Raki的读paper小记:GloVe: Global Vectors for Word Representation
大名鼎鼎来自Stanford Chris Manning组的GloVe词向量
摘要
本方法提出的初衷是,基于shallow-window的方法的缺点是它们不能直接对语料库的共现统计数据进行操作,而只是用一个滑动窗口滑过整个语料库,无法利用数据中的大量重复。
碎碎念:首先得吐槽一下,GloVe是目前读过的paper里面最难懂的…明明他的model并不是很复杂,可能因为生词有点多(泪目
模型
我们利用我们的见解构建了一个新的词表示模型,我们称之为GloVe,用于全局向量,因为全局语料库统计数据是由该模型直接捕获的
首先给了一个例子:

这个例子说明,一个词向量学习的合适出发点应该是共现概率的比率,而不是概率本身有关

用公式表示为:
F ( w i , w j , w k ~ ) = P i k P j k \Large F(w_i,w_j,\tilde{w_k})=\frac{P_{ik}}{P_{jk}} F(wi,wj,wk~)=PjkPik
由于向量空间本质上是线性结构,因此最自然的方法是使用向量差。为了达到这个目的,我们可以将我们的考虑限制在那些只依赖于两个目标词的差异的函数F上,
把公式改为:
F ( w i − w j , w k ~ ) = P i k P j k \Large F(w_i-w_j,\tilde{w_k})=\frac{P_{ik}}{P_{jk}} F(wi−wj,wk~)=PjkPik
然后又出现了新的问题,等式的左边是一个向量,而右边是一个标量
虽然 F F F 可以被看作是一个复杂的函数,例如通过神经网络进行参数化,但这样做会混淆我们试图捕捉的线性结构。为了避免这个问题,我们可以先取参数的点积
F ( ( w i − w j ) T w k ~ ) = P i k P j k \Large F((w_i-w_j)^T\tilde{w_k})=\frac{P_{ik}}{P_{jk}} F((wi−wj)Twk~)=PjkPik
这可以防止 F F F以不希望的方式混合向量维度
在词-词共现矩阵中,我们应该是可以任意交换两个词的位置的,而前面的公式并没有对称性
然而,对称性可以分两步恢复:
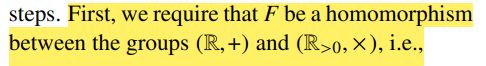
-
F ( ( w i − w j ) T w k ~ ) = F ( w i T w k ~ ) F ( w j T w k ~ ) \large F((w_i-w_j)^T\tilde{w_k})=\frac{F(w_i^T\tilde{w_k})}{F(w_j^T\tilde{w_k})} F((wi−wj)Twk~)=F(wjTwk~)F(wiTwk~)
-
F ( w i T w k ~ ) = P i k = X i k X i \large F(w_i^T\tilde{w_k}) = P_{ik} = \frac{X_{ik}}{X_i} F(wiTwk~)=Pik=XiXik
解决办法是 F = e x p F=exp F=exp,或者: w i T w k ~ = l o g P i k = l o g ( X i k ) − l o g ( X i ) \large w_i^T\tilde{w_k} = log{P_{ik}} = log(X_{ik}) - log(X_i) wiTwk~=logPik=log(Xik)−log(Xi)

由于 l o g ( X i ) log(X_i) log(Xi)是不依赖于 k k k的项,所以可以被吸收到 w i w_i wi的偏置里面,加上 w i ~ \tilde{w_i} wi~的偏置就
得到公式: w i T w k ~ + b i + b k ~ = l o g ( X i k ) \large w_i^T\tilde{w_k} + b_i + \tilde{b_k} = log(X_{ik}) wiTwk~+bi+bk~=log(Xik)
满足了对称性,但是此公式还是有一个问题,就是在x取0的时候,对数将会发散,所以需要进行一点小小的偏移: l o g ( X i k ) − > l o g ( 1 + X i k ) \large log(X_{ik}) ->log(1+X_{ik}) log(Xik)−>log(1+Xik)
保持了稀疏性并且防止发散
把共现矩阵log进行因式分解的思想有点类似于LSA,该模型的一个主要缺点是,它对所有的共现进行了同等的加权,即使是那些很少发生或从未发生的事件,而频率很低的共现噪声非常多,并且带有更少的信息,作者提出了一种最小二乘加权回归来解决这些问题:

J = ∑ i , j = 1 V f ( X i , j ) ( w i T w k ~ + b i + b k ~ − l o g ( X i k ) ) 2 \large J = \sum_{i,j=1}^V f(X_{i,j})(w_i^T\tilde{w_k} + b_i + \tilde{b_k} - log(X_{ik}))^2 J=∑i,j=1Vf(Xi,j)(wiTwk~+bi+bk~−log(Xik))2
where V is the size of the vocabulary
The weighting function should obey the following properties:

进行一个玄学的选函数

再进行一个玄学的超参数选取,反正很work就完事了

Relationship to Other Models
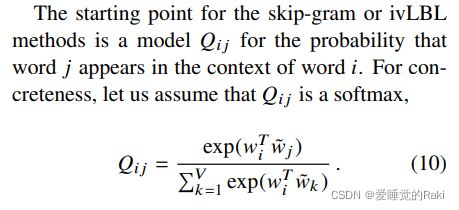
因为softmax的开销非常大,skip-gram选用需要优化的全局函数将会高效很多:
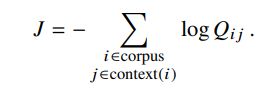
其中,我们使用了一个事实,即相似项的数量由共现矩阵X给出,然后化一下公式,就搞出了交叉熵公式

但是交叉熵损失有一个很不好的属性就是它有长尾分布,通常建模很差,对不太可能发生的事件过于重视
此外,为了使测度有界,需要对模式分布Q进行适当的归一化。由于softmax中整个词汇表的总和,这就出现了计算瓶颈。
对此,我们可以选用最小二乘公式来解决
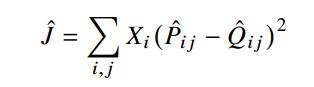
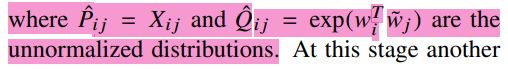
新的问题又出现了, X i j X_{ij} Xij的数值经常会很大,我们把P和Q替换成对数
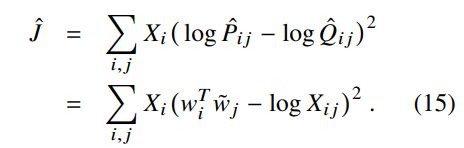
最后得到如下公式,跟之前推导出来的 J = ∑ i , j = 1 V f ( X i , j ) ( w i T w k ~ + b i + b k ~ − l o g ( X i k ) ) 2 \large J = \sum_{i,j=1}^V f(X_{i,j})(w_i^T\tilde{w_k} + b_i + \tilde{b_k} - log(X_{ik}))^2 J=∑i,j=1Vf(Xi,j)(wiTwk~+bi+bk~−log(Xik))2 ,是等价的
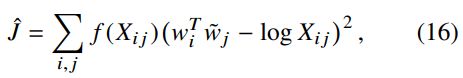
Complexity of the model



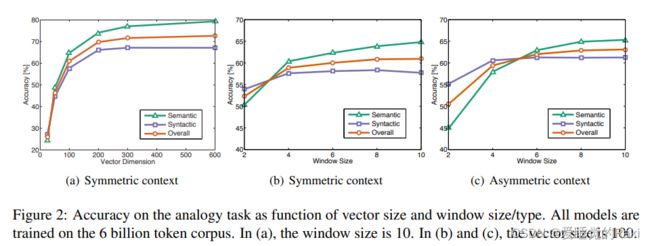
实验
实验部分就是一些sota,直接看图就能一目了然了
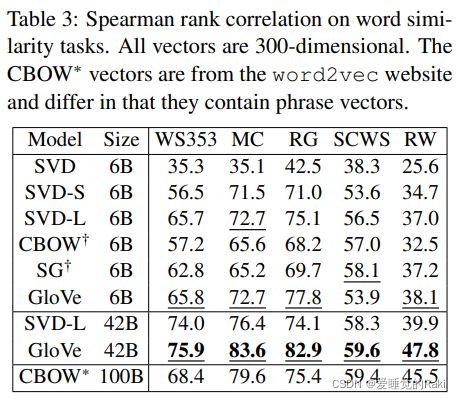
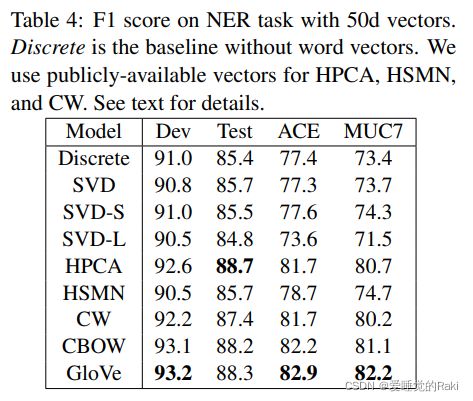
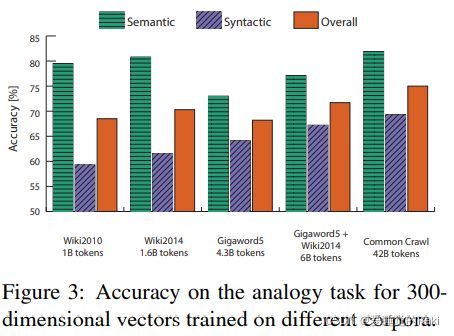
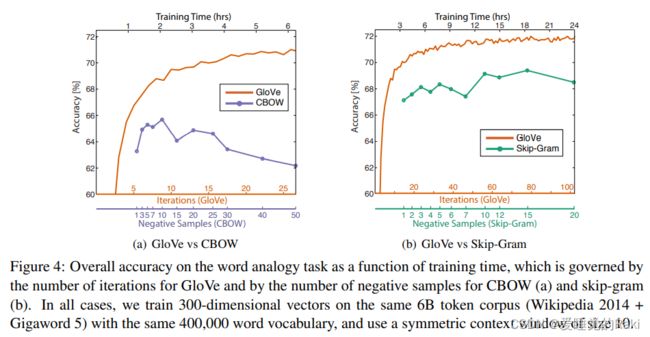
评价
总⽽⾔之,GloVe 模型仅对单词共现矩阵中的⾮零元素训练,从⽽有效地利⽤全局统计信息,并⽣成具
有有意义的⼦结构向量空间。给出相同的语料库,词汇,窗⼝⼤⼩和训练时间,它的表现都优于
word2vec,它可以更快地实现更好的效果,并且⽆论速度如何,都能获得最佳效果
然后现在一般常用的也是GloVe在840b语料上训练出来的300d词向量