五大常见算法策略之——动态规划策略
Dynamic Programming
Dynamic Programming是五大常用算法策略之一,简称DP,译作中文是“动态规划”,可就是这个听起来高大上的翻译坑苦了无数人,因为看完这个算法你可能会觉得和动态规划根本没太大关系,它对“动态”和“规划”都没有太深的体现。
举个最简单的例子去先浅显的理解它,有个大概的雏形,找一个数组中的最大元素,如果只有一个元素,那就是它,再往数组里面加元素,递推关系就是,当你知道当前最大的元素,只需要拿当前最大元素和新加入的进行比较,较大的就是数组中最大的,这就是典型的DP策略,将小问题的解保存起来,解决大问题的时候就可以直接使用。
刚刚说的如果还是感觉有点迷糊,不用慌,下面几个简单的小栗子让你明白这句话的意思。
0、Fibonacci再讨论(易)
1、求解路径个数(易)
2、小青蛙跳台阶再讨论(易)
3、最长公共子序列问题(偏难)
4、0-1背包问题(一般)
Fibonacci再讨论
第一个数是1,第二个数也是1,从第三个数开始,后面每个数都等于前两个数之和。要求:输入一个n,输出第n个斐波那契数。
还是我们上节讨论递归与分治策略时候举的第一个例子——Fibonacci数列问题,它实在太经典了,所以将其反复拿出来说。
我们如果深入分析一下上节说过的递归方法解决Fibonacci数列,就会发现出现了很多重复运算,比如你在计算f(5)的时候,你要计算f(4)和f(3),计算f(4)又要计算(3)和f(2),计算f(3),又要计算f(2)和f(1),看下面这个图
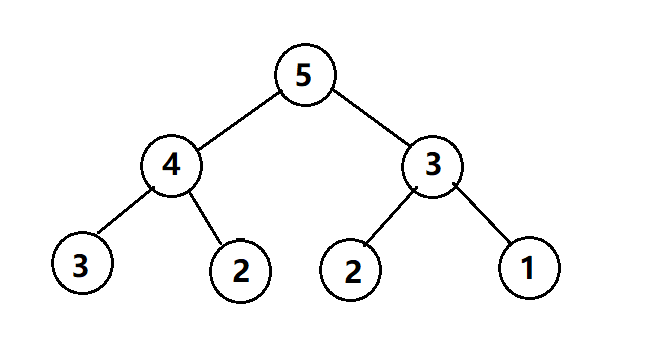
对f(3)和f(2)进行了重复运算,这还是因为5比较小,如果要计算f(100),那你可能要等到天荒地老它还没执行完(手动滑稽),感兴趣的朋友可以试试,反正我已经试过了。
public static int fibonacci(int n){//递归解法
if(n == 1) return 1;
else if(n == 2) return 1;
else return fibonacci(n - 1) + fibonacci(n - 2);
}
上面就是递归的解法,代码看着很简单易懂,但是算法复杂度已经达到了O(2^n),指数级别的复杂度,再加上如果n较大会造成更大的栈内存开销,所以非常低效。
我们再来说说DP策略解决这个问题
我们知道导致这个算法低效的根本原因就是递归栈内存开销大,对越小的数要重复计算的次数越多,那既然我们已经将较小的数,诸如f(2),f(3)…这些计算过了,为什么还要重复计算呢,这时就用到了DP策略,将计算过的f(n)保存起来。我们看看代码:
/**
* 对斐波那契数列求法的优化:如果单纯使用递归,那重复计算的次数就太多了,为此,我们对其做一些优化
* 假设最多计算到第100个斐波那契数
* 用arr这个数组来保存已经计算过的Fibonacci数,以确保不会重复计算某些数
*/
private static int arr[] = new int[100];
public static int Fibonacci(int n){
if(n <= 2){
return 1;
}else{
if(arr[n] != 0) //判断是否计算过这个f(n)
return arr[n];
else{
arr[n] = Fibonacci(n-1)+Fibonacci(n-2);
return arr[n];
}
}
}
arr数组初始化为0,arr[i]就表示f(i),每次先判断arr[i]是否为0,如果为0则表示未计算过,则递归计算,如果不为0,则表示已经计算过,那就直接返回。
这样的好处避免了很大程度上重复的计算,但是对栈内存的开销虽然有减小但还不是很显著,因为只要有递归,栈内存就免不了有较大开销。所以针对Fibonacci数列我们还有一个递推的方式来计算,其实这也符合DP策略的思想,都是将计算过的值保存起来。
//甚至可以使用递推来求解Fibonacci数列
public static int fibonacci(int n){
if(n <= 2) return 1;
int f1 = 1, f2 = 1, sum = 0;
for(int i = 3; i <= n; i++){
sum = f1+f2;
f1 = f2;
f2 = sum;
}
return sum;
}
求解路径个数
一个机器人每次只能向右或者下走一步,问它试图到达右下角“Finish”,共有多少条不同的路径?(7*3的网格)
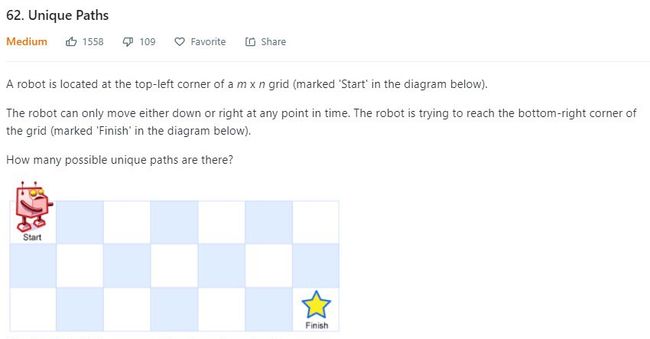
DP策略类的题最重要是要找状态转移方程,恰恰也是最难的一步。

- 1、我们通过这个图可以看出其实要到达(i,j)也就两种情况,一种是从(i,j-1)向右走一步到达,另一种是从(i-1,j)向下走一步到达,所以将这两种情况的路径数相加就是到(i,j)的所有路径数。
由此列出状态转移方程:
f(i,j)=f(i-1,j)+f(i,j-1)
- 2、根据DP的思路,将已经计算过的存储起来并用于后面复用其结果,这里我们考虑用二维数组来存储f(i,j)。
- 3、问题规模从小到大计算,大规模的问题复用小规模问题的解进行计算。
代码实现
/**
* 此题是求解路径个数,让你从(1,1)走到某个特定的位置,求一共有多少种走法
* @param i
* @param j
* @return
*/
public static int Count_Path(int i, int j){
int result[][] = new int[i][j];
for (int k = 0; k < i; k++) { //将二维数组初始化为1
Arrays.fill(result[k],1);
}
for (int k = 1; k < i; k++) {
for (int l = 1; l < j; l++){
result[k][l] = result[k-1][l]+result[k][l-1];
}
}
return result[i-1][j-1];
}
小青蛙跳台阶再讨论
又是那只熟悉的青蛙,和上节递归与分治中相同的例题,一只青蛙一次可以跳上1级台阶,也可以跳上2级,求该青蛙跳上一个n级的台阶共有多少种跳法。详细思路可以看看上一篇文章——递归与分治策略。
我们下面先回顾一下上次用的递归算法:
public static int Jump_Floor1(int n){
if(n <= 2){
return n;
}else{ //这里涉及到两种跳法,1、第一次跳1级就还有n-1级要跳,2、第一次跳2级就还有n-2级要跳
return Jump_Floor1(n-1)+Jump_Floor1(n-2);
}
}
其实和第一个例子斐波那契一样,之所以把它又拉出来讨论,是因为它的递归解法中涉及的重复计算实在太多了,我们需要将已经计算过的数据保存起来,以避免重复计算,提高效率。这里大家可以先自己试着改一下其实和第一个例子的改进方法是一样的,用一个数组来缓存计算过的数据。
/**
* 看完递归的方法不要先被它的代码简洁所迷惑,可以分析一下复杂度,就会发现有很多重复的计算
* 而且看完这个会发现和Fibonacci的递归方法有点像
* @非递归
*/
private static int result[] = new int[100];
public static int Jump_Floor2(int n){
if(n <= 2){
return n;
}else{
if(result[n] != 0)
return result[n];
else{
result[n] = Jump_Floor2(n-1)+Jump_Floor2(n-2);
return result[n];
}
}
}
下面将难度做一提升,我们来讨论一道DP策略里的经典例题——最长公共子列问题
最长公共子序列问题
给定两个序列,需要求出两个序列最长的公共子序列,这里的子序列不同于字串,字串要求必须是连续的一个串,子序列并没有这么严格的连续要求,我们举个例子:
比如A = “LetMeDownSlowly!” B=“LetYouDownQuickly!” A和B的最长公共子序列就是"LetDownly!"
比如字符串1:BDCABA;字符串2:ABCBDAB,则这两个字符串的最长公共子序列长度为4,最长公共子序列是:BCBA
我们设 X=(x1,x2,…xn) 和 Y={y1,y2,…ym} 是两个序列,将 X 和 Y 的最长公共子序列记为LCS(X,Y),要找它们的最长公共子序列就是要求最优化问题,有以下几种情况:
- 1、n = 0 || m = 0,不用多说最长的也只能是0,LCS(n,m) = 0
- 2、X(n) = Y(m),说明当前序列也是相等的,那就给这两个元素匹配之前的最长长度加一,即LCS(n,m)=LCS(n-1,m-1)+1
- 3、X(n) != Y(m),这时候说明这两个元素并没有匹配上,那所以最长的公共子序列长度还是这两个元素匹配之前的最长长度,即max{LCS(n-1,m),LCS(n,m-1)}
由此我们可以列出状态转移方程:(用的别人的图)
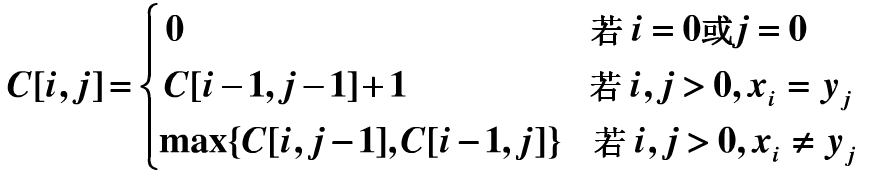
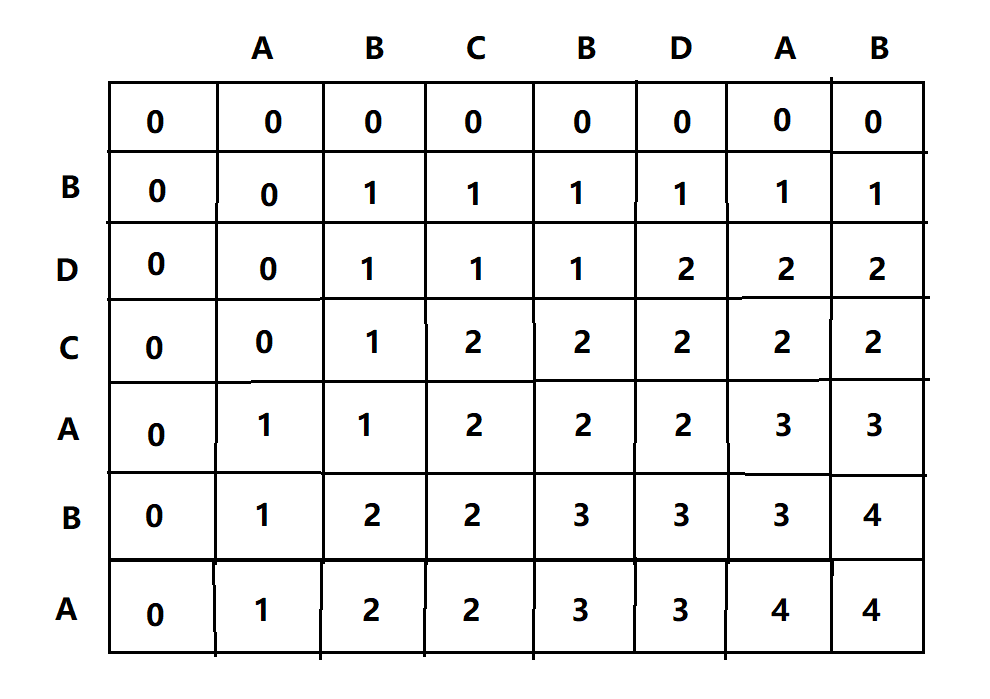
我们可以考虑用一个二维数组来保存LCS(n,m)的值,n表示行,m表示列,作如下演示,比如字符串1:ABCBDAB,字符串2:BDCABA;
1、先对其进行初始化操作,即将m=0,或者n=0的行和列的值全填为0

2、判断发现A != B,则LCS(1,1) = 0,填入其中
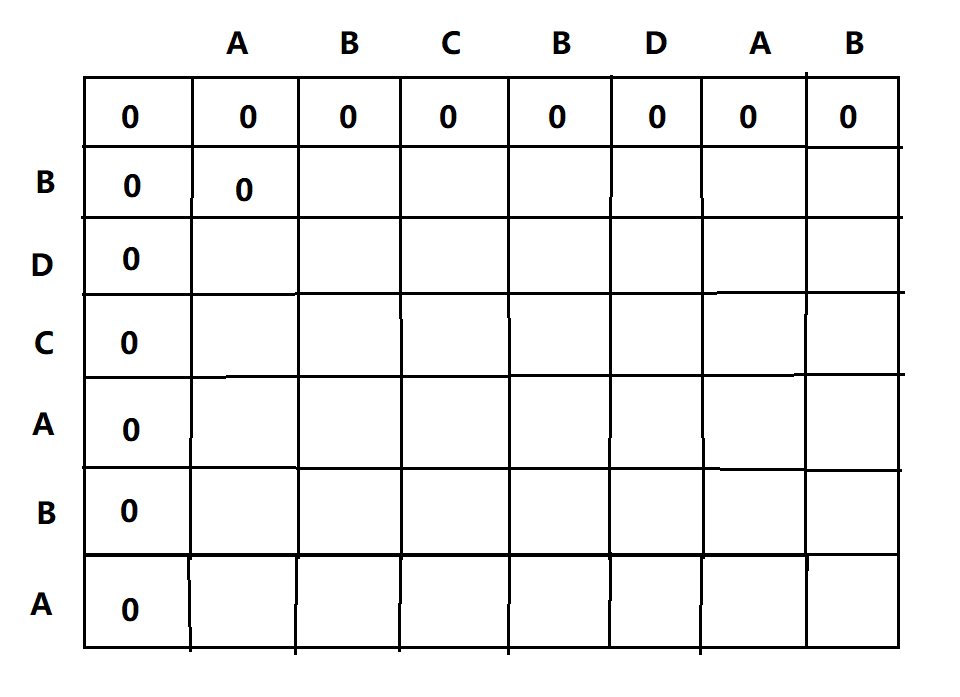
3、判断B == B,则LCS(1,2) = LCS(0,1)+1=1,填入其中
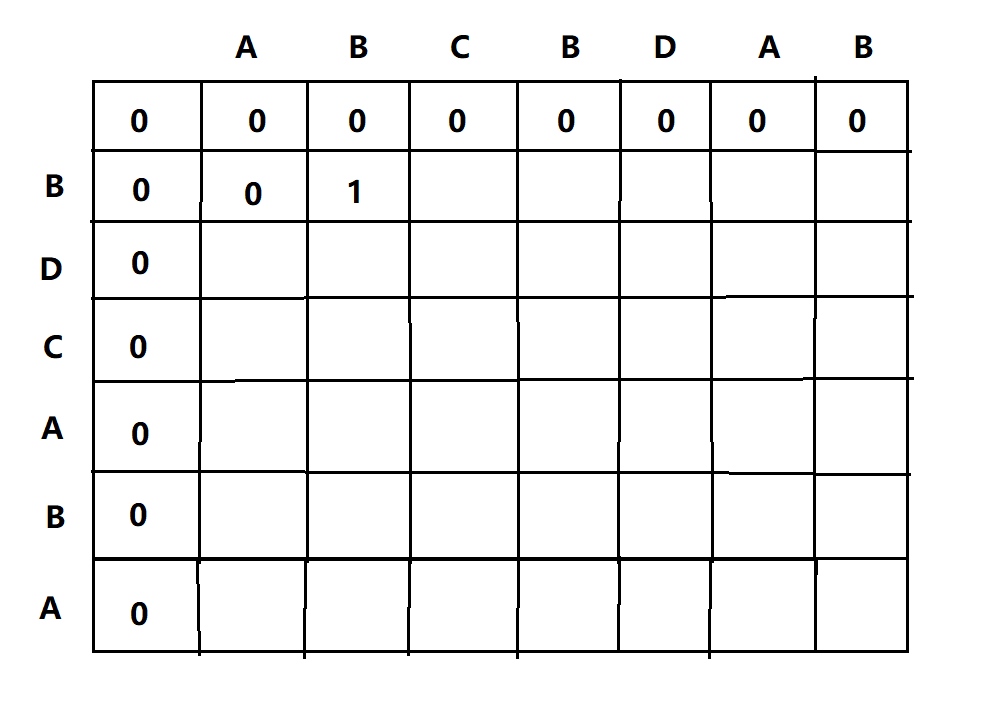
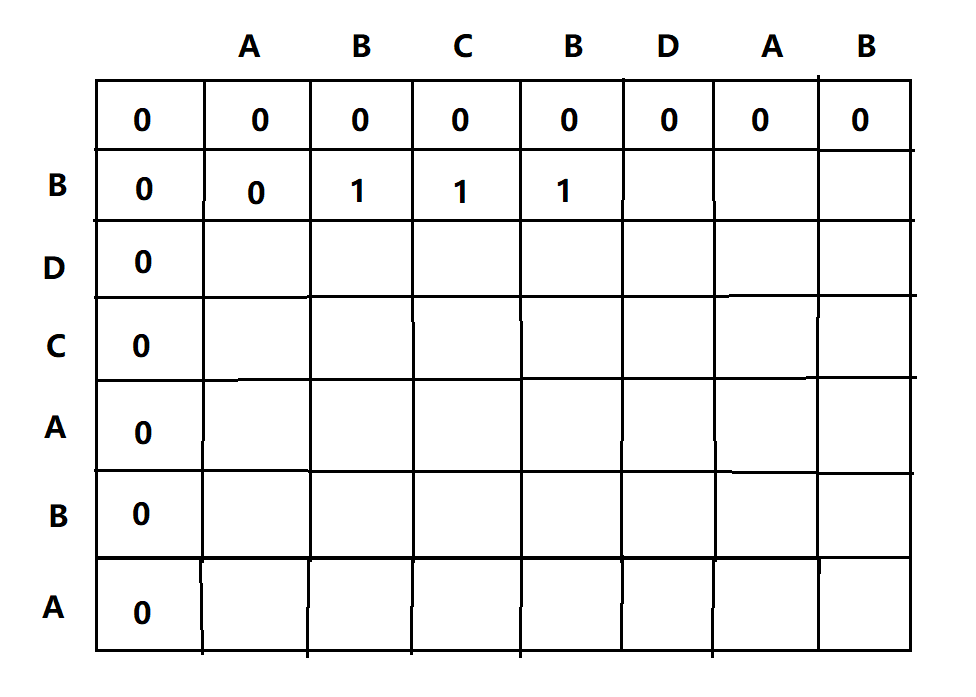
4、判断B != C,则LCS(1,3)就应该等于LCS(0,3)和LCS(1,2)中较大的那一个,即等于1,通过观察我们发现现在的两个序列是{B}和{ABC}在比较,即使现在B != C,但是因为前面已经有一个B和其匹配了,所以长度最少已经为1了,所以当C未匹配时,子序列的最大值是前面的未比较C和B时候的最大值,所以填1
5、再比较到B和B,虽然两者相等,但是只能是LCS(n-1,m-1)+1,所以还是1,因为一个B只能匹配一次啊,举个例子:就好像是DB和ABCB来比较,当第一个序列的B和第二个序列的第二个B匹配时,就应该是D和ABC的最长子序列+1,所以如下填表:
6、掌握规律后,我们直接完整填完这个表
代码实现:
/**
* 求最长公共子序列问题
* Talk is cheap, show me the code!
* 参考公式(也是最难的一步):
* { 0 i = 0, j = 0
* c[i][j] = { c[i-1][j-1]+1 i,j>0, x[i] == y[i]
* { max{c[i-1][j],c[i][j-1]} i,j>0, x[i] != y[i]
* 参考书目:算法设计与分析(第四版)清华大学出版社 王晓东 编著
* 参考博客:https://www.cnblogs.com/hapjin/p/5572483.html
* 比如A = "LetMeDownSlowly!" B="LetYouDownQuickly!" A和B的最长公共子序列就是"LetDownly!"
* @param x
* @param y
* @Param c 用c[i,j]表示:(x1,x2....xi) 和 (y1,y2...yj) 的**最长**公共子序列的长度
* @return 最长公共子序列的长度
*/
//maybe private method
private static int lcsLength(String x, String y, int[][] c){
int m = x.length();
int n = y.length();
//下面是初始化操作,其实也没必要,因为Java中默认初始化为0,其他语言随机应变
for (int i = 0; i <= m; i++) c[i][0] = 0;
for (int i = 0; i <= n; i++) c[0][i] = 0;
//用一个序列的每个元素去和另一个序列分别比较
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if(x.charAt(i-1) == y.charAt(j-1)){ //如果遇到相等的,就给序列的上一行上一列的加1
c[i][j] = c[i-1][j-1]+1;
}else if(c[i-1][j] >= c[i][j-1]){ //取上一次最大的,保证最长子序列的最长要求
c[i][j] = c[i-1][j];
}else{
c[i][j] = c[i][j-1];
}
}
}
return c[m][n];
}
0-1背包问题
也是很经典的一道算法题:0-1背包问题说的是,给定背包容量W,一系列物品{weiht,value},每个物品只能取一件,计算可以获得的value的最大值。
最优解问题,当然是我们DP,最难的一步还是状态转移方程,我们先把方程给出来,再对其进行讨论.
m[i][j] = max{ m[i-1][j-w[i]]+v[i] , m[i-1][j]}
m[i][j]表示1,2,…,i个物品,背包容量为j时候的最大value,w[i]表示第i个物品的重量,v[i]表示第i个物品的value
我们用一个二维数组来存储这个m,i表示1,2,…,i个物品,j表示背包容量
对于每一个物品来说,要计算当前最大的value,分为两种情况:1、将这个物品放进去,不将这个物品放进去
- 1、我们先考虑不将其放进去, 很好理解,m[i-1][j]就是不将第i个物品放入背包的最大value,不放就是1,2,…,i-1个物品,背包容量为j
- 2、再考虑放进去的情况,既然要将其放进去,那就在背包中给其预先留好位置,m[i-1][j-w[i]]表示在背包中先给第i个物品把地方腾出来,然后背包可用空间就是j-w[i],在这些可用空间里1,2,…,i-1个物品放的最大value就是m[i-1][j-w[i]],将其放进去只需要再给加上v[i]即可,即m[i-1][j-w[i]]+v[i]。
所以状态转移方程就是取放进去和不放进去两种情况的最大值
m[i][j] = max{ m[i-1][j-w[i]]+v[i] , m[i-1][j]}
代码实现
/**
* 此函数用于计算背包中能存放的最大values
* @param m m[i][j]用于记录1,2,...,i个物品在背包容量为j时候的最大value
* @param w w数组存放了每个物品的重量weight,w[i]表示第i+1个物品的weight
* @param v v数组存放了每个物品的价值value,v[i]表示第i+1个物品的value
* @param C C表示背包最大容量
* @param sum sum表示物品个数
* 状态转移方程: m[i][j] = max{ m[i-1][j-w[i]]+v[i] , m[i-1][j]}
* m[i-1][j]很好理解,就是不将第i个物品放入背包的最大value
* m[i-1][j-w[i]]+v[i]表示将第i个物品放入背包,m[i-1][j-w[i]]表示在背包中先给第i个物品把地方腾出来
* 然后背包可用空间就是j-w[i],在这些可用空间里1,2,...,i-1个物品放的最大value就是m[i-1][j-w[i]],那
* 最后再加上第i个物品的value,就是将第i个物品放入背包的最大value了
*/
public static void knap(int[][] m, int[] w,int[] v, int C, int sum){
for(int j = 0; j < C; j++){ //初始化 stuttering
if(j+1 >= w[0]){ //第一行只有一个物品,如果物品比背包容量大就放进去,否则最大value只能为0
m[0][j] = v[0];
}else{
m[0][j] = 0;
}
}
for(int i = 1; i < sum; i++){
for(int j = 0; j < C; j++){
int a = 0, b = 0; //a表示将第i个物品放入背包的value,b表示不放第i个物品
if(j >= w[i])
a = m[i-1][j-w[i]]+v[i];
b = m[i-1][j];
m[i][j] = (a>b?a:b);
}
}
}