记录一次 mmclassification 自定义数据训练和推理
总体参考如下(还有其他CSDN和知乎贴子):
欢迎来到 MMClassification 中文教程! — MMClassification 0.21.0 文档
mmclassification/getting_started.md at master · open-mmlab/mmclassification · GitHub
1. 环境安装
除了安装基础的python,pytorch等,重点是mmcv和mmcls!
由于要用到开发场景,不要用pip安装封装好的包,用官方建议(官方install那一步也有讲):
pip install openmim
mim install -e .
2. 代码
直接clone的mmlab官方源码:
GitHub - open-mmlab/mmclassification at dev https://github.com/open-mmlab/mmclassification/tree/dev
https://github.com/open-mmlab/mmclassification/tree/dev
3. 数据集
自己数据集有个文件夹,假设我是猫狗数据集dogs_cats,下边有如下几个文件夹:

以猫狗数据集为例,其中假设你已经在train、test和val三个文件夹中放好了图片了(注意看我红线部分,他们三个里边都分别有两个文件夹,分别是class1和class2, class2装的猫图片)。

meta中应该有如下几个文件:
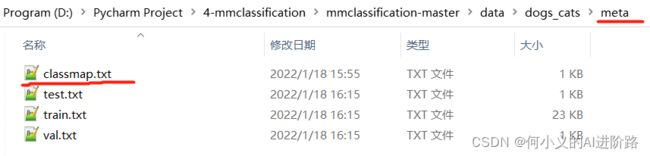
其中先看classmap.txt,其中内容写好类名和他的类代号:

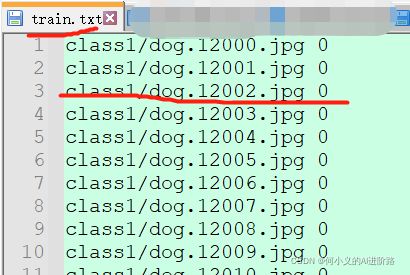
train.txt,test.txt, val.txt用一个脚本 data_deal.py 生成,运行完了,他们内容下边这样:
至于 data_deal.py, 脚本参考:
# -*- coding:utf8 -*-
import os
import glob
import re
'''
生成train.txt val.txt test.txt
'''
# 需要改为您自己的路径
root_dir = "/xxx/data/cats_dogs"
# 在该路径下有train val test meta三个文件夹
train_dir = os.path.join(root_dir, "train")
val_dir = os.path.join(root_dir, "val")
test_dir = os.path.join(root_dir, "test")
meta_dir = os.path.join(root_dir, "meta")
def generate_txt(images_dir,map_dict):
# 读取所有文件名
imgs_dirs = glob.glob(images_dir+"/*/*")
imgs_dirs = [ii.replace('\\', '/') for ii in imgs_dirs]
images_dir = images_dir.replace('\\', '/')
typename = images_dir.split("/")[-1]
target_txt_path = os.path.join(meta_dir, typename+".txt")
f = open(target_txt_path, "w")
# 遍历所有图片名
for img_dir in imgs_dirs:
# 获取第一级目录名称
filename = img_dir.split("/")[-2]
num = map_dict[filename]
# 写入文件
relate_name = re.findall(typename+"/([\w / - .]*)",img_dir)
f.write(relate_name[0]+" "+num+"\n")
def get_map_dict():
# 读取所有类别映射关系
class_map_dict = {}
with open(os.path.join(meta_dir, "classmap.txt"),"r") as F:
lines = F.readlines()
for line in lines:
line = line.split("\n")[0]
filename, cls, num = line.split(" ")
class_map_dict[filename] = num
return class_map_dict
if __name__ == '__main__':
class_map_dict = get_map_dict()
generate_txt(images_dir=train_dir, map_dict=class_map_dict)
generate_txt(images_dir=val_dir, map_dict=class_map_dict)
generate_txt(images_dir=test_dir, map_dict=class_map_dict)
4. 配置文件
注:以下描述的路径均在项目根目录的基础路径下!
(1)新建 mmcls\datasets\a_mydataset.py ,自己数据集的定义脚本
(主要是CLASSES = ["dog", "cat"]这一句):
# -*- coding:utf8 -*-
import numpy as np
from .builder import DATASETS
from .base_dataset import BaseDataset
@DATASETS.register_module()
class MyDataset(BaseDataset):
CLASSES = ["dog", "cat"]
def load_annotations(self):
assert isinstance(self.ann_file, str)
data_infos = []
with open(self.ann_file) as f:
samples = [x.strip().split(' ') for x in f.readlines()]
for filename, gt_label in samples:
info = {'img_prefix': self.data_prefix}
info['img_info'] = {'filename': filename}
info['gt_label'] = np.array(gt_label, dtype=np.int64)
data_infos.append(info)
return data_infos(2)mmcls\datasets\__init__.py 需要对自己的数据在init里添加,进行注册:
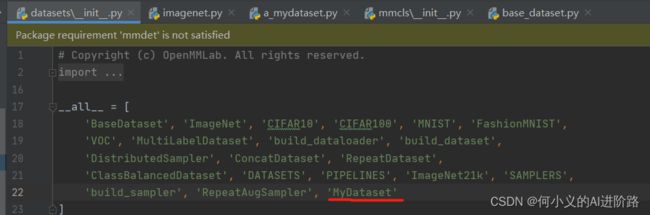
(3)新建 config/_base_/datasets/a_mydataset.py (主要参考 imagenet_bs32.py 对应改为自己的数据路径)
# dataset settings
dataset_type = 'MyDataset'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True) # coco数据训练时原始的预处理方式
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='RandomResizedCrop', size=224), # 随机缩放裁剪
dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'), # 随机翻转
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='ToTensor', keys=['gt_label']),
dict(type='Collect', keys=['img', 'gt_label']) # 图像和标签的集合
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', size=(256, -1)),
dict(type='CenterCrop', crop_size=224),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]
data_root = '/xxx/data/dogs_cats' # 你的数据集根目录
data = dict(
samples_per_gpu=5, # dataloader.batch_size == self.samples_per_gpu # 每批次样本数量
workers_per_gpu=2, # dataloader.num_workers == self.workers_per_gpu # 1的话表示只有一个进程加载数据
train=dict(
type=dataset_type,
data_prefix=data_root + '/train',
ann_file=data_root + '/meta/train.txt',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_prefix=data_root + '/val',
ann_file=data_root + '/meta/val.txt',
pipeline=test_pipeline),
test=dict(
# replace `data/val` with `data/test` for standard test
type=dataset_type,
data_prefix=data_root + '/val',
ann_file=data_root + '/meta/val.txt',
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='accuracy') # 分类,用accuracy(4)新建 config/_base_/model/a_resnet18_mydataset.py, 主要是参考resnet18.py
(网络的设置:注意是head里边的num_classes设置成自己的类别数量)
# model settings
model = dict(
type='ImageClassifier',
backbone=dict( # backbone: RES-NET
type='ResNet',
depth=18, # resnet18
num_stages=4, # resnet18 --- block-depth分别是(2,2,2,2)
out_indices=(3, ), # 取第三阶段,也就是最后一阶段的输出,resnet最后输出特征纬度是512
style='pytorch',
# torchvision默认预训练模型,这里默认下载放到/home/yons/.cache/torch/hub/checkpoints
# init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet18'),
# 预训练模型也可以用官方应用imagenet训练好的
# https://github.com/open-mmlab/mmclassification/blob/dev/docs/en/model_zoo.md 可下载checkpoint和查看更多,这里下载对应 resnet18_8xb32_in1k.py 的预训练设置
init_cfg=dict(
type='Pretrained',
checkpoint='/xxx/checkpoints/'resnet18_batch256_imagenet_20200708-34ab8f90.pth',
prefix='backbone',
),
frozen_stages=2, # 加入预训练模型时候,冻结前两层(实验证明,冻结部分权重,效果更好)
),
neck=dict(type='GlobalAveragePooling'), # neck:平均池化
head=dict(
type='LinearClsHead',
num_classes=2, # 二分类(因为是猫狗数据集了,不是imagenet)
in_channels=512,
loss=dict(type='CrossEntropyLoss', loss_weight=1.0), # 分类,交叉熵
topk=(1, 5),
# topk=(1, 2) # so you would have to check output.shape and make sure dim1 is larger or equal to maxk.
)
)
(5)新建 config/_base_/schedules/a_imagenet_bs256.py,
或者直接用imagenet_bs256.py, 定义优化器,学习率,和迭代次数等等。
# optimizer
optimizer = dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001) # momentum:学习率动量 weight_decay:权重惩罚,正则化
optimizer_config = dict(grad_clip=None) # 设置梯度截断(裁剪)阈值,防止梯度无限大爆炸
# learning policy
lr_config = dict(policy='step', step=[30, 60, 90]) # 100次迭代,每隔设定的这几次,lr就降低0.1倍
runner = dict(type='EpochBasedRunner', max_epochs=100)
(6) config/_base_/default_runtime.py, 设置多少批次打印日志,多少次迭代保存一次模型等等。
# checkpoint saving
checkpoint_config = dict(interval=20) # 多少次迭代保存一次模型
# yapf:disable
log_config = dict(
# interval=100,
interval=40, # 多少批次 打印一次
hooks=[
dict(type='TextLoggerHook'),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
(7) 新建 config/resnet/a_resnet18_b32x8_mydataset.py (这里就是模型配置主脚本了,借鉴resnet18_b32x8_imagenet的训练配置,按照如下顺序定义自己的配置文件。
# b32指的batch-size,8指gpu
_base_ = [
'../_base_/models/a_resnet18_mydataset.py', # model config
'../_base_/datasets/a_mydataset.py', # data config
'../_base_/schedules/a_imagenet_bs256.py', # schedules config
'../_base_/default_runtime.py' # runtime config
]5. 训练
tools/train.py 中修改config和work-dir ,然后运行:python tools/train.py

训练完了过后,不出意外的话,训练结果会保存到设定的train_result/0310下(这个可以自己随便设置):

6. 推理验证
(1)一张图评估, 就新建 test_one.py 用下边:
# Copyright (c) OpenMMLab. All rights reserved.
from argparse import ArgumentParser
import argparse
from mmcls.apis import inference_model, init_model, show_result_pyplot
def main():
# ### 测试的args,用于debug ###################
args = argparse.Namespace()
# == 本地 ===========
args.img = r'\xxx\dogs_cats\val\class2\cat.5658.jpg'
args.config = 'configs/resnet/a_resnet18_b32x8_mydataset.py'
args.checkpoint = 'train_result/0310/epoch_100.pth'
args.device = 'cpu'
# build the model from a config file and a checkpoint file
model = init_model(args.config, args.checkpoint, device=args.device)
# test a single image
result = inference_model(model, args.img)
# show the results
show_result_pyplot(model, args.img, result)
if __name__ == '__main__':
main()
效果还不错!

(2)对val.txt集中测试, 参考tools/test.py, 只需要对应改一下,再 python tools/test.py 即可!

7. 小结
(1) 环境一定要装好,mmcls要安装开发版的,不是应用版的;
(2)关于数据可以用你自己的,我网上下载的猫狗二分类图片;
(3)所有步骤,一环扣一环,不可忽略了;
(3)有问题可以到mmlab的官方论坛知乎,或者github中查看,没问题的,加油!奥利给~