拓端tecdat|Python多项式Logistic逻辑回归进行多类别分类和交叉验证准确度箱线图可视化
原文链接:http://tecdat.cn/?p=25583
原文出处:拓端数据部落公众号
多项式逻辑回归 是逻辑回归的扩展,它增加了对多类分类问题的支持。
默认情况下,逻辑回归仅限于两类分类问题。一些扩展,可以允许将逻辑回归用于多类分类问题,尽管它们要求首先将分类问题转换为多个二元分类问题。
相反,多项逻辑回归算法是逻辑回归模型的扩展,涉及将损失函数更改为交叉熵损失,并将概率分布预测为多项概率分布,以原生支持多类分类问题。
在本教程中,您将了解如何在 Python 中开发多项逻辑回归模型。
完成本教程后,您将了解:
- 多项逻辑回归是逻辑回归的扩展,用于多类分类。
- 如何开发和评估多项逻辑回归并开发最终模型以对新数据进行预测。
- 如何调整多项逻辑回归模型的惩罚超参数。
教程概述
本教程分为三个部分:
- 多项逻辑回归
- 评估多项逻辑回归模型
- 多项 Logistic逻辑回归的调整惩罚
多项逻辑Logistic回归
逻辑回归是一种分类算法。
它适用于具有数字输入变量和具有两个值或类的分类目标变量的数据集。这种类型的问题被称为二元分类问题。
逻辑回归是为两类问题设计的,使用二项式概率分布函数。对于正类或结果,类标签映射到 1,对于负类或结果,映射到 0。拟合模型预测示例属于第 1 类的概率。
默认情况下,逻辑回归不能用于具有两个以上类别标签的分类任务,即所谓的多类别分类。
相反,它需要修改以支持多类分类问题。
使逻辑回归适应多类分类问题的一种流行方法是将多类分类问题拆分为多个二元分类问题,并在每个子问题上拟合标准逻辑回归模型。
另一种方法涉及更改逻辑回归模型以直接支持多个类别标签的预测。具体来说,预测输入示例属于每个已知类标签的概率。
定义多类概率的概率分布称为多项概率分布。适用于学习和预测多项概率分布的逻辑回归模型称为多项逻辑回归。同样,我们可以将默认或标准逻辑回归称为二项式逻辑回归。
- 二项式逻辑回归:标准逻辑回归,预测每个输入示例的二项式概率(即两个类别)。
- 多项式逻辑回归:逻辑回归的修改版本,预测每个输入示例的多项概率(即多于两个类别)。
将逻辑回归从二项式概率改为多项式概率,需要改变用于训练模型的损失函数(例如,将对数损失改为交叉熵损失),并将输出从单一概率值改为每个类标签的一个概率。
现在我们已经熟悉了多项逻辑回归,让我们看看我们如何在Python中开发和评估多项逻辑回归模型。
评估多指标Logistic回归模型
在本节中,我们将使用Python机器学习库开发并评估一个多项逻辑回归模型。
首先,我们将定义一个合成的多类分类数据集,作为基础。这是一个通用的数据集,以后你可以很容易地用你自己加载的数据集来替换。
classification()函数可以用来生成一个具有一定数量的行、列和类的数据集。在这种情况下,我们将生成一个具有1000行、10个输入变量或列和3个类的数据集。
下面的例子总结了数组的形状和三个类中的例子分布。
# 测试分类数据集
import Counter
# 定义数据集
X, y = mclas
# 对数据集进行总结
print
运行这个例子,证实了数据集有1,000行和10列,正如我们预期的那样,而且这些行大约均匀地分布在三个类别中,每个类别中大约有334个例子。

scikit库支持Logistic回归。
将 "solver "参数设置为支持多指标逻辑回归的解算器,从而配置为多指标逻辑回归。
# 定义多项式逻辑回归模型
modl = LoRe(muss)
多项式逻辑回归模型将使用交叉熵损失进行拟合,并将预测每个整数编码的类标签的整数值。
现在我们已经熟悉了多项逻辑回归API,我们可以看看如何在我们的合成多类分类数据集上评估一个多项逻辑回归模型。
使用重复分层的k-fold交叉验证来评估分类模型是一个好的做法。分层确保了每个交叉验证折在每个类别中的例子的分布与整个训练数据集大致相同。
我们将使用10个折的三次重复,这是一个很好的默认值,并且考虑到类的平衡,使用分类精度来评估模型性能。
下面列出了评估多类分类的多项逻辑回归的完整例子。
# 评估多指标Logistic回归模型
from numpy import mean
# 定义数据集
X, y = makeclas
# 定义多项式逻辑回归模型
modl = LogReg
# 定义模型的评估程序
cv = RepeKFold
# 评估模型并收集分数
n_scores = crovalsc
# 报告模型的性能
print('Mean Accurac)
运行这个例子可以报告所有交叉验证和评估程序的重复的平均分类准确率。
注意:鉴于算法或评估程序的随机性,或数字精度的差异,你的结果可能会有所不同。考虑把这个例子运行几次,然后比较平均结果。
在这个例子中,我们可以看到,在我们的合成分类数据集上,带有默认惩罚的多项逻辑回归模型取得了约68.1%的平均分类精度。
![]()
我们可以决定使用多项逻辑回归模型作为我们的最终模型,并对新数据进行预测。
这可以通过首先在所有可用数据上拟合模型,然后调用predict()函数对新数据进行预测来实现。
下面的例子演示了如何使用多项逻辑回归模型对新数据进行预测。
# 用多指标逻辑回归模型进行预测
from sklearn.datasets
# 定义数据集
X, y = makclas
# 定义多项式逻辑回归模型
model = LogRegr
# 在整个数据集上拟合该模型
fit(X, y)
# 定义单行输入数据
row
# 预测类别标签
predict([row])
# 对预测的类进行总结
print('Predic运行这个例子首先在所有可用的数据上拟合模型,然后定义一行数据,提供给模型,以便进行预测。
在这种情况下,我们可以看到,模型对单行数据的预测是 "1 "类。
![]()
多项式逻辑回归的一个好处是,它可以预测数据集中所有已知类标签的校准概率。
这可以通过调用模型的predict_proba()函数来实现。
下面的例子演示了如何使用多项逻辑回归模型预测一个新例子的多项概率分布。
# 用多指标逻辑回归模型预测概率
from sklea
# 定义数据集
X, y = makclassif
# 定义多项式逻辑回归模型
model = LoRegre
# 在整个数据集上拟合该模型
fit(X, y)
# 定义单行输入数据
# 预测一个多项式概率分布
preprob
# 对预测的概率进行总结
print('Predict
运行这个例子首先在所有可用的数据上拟合模型,然后定义一行数据,将其提供给模型,以便预测类的概率。
注意:鉴于算法或评估程序的随机性,或数字精度的差异,你的结果可能会有所不同。考虑将这个例子运行几次,并比较平均结果。
在这个例子中,我们可以看到第1类(例如,数组索引被映射到类的整数值)的预测概率最大,约为0.50。
![]()
现在我们已经熟悉了评估和使用多项逻辑回归模型,让我们来探索如何调整模型的超参数。
多项式Logistic回归的调整惩罚
调整多项逻辑回归的一个重要超参数是惩罚项。
这个项对模型施加惩罚,寻求更小的模型权重。这是通过在损失函数中加入模型系数的加权和来实现的,鼓励模型在拟合模型的同时减少权重的大小和误差。
一种流行的惩罚类型是L2惩罚,它将系数的平方之和(加权)加入到损失函数中。可以使用系数的加权,将惩罚的强度从完全惩罚降低到非常轻微的惩罚。
默认情况下,LogisticRegression类使用L2惩罚,系数的权重设置为1.0。惩罚的类型可以通过 "惩罚 "参数设置,其值为 "l1"、"l2"、"elasticnet"(例如两者),尽管不是所有的求解器都支持所有的惩罚类型。惩罚中的系数权重可以通过 "C "参数设置。
# 定义带有默认惩罚的多项式逻辑回归模型
Logistic惩罚的加权实际上是反加权,也许惩罚=1-C。
从文件中可以看出。
C : float, default=1.0
正则化强度的倒数,必须是一个正的浮点数。与支持向量机一样,较小的值表示较强的惩罚。
这意味着,接近1.0的值表示很少的惩罚,接近0的值表示强的惩罚。C值为1.0可能表示根本没有惩罚。
- C接近于1.0。轻惩罚。
- C接近0.0:强惩罚。
# 定义无惩罚的多项式逻辑回归模型
LogRegr( penal='none')现在我们已经熟悉了惩罚,让我们来看看如何探索不同惩罚值对多指标逻辑回归模型性能的影响。
在对数尺度上测试惩罚值是很常见的,这样可以快速发现对一个模型很有效的惩罚尺度。一旦发现,在这个尺度上进一步调整可能是有益的。
我们将在对数尺度上探索加权值在0.0001到1.0之间的L2惩罚,此外还有不惩罚或0.0。
下面列出了评估多项逻辑回归的L2惩罚值的完整例子。
#调整多指标逻辑回归的正则化
from numpy import mean
# 获取数据集
def getet():
X, y = make_
# 获得一个要评估的模型列表
def ges():
models = dict()
#为模型创建名称
# 在某些情况下关闭惩罚
# 在这种情况下没有惩罚
models[key] = LogisticReg penalty='none'
models[key] = LogisticR penalty='l2'
# 使用交叉验证法评估一个给定的模型
def evamodel
# 定义评估程序
cv = RataifiFod
# 评估模型
scs= cssva_scre
# 定义数据集
X, y = gatet()
# 获得要评估的模型
gt_dels()
# 评估模型并存储结果
for name, moel in mos.ims():
# 评估模型并收集分数
oes = evadel(model, X, y)
# 存储结果
rsts.append
names.append
# 总结
# 绘制模型性能的比较图
运行这个例子可以报告每个配置的平均分类精度。
注意:鉴于算法或评估程序的随机性,或数字精度的差异,你的结果可能会有所不同。考虑多运行几次这个例子,并比较平均结果。
在这个例子中,我们可以看到,C值为1.0的最佳得分约为77.7%,这与不使用惩罚达到相同的得分是一样的。
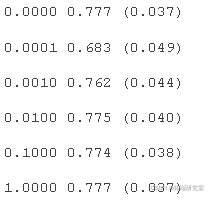
为每种配置的准确度分数创建了一个盒须图,所有的图都并排显示在一个相同比例的图上,以便直接比较。
在这种情况下,我们可以看到,我们在这个数据集上使用的惩罚越大(即C值越小),模型的性能就越差。
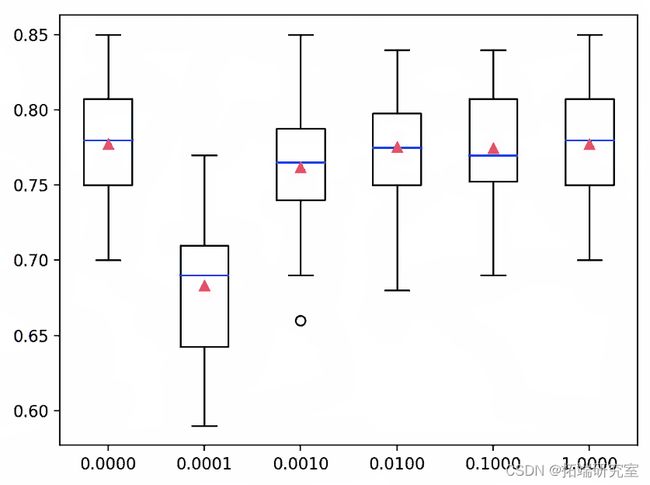
多项式Logistic回归的L2惩罚与准确率的箱线图
概括
在本教程中,您了解了如何在 Python 中开发多项逻辑回归模型。
你有任何问题吗?
在下面的评论中提出您的问题,我会尽力回答。

最受欢迎的见解
1.R语言多元Logistic逻辑回归 应用案例
2.面板平滑转移回归(PSTR)分析案例实现
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
4.R语言泊松Poisson回归模型分析案例
5.R语言混合效应逻辑回归Logistic模型分析肺癌
6.r语言中对LASSO回归,Ridge岭回归和Elastic Net模型实现
7.R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
8.python用线性回归预测股票价格
9.R语言用逻辑回归、决策树和随机森林对信贷数据集进行分类预测