js逆向工具-初学AST解混淆
目录
-
-
-
- 一、AST简单了解
- 二、babel环境安装
- 三、快速入门例子
-
- 1、入门例子讲解:修改变量值
- 2、入门案例代码:修改变量值
- 四、实际案例1-ob混淆之ast还原
-
- 1、数组 + 移位自执行函数 + 解密字符串函数 还原
- 2、定义的对象Object有规律的key和value 还原
- 3、while + switch控制流平坦化
-
-
一、AST简单了解
- 以下文章简单了解下,可以通过案例熟悉再回头再来看这些文章
- babel手册1、babel手册2
- 13个示例快速入门JS抽象语法树
- ast的概念和babel这一工具的具体使用
- 可视化显示AST结构工具

ast的作用:ast作用主要是将混淆的难读的js还原成可读性高的js,对整个js的逻辑不做任何改变,你可以理解为化繁为简,可见性的瘦身,也许网页上是1w多行的混淆代码,瘦身后只有不到1千行;脱混淆后要注意替换到网页试试看能否能用处理逻辑:就是一颗树,不停的找分支,确定当前分支的各个属性特性,即定位要改的节点就是找type,然后对该type节点操作即可,你可以简单理解为html里面找到了父标签然后对子标签进行操作,理解为xpath或者css选择器的逻辑也不为过十分要注意的:每次还原逻辑的时候,都要保证当前代码是可以正常运行的,然后再进行下一步还原逻辑
二、babel环境安装
- node安装:node环境安装
- babel相关包安装:在cmd窗口下执行如下命令
npm install -g @babel/core npm install -g @babel/parser npm install -g @babel/template npm install -g @babel/traverse npm install -g @babel/types npm install -g @babel/generator
三、快速入门例子
1、入门例子讲解:修改变量值
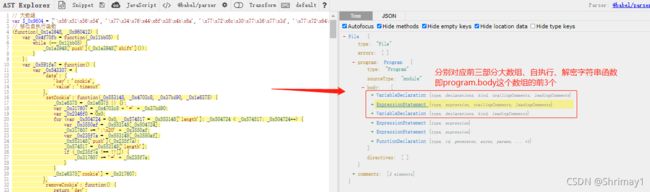
- 分为三部分:引入原js文件,ast操作节点还原逻辑,还原后的js文件存储
- 首先打开可视化显示AST结构工具,查看原js文件结构,我们这里
只需要关注type节点是什么,以及你想操作的结果在哪个节点下

- 比如我这里想把原js文件
var a = 1通过ast操作变成var a = "shirmay",那对应的type节点VariableDeclarator,要修改的是该节点的init键 - 对应代码脚本,其中t.stringLiteral(“shirmay”)即要赋的值
var traverses_1 = { VariableDeclarator(path) { var cur_node = path.node; // console.log(cur_node.id.name); // console.log(cur_node.init.value); cur_node.init = t.stringLiteral("shirmay"); // 修改变量值 } } - 最终完整的ast操作js修改变量值的脚本,完整代码在下面案例1,各个代码注释已经在图片中标注,
后续我们只需要修改traverses还原逻辑即可,其它基本就是个固定框架

2、入门案例代码:修改变量值
- 把原js文件
var a = 1通过ast操作变成var a = "shirmay" - 原js文件:demo_1.js
var a = 1; - ast还原文件:ast_demo_1.js
// 将JS源码转换成语法树 var parser = require("@babel/parser"); // 为parser提供模板引擎 var template = require("@babel/template").default; // 遍历AST树节点 var traverse = require("@babel/traverse").default; // 操作节点,比如判断节点类型,生成新的节点等 var t = require("@babel/types"); // 将语法树转换为源代码 var generator = require("@babel/generator").default; // 1、读取原始文件 var fs = require("fs"); var jscode = fs.readFileSync("demo_1.js", {encoding: "utf-8"}); console.log("原js文件内容:", jscode); // 2、对原始文件进行操作,使用traverse遍历语法树,因为变量定义为VariableDeclarator类型,所以我们只对type为VariableDeclarator的节点进行处理 var ast = parser.parse(jscode); var traverses_1 = { VariableDeclarator(path) { var cur_node = path.node; // console.log(cur_node.id.name); // console.log(cur_node.init.value); cur_node.init = t.stringLiteral("shirmay"); // 修改变量值 } } traverse(ast, traverses_1) // 3、生成还原后的js文件 var ast_js_code = generator(ast); console.log("ast操作后的js文件内容:", ast_js_code.code)
四、实际案例1-ob混淆之ast还原
- ob混淆分为以下几个步骤:
- ①【数组 + 移位自执行函数 + 解密字符串函数】还原
- ②【定义的对象Object,有规律的key和value】还原
- ③【while + switch 组合控制流平坦化】还原
- 分为三部分:引入原js文件,ast操作节点还原逻辑,还原后的js文件存储,通用的代码结构如下,我们每次需要该段就是还原逻辑的处理traverses_1、traverses_2、traverses_3等…
// 通用的引用模块 var parser = require("@babel/parser"); // 将JS源码转换成语法树AST var template = require("@babel/template").default; // 为parser提供模板引擎 var traverse = require("@babel/traverse").default; // 遍历AST树节点操作 var types = require("@babel/types"); // 操作节点,比如判断节点类型,生成新的节点等 var generator = require("@babel/generator").default; // 将语法树AST转换为js代码 var fsrw = require("fs"); var jscode = fsrw.readFileSync("ob_1_before.js", {encoding: "utf-8"}); // 读取原始混淆文件 var ast_parse = parser.parse(jscode); //将JS源码转换成语法树AST // 定义每个还原逻辑 var traverses_1 = {........................} var traverses_2 = {........................} var traverses_3 = {........................} // 还原逻辑运行 traverse(ast_parse, traverses_1) traverse(ast_parse, traverses_2) traverse(ast_parse, traverses_3) // 生成还原后的js文件 var ast_js_code = generator(ast_parse); // console.log("ast操作后的js文件内容:", ast_js_code.code) fsrw.writeFileSync('./ob_1_after.js', ast_js_code.code)
1、数组 + 移位自执行函数 + 解密字符串函数 还原
-
其目的是将js文件的如此类的
$_0x4f70('\x30\x78\x31\x34', '\x64\x5a\x59\x67') + '\x6f\x64'还原成"nDAod",其中还涉及了将十六进制字符串还原成正常易读的字符串,最终效果图如下

-
首先打开可视化显示AST结构工具,查看原js文件结构,并确定解密函数字符串为"$_0x4f70",分出前三部分并加载到内存后删除
// 获取解密函数前三部分(大数组+自执行函数+解密字符串函数),并写入内存后删除 var decryptFunNameStr = "$_0x4f70" let descrypt_strfun_js = ''; for(let i=0;i<=2;i++){ descrypt_strfun_js += generator(ast_parse.program.body[i], {compact:true}).code // compact:true, 设置js压缩 delete ast_parse.program.body[i] } eval(descrypt_strfun_js); -
其次观察$_0x4f70(’\x30\x78\x63\x62’, ‘\x69\x59\x23\x63’)树结构,需要解混淆的节点type为
CallExpression,所以我们对CallExpression节点逐个判断,满足当前节点的callee.name是解密字符串函数时,对当前节点进行统一解混淆替换

// 调用解密函数的逻辑还原 var decryptFunNameStr = "$_0x4f70" var traverses_1 = { CallExpression(path) { var cur_node = path.node; if(cur_node.callee.name === decryptFunNameStr && cur_node.arguments.length === 2){ path.replaceInline(types.valueToNode(eval(path.toString()))); } } } -
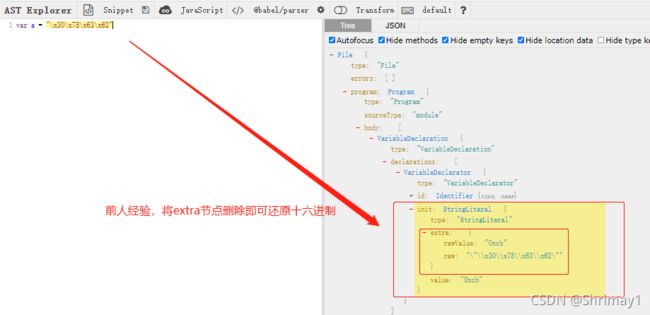
最后关于一些十六进制,unicode的字符串还原,借鉴前人经验,直接删除extra这个节点即可
// 处理十六进制等字符串还原 var traverses_2 = { // A.处理十六进制字符串,针对"\x68\x65\x6c\x6c" 》》 'hell' NumericLiteral(path) { cur_node = path.node; if (cur_node.extra && /^0[obx]/i.test(cur_node.extra.raw)) { cur_node.extra = undefined; } }, // B. 处理Unicode字符串,针对"\u0068\u0065\u006c\u006c" 》》'hell' StringLiteral(path) { cur_node = path.node; if (cur_node.extra && /\\[ux]/gi.test(cur_node.extra.raw)) { cur_node.extra = undefined; } }, // C. 字符串合并,exit的方式可以往深层判断是否都是满足这个, 针对 "whi" + "le " + "(tr" + "ue)" + " {}" 》》 "while (true) {}" BinaryExpression: { exit: function(path){ cur_node = path.node; if (cur_node.left.type==="StringLiteral"&&cur_node.right.type==="StringLiteral"&&cur_node.operator==='+'){ path.replaceWith(types.valueToNode(cur_node.left.value + cur_node.right.value)) } } } }
2、定义的对象Object有规律的key和value 还原
- 本案例的对象Object是
_0x3f5d3a,后又赋值给了对象 _0x1104e6 ,再后面一直调用的也是 _0x1104e6 对象 - 所以先将
_0x3f5d3a临时存储,然后再分析 _0x1104e6 对象引用时如何替换,其中我们发现_0x3f5d3a对象的值就两种类型,要么是function,要么是字符串,所以在后面分析 _0x1104e6 引用时,就只分析这两种情况
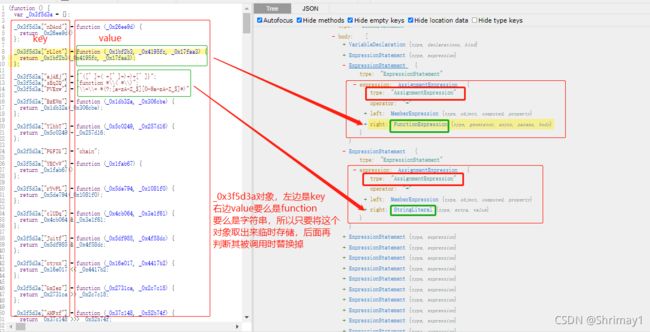
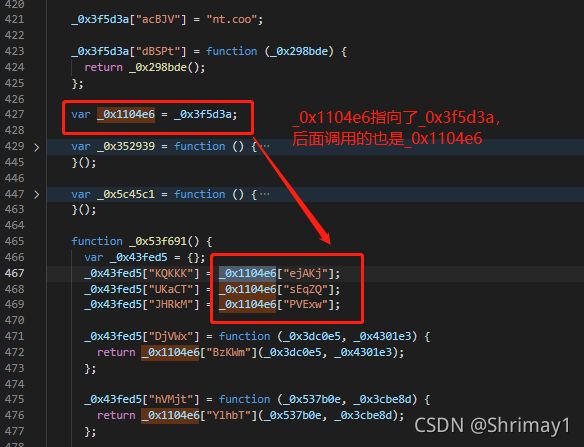
- 对象Object是
_0x3f5d3a临时存储代码// 将有规律的对象临时存储,并删除相应的节点 var temp_obj = {}; var regularObjNameStr = '_0x3f5d3a' var traverses_3 = { AssignmentExpression(path){ var cur_node = path.node; if((cur_node.right.type === 'FunctionExpression' || cur_node.right.type === 'StringLiteral')){ if(cur_node.left.object.name === regularObjNameStr){ temp_obj[cur_node.left.property.value] = cur_node.right; path.remove(); } } }, } - _0x1104e6 对象的值是字符串时被引用
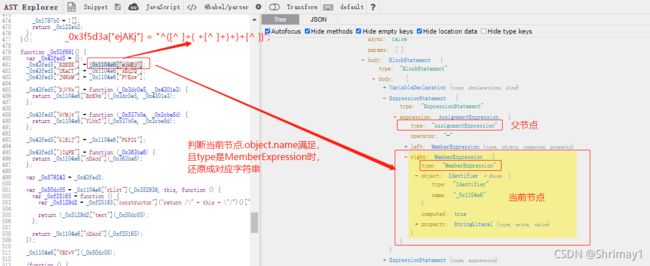
- _0x1104e6 对象的值是函数时被引用
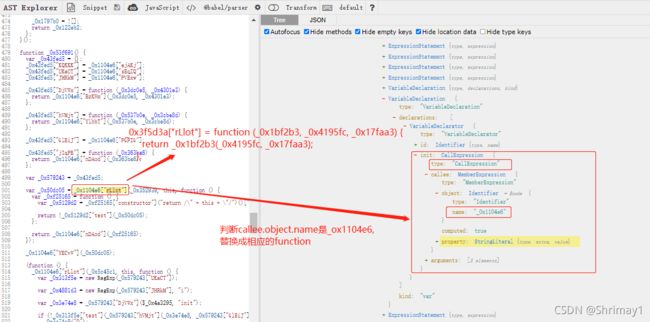
- ast代码,注意本案例当中
cur_node.callee.object.name === '_0x1104e6'// 有规律的对象引用替换 var refererObjNameStr = '_0x1104e6' var traverses_4 = { MemberExpression(path){ cur_node = path.node; if(cur_node.object.name === refererObjNameStr && (path.inList || path.parent.type === 'AssignmentExpression' || path.parent.type === 'BinaryExpression'|| path.parent.type === 'MemberExpression')){ path.replaceInline(temp_obj[cur_node.property.value]) } }, CallExpression(path){ cur_node = path.node if(cur_node.callee.object && cur_node.callee.object.name === refererObjNameStr){ const y_node = temp_obj[cur_node.callee.property.value]; if (y_node && y_node.body.body[0].argument.type === 'BinaryExpression'){ const operator = y_node.body.body[0].argument.operator; path.replaceInline(types.binaryExpression(operator, cur_node.arguments[0], cur_node.arguments[1])) } else if(y_node && y_node.body.body[0].argument.type === 'CallExpression'){ const arg = cur_node.arguments.slice(1); path.replaceInline(types.callExpression(cur_node.arguments[0], arg)) } } } }
3、while + switch控制流平坦化
-
控制流平坦化还原思路参考Nanda的这篇文章
-
控制流基本语法包括两种:一种是
if / else 条件语句判断,另一种是while / switch / case 条件语句判断,本案例是第二种,还原效果如图
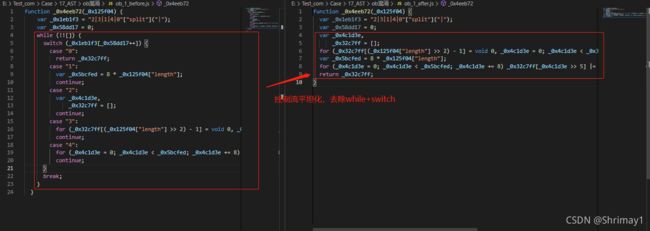
-
还原逻辑,可以将控制流数组先取出来》然后遍历控制流数组,依次取出依次取出对应的SwitchCase节点》再将每个SwitchCase节点的consequent代码块添加到临时数组中,如果有continue则删除该代码节点》遍历完后用用临时数组替换掉SwitchStatement节点
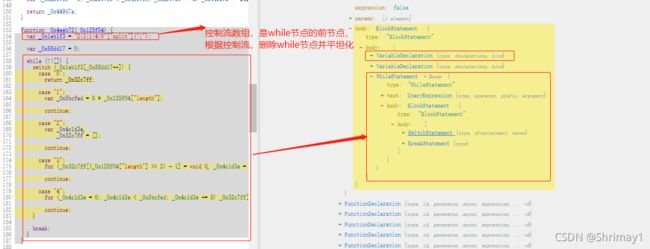
// 控制流平坦化while + switch var traverses_5 = { WhileStatement(path){ cur_node = path.node; if(cur_node.body.body[0].type === "SwitchStatement"){ var swithStm = cur_node.body.body[0]; // 找到path节点的前兄弟节点,即 _0x1eb1f3所在的节点,然后获取 _0x1eb1f3数组 var arrNodePath = path.getAllPrevSiblings()[1] var arrValue = arrNodePath.node.declarations[0].init.callee.object.value.split('|'); // SwitchCase节点遍历并临时存储到一个数组 var caseList = swithStm.cases; var temp_arr_switch_case = []; arrValue.map(targetIdx => { var targetBody = caseList[targetIdx].consequent; // 如果最后一个节点是,则删除ContinueStatement块(continue语句) if (types.isContinueStatement(targetBody[targetBody.length - 1])){ targetBody.pop(); } temp_arr_switch_case = temp_arr_switch_case.concat(targetBody) }); // 多个节点替换一个节点的话使用replaceWithMultiple方法 path.replaceWithMultiple(temp_arr_switch_case); } }, }