00 一些前言
数字逻辑是计算机组成与体系结构的前导课,但是在两者的衔接之间并没有那么流畅,比如对面向硬件电路的设计思路缺乏。这篇总结是在数字逻辑和计组体系结构的衔接阶段进行的。
虽然这篇文是两门课的交接,也算是两个系列的一种过渡,但不代表我的数字逻辑部分就已经完成,这个系列后续会继续更新FPGA的小项目记录,以及阅读笔记等等。
本文主要是对于这个视频的笔记,我觉得很有用,加之此前我的实验报告由于课程关系不好直接往网上发,所以在这里整理一部分代码留作黑箱子。后续还会根据课程老师的要求对本文进行补充和优化:
从数字逻辑到计算机组成原理
01 前提准备
- 工具:仿真、综合工具的熟练Vivado和编辑器
- 面向硬件电路的设计思路
- 要学会造CPU,而不是只会背课本。所以我打算加入试点班。
02 回顾数字逻辑
02-1 数值表示 | 原码补码 | 逻辑门 | 布尔代数
- 数值和数制:
- 重点是二进制、十六进制;
- 数值的原码表示和补码表示:
- 有符号数和无符号数
- 加减溢出问题;
- 基本逻辑门:
- 与或非、NAND;
- 以及CMOS门电路;
- 布尔代数:
- 逻辑表达式;
- 真值表;
- 逻辑运算律;
- 卡诺图;
02-2 译码器等器件
这部分基本上涵盖了上学期数字逻辑的所有实验,所以是数字逻辑里比较重要的部分。
- n-2n译码器Decoder;
- 数据选择器MUX;
- 一位全加器,串行进位多位全加器;
- 锁存器和触发器;
- 传并行加载转换器等;
- 触发器的时序分析、延迟分析;
- 计数器;
- 移位寄存器;
- 状态机设计;
02-3 原理部分
- 组合逻辑电路和时序逻辑电路的原理
- 只读存储器ROM基本原理
- 随机存储器RAM基本原理
- 动态存储器DRAM基本原理
- 现场可编程门阵列FPGA基本原理
这部分我的数字逻辑课程是没有讲解的,但后续我会继续了解,毕竟是课程相关的东西。
03 主要过渡内容
03-1 Verilog
这是一个硬件语言,我此前也写过数字逻辑实践4->面向硬件电路的设计思维--FPGA设计总述,就是在描述Verilog与高级语言软件思路的不同。
03-1-1 怎么学
- 采用RTL(Register Transfer Level,寄存器传输级)设计;
- 使用限制的可综合子集
- 将自己实现的代码和参考代码对比思考
03-1-2 面向硬件电路的设计思路
- 谨记这不是在写代码,而是在设计电路(并行);
- 先进行(设想)电路结构设计,再进行Verilog代码编写;
- 遵循自顶向下、模块划分、逐层细化的设计步骤;
- 不要写一点、试一下、改一点、再试一下,这样效率很低;
⭐03-1-3 可综合代码Verilog(限制版)
在写CPU时,主要使用以下语法,其他的尽量不要使用:
- 模块声明module endmodule
- 端口声明input output inout
- 线网数据类型 wire
- 变量数据类型 reg,integer
- 参数常量 (parameter constants)
- 整型数 (literal integer numbers)
- 模块实例化
- 连续赋值语句assgin
- always结构化语句
- begin...end块
- 阻塞赋值=和非阻塞赋值<=
- 条件判断语句if,if...else,case
- for循环
- 组合逻辑敏感列表的 @*
- 多维数组(寄存器堆)
- generate表达式
03-1-4 代码风格建议(要求)
-
数据通路上的组合逻辑用assign写,禁止用always写;controller中可以用,datapath不可以。
-
用always写组合逻辑的时候,只允许出现在生成状态机的next state的时候,且该语句中只能出现阻塞赋值=;
-
写时序逻辑的时候,always语句中,只允许出现非阻塞赋值(<=);
-
寄存器堆封装成单独的模块,以实例化的方式使用;
-
case语句在任何情况下都要有default;
- 这一点在上一篇文章也提到过;保证了安全性和没实现指令的放置;
-
模块实例化时候的参数和端口只允许用名字相关的方式进行赋值和连接;
就是实例化的时候用名字对应的方式来确保实例化不会错位;
即这种方式
.clk(clk) -
数据通路的组合逻辑中,1bit的逻辑运算用&、|、~、^这类位运算符;
控制信号的组合逻辑中,1bit的逻辑运算用&& 、||、!这三个运算符。
-
运算优先级!
03-2 代码实例
为了在实操里有效注意到上面提到过的东西,针对我写过的实验类型,来看看更好的实现方式。
视频中提到的代码在[这里][step_into_mips/rtl_code at prepare · lvyufeng/step_into_mips (github.com)],也是下面规范代码的来源处,至于下面我的数字逻辑实验代码,对比之下,那没有价值。
03-2-1 模块调用和实例化
下面的代码没什么功能可言,但对于格式而言很标准,可以学习一下它的模块调用和实例化,我作了标注。
module top;
wire [15:0] btm_a;
wire [ 7:0] btm_b;
wire [ 3:0] btm_c;
wire [ 3:0] btm_y;
wire btm_z;
bottom #(
.A_WIDTH (16),
.B_WIDTH ( 7),
.Y_WIDTH ( 3)
)
//这里的参数可以调整就相当于全局变量,用一个变量存储常数。
inst_btm(
.a (btm_a), //I
.b (btm_b), //I
.c (btm_c), //I
.y (btm_y), //O
.z (btm_z) //O
);
//这里就是前面提到过的按名字来实例化变量
endmodule
module bottom #
(
parameter A_WIDTH = 8,
parameter B_WIDTH = 4,
parameter Y_WIDTH = 2
)
(
input wire [A_WIDTH-1:0] a,
input wire [B_WIDTH-1:0] b,
input wire [ 3:0] c,
output wire [Y_WIDTH-1:0] y,
output reg z
);
// internal logic
endmodule
03-2-2 基本逻辑门
下面提到的是32位的与或非、与非、或非、异或、同或,这是ALU(运算器)实现的基础。
module bit_logic(
input [31:0] a,
input [31:0] b,
output [31:0] y1,
output [31:0] y2,
output [31:0] y3,
output [31:0] y4,
output [31:0] y5,
output [31:0] y6,
output [31:0] y7
);
assign y1 = a & b; //与
assign y2 = a | b; //或
assign y3 = ~a; //非
assign y4 = ~(a & b); //与非
assign y5 = ~(a | b); //或非
assign y6 = a ^ b; //异或
assign y7 = a ~^ b; //同或
endmodule
03-2-3 译码器
当时我校实验二的任务有一个是2-4译码器,我当时的代码(.v文件)如下,使用always+case实现的:
module dec2to4(W,En,Y);
input[1:0]W;
input En;
output reg [0:3]Y;
always @(W,En)
case({En,W})
3'b100:Y = 4'b1000;
3'b101:Y = 4'b0100;
3'b110:Y = 4'b0010;
3'b111:Y = 4'b0001;
default: Y = 4'b0000;
endcase
endmodule
这时候回忆一下上面的内容,数据通路上的组合逻辑用assign写,禁止用always,看如下规范代码:
module decoder_4_16(
input [ 3:0] in,
output [16:0] out
);
// one-hot,独热编码
assign out[ 0] = (in == 3'd0 );
assign out[ 1] = (in == 3'd1 );
assign out[ 2] = (in == 3'd2 );
assign out[ 3] = (in == 3'd3 );
assign out[ 4] = (in == 3'd4 );
assign out[ 5] = (in == 3'd5 );
assign out[ 6] = (in == 3'd6 );
assign out[ 7] = (in == 3'd7 );
assign out[ 8] = (in == 3'd8 );
assign out[ 9] = (in == 3'd9 );
assign out[10] = (in == 3'd10);
assign out[11] = (in == 3'd11);
assign out[12] = (in == 3'd12);
assign out[13] = (in == 3'd13);
assign out[14] = (in == 3'd14);
assign out[15] = (in == 3'd15);
endmodule
但明显可以发现,上面的代码缺点在于重复结构,看起来很笨重,所以可以用generate来代替,准确来说这不是for循环,只是通过这种方式在编译器的层面自动生成了上面那么多重复的语句:
//另一个5-32译码器
//用generate语句改善编码效率
module decoder_5_32(
input [ 4:0] in,
output [31:0] out
);
genvar i;
generate for (i=0; i<32; i=i+1) begin : gen_for_dec_5_32
assign out[i] = (in == i);
end endgenerate
endmodule
//6-64译码器
module decoder_6_64(
input [ 5:0] in,
output [63:0] out
);
genvar i;
generate for (i=0; i<63; i=i+1) begin : gen_for_dec_6_64
assign out[i] = (in == i);
end endgenerate
endmodule
03-2-4 编码器
编码器当时学校任务是8-3编码器,我的代码如下,也是个case:
module enc8to3(x,y);
input [7:0]x;
output [2:0]y;
reg[2:0]y;
always@(x)
begin
case(x)
8'b00000001:y=3'b000;
//x=8 ’b00000001,y 输出为 3 ’b000
8'b00000010:y=3'b001;
//x=8 ’b00000010,y 输出为 3 ’b001
8'b00000100:y=3'b010;
//x=8 ’b00000100,y 输出为 3 ’b010
8'b00001000:y=3'b011;
//x=8 ’b00001000,y 输出为 3 ’b011
8'b00010000:y=3'b100;
//x=8 ’b00010000,y 输出为 3 ’b100
8'b00100000:y=3'b101;
//x=8 ’b00100000,y 输出为 3 ’b101
8'b01000000:y=3'b110;
//x=8 ’b01000000,y 输出为 3 ’b110
8'b10000000:y=3'b111;
//x=8·’b10000000,y 输出为 3 ’b111
default: y=3'b000;
endcase
end
endmodule
来看看好一点的规范代码:
module encoder_8_3(
input [7:0] in,
output [2:0] out
);
//独热
assign out = in[0] ? 3’d0 :
in[1] ? 3’d1 :
in[2] ? 3’d2 :
in[3] ? 3’d3 :
in[4] ? 3’d4 :
in[5] ? 3’d5 :
in[6] ? 3’d6 :
3’d7 ;
endmodule
//这其实是一个优先级编码器,是一层一层的else,所以最后的网格电路会比较慢
下面是一种更好的写法:
//保证设计输入in永远至多只有一个1
//即at-most-1-hot向量
module encoder_8_3(
input [7:0] in,
output [2:0] out
);
assign out = ({3{in[0]}} & 3’d0)
| ({3{in[1]}} & 3’d1)
| ({3{in[2]}} & 3’d2)
| ({3{in[3]}} & 3’d3)
| ({3{in[4]}} & 3’d4)
| ({3{in[5]}} & 3’d5)
| ({3{in[6]}} & 3’d6)
| ({3{in[7]}} & 3’d7);
endmodule
用逻辑运算符 | 使得所有的表达式并行,在电路上表示为同一级并行结构。下面可以看到这个语句与多路选择器其实也很相似。
03-2-4 多路选择器
当时我写的是:
module mux2to1(w0,w1,s,f);
input w0,w1,s;
output reg f;
//assign f = s ? w1 : w0;
//这不是可综合的代码,替换
//2022-3-12
//上面说错了,assign对于reg类型不可综合,wire还行,甚至在数据通路上这个组合逻辑模块应当使用assign。
always @(w0,w1,s)
f = s ? w1 : w0;
endmodule
再来看规范代码,与上面的编码器相同,给出了一个优先级代码(速度不那么快),和另一个并行代码(速度快):
module mux5_8b(
input [7:0] in0, in1, in2, in3, in4,
input [2:0] sel,
output [7:0] out
);
//优先级代码
assign out = (sel==3’d0) ? in0 :
(sel==3’d1) ? in1 :
(sel==3’d2) ? in2 :
(sel==3’d3) ? in3 :
(sel==3’d4) ? in4 :
8’b0;
endmodule
module mux5_8b(
input [7:0] in0, in1, in2, in3, in4,
input [2:0] sel,
output [7:0] out
);
//并行代码
assign out = ({8{sel==3’d0}} & in0)
| ({8{sel==3’d1}} & in1)
| ({8{sel==3’d2}} & in2)
| ({8{sel==3’d3}} & in3)
| ({8{sel==3’d4}} & in4);
endmodule
//不要忘了写{8{}}中的8,这是与in0等保持一致。
下面是一个特殊一点的多路选择器,实现五选一,这个五中的每一个都是一个位宽为8的数组。
module max5_1hot_8b(
input [7:0]in0, in1, in2, in3, in4,
input [4:0]sel_v,
output [7:0]out
);
assign out = ({8{sel_v[0]}} & in0)
|({8{sel_v[1]}} & in1)
|({8{sel_v[2]}} & in2)
|({8{sel_v[3]}} & in3)
|({8{sel_v[4]}} & in4);
endmodule
03-2-5 全加器 / 加法器
全加器事实上代码的操作空间不大,下面是我写的:
module twoadder(x,y,carryin,Sum,carryout);
parameter n = 2;
input [n-1:0]x,y;
input carryin;
output reg [n-1:0]Sum;
output reg carryout;
always @(x,y,carryin)
begin
{carryout,Sum} = x + y + carryin;
end
endmodule
这是参考代码:
module adder(
input [31:0] a,
input [31:0] b,
input cin,
output [31:0] s,
output cout
);
assign {cout, s} = a + b + cin;
endmodule
//基本一致
03-2-6 寄存器 / D触发器
这部分就是时序逻辑了,有好几个形态的Dflipflop:
-
最普通的上跳沿触发的D寄存器
module Dflipflop( input clk, input din, output reg q ); always @(posedge clk) begin q <= din; end endmodule -
带使能端的D寄存器,两种推荐写法:
//第一种:if module Dflipflop_en( input clk, input en, input din, output reg q ); always @(posedge clk) begin if (en) q <= din; end endmodule //第二种:三元运算 module Dflipflop_en( input clk, input en, input din, output reg q ); always @(posedge clk) begin q <= en ? din : q; end endmodule -
带复位的D寄存器,两种推荐写法:
。//写法1:if-else if
module Dflipflop_r(
input clk,
input rst,
input din,
output reg q
);
always @(posedge clk) begin
if (rst) q <= 1’b0;
else if (en) q <= din;
end
endmodule
//写法二:二重三元运算
module Dflipflop_r(
input clk,
input rst,
input din,
output reg q
);
always @(posedge clk) begin
q <= rst ? 1'b0 :
en ? din : q;
end
endmodule
-
以上两个寄存器都推荐使用if的实现方式,因为软件会对这种方式进行优化,对三元运算符的不会;
并且 if 的方式对于q优先级显示得较为清楚。
这里强调一个问题:
就是rst要不要放在posedge里,即:
always @(posedge clk, rst) begin
产生这个问题多半是因为课本上的代码,有些是上面实例代码的形式,有些是这个形式。这个问题也很简单,即记住要把时钟敏感的信号放在@里,非时钟敏感的就不放进去。
03-2-7 寄存器堆
这个实验我没有做过,基本就是实现一个指令集对应的寄存器数组。
module regfile(
input clk,
// READ PORT 1
input [ 4:0] raddr1,
output [31:0] rdata1,
// READ PORT 2
input [ 4:0] raddr2,
output [31:0] rdata2,
// WRITE PORT
input we,
//write enable, HIGH valid
input [ 4:0] waddr,
input [31:0] wdata
);
reg [31:0] rf[31:0];
//WRITE
always @(posedge clk) begin
if (we) rf[waddr]<= wdata;
end
//READ OUT 1
assign rdata1 = (raddr1==5'b0) ? 32'b0 : rf[raddr1];
//READ OUT 2
assign rdata2 = (raddr2==5'b0) ? 32'b0 : rf[raddr2];
//读的时候是一个组合逻辑,所以是we,而不是en
endmodule
下面还有一个写法,看起来很长,如果仔细看,下面读1和读2的操作都是并行的,具体实现的就是一个译码的操作,即将地址译为一个one-hot。这种写法是上面代码具体实现的样子。
//另一个写法
module regfile(
input clk,
// READ PORT 1
input [ 4:0] raddr1,
output [31:0] rdata1,
// READ PORT 2
input [ 4:0] raddr2,
output [31:0] rdata2,
// WRITE PORT
input we, //write enable, HIGH valid
input [ 4:0] waddr,
input [31:0] wdata
);
reg [31:0] rf[31:0];
wire [31:0] waddr_dec, raddr1_dec, raddr2_dec;
//WRITE
decoder_5_32 U0(.in(waddr ), .out(waddr_dec));
always @(posedge clk) begin
if (we & waddr_dec[ 0]) rf[ 0] <= wdata;
if (we & waddr_dec[ 1]) rf[ 1] <= wdata;
if (we & waddr_dec[ 2]) rf[ 2] <= wdata;
if (we & waddr_dec[ 3]) rf[ 3] <= wdata;
if (we & waddr_dec[ 4]) rf[ 4] <= wdata;
if (we & waddr_dec[ 5]) rf[ 5] <= wdata;
if (we & waddr_dec[ 6]) rf[ 6] <= wdata;
if (we & waddr_dec[ 7]) rf[ 7] <= wdata;
if (we & waddr_dec[ 8]) rf[ 8] <= wdata;
if (we & waddr_dec[ 9]) rf[ 9] <= wdata;
if (we & waddr_dec[10]) rf[10] <= wdata;
if (we & waddr_dec[11]) rf[11] <= wdata;
if (we & waddr_dec[12]) rf[12] <= wdata;
if (we & waddr_dec[13]) rf[13] <= wdata;
if (we & waddr_dec[14]) rf[14] <= wdata;
if (we & waddr_dec[15]) rf[15] <= wdata;
if (we & waddr_dec[16]) rf[16] <= wdata;
if (we & waddr_dec[17]) rf[17] <= wdata;
if (we & waddr_dec[18]) rf[18] <= wdata;
if (we & waddr_dec[19]) rf[19] <= wdata;
if (we & waddr_dec[20]) rf[20] <= wdata;
if (we & waddr_dec[21]) rf[21] <= wdata;
if (we & waddr_dec[22]) rf[22] <= wdata;
if (we & waddr_dec[23]) rf[23] <= wdata;
if (we & waddr_dec[24]) rf[24] <= wdata;
if (we & waddr_dec[25]) rf[25] <= wdata;
if (we & waddr_dec[26]) rf[26] <= wdata;
if (we & waddr_dec[27]) rf[27] <= wdata;
if (we & waddr_dec[28]) rf[28] <= wdata;
if (we & waddr_dec[29]) rf[29] <= wdata;
if (we & waddr_dec[30]) rf[30] <= wdata;
if (we & waddr_dec[31]) rf[31] <= wdata;
end
//READ OUT 1
decoder_5_32 U1(.in(raddr1), .out(raddr1_dec));
assign rdata1 = ({32{raddr1_dec[ 1]}} & rf[ 1]) //NOTE: we omit No. 0 entry because GR[0] always be zero.
| ({32{raddr1_dec[ 2]}} & rf[ 2])
| ({32{raddr1_dec[ 3]}} & rf[ 3])
| ({32{raddr1_dec[ 4]}} & rf[ 4])
| ({32{raddr1_dec[ 5]}} & rf[ 5])
| ({32{raddr1_dec[ 6]}} & rf[ 6])
| ({32{raddr1_dec[ 7]}} & rf[ 7])
| ({32{raddr1_dec[ 8]}} & rf[ 8])
| ({32{raddr1_dec[ 9]}} & rf[ 9])
| ({32{raddr1_dec[10]}} & rf[10])
| ({32{raddr1_dec[11]}} & rf[11])
| ({32{raddr1_dec[12]}} & rf[12])
| ({32{raddr1_dec[13]}} & rf[13])
| ({32{raddr1_dec[14]}} & rf[14])
| ({32{raddr1_dec[15]}} & rf[15])
| ({32{raddr1_dec[16]}} & rf[16])
| ({32{raddr1_dec[17]}} & rf[17])
| ({32{raddr1_dec[18]}} & rf[18])
| ({32{raddr1_dec[19]}} & rf[19])
| ({32{raddr1_dec[20]}} & rf[20])
| ({32{raddr1_dec[21]}} & rf[21])
| ({32{raddr1_dec[22]}} & rf[22])
| ({32{raddr1_dec[23]}} & rf[23])
| ({32{raddr1_dec[24]}} & rf[24])
| ({32{raddr1_dec[25]}} & rf[25])
| ({32{raddr1_dec[26]}} & rf[26])
| ({32{raddr1_dec[27]}} & rf[27])
| ({32{raddr1_dec[28]}} & rf[28])
| ({32{raddr1_dec[29]}} & rf[29])
| ({32{raddr1_dec[30]}} & rf[30])
| ({32{raddr1_dec[31]}} & rf[31]);
//READ OUT 2
decoder_5_32 U2(.in(raddr2), .out(raddr2_dec));
assign rdata2 = ({32{raddr2_dec[ 1]}} & rf[ 1])
| ({32{raddr2_dec[ 2]}} & rf[ 2])
| ({32{raddr2_dec[ 3]}} & rf[ 3])
| ({32{raddr2_dec[ 4]}} & rf[ 4])
| ({32{raddr2_dec[ 5]}} & rf[ 5])
| ({32{raddr2_dec[ 6]}} & rf[ 6])
| ({32{raddr2_dec[ 7]}} & rf[ 7])
| ({32{raddr2_dec[ 8]}} & rf[ 8])
| ({32{raddr2_dec[ 9]}} & rf[ 9])
| ({32{raddr2_dec[10]}} & rf[10])
| ({32{raddr2_dec[11]}} & rf[11])
| ({32{raddr2_dec[12]}} & rf[12])
| ({32{raddr2_dec[13]}} & rf[13])
| ({32{raddr2_dec[14]}} & rf[14])
| ({32{raddr2_dec[15]}} & rf[15])
| ({32{raddr2_dec[16]}} & rf[16])
| ({32{raddr2_dec[17]}} & rf[17])
| ({32{raddr2_dec[18]}} & rf[18])
| ({32{raddr2_dec[19]}} & rf[19])
| ({32{raddr2_dec[20]}} & rf[20])
| ({32{raddr2_dec[21]}} & rf[21])
| ({32{raddr2_dec[22]}} & rf[22])
| ({32{raddr2_dec[23]}} & rf[23])
| ({32{raddr2_dec[24]}} & rf[24])
| ({32{raddr2_dec[25]}} & rf[25])
| ({32{raddr2_dec[26]}} & rf[26])
| ({32{raddr2_dec[27]}} & rf[27])
| ({32{raddr2_dec[28]}} & rf[28])
| ({32{raddr2_dec[29]}} & rf[29])
| ({32{raddr2_dec[30]}} & rf[30])
| ({32{raddr2_dec[31]}} & rf[31]);
endmodule
04 设计基本流程 | 注意事项
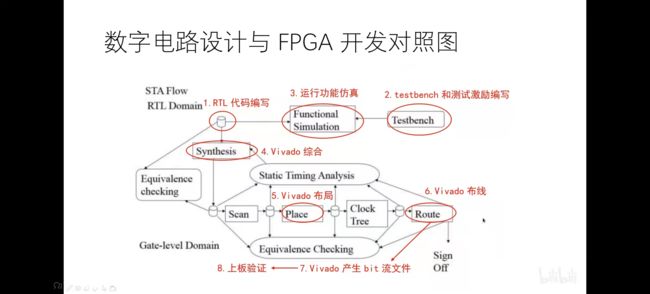
基本如上图所示,我们需要:
- CPU结构图
- RTL代码编写(即上面各种箱子)
- 功能仿真,vivado里的Functional Simulation;必须先进行此步再综合;仿真不正确不要向后做;
- 测试代码testbench,cpu检验时老师会给
- 综合;
- Vivado布局布线;
- 验证;
05 结语
05-1 课外书籍推荐
书不一定要是纸质书,看不一定是一页一页看,但这些书确实挺好:
-
《verilog数字系统设计教程》夏宇闻
查一些基本语法;
-
《自己动手写CPU》雷思磊
快速做出来CPU;
-
《数字设计与计算机体系结构》戴维·莫尼·哈里斯
MIPS-FPGA的鼻祖;
读者如果需要的话,可以联系我,我找到了一些资源。
05-2 安排
我想我会在下一篇会讲解(记录)vivado下载安装使用以及第三方编辑器的调配。