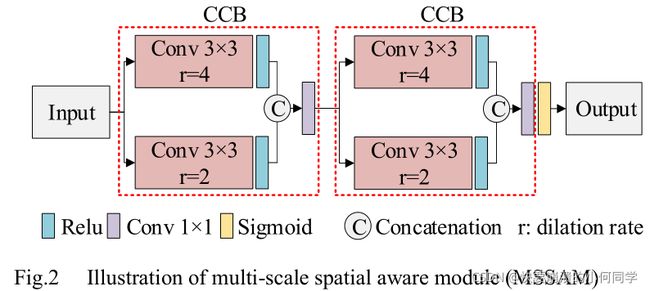
B. MSSAM,multi-scale spatial aware module (多尺度空间感知模块)
参考多尺度残差块MSRB[17],通过引入扩张卷积(dilated convolution),设计多尺度空间感知模块MSSAM,有效检测多尺度空间特征。
如图2所示,MSSAM通过signmoid函数将两个连续的上下文组合块(CCB)堆叠起来。在这里,CCB的设计是通过学习大接受域的语境组合特征来捕获大规模空间信息。显然,增加内核大小可以用来生成较大的接受字段。然而,增加内核大小也意味着增加内存计算量。为了避免这一问题,在CCB中引入了扩张卷积(dilated convolution),以扩大接收域,使卷积输出包含更大范围的信息。具体而言,在CCB中,我们引入两个具有不同膨胀因子的并行扩张卷积层来捕捉不同尺度的空间特征,然后将这些多尺度特征连接起来增加信道大小,最后使用1*1卷积使信道数与输入相同。
【扩张卷积】
扩张卷积(dilated convolutions)又名空洞卷积(atrous convolutions),是针对图像语义分割问题中下采样会降低图像分辨率、丢失信息而提出的一种卷积思路。
下采样或降采样的作用:
1、使得图像符合显示区域的大小;
2、生成对应图像的缩略图;
3、处理大型图像减少运算量。
扩张卷积(dilated convolutions)向卷积层引入了一个称为 “扩张率(dilation rate)”的新参数,该参数定义了卷积核处理数据时各值的间距。换句话说,相比原来的标准卷积,扩张卷积(dilated convolution) 多了一个hyper-parameter(超参数)称之为dilation rate(扩张率),指的是kernel各点之前的间隔数量,正常的convolution 的 dilatation rate为 1.当等于1 时,扩张卷积会变得和标准卷积一样。
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。

在这张图像中,3×3 的红点表示经过卷积后,输出图像是 3×3 像素。尽管所有这三个扩张卷积的输出都是同一尺寸,但模型观察到的感受野有很大的不同。l=1时感受野为 3×3,l=2 时为 7×7,l=3 时,感受野的大小就增加到了 15×15。有趣的是,与这些操作相关的参数的数量是相等的。我们「观察」更大的感受野不会有额外的成本。因此,扩张卷积可用于廉价地增大输出单元的感受野,而不会增大其核大小,这在多个扩张卷积彼此堆叠时尤其有效。
扩张卷积与普通的卷积相比,除了卷积核的大小以外,还有一个扩张率(dilation rate)参数,主要用来表示扩张的大小。扩张卷积与普通卷积的相同点在于,卷积核的大小是一样的,在神经网络中即参数数量不变,区别在于扩张卷积具有更大的感受野。
扩展卷积在保持参数个数不变的情况下增大了卷积核的感受野,同时它可以保证输出的特征映射(feature map)的大小保持不变。
参考博文:
[1] 扩张卷积(Atrous 卷积)_小镇大爱的博客-CSDN博客
C. 实例化
MSCAM和MSSAM可以单独或组合插入任何基于CNN的骨干图像分类体系,以进一步捕获上下文信息。图3展示了五种不同的方案。考虑到MSCAM和MSSAM并行结合是图3中最复杂的方案,我们以该方案为例,简要说明所提模块的实例化过程。首先,将Blocki的feature map输入到MSCAM和MSSAM中,生成多尺度通道注意细化特征和多尺度空间感知细化特征。其次,通过连接操作将两个细化的特征结合起来。然后,对合并后的结果进行标准的1*1卷积,使输出特征与输入特征具有相同的大小。最后,通过基于恒等映射的短残差连接将精炼后的特征添加到原始特征中,获得感知上下文的增强特征,并将其输入到下一个块中。
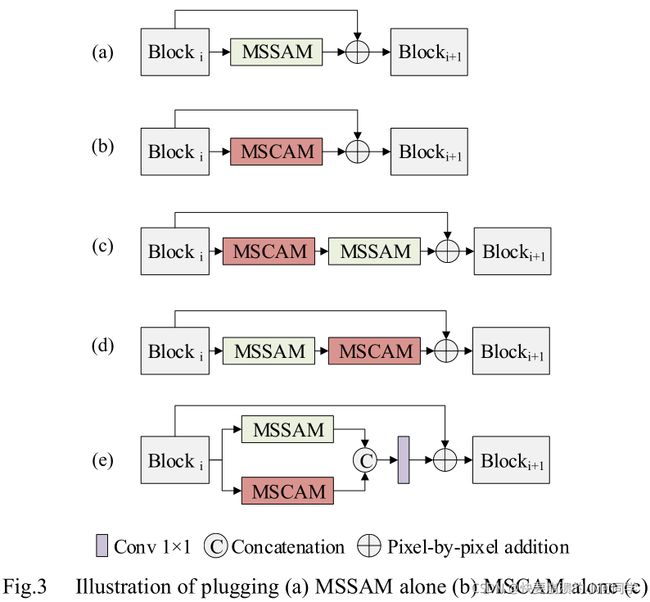
如图3所示,需要强调的是所提出的模块是被插入到两个块之间的。在这里,块被定义为一组输出大小相同的连续卷积:(1)一种选择是我们把所有大小相同的连续卷积看作一个块。在这种情况下,每个块的输出是这个尺度感受野的最终特征,因此可以将MSCAM(MSSAM)添加到这个块的最后一个卷积层的后面,以便通过捕获它们在这个尺度感受野的上下文信息来生成细化的特征。如表1所示,对于基线网络ResNet50,我们以这种方式插入建议的模块。

(2)另一种选择是,我们将具有相同大小的连续卷积的一部分视为一个块,从而根据其上下文信息生成更精细的特征。如表2所示,
SqueezeNet[21]就是这样的情况,我们把提议的模块插在每次激励的后面。

我们也可以根据具体的网络架构,使用上述两种方法同时将所提出的模块插入到一个网络中,如表3所示的MobileNet[22]网络。

【实验】
为了更好地进行专一的比较,我们在PyTorch框架中复现了所有的网络,然后在NVIDIA
Tesla V100 32G上进行训练和测试。
A. 实验细节
1)baselines
我们使用深度为18到101的ResNet [4]和Xception [9]作为基线网络,考虑到它们在图像分类方面最先进的性能。同时,为了更全面地测试我们的模块的适应性,我们还选择了MobileNet和SqueezeNet(带简单旁路的SqueezeNet)等一些典型的轻量级网络作为基线网络。
2)数据集
CIFAR 10[23]。该数据集由60000张彩色自然图像组成,包含32*32像素,平均分为10类。在训练集中每个类有5000张图像,测试集中每一类有1000张图片。
CIFAR100[23]。这个数据集也是由60000个彩色自然图像组成,32*32像素,平均分为100个类。在训练集中,每个类有500张图像,在测试集中,每个类有100张图像。
Tiny-ImageNet[24]。这个数据集是原始ImageNet数据集的一个修改过的子集。它由11万幅64*64像素的图像和200个类组成,每类500幅图像用于训练,50幅图像用于测试。
ImageNet[25]。该数据集是一个公共大型数据集,包含130万张训练图像、50,000张验证图像和100,000张测试图像,包含1,000个类。在SENet[10]和CBAM[11]之后,从图像或其水平翻转中随机采样224*224大小的裁剪图片。使用平均值和标准差将图像归一化到[0 1]。我们报告验证集上的单图像裁剪误差率。
很明显,上述四个数据集的图像数量、类型和分辨率都不同,因此基于它们的分类实验仍然很有说服力。
3)实现细节
提议的模块可以插入到任何CNN架构中。在实验中,我们将CAM[10]、CBAM[11]和我们的模块分别插入基线网络的两个conv块之间。根据图像总数,我们使用SGD, CIFAR数据集的mini-batch大小为128,Tiny-ImageNet和ImageNet的mini-batch大小为256。CIFAR100的学习率从0.1开始,考虑到每类图像的数量,每60个epoch除以10,其他数据集每30个epoch除以10。
MSCAM(MSSAM) +ResNet、SqueezeNet和MobileNet的网络架构分别如表I、表II和表III所示。特别地,网络Xception包含3个流:入口流、中间流和出口流。考虑到这三个流都有自己的设计理念,我们只在每个流的末端添加注意模块,以避免破坏网络结构。
B. 结果对比和分析
在本节中,我们将用经验来展示我们所建议的模块的有效性。
1)Ablation studies(消融研究)
一些新颖的深度学习模型在论文中都会进行AblationStudy,这部分的主要意义在于系统性的移除模型中的各种组件/trick等因子或者是创新的方法,来探究各个因素对于模型整体贡献的强弱多寡,找到对性能最主要的影响因素。
基于CIFAR100数据集和ResNet18、ResNet50基线的消融研究如表4所示。可以看到:(1)与ResNet18、ResNet50基线相比,使用我们模块的模型的错误率均有不同程度的下降。(2)MSCAM与MSSAM的顺序组合(MSCAM+MSSAM或MSSAM+MSCAM)与MSSAM模块的组合失效,而MSCAM与MSSAM的并行组合(MSSAM&MSCAM)是最最好的安排策略,进一步推动了性能。(3)对于ResNet18和ResNet50,baseline+MSCAM的错误率与baseline+MSCAM & MSSAM的错误率是一致的;而前者的参数比后者小得多。
考虑到网络性能,在接下来的实验中,我们对所有的基线网络只使用MSCAM和MSCAM&MSSAM(缩写为MSC&SAM)模块。
2)与最先进的网络进行比较
在CIFAR10、CIFAR100和Tiny-ImageNet数据集上与最新方法的比较结果如表v所示。可以清楚地看到:(1)对于每一个基线,在几乎所有的数据集上,采用MSCAM或MSC&SAM模块的网络都优于原始网络和采用CAM或CBAM模块的网络,证明了所提出模块的有效性。(2)将ResNet34与ResNet18+MSCAM、ResNet50与ResNet34+MSCAM、ResNet101与ResNet50+MSCAM进行比较,可以发现前者的准确率和参数个数均优于后者。主要原因是所提出的MSCAM模块可以使网络在一层中获取更多的上下文信息,与更深层次的网络具有相同的效果。(3)尽管对于大多数baseline而言,网络baseline+ MSC&SAM在精度上略优于baseline+MSCAM,但前者的参数数量远高于后者。因此,只有当用户不关心参数而更关心准确率时,所提出的MSC&SAM模块才有价值。
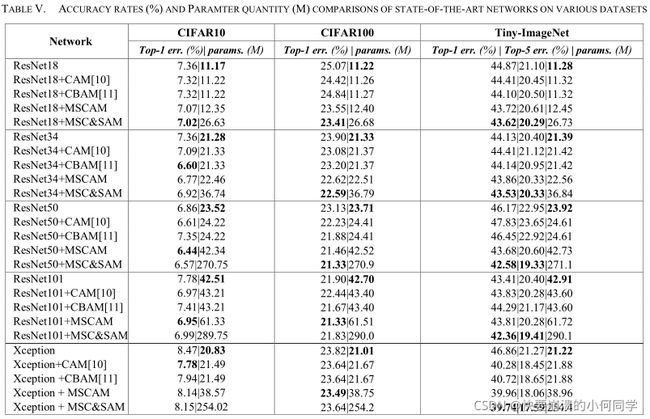
图4给出了Tiny-ImageNet数据集上不同基线的top-1和top-5误差曲线。结果表明,我们提出的MSC&SAM不仅优于CAM[10]或CBAM[11],而且在所有的误差图中都具有很强的鲁棒性。

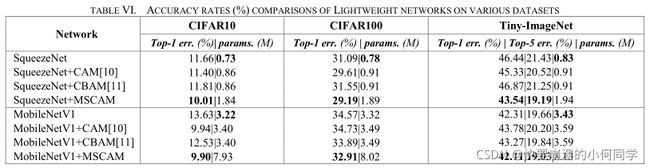
3)与轻量级网络的比较
如表V所示,MSC&SAM模块的参数量非常大,因此,为了保持轻量级网络的轻量化特性,在本次实验中,我们只在轻量级网络中加入了MSCAM模块。
表VI显示了两种轻量级网络在不同数据集上的定量比较结果。可以看出:使用MSCAM模块的网络对于SqueezeNet和MobileNetV1的所有数据集都实现了最高的精度。同时,与baseline相比,SqueezeNet+MSCAM新增加的参数小于1M,而MobileNetV1+MSCAM新增加的参数小于4M。因此,MSCAM也适用于轻量级网络。
4)在大数据集ImageNet的比较
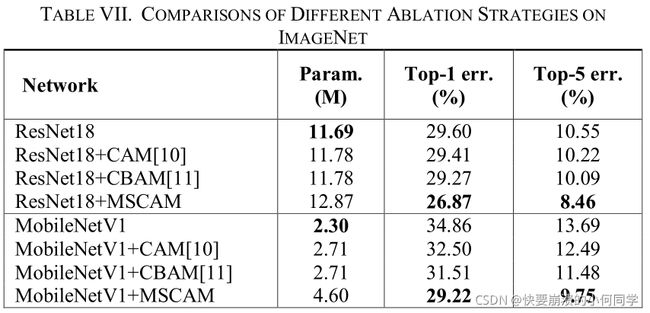
为了评估所提出的模块对大数据集的适应性,我们进一步选择一个残差网络和一个轻量级网络作为baseline,并将所提出的模块与ImageNet上的baseline baseline+CAM[10]和baseline+CBAM[11]进行比较。比较结果见表VII。我们可以观察到:(1)采用MSCAM的ResNet18性能优于baseline和与其他模块的baseline。与ResNet18、ResNet18+CAM和ResNet18+CBAM相比,采用MSCAM的ResNet18的top-1错误率分别降低了2.73%、2.54%和2.40%,top-5错误率分别降低了2.09%、1.76%和1.63%。同时,增加的参数个数小于1.2M。(2)采用MSCAM的轻量级网络MoblieNetV1的性能提升更为明显。其中,MoblieNetV1、MoblieNetV1+CAM和MoblieNetV1+CBAM相比,采用MSCAM的MoblieNetV1的top-1错误率分别降低了5.64%、3.28%和2.29%,top-5错误率分别降低了3.94%、2.74%和1.73%。提出的轻量级网络MSCAM模块的突出不足是,虽然增加的参数小于2.5M,但增加率为100%。如何为轻量级网络建立更轻量级的MSCAM是我们未来的工作。
5)可视化结果
图5基于TinyImageNet中的测试集,使用Grad-CAM可视化了不同网络的最后卷积输出的特征[26]。Grad-CAM使用给定目标概念的梯度来产生空间定位图,突出图像中用于预测概念的重要区域。这意味着在理想的分类网络中,类别标签对应的关注区域应该被清晰地突出显示。如图5所示,通过采用MSCAM,基于其多尺度上下文信息,与ResNet50和ResNet50+CAM相比,关注区域可以被更精确地聚焦。因此,MSCAM可以插入不同的分类网络,生成更精细的特征,提高其图像分类能力。

【结论】
本文首先提出了基于多尺度上下文信息准确提取上下文信息的MSCAM模块,然后设计了基于多尺度空间信息的MSCAM模块,最后通过不同的方式将其组合起来进一步提高网络性能。在先进网络和轻量化网络上的实验验证了所提模块的有效性。目前,我们只在分类任务中使用我们提出的模块,而在未来的工作中,我们将使用它们来探索其他的视觉任务,如分割、检测等。此外,我们还将专注于为轻量级网络建立更轻量级的MSCAM。
g-Q2CDSzsj-1632471350316)]
【结论】
本文首先提出了基于多尺度上下文信息准确提取上下文信息的MSCAM模块,然后设计了基于多尺度空间信息的MSCAM模块,最后通过不同的方式将其组合起来进一步提高网络性能。在先进网络和轻量化网络上的实验验证了所提模块的有效性。目前,我们只在分类任务中使用我们提出的模块,而在未来的工作中,我们将使用它们来探索其他的视觉任务,如分割、检测等。此外,我们还将专注于为轻量级网络建立更轻量级的MSCAM。