NLP之Transformer

总体来看,Transformer这个模型架构还是遵循着Encoder-Decoder的格式。此外,Transformer由注意力机制模块组成,因此在学习Transformer之前有必要对注意力机制有个了解(点这里)。
参考文档:
①Transformer模型的PyTorch实现
②Transformer 模型详解
③Transformer原理解读
③《Attention is All You Need》浅读(简介+代码)
Transformer
- 1 Transformer结构
-
- 1.1Self-attention
- 1.2 Scaled dot-product attention
- 1.3 Multi-head self-attention
- 1.4 Residual connection
- 1.5 Positional Encoding
- 1.6 Layer Normalization
- 1.7 Masking
-
- 1.7.1 Padding Mask
- 1.7.2 Sequence Mask
- 1.8 Position-wise Feed-Forward Networks
- 1.9 Linear&Softmax层
- 2 总结
-
- 2.1 Transformer模型
- 2.2 Transformer流程
1 Transformer结构
对注意力机制就有初步了解之后,就可以进行Transformer的学习了!
1.1Self-attention
Self-attention,又称自注意力,内部注意力,谷歌的这篇Transformer全是self-attention。自注意力就是 A t e n t i o n ( X , X , X ) Atention(X,X,X) Atention(X,X,X),即在序列内部做注意力,寻找序列内部的联系(从Transformer的成功来看self-attention在NLP上还是很有作用的)。
与self-attention相对的是Context-attention,即发生在Encoder和Decoder之间的注意力,比如之前关于Seq2Seq中引入的注意力机制就是Context-attention。
Note:
- 之前的注意力机制中,涉及两个隐藏状态,分别是Encoder端和Decoder端的 h t h_t ht,即输入序列某个位置的隐藏状态和输出序列某个位置的隐藏状态。而self-attention就是说输出序列就是输入序列,计算自己的attention分数。
1.2 Scaled dot-product attention

在Transformer论文中,注意力函数选择的是缩放乘性注意力——Scaled Dot-Product,其表达式为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V . Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V. Attention(Q,K,V)=softmax(dkQKT)V.
Note:
- d k d_k dk表示 K K K矩阵的维度。
- 缩放因子 1 d k \frac{1}{\sqrt{d_k}} dk1是为了防止分子乘积太大的话,使得结果处于softmax函数梯度很小的地方,造成梯度消失,故缩减因子可以一定程度上减缓它。
- 这个注意力分数 A t t e n t i o n ( Q , K , V ) Attention(Q,K,V) Attention(Q,K,V)相当于是对 V V V的加权平均,而权重是通过 Q Q Q和 K K K之间的运算所得。
- Q Q Q和 K K K的计算表示如下:
 最后的运算结果 Q K T QK^T QKT可以表示为词与词之间的关系。
最后的运算结果 Q K T QK^T QKT可以表示为词与词之间的关系。
论文中也给出了相关的图:

Q 、 K 、 V Q、K、V Q、K、V是什么?

Note:
- W Q 、 W K 、 W V W^Q、W^K、W^V WQ、WK、WV是线性变换矩阵。
- X 、 Q 、 K 、 V X、Q、K、V X、Q、K、V的每一行都表示一个Word。
Self-attention:
- 对于Encoder部分的第一层,矩阵X是输入通过Embeding和Positional encoding相加的结果,其余层都来自于上一层的输出。
- 对于Decoder部分的第一层。矩阵X是输出通过Embeding和Positional encoding相加的结果,其余层都来自于上一层的输出。
Encoder-Decoder-attention:
Q Q Q来自于Decoder上一层的输出, K 、 V K、V K、V来自于Encoder的输出,即编码信息矩阵C:
。
Note:
- Q 、 K 、 V Q、K、V Q、K、V三者的维度是一样的。
1.3 Multi-head self-attention

如果说上面的scaled dot-product attention 是一个人在观察输入,那么Multi-head就是多个人站在不同角度去观察输入,并且不同人所得到的注意力是不同的。
之后 Q 、 K 、 V Q、K、V Q、K、V通过线性映射分成 h h h份,对每一份使用scaled dot-product attention模块,最后将多个注意力聚合起来,再通过全连接层输出。
Note:
- Multi-head attention就相当于聚集了所有人对输入不同的观察力理解,它比单个注意力对输入的理解更加全面。
Multi-head attention公式如下:
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , ⋯ , h e a d h ) ⋅ W O , 其 中 , h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) MultiHead(Q,K,V) = Concat(head_1,\cdots,head_h)\cdot W^O,\\ 其中,head_i = Attention(QW_i^Q,KW^K_i,VW^V_i) MultiHead(Q,K,V)=Concat(head1,⋯,headh)⋅WO,其中,headi=Attention(QWiQ,KWiK,VWiV)
Note:
- W i Q ∈ R d m o d e l × d k , W i K ∈ R d m o d e l × d k , W i V ∈ R d m o d e l × d v , W O ∈ R h d v × d m o d e l W_i^Q \in\mathbb{R}^{d_{model}\times d_k},W_i^K \in\mathbb{R}^{d_{model}\times d_k},W_i^V \in\mathbb{R}^{d_{model}\times d_v},W^O\in \mathbb{R}^{hd_v\times d_{model}} WiQ∈Rdmodel×dk,WiK∈Rdmodel×dk,WiV∈Rdmodel×dv,WO∈Rhdv×dmodel.
- 论文中 h = 8 h=8 h=8, d k = d v = d m o d e l / h = 64 d_k=d_v=d_{model}/h = 64 dk=dv=dmodel/h=64。也就是说最后输入的scaled dot-product attention的向量维度是64。
- 无论是Encoder还是Decoder,经过Multi-head attention模块之后的输出和输入矩阵是想同维度的。
1.4 Residual connection

Transformer结构中存在着残差连接,这起源于何凯明残差网络,残差网络是用于解决网络深度太大导致梯度回传消失的问题,具体的可以参考另一篇中关于残差网络部分。
1.5 Positional Encoding
到目前为止我们发现Transformer似乎没有表达序列位置信息的能力,要知道序列次序信息在NLP中是十分重要的,之前RNN结构可以天然利用次序信息,可放到Transformer里似乎没有办法了,那怎么办呢?
——Positional Encoding
谷歌在文章中又引入了位置编码,positional encoding来缓解Transformer的硬伤——无法对位置信息很好的建模。
具体地,谷歌采用正弦和余弦来编码位置信息:
P E ( p o s , i ) = { s i n ( p o s 1000 0 i / d m o d e l ) i f n i s e v e n , c o s ( p o s 1000 0 ( i − 1 ) / d m o d e l ) i f n i s o d d . PE_{(pos,i)} = \begin{cases} sin(\frac{pos}{10000^{i/d_{model}}}) & if\ n\ is\ even,\\ cos(\frac{pos}{10000^{(i-1)/d_{model}}}) &if\ n\ is\ odd. \end{cases} PE(pos,i)={sin(10000i/dmodelpos)cos(10000(i−1)/dmodelpos)if n is even,if n is odd.其中, p o s pos pos是位置序号, i i i是维度,当 i i i是偶数地时候,那一维采用 s i n sin sin编码,否则就采用 c o s cos cos编码。
Note:
- d m o d e l d_{model} dmodel是位置向量的最大长度,和word embeding最大长度保持一致,便于相加。
- 采用正弦余弦编码的原因是,其可以表示不同位置之间的相对关系,因为三角函数存在一种关系: s i n ( α + β ) = s i n α c o s β + c o s α s i n β c o s ( α + β ) = c o s α c o s β − s i n α s i n β sin(\alpha+\beta)=sin\alpha cos\beta + cos\alpha sin\beta\\cos(\alpha+\beta) = cos\alpha cos\beta - sin\alpha sin\beta sin(α+β)=sinαcosβ+cosαsinβcos(α+β)=cosαcosβ−sinαsinβ也就是说,对于词汇之间的位置偏移 k k k, P E ( p o s + k ) PE(pos+k) PE(pos+k)可以表示成 P E ( p o s ) PE(pos) PE(pos)和 P E ( k ) PE(k) PE(k)组合的形式,这样的话位置向量就有了表达相对位置的能力。
1.6 Layer Normalization
不同于BN,Layer Normalization做的是层归一化,即对某一层的所有神经元输入进行归一化,或者说每 h i d d e n _ s i z e hidden\_size hidden_size个数求平均/方差。它在training和inference时没有区别,只需要对当前隐藏层计算mean and variance就行。不需要保存每层的moving average mean and variance,此外,其增加了gain和bias作为学习的参数。
Pytorch已经有相关实现:nn.LayerNorm
1.7 Masking
Transformer也需要用到掩码技术(Masking)去对某些值进行掩盖,使其不产生效果。
有2种模式,一种是Padding Mask,其在所有的Scaled Dot-Product Attention里都需要用到;另一种是Sequence Mask,其只在Decoder的Self Attention里用到。
1.7.1 Padding Mask
由于序列的长短不一,因此为了对齐,需要对较短的序列进行填充。在注意力机制中,我们会在缺省的位子上加上一个很大的负数,这样在注意力机制的softmax步骤中就会使得这些位子的注意力权重为0,使得我们的注意力不会放在这些位子上。
相对的Mask张量中,对于需填充位置为False,否则为True。
1.7.2 Sequence Mask
在RNN为原型的Seq2Seq中,我们在t时刻是看不到未来时刻的标签的,但这在Transformer中会出问题,为了让Decoder在解码过程中不会使标签过早的提前暴露,需要对输入进行一些mask。
Masking矩阵是一个和上三角值全为负无穷,下三角全为1的矩阵:

Sequence Mask需要在softmax运算之前使用:
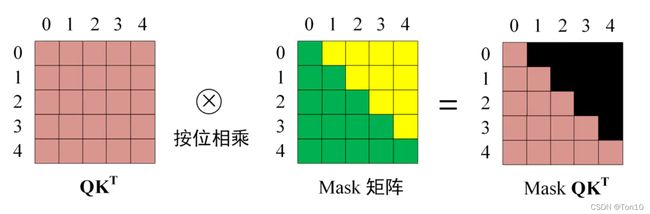
掩码之后对每一行进行softmax,可以从上图看出,在预测第0个单词的时候,单词0对单词1、2、3、4的注意力全为0。
1.8 Position-wise Feed-Forward Networks
Transformer的模型结构中会有Position-wise Feed-Forward Networks的存在,这是一个两层全连接层中间接一个RELU非线性层构造而出的,表达式为:
F F N ( x ) = m a x ( 0 , x ⋅ W 1 + b 1 ) ⋅ W 2 + b 2 . FFN(x) = max(0, x\cdot W_1+b_1)\cdot W_2 + b_2. FFN(x)=max(0,x⋅W1+b1)⋅W2+b2.
实际中使用一个 1 × 1 1\times1 1×1的卷积层来代替全连接层。输入输出维度均为512,中间层的维度为2048.具体设置如下:

1.9 Linear&Softmax层

在解码端,输出的注意力矩阵和输入矩阵是想同维度的,Transformer通过一个全连接层将输出进一步映射成(输入维度,词汇表)的格式,然后通过softmax对每一行进行处理,使得每一行概率和为1,每一行最大概率对应的词就是所预测的词。
2 总结
2.1 Transformer模型
下面总结下Transformer整个模型:
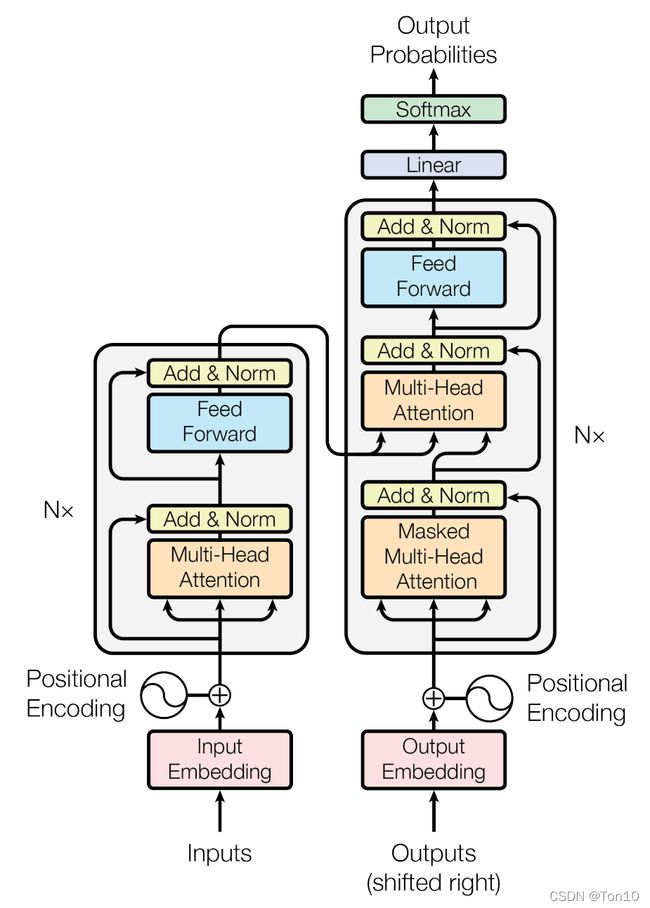
Encoder部分:
- 输入由词向量和位置编码向量相加组成。
- 由 N = 6 N=6 N=6个相同模块串联而成,每个模块由2个子层组成,分别是Multi-Head Attention层(采用自注意力机制),其输出的矩阵和输入矩阵想同纬度;此外还有Feed-Forward层,并且每个层都连接一个LayerNorm层。整个模块由残差结构相连。
- 输出是一个编码矩阵C,是给Decoder用的,它和输入矩阵的相同维度的。
Decoder部分:
- 输入由词向量和位置编码向量相加组成。
- 由 N = 6 N=6 N=6个相同模块串联而成,每个模块由3个子层组成,第一个子层是Masked Multi-Head Attention(采用自注意力机制),其引入了Sequence masking;第二个子层是Multi-Head Attention,和上述不同,它采用的是Context Attention,其 K 、 V K、V K、V来自于Encoder输出的编码信息矩阵C,这样做的好处在于每一位单词都可以利用到Encoder所有单词的信息;第三个子层是Feed-Forward层,每个层都连接一个LayerNorm层,并且都是残差结构。
- 输出的注意力矩阵经过线性层和Softmax层输出一个概率。
2.2 Transformer流程
了解整个模型之后,我们再结合图示和具体例子对整体流程有个更深一步的了解,详见Transformer流程详解,这是网上一个博主写的,很清晰详细,点赞!!!