【飞桨PaddlePaddle】四天搞懂生成对抗网络(三)——用CGAN做图像转换的鼻祖pix2pix


Pix2Pix的不甘の野望
也许是CycleGAN的光芒太过耀眼,Pix2Pix就像家中的次子,还没得宠多长时间,就被弟弟CycleGAN抢走了风头。这也怪不得它们的“爹滴”朱大神把“域风格迁移”的CycleGAN(下个项目介绍)造得太好用了,似乎完全能够代替“像素风格迁移”的Pix2Pix,以至于都来不及给Pix2Pix起个××GAN的名字~
其实,除了“白天照片变夜晚”、“图片着色”、“蓝图变街景”等它弟弟CycleGAN更容易玩儿的花样儿外,Pix2Pix是有着自己的独门绝技的。比如,用自然风景照片训练好的Pix2Pix模型,能实时将手绘的草图渲染成对应风景照片。如果训练集照片里包括老虎等动物,我们几笔在一个圆圈脑袋上画个王字,Pix2Pix模型就能生成一张活灵活现的大老虎,比《照相馆的故事》快多了~Pix2Pix的工作也启发了一些更具体的应用,比如专门手绘照片的SketchyGAN、手绘人脸的模型DeepFaceDrawing等。另外Pix2Pix->Pix2PixHD(高清渲染)->Vid2Vid(视频实时渲染)也是一条发展路线。试想,只需建好游戏人物和场景的结构模型,然后机器自动按训练的风格渲染人物和场景,游戏设计师们有没有感到点儿激动。
在上一篇《风格迁移的“精神始祖”Conditional GAN》中,我们介绍了“加上了按钮”的CGAN,让GAN学会了听从类别指令。这次要完成的任务是图像到图像翻译(image-to-image translation),我们上眼Pix2Pix。
像素迁移网络Pix2Pix的介绍
1. Pix2Pix的原理
发表在CVPR2017上的论文《Image-to-Image Translation with Conditional Adversarial Networks》是将GAN应用于有监督的图像到图像翻译的经典论文,提出的GAN模型被简称为Pix2Pix(不叫××GAN,很像是小名儿吧~)。为了解决图像到图像的翻译(也就是前面提到的那些上色、手绘草图的应用),我们需要建立一个模型实现图像到图像的映射。
以前曾经有过尝试搭建一个CNN网络进行映射,并用L1距离来度量、优化模型,结果发现效果很模糊(用L2距离更模糊),就像下面这样:
那么,既然GAN能够较好地生成图片的细节,我们何不拿来一用?显然,经典GAN是不行的,没法控制输出嘛。CGAN正好拿来一用。对此,朱大神在报告里曾经解释过:如果我们用经典GAN,判别器判别时会出现这样的问题。
这样的生成图片判别为真没问题
但是,这样的生成图片也判断为真就有问题了。显而易见,生成的猫图片与手绘的猫草图的形态完全不一致。但因为这也是一张猫图片,是符合训练集图片的像素概率分布的,所以会被经典GAN判别为真图片。
为了解决这一问题,我们将输入的猫草图作为“条件标签”和生成的猫图片一起送入判别器进行判断,如下图:

这看上去是不是有点儿CGAN的影子?没错,这个Pix2Pix就是个CGAN!
2.Pix2Pix的结构
我们将Pix2Pix的结构与上篇CGAN的结构对比一下:
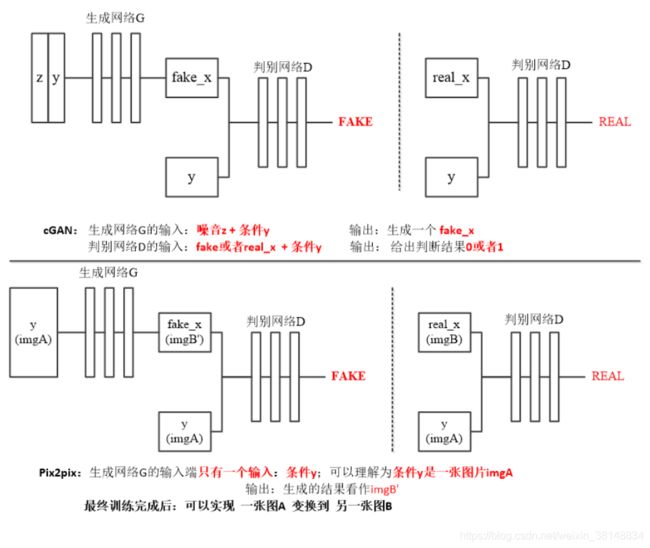
上图的上半部份是普通CGAN的结构,下半部分是Pix2Pix的结构。对比发现,Pix2Pix与CGAN的结构有两点不同:
-
在Pix2Pix中,输入生成器的控制条件由“分类标签y”变成了A组(原风格)图片,因为这里我们要用A组(原风格)图片做为控制条件来生成B组(目标风格)图片。由于输入生成器的A组图片的维度(图片尺寸)与生成器输出的B组图片的维度相同,足以映射复杂分布,所以,我们不必再输入噪声z。细心的同学可能会发现:在刚才那张“对比普通CGAN和Pix2Pix结构”的图片中,我们对“条件y”的解释,与上一张“介绍给Pix2Pix加标签原因”的图片中的解释不一样。“对比结构”的图片中将生成器的输入解释为“条件y”,而“解释用CGAN原因”的图片中将生成器的输入解释为“输入x”。实际上这两种对生成器输入的解释都指的是A(原风格)组图片,不影响后面的推理。但个人觉得:将生成器的输入解释为“条件y”更容易帮助理解Pix2Pix的CGAN本质。我理解,Pix2Pix拟合的是训练集中B组(目标风格)图片的像素概率分布,A组(原风格)图片是作为“约束条件”来使用的。对比一下普通CGAN的结构就清楚了。
-
在Pix2Pix中,输入判别器的控制条件也由“分类标签y”变成了A组(原风格)图片。A组(原风格)图片作为“条件y”要和真B组(目标风格)图片或生成器生成的假B组图片(在图像通道维度上)拼接在一起送入判别器。这个很好理解,也说明了前面把生成器的输入解释为“条件y”更“工整”。
这样,Pix2Pix做了以上改动后,整个模型从“输入噪声、输出图片”的流程,变成了“输入A组图片、输出B组图片”的流程。
3.Pix2Pix的loss
在大神造Pix2Pix的过程中也试过各种“配方”。包括使用L1损失、使用CGAN损失和使用两者之和,测试结果如下:

观察结果发现:
-
只用L1损失时,生成的图片比较模糊。
-
只用CGAN损失时,生成的图片很清晰,但颜色风格与Ground Truth图片差别较大。
-
使用L1+CGAN损失时,生成的图片又清晰,又保留了更多Ground Truth图片的特征。
所以,最后Pix2Pix使用了L1+CGAN损失。我们看下loss的构成。
先看L1损失:

L1损失的计算方法就是真B组(目标风格)图片与生成器生成的假B组图片逐像素求差的绝对值再求平均。公式中的x指A组(原风格)图片,y指B组(目标风格)图片,z指C输入给生成器的(一般是高斯分布的)噪声,代码中并未使用。
再来看看CGAN损失:
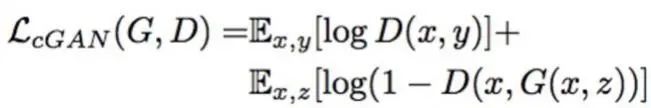
Pix2Pix的CGAN损失和普通CGAN损失一模一样,前文《风格迁移的“精神始祖”Conditional GAN》中有详细的解读。
Pix2Pix总的损失是这两者之和:
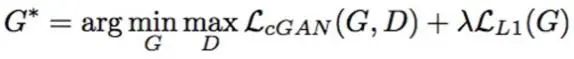
用Paddle实现Pix2Pix
代码总是我最喜欢的部分,就像飞桨PaddlePaddle一样~使用飞桨PaddlePaddle的动态图模式能够很方便的实现一个GAN网络,而且还能即时输出调试。
这个项目中,我们使用城市街景分割数据集,将照片风格的图片翻译成掩码风格的图片(其实就是做了像素分割任务)。
代码的可执行版本请登录AI Studio 一键fork运行,有免费GPU算力哦~
https://aistudio.baidu.com/aistudio/projectdetail/1119048
1.数据准备和辅助函数
Pix2Pix需要将训练集图片分组、配对,处理起来比较麻烦一点。所以,我就借(偷)鉴(懒)了Paddle代码库里的GAN的data reader。这个reader在每个batch的循环中输出的图片都是成对的,shuffle也是同步进行不会打破这一对应关系,输出的数据形状为【2,N,C,W,H】。
# 解压数据集,首次运行后注释
# !unzip -qo -d /home/aistudio/data/data10830 /home/aistudio/data/data10830/cityscapes.zip
from data_reader import data_reader
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
class CFG():
def __init__(self):
self.data_dir = 'data/data10830'
self.shuffle = True
self.dataset = 'cityscapes/cityscapes'
self.model_net = 'Pix2pix'
self.train_list = 'data/data10830/cityscapes/pix2pix_train_list'
self.batch_size = 1
self.drop_last = False
self.run_test = False
self.load_size = 256
self.crop_size = 224
self.crop_type = 'Random'
cfg = CFG()
print(cfg.data_dir)
reader = data_reader(cfg)
def show_reader_data(reader):
train_reader, test_reader, batch_num = reader.make_data()
data = next(train_reader())
data = np.array(data)
# print(data.shape)
# data = np.array(data).transpose((1, 0, 2, 3, 4))
print('读取数据的形状:', data.shape)
img1 = (data[0][0].transpose((1, 2, 0)) + 1) * 0.5
img2 = (data[1][0].transpose((1, 2, 0)) + 1) * 0.5
print('A组照片的形状:', img1.shape, 'B组照片的形状:', img2.shape)
plt.figure(figsize=(12, 8), dpi=80)
plt.subplot(1, 2, 1)
plt.imshow(img1)
plt.title('pic')
plt.xticks = ([])
plt.yticks = ([])
plt.subplot(1, 2, 2)
plt.imshow(img2)
plt.title('seg')
plt.xticks = ([])
plt.yticks = ([])
return data
def show_pics(pics, heatmap=np.zeros((1, 1))):
plt.figure(figsize=(4 * len(pics), 4), dpi=80)
for i in range(len(pics)):
pics[i] = (pics[i][0].transpose((1,2,0)) + 1) / 2
plt.subplot(1, len(pics), i + 1)
plt.imshow(pics[i])
# plt.xticks([])
# plt.yticks([])
data = show_reader_data(reader)
data/data10830
data/data10830/cityscapes/cityscapes data/data10830/cityscapes/pix2pix_train_list读取数据的形状:(2, 1, 3, 224, 224)
A组照片的形状:(224, 224, 3) B组照片的形状:(224, 224, 3)

上面代码数据读入代码执行后,打印了数据形状和分属A、B组的一对图片。左边是照片(原)风格的,右边是mask掩码(目标)风格的。
2.判别器PatchGAN
在前面分析Pix2Pix的loss时,我们知道了,一方面Pix2Pix使用L1 loss保证生成图片物体的边缘对齐和颜色还原,另一方面是靠GAN loss来使生成的图片更清晰,也就是所谓构建图片的“高频部分”。而PatchGAN的思想就是,既然GAN只用于构建高频信息,那么:
-
就不需要将整张图片输入到判别器中。让判别器对图像的每个大小为N x N的patch做真假判别就可以了。这样可以减少参数数量,加快训练速度。
-
判别图片真假的方法也不再是回归出一个图片真假的概率值。而PatchGAN的判别器输出的是一个30×30的特征图,这个特征图的每一个点对应原图片一块70×70大小的patch。计算对抗loss时将这个特征图降维取均值,以衡量生成图片的每一个patch与真图片的差异。实测这样可以提高生成图片的清晰度。
论文测试了各种patch取值的效果,对比如下:

对比的结果,patch大小在70x70的时候,从视觉上看结果就和直接把整张图片作为判别器输入没有多大区别了。
需要注意的一点是,patch取值70×70是反推的。比如,原文中输入图片的size是256×256,经过判别器卷积、下采样后输出一张30×30的特征图,这个特征图的每一个点对应的正好是输入图片中一块70×70的区域,也就是所谓patch大小为70×70。
import paddle.fluid as fluid
from paddle.fluid.dygraph import Conv2D, Linear, Dropout, BatchNorm, Pool2D, Conv2DTranspose, InstanceNorm, SpectralNorm
import numpy as np
class Disc(fluid.dygraph.Layer):
def __init__(self):
super(Disc, self).__init__()
self.conv1 = Conv2D(6, 64, 4, stride=2, padding=1, bias_attr=True, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.in1 = InstanceNorm(64)
self.conv2 = Conv2D(64, 128, 4, stride=2, padding=1, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.in2 = InstanceNorm(128)
self.conv3 = Conv2D(128, 256, 4, stride=2, padding=1, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.in3 = InstanceNorm(256)
self.conv4 = Conv2D(256, 512, 4, padding=1, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.in4 = InstanceNorm(512)
self.conv5 = Conv2D(512, 1, 4, padding=1, bias_attr=True, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
def forward(self, x):
x = self.conv1(x)
x = self.in1(x)
x = fluid.layers.leaky_relu(x, alpha=0.2)
x = self.conv2(x)
x = self.in2(x)
x = fluid.layers.leaky_relu(x, alpha=0.2)
x = self.conv3(x)
x = self.in3(x)
x = fluid.layers.leaky_relu(x, alpha=0.2)
x = self.conv4(x)
x = self.in4(x)
x = fluid.layers.leaky_relu(x, alpha=0.2)
x = self.conv5(x)
return x
3.ResNet版生成器
在原版的CGAN中,生成器采用的是先下采样“编码”,再上采样“解码”的encoder-decoder结构。Pix2Pix论文中将这种encoder-decoder结构与U-Net进行了对比,由于U-Net结构使用了多尺度融合的方式进行跨层连接,取得了更好的效果,被Pix2Pix选择用作生成器。但是当大名鼎鼎的ResNet横空出世后,所有的GAN都采用了“残差块”作为部件的ResNet版生成器(包括Pix2Pix的弟弟CycleGAN和以后各种魔改的GAN)。所以我们在这里也采用了ResNet版的生成器,算是让Pix2Pix穿越未来~
# 定义生成器使用的残差块
class Residual(fluid.dygraph.Layer):
def __init__(self, input_output_dim, use_bias):
super(Residual, self).__init__()
name_scope = self.full_name()
self.conv1 = Conv2D(input_output_dim, input_output_dim, 3, bias_attr=use_bias, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.bn1 = BatchNorm(input_output_dim)
self.conv2 = Conv2D(input_output_dim, input_output_dim, 3, bias_attr=use_bias, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.bn2 = BatchNorm(input_output_dim)
def forward(self, x_input):
x = fluid.layers.pad2d(x_input, [1, 1, 1, 1], mode='reflect')
x = self.conv1(x)
x = self.bn1(x)
x = fluid.layers.relu(x)
x = fluid.layers.pad2d(x, [1, 1, 1, 1], mode='reflect')
x = self.conv2(x)
x = self.bn2(x)
return x + x_input
# 定义ResNet版的生成器
class Gen(fluid.dygraph.Layer):
def __init__(self, base_dim=64, residual_num=7):
super(Gen, self).__init__()
self.residual_num = residual_num
self.conv1 = Conv2D(3, base_dim, 7, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.bn1 = BatchNorm(base_dim)
self.conv2 = Conv2D(base_dim, base_dim * 2, 3, padding=1, stride=2, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.bn2 = BatchNorm(base_dim * 2)
self.conv3 = Conv2D(base_dim * 2, base_dim * 4, 3, padding=1, stride=2, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.bn3 = BatchNorm(base_dim * 4)
self.residual_list = []
for i in range(residual_num):
layer = self.add_sublayer('res_'+str(i), Residual(base_dim * 4, False))
self.residual_list.append(layer)
self.convTrans1 = Conv2DTranspose(base_dim * 4, base_dim * 2, 3, stride=2, padding=1, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.bn4 = BatchNorm(base_dim * 2)
self.convTrans2 = Conv2DTranspose(base_dim * 2, base_dim, 3, stride=2, padding=1, bias_attr=False, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
self.bn5 = BatchNorm(base_dim)
self.conv4 = Conv2D(base_dim, 3, 7, bias_attr=True, param_attr=fluid.initializer.NormalInitializer(loc=0, scale=0.02))
def forward(self, x):
x = fluid.layers.pad2d(x, [3, 3, 3, 3], mode='reflect')
x = self.conv1(x)
x = self.bn1(x)
x = fluid.layers.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = fluid.layers.relu(x)
x = self.conv3(x)
x = self.bn3(x)
x = fluid.layers.relu(x)
for res_layer in self.residual_list:
x = res_layer(x)
x = self.convTrans1(x)
x = self.bn4(x)
x = fluid.layers.relu(x)
x = fluid.layers.pad2d(x, [0, 1, 0, 1], mode='constant', pad_value=0.0)
x = self.convTrans2(x)
x = self.bn5(x)
x = fluid.layers.relu(x)
x = fluid.layers.pad2d(x, [0, 1, 0, 1], mode='constant', pad_value=0.0)
x = fluid.layers.pad2d(x, [3, 3, 3, 3], mode='reflect')
x = self.conv4(x)
x = fluid.layers.tanh(x)
return x4.测试判别器与生成器模块
with fluid.dygraph.guard(fluid.CPUPlace()):
# with fluid.dygraph.guard(fluid.CUDAPlace(0)):
img_a = fluid.dygraph.to_variable(np.array(data[0]))
img_b = fluid.dygraph.to_variable(np.array(data[1]))
real_a_real_b = fluid.layers.concat((img_a, img_b), axis=1)
d = Disc()
pred_fb = d(real_a_real_b)
print('判别器输出的Patch的形状:', pred_fb.shape)
r = Residual(3, False)
pred_res = r(img_a)
print('测试残差块输出的形状:', pred_res.shape)
g = Gen()
pred_fb = g(img_a)
print('生成器生成的图片数据的形状:', pred_fb.shape)
show_pics([data[0], data[1], pred_fb.numpy()])判别器输出的Patch的形状:[1, 1, 26, 26]
测试残差块输出的形状:[1, 3, 224, 224]
生成器生成的图片数据的形状:[1, 3, 224, 224]

上面的代码分别打印了Pix2Pix各个部件的输出,左边的是训练集A组街景风格图片,中间的是训练集B组mask掩码风格图片,右边的是刚才定义的生成器生成的B组mask掩码风格图片。可见没经过训练的生成器只能将左边的图片映射成右边的带有一点原图片信息的噪声图片。下面我们开始训练。
5.训练代码
1)街景变蓝图
下面,我们看看街景风格变mask掩码风格的生成效果。执行下面的代码就可以看看我已经训练了5w次迭代的模型的效果了。当然也可以从新训练。不同参数的train函数调用我也都注释后保留了下来。
# scene to mask
import matplotlib.pyplot as plt
%matplotlib inline
import time
reader = data_reader(cfg)
def train(reader, epoch_num=99999, batch_size=1, use_gpu=True, lambda_l1=100, model_path='./model/', \
step_num=50, print_interval=1, load_model=False):
first_iteration = True
place = fluid.CUDAPlace(0) if use_gpu == True else fluid.CPUPlace()
with fluid.dygraph.guard(place):
train_reader, _, batch_num = reader.make_data()
g = Gen()
d = Disc()
ones, zeros = '', ''
g_optimizer = fluid.optimizer.Adam(learning_rate=0.0002, beta1=0.5, beta2=0.999, parameter_list=g.parameters())
d_optimizer = fluid.optimizer.Adam(learning_rate=0.0002, beta1=0.5, beta2=0.999, parameter_list=d.parameters())
if load_model == True:
g_para, g_opt = fluid.load_dygraph(model_path+'g')
d_para, d_opt = fluid.load_dygraph(model_path+'d')
g.load_dict(g_para)
g_optimizer.set_dict(g_opt)
d.load_dict(d_para)
d_optimizer.set_dict(d_opt)
print('Start time :', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
for epoch in range(epoch_num):
for batch, data in enumerate(train_reader()):
real_a = fluid.dygraph.to_variable(np.array(data[0]))
real_b = fluid.dygraph.to_variable(np.array(data[1]))
real_a_real_b = fluid.layers.concat((real_a, real_b), axis=1)
fake_b = g(real_a)
real_a_fake_b = fluid.layers.concat((real_a, fake_b), axis=1)
pred_real = d(real_a_real_b)
pred_fake = d(real_a_fake_b)
if first_iteration == True:
first_iteration = False
ones = fluid.dygraph.to_variable(np.ones(pred_real.shape, 'float32'))
zeros = fluid.dygraph.to_variable(np.zeros(pred_real.shape, 'float32'))
d_loss_real = fluid.layers.sigmoid_cross_entropy_with_logits(pred_real, ones)
d_loss_real = fluid.layers.reduce_mean(d_loss_real, dim=[1, 2, 3])
d_loss_fake = fluid.layers.sigmoid_cross_entropy_with_logits(pred_fake, zeros)
d_loss_fake = fluid.layers.reduce_mean(d_loss_fake, dim=[1, 2, 3])
d_loss = d_loss_real + d_loss_fake
d_loss.backward()
d_optimizer.minimize(d_loss)
d.clear_gradients()
real_a = fluid.dygraph.to_variable(np.array(data[0]))
fake_b = g(real_a)
pic_fake = fake_b.numpy()
real_a_fake_b = fluid.layers.concat((real_a, fake_b), axis=1)
pred_fake = d(real_a_fake_b)
g_loss_fake = fluid.layers.sigmoid_cross_entropy_with_logits(pred_fake, ones)
g_loss_fake = fluid.layers.reduce_mean(g_loss_fake, dim=[1, 2, 3])
g_loss_l1 = fluid.layers.reduce_mean(fluid.layers.abs(real_b - fake_b))
g_loss = g_loss_fake + g_loss_l1 * lambda_l1
g_loss.backward()
g_optimizer.minimize(g_loss)
g.clear_gradients()
if batch % print_interval == 0:
print('epoch:', epoch, ', batch:', batch, ', d_loss_real:', d_loss_real.numpy(), ', d_loss_fake:', d_loss_fake.numpy(), \
', g_loss_fake:', g_loss_fake.numpy(), ', g_loss_l1:', g_loss_l1.numpy())
show_pics([data[0], data[1], pic_fake])
if batch % 10000 == 0 and batch != 0:
fluid.save_dygraph(g.state_dict(), model_path+'g')
fluid.save_dygraph(g_optimizer.state_dict(), model_path+'g')
fluid.save_dygraph(d.state_dict(), model_path+'d')
fluid.save_dygraph(d_optimizer.state_dict(), model_path+'d')
print('Model Saved :', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), batch)
if batch + 1 >= step_num:
fluid.save_dygraph(g.state_dict(), model_path+'g')
fluid.save_dygraph(g_optimizer.state_dict(), model_path+'g')
fluid.save_dygraph(d.state_dict(), model_path+'d')
fluid.save_dygraph(d_optimizer.state_dict(), model_path+'d')
print('End time :', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
return
model_path = './model/scene2mask/'
# 已训练5w steop
# 从头训练
# train(reader, use_gpu=True, step_num=1, model_path=model_path)
# 继续训练
train(reader, use_gpu=True, load_model=True, step_num=5, model_path=model_path)data/data10830/cityscapes/cityscapes data/data10830/cityscapes/pix2pix_train_list
Start time : 2020-11-10 22:17:58
epoch: 0 , batch: 0 , d_loss_real: [0.00385989] , d_loss_fake: [0.18116194] , g_loss_fake: [2.4605167] , g_loss_l1: [0.1725532]
epoch: 0 , batch: 1 , d_loss_real: [0.8069366] , d_loss_fake: [0.20235592] , g_loss_fake: [1.3542936] , g_loss_l1: [0.07160708]
epoch: 0 , batch: 2 , d_loss_real: [0.19419678] , d_loss_fake: [0.40251613] , g_loss_fake: [1.7226954] , g_loss_l1: [0.11683807]
epoch: 0 , batch: 3 , d_loss_real: [0.23289065] , d_loss_fake: [0.7248107] , g_loss_fake: [1.7360678] , g_loss_l1: [0.06112225]
epoch: 0 , batch: 4 , d_loss_real: [0.44663462] , d_loss_fake: [0.7783506] , g_loss_fake: [1.4364344] , g_loss_l1: [0.06217283]
End time : 2020-11-10 22:18:00





效果还不错吧,但还是不如专业的图像分割网络。但是,下面这个玩法分割网络就不灵了~
2)蓝图变街景
如果,刚才同学看了下训练代码部分,就会发现Pix2Pix的训练代码基本上和上一个项目《风格迁移的“精神始祖”Conditional GAN》的训练代码没什么大区别。唯一一个非常重要的不同就是:Pix2Pix的loss函数除了和CGAN一样的对抗损失部分外,还增加了训练集B组图片与生成的B组图片的L1损失。其计算方式就是两张图片逐像素求差的绝对值再求平均。这样做能提高生成图片的质量。分别使用对抗损失和L1损失的具体分析和实验请见原论文《Image-to-Image Translation with Conditional Adversarial Networks》。
感兴趣的小伙伴也可以自己改下下面代码的loss,试验下。我在别的项目中(实际上是大坑中~)已经实验过了,确实如论文所示。这里为了项目的工整就不搬过来了。实验也很简单只需将代码中计算loss的部分
g_loss = g_loss_fake + g_loss_l1 * lambda_l1
分别改为
g_loss = g_loss_fake
和
g_loss = g_loss_l1 * lambda_l1
训练下看看图片效果就行了。其中的lambda_l1参数是调整L1 loss占比的权重值,论文中是100。可以根据数据集的效果自己调节。
# mask to scene
import matplotlib.pyplot as plt
%matplotlib inline
import time
reader = data_reader(cfg)
def train(reader, epoch_num=99999, batch_size=1, use_gpu=True, lambda_l1=100, model_path='./model/', \
step_num=50, print_interval=1, load_model=False):
first_iteration = True
place = fluid.CUDAPlace(0) if use_gpu == True else fluid.CPUPlace()
with fluid.dygraph.guard(place):
train_reader, _, batch_num = reader.make_data()
g = Gen()
d = Disc()
ones, zeros = '', ''
g_optimizer = fluid.optimizer.Adam(learning_rate=0.0002, beta1=0.5, beta2=0.999, parameter_list=g.parameters())
d_optimizer = fluid.optimizer.Adam(learning_rate=0.0002, beta1=0.5, beta2=0.999, parameter_list=d.parameters())
if load_model == True:
g_para, g_opt = fluid.load_dygraph(model_path+'g')
d_para, d_opt = fluid.load_dygraph(model_path+'d')
g.load_dict(g_para)
g_optimizer.set_dict(g_opt)
d.load_dict(d_para)
d_optimizer.set_dict(d_opt)
print('Start time :', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
for epoch in range(epoch_num):
for batch, data in enumerate(train_reader()):
real_a = fluid.dygraph.to_variable(np.array(data[1]))
real_b = fluid.dygraph.to_variable(np.array(data[0]))
real_a_real_b = fluid.layers.concat((real_a, real_b), axis=1)
fake_b = g(real_a)
real_a_fake_b = fluid.layers.concat((real_a, fake_b), axis=1)
pred_real = d(real_a_real_b)
pred_fake = d(real_a_fake_b)
if first_iteration == True:
first_iteration = False
ones = fluid.dygraph.to_variable(np.ones(pred_real.shape, 'float32'))
zeros = fluid.dygraph.to_variable(np.zeros(pred_real.shape, 'float32'))
d_loss_real = fluid.layers.sigmoid_cross_entropy_with_logits(pred_real, ones)
d_loss_real = fluid.layers.reduce_mean(d_loss_real, dim=[1, 2, 3])
d_loss_fake = fluid.layers.sigmoid_cross_entropy_with_logits(pred_fake, zeros)
d_loss_fake = fluid.layers.reduce_mean(d_loss_fake, dim=[1, 2, 3])
d_loss = d_loss_real + d_loss_fake
d_loss.backward()
d_optimizer.minimize(d_loss)
d.clear_gradients()
real_a = fluid.dygraph.to_variable(np.array(data[1]))
fake_b = g(real_a)
pic_fake = fake_b.numpy()
real_a_fake_b = fluid.layers.concat((real_a, fake_b), axis=1)
pred_fake = d(real_a_fake_b)
g_loss_fake = fluid.layers.sigmoid_cross_entropy_with_logits(pred_fake, ones)
g_loss_fake = fluid.layers.reduce_mean(g_loss_fake, dim=[1, 2, 3])
g_loss_l1 = fluid.layers.reduce_mean(fluid.layers.abs(real_b - fake_b))
g_loss = g_loss_fake + g_loss_l1 * lambda_l1
g_loss.backward()
g_optimizer.minimize(g_loss)
g.clear_gradients()
if batch % print_interval == 0:
print('epoch:', epoch, ', batch:', batch, ', d_loss_real:', d_loss_real.numpy(), ', d_loss_fake:', d_loss_fake.numpy(), \
', g_loss_fake:', g_loss_fake.numpy(), ', g_loss_l1:', g_loss_l1.numpy())
show_pics([data[1], data[0], pic_fake])
if batch % 10000 == 0 and batch != 0:
fluid.save_dygraph(g.state_dict(), model_path+'g')
fluid.save_dygraph(g_optimizer.state_dict(), model_path+'g')
fluid.save_dygraph(d.state_dict(), model_path+'d')
fluid.save_dygraph(d_optimizer.state_dict(), model_path+'d')
print('Model Saved :', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), batch)
if batch + 1 >= step_num:
fluid.save_dygraph(g.state_dict(), model_path+'g')
fluid.save_dygraph(g_optimizer.state_dict(), model_path+'g')
fluid.save_dygraph(d.state_dict(), model_path+'d')
fluid.save_dygraph(d_optimizer.state_dict(), model_path+'d')
print('End time :', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
return
model_path = './model/mask2scene/'
# 已训练40w step
# 从头训练
# train(reader, use_gpu=True, step_num=1, model_path=model_path)
# 继续训练
train(reader, use_gpu=True, load_model=True, step_num=5, model_path=model_path)
data/data10830/cityscapes/cityscapes data/data10830/cityscapes/pix2pix_train_list
Start time : 2020-11-10 22:18:12
epoch: 0 , batch: 0 , d_loss_real: [0.17122237] , d_loss_fake: [0.6814326] , g_loss_fake: [1.8777969] , g_loss_l1: [0.09817581]
epoch: 0 , batch: 1 , d_loss_real: [0.86400205] , d_loss_fake: [0.09681298] , g_loss_fake: [2.4242845] , g_loss_l1: [0.12746824]
epoch: 0 , batch: 2 , d_loss_real: [0.05332229] , d_loss_fake: [0.48535496] , g_loss_fake: [2.2860258] , g_loss_l1: [0.1772472]
epoch: 0 , batch: 3 , d_loss_real: [0.08443183] , d_loss_fake: [0.47446522] , g_loss_fake: [2.4390275] , g_loss_l1: [0.11949492]
epoch: 0 , batch: 4 , d_loss_real: [0.19417647] , d_loss_fake: [0.12773074] , g_loss_fake: [3.17816] , g_loss_l1: [0.15548548]
End time : 2020-11-10 22:18:14





总结与思考
-
上面蓝图生成街景的效果看上去还不错。其实我在实现这个Pix2Pix踩了一个不小的坑。坑里的情形就是训练的GAN生成的图片非常模糊,几乎就像是原论中没用L1 loss的情况,图片各种物体没有纹理细节只有边缘的分界。这真是让我困扰了很长时间,甚至耽搁了一个实验对比原版的vanilla gan、lsgan和wgan-gp项目。后来发现这个坑是我自己挖的(哭脸)。我直接使用了Paddle代码库里的数据读取模块,发现这个模块使用了“随机裁切”的方式每次读取图片的某部分来增强GAN的效果,这个trick在一些文章中也被提及,算是一种数据增强方法。所以我就开(悲)心(催)地将读取器的load_size(图片读取后统一resize的尺寸)由原来的256改成了286,因为原来crop_size(随机裁切尺寸)也是设的256。那样,就没法应用随机裁切的效果了。但是,原数据集的尺寸就是256×256的,这样一改,不知是因为resize插值方式的原因还是什么其他的,导致了生成图片的模糊。后来我将load_size改回图片数据的原生尺寸256×256,减小crop_size的尺寸为224×224后,生成的图片就清晰了。其实,开始我选择改大load_size,而不是改小crop_size也是有原因的。因为原论文判别器输入的图片尺寸就是256×256,相应的输出尺寸就是30×30。论文分析这个输出的30×30特征图正好对应输入尺寸为70×70的一片区域。我也是为了和原论文的数据对齐,才不小心踩了这个坑。出坑的结论就是,训练GAN时,处理图片绝对不要用resize啊。可能不同的插值方式会影响GAN学习图片高频部分的像素概率分布吧,我猜~~
-
如果要求高的话,Pix2Pix生成图片的细节还是不够清晰,即使用了PatchGAN和随机裁切也不够好,原因就是随着生成图片的尺寸越来越大,对GAN判别、生成能力的也要求越来越高。也许(说“也许”是因为,原本打算下面搞下CycleGAN~)下一个项目我们就实现下靠多尺度生成解决Pix2Pix清晰度问题的Pix2PixHD网络。
-
随着玩过的GAN越来越多,我发现GAN在生成人类不易察觉的细节信息的能力还是不错的(也可能只是心里上的错觉~),但在宏观认知水平上的生成“破绽”往往比较明显。比如这个例子中生成一坨树或建筑的远景图片还说得过去,但要是生成比较近距离的图片时,你会发现树可能没有主干、建筑可能是个悖论,尤其地上的标线更是奇怪(像撒出来的面条)~。即使小朋友画一只猫的细节很难画像,但绝不会画两张嘴、四只眼睛。而GAN的能力和小朋友们正相反。我想这也可能是下一阶段GAN网络要解决的问题吧。另外,现在基础网络的研究又有了许多新成果,都可以应用到GAN中,比如多尺度、注意力、裁剪等,GAN网络经各种加持后会有更加惊艳的效果吧。欢迎各位大佬同学一起交流、探讨!
现在有了PaddleGAN这个“神器”,GAN的活再也不用自己干~附上炼丹套件地址:
https://github.com/PaddlePaddle/PaddleGAN/blob/master/docs/zh_CN/tutorials/pix2pix_cyclegan.md
学习官方大佬优雅的代码风格也是能给自己涨点的啊~
更多阅读:
《四天搞懂生成对抗网络(一)——通俗理解经典GAN》
《四天搞懂生成对抗网络(二)——风格迁移的“精神始祖”Conditional GAN》
如在使用过程中有问题,可加入飞桨官方QQ群进行交流:1108045677。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·飞桨PaddleGAN项目地址(欢迎Star)·
GitHub:
https://github.com/PaddlePaddle/PaddleGAN
Gitee:
https://Gitee.com/PaddlePaddle/PaddleGAN
·飞桨官网地址·
https://www.paddlepaddle.org.cn/