《Python 深度学习》之”新闻分类:多分类问题“代码分享
本文将会构建一个网络,将路透社新闻划分为46个互斥的主题。
一.路透社数据集
1.加载路透社数据集
from keras.datasets import reuters
(train_data, train_labels),(test_data,test_labels) = reuters.load_data(num_words = 10000)
#参数num_words = 10000将数据限定为前10000个最常见的单词
显示训练样本和测试样本
len(train_data) #OUT:8982
len(test_data)#OUT:2246
2.将索引解码为新闻文本
word_index = reuters.get_word_index()
reverse_word_index = dict([(value,key) for (key, value) in word_index.items()])
decoded_newswire = ''.join([reverse_word_index.get(i -3, '?') for i in train_data[0]])
#索引减3是因为)0,1,2是为”padding“填充、”start of sequence“(序列开始)、”unkown(未知词)分别保留的索引“
二.准备数据
3.编码数据
import numpy as np
def vectorize_sequences(sequences,dimension=10000):
results = np.zeros((len(sequences), dimension))
for i ,sequence in enumerate(sequences):
results[i,sequence] = 1.
return results
x_train = vectorize_sequences(train_data) #将训练标签向量化
x_test = vectorize_sequences(test_data) #将测试标签向量化
*注意,Kares内置方法可以实现这个操作:
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
三.构建网络
4.模型定义
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
5.模型编译
model.compile(optimizer='rmsprop' ,
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
四.验证你的方法
6.留出验证集
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
7.训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data = (x_val, y_val))

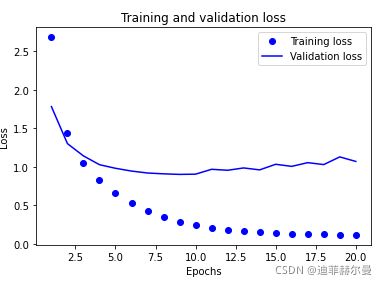
绘制损失曲线和精度曲线
import matplotlib.pyplot as plt
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(loss)+1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label = 'Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.clf()
accuracy = history.history['accuracy']
val_accuracy = history.history['val_accuracy']
plt.plot(epochs, accuracy, 'bo', label = 'Training accuracy')
plt.plot(epochs, val_accuracy, 'b', label = 'Validation accuracy')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()

*注意:网络在训练9轮后开始过拟合。
8.从头开始重新训练一个模型
model = models.Sequential()
model.add(layers.Dense(64,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(64,activation='relu'))
model.add(layers.Dense(46,activation='softmax'))
model.compile(optimizer='rmsprop',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=9,
batch_size=512,
validation_data=(x_val,y_val))
results = model.evaluate(x_test,one_hot_test_labels)

9.在新数据上生成预测结果
results #[0.9595018029212952, 0.7871772050857544]
predictions中每个元素都是长度为46的向量
predictions = model.predict(x_test)
predictions[0].shape #(46,)
这个向量的所有元素综总和为1
np.sum(predictions[0]) #1.0
最大的元素就是预测类别,即概率最大的类别
np.argmax(predictions[0]) #3