2020多媒体信号处理复习笔记
一丶Course Introduction
1.什么是信号处理?
信号处理是系统工程,电气工程和应用数学领域中涉及的
- 领域模拟或数字信号的操作或分析,
- 代表时间变化或空间变化的物理量。
典型的操作和应用
- 信号采集与重建
- 信号压缩(源编码)
- 特征提取,例如 图像理解
- 质量提升,例如 降噪,图像增强等
2.涉及内容
多媒体信号处理和压缩简介
- 音频处理和压缩 WAVE, ADPCM, MP3 and AAC
- 图像处理和压缩 JPEG, GIF
- 视频处理和压缩 H.264
音频和视频容器
- AV流容器:AVI,MP4等
010编辑
3.数据压缩
数据压缩,源编码或比特率降低涉及使用比原始表示更少的比特对信息进行编码。
无损压缩通过识别和消除统计冗余来减少比特。 无损压缩不会丢失任何信息。
- LZW,霍夫曼编码,算术编码
有损压缩通过识别不必要的信息并将其删除来减少比特。
- 量化,JPEG
4.数字容器格式
容器或包装器格式是图元文件格式,其规范描述了计算机文件中不同数据元素和元数据如何共存。容器文件用于标识和交错不同的数据类型。
容器格式可以支持多个音频和视频流,字幕,章节信息和元数据,以及一起播放各种流所需的同步信息。
(选择题)
容器格式的各个部分具有不同的名称:
- RIFF和PNG中的“块”,
- QuickTime / MP4中的“原子”,
- MPEG-TS中的“数据包”(来自通信术语),
- JPEG中的“段”。
一些容器是音频专有的:
- AIFF(IFF文件格式,在Mac OS平台上广泛使用)
- WAV(RIFF文件格式,在Windows平台上广泛使用)
- XMF(可扩展音乐格式)
其他容器是静态图像专用的:
- TIFF(标记图像文件格式)静止图像和关联的元数据。
其他灵活的容器可以容纳多种类型的音频和视频以及其他媒体:
- 3GP(许多手机使用;基于ISO基本媒体文件格式)
- ASF(Microsoft WMA和WMV的容器)
- AVI(标准的Microsoft Windows容器)
- Flash Video(FLV,F4V)(来自Adobe Systems的视频和音频容器)
- Matroska(MKV)(不限于任何编解码器或系统,)
- MJ2-Motion JPEG 2000文件格式。
- QuickTime文件格式(Apple的标准QuickTime视频容器)
5.010编辑
010编辑器是具有二进制模板技术的专业文本和十六进制编辑器。
- 文本编辑器:编辑文本文件,XML,HTML,Unicode和UTF-8文件,C / C++源代码等。无限的撤消功能以及强大的编辑和脚本编写工具。
- 十六进制编辑器:无与伦比的二进制编辑性能。 编辑任何大小的文件。 使用强大的二进制模板技术来了解二进制数据。
- 磁盘编辑器:使用硬盘驱动器,存储密钥,闪存驱动器,CD-ROM等查找和修复程序。
- 流程编辑器:调查和修改流程中的内存。
6.Audio Format
未压缩的音频格式
- WAVE,AIFF,Raw PCM
无损压缩格式
- FLAC, Monkey’s audio (APE extension), Shorten, WMA Lossless,
有损压缩格式
- MP3,AAC,WMA,AC3
7.Video Format
- MPEG-1
- MPEG-2
- MPEG-4 visual/AVC
- H.261
- H.263
- H.264
视频压缩标准的历史(用途重点!!!)

8.Audio and Video Container
- AVI
- MP4
- ASF
- FLV
- SWF
- 3GP
- RMVB
- Quicktime
二丶AVI Walk Through
0.Windows Bitmap File Structure
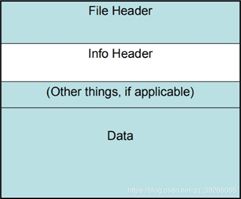


bfOffBits是从位图文件头到位图数据的偏移量”指的就是,位图信息头(BITMAPINFOHEADER)+全部颜色对照表(RGBQUAD)的字节数。
重点:bfType:BM 、bfSize文件长度 、offbits偏移
宽度、高度、biBitCount每个像素bit数 、biClrUsed色彩索引数
1. Windows Bitmap Data
- 数据由代表位图的连续行或扫描线的字节值数组组成。
- 每条扫描线由连续的字节组成,这些字节按从左到右的顺序代表扫描线中的像素。
- 代表扫描线的字节数取决于位图的宽度。
- 如果需要,扫描线必须补零以在32位边界结束。
- 这意味着宽度为8位,20位或30位的单色位图将具有相同的扫描线大小:32位
- 40位宽的单色位图将具有64位的扫描线大小。
- 位图中的扫描线是从下往上存储的。
- 这意味着数组中的第一个字节代表位图左下角的像素,最后一个字节代表右上角的像素。
2. 灰度位图 Greyscale Bitmaps
- 每个像素使用8位(即1个字节)
- 请注意,Info标头的biBitCount字段将为8
- 每个字节代表256个灰色阴影。
- 白色为“ ff”
- 黑色为“ 00”
- 中间的数字表示从白色到黑色的几种灰色阴影。
3. 24-bit Colour Bitmap (RGB)
- 每个像素使用24位(即3个字节)
- 请注意,Info标头的biBitCount字段将为24。
- 每个像素都有3个字节,分别代表红色,绿色和蓝色。
- 白色是“ ffffff”
- 黑色是“ 000000”
- 红色是“ ff0000”
- 绿色是“ 00ff00”
- 蓝色是“ 0000ff”
4. 8-bit Colour Bitmap (索引)
- 每个像素使用8位。 只能使用256种颜色
- 使用哪种颜色?
- 使用一个称为调色板的颜色表来选择要使用的颜色
- 在一个位图中,颜色0可以是“浅橙色”,颜色1可以是“深棕色”
- 在另一种颜色中,颜色0可以是“淡黄色”,而 颜色1可能是“深红色”
- 颜色表位于信息标题和数据之间
- 每个条目有4个字节(R,G,B,0x0)
5.The Colour Table

6.Greyscale Bitmaps Revisited(8-bit 特例)
- 这些实际上是8位彩色位图的特殊情况。
- 存在一个颜色表,其中条目0指向黑色,条目255指向白色,而介于两者之间的条目指向灰色阴影。(而8-bit指向的彩色)
- 对于给定大小的图像,8位灰度位图和8位彩色位图的大小相同。
7.The WAV Format
- WAV文件格式是一种用于存储数字音频(波形)数据的简单文件格式。
- 它支持各种位分辨率,采样率和音频通道。
- 此格式在Windows平台上很流行,并广泛用于处理数字音频波形的程序中。
- WAV文件是许多不同类型的块的集合。
- 有一个必需的格式**(“ fmt”)块**,其中包含描述波形的参数,例如采样率。还需要包含实际波形数据的数据**(“data”)块**。所有其他块都是可选的。
The WAV Format

RIFF(Resource Interchange File Format):资源文件交互的格式,代表资源可以共享交互,
Big Chunk Size :文件大小,但并不包括头部
- 所有使用WAV的应用程序都必须能够读取2个必需的块(FMT+DATA),并且可以选择有选择地忽略可选的块。
- 复制WAV的程序应复制WAV中的所有块,即使是选择不解释的块也是如此。
- 对WAV文件中的块顺序没有任何限制,但格式块必须位于数据块之前。
- 请注意,格式块可能不是第一个块。
(一个WAV文件通常有三个chunk以及一个可选chunk,其在文件中的排列方式依次是:RIFF chunk,Format chunk,Fact chunk(附加块,可选),Data chunk) - 所有数据都以8位字节存储,以小端格式排列。
- 多字节值的字节首先与低序(即最低有效)字节一起存储。
- 请注意,“数据块”与“块数据”不同。
- “数据块”具有“块大小”和一些“块数据”。
- 其他所有块也是如此。
Format tag 数据格式
- 例如:0X01 PCM 、0X02 ADPCM 、0X55 MP3(重点)
The Format Chunk

Channels通道(momo 单通道 、stereo 多通道)
Samples per second 抽样速率 (标准:44.1KHZ 48KHZ 32KHZ 22.05KHZ 96KHZ)
Average bytes per second 每秒多少个字节
Block align
- 例如3个未压缩的通道组成一个块,每个通道2个字节,则Block align为6
Bits per sample 每个音频信号位数
8.The AVI Format
-
AVI是Microsoft开发的另一种资源交换文件格式(RIFF)
-
代表音频视频交织
-
格式将文件中的视频和音频数据交织(即,一段视频数据后面紧跟着一段音频数据。)
- 交织允许媒体播放器以块形式读取而不是读取数据整体。



dwMicroSecPerFrame 每帧多少微秒
dwMaxBytesPerSec 每秒多少个字节(不重要)
dwFlags 标签,有没有索引或者必须使用索引等
dwTotalFrames 文件一共多少帧
dwInitialFrams 视频初始帧,视频通常会延迟,会有初始帧(可忽略)
dwStreams 多少数据流(例如音频流,视频流)
dwSuggestedBufferSize 解压时需要缓冲区大小
dwWidth dwHeight 视频图像的高度和宽度
AVIStreamHeader

fccType = vids 代表一个视频流 (auds代表音频流)
fccHanldler = mp4v 代表压缩格式
wflags 是否使用色彩表,有没有改变,真彩色压缩通常是不需要的
dwinitialFrames 音频不同步,会有一些初始帧
dwRate/dwScale 代表视频一秒多少帧/音频一秒多少抽样信号
Data LIST

注意AVI是Wave格式,必须以两个字节对齐,填充。解码时不需要考虑填充的数据。
- 数据块可以直接驻留在“ movi”列表中,也可以分组在“ rec”列表中。
- 标识每个数据块的FOURCC包含一个two_x0002_digit流编号,后跟一个两个字符的代码,用于定义块中信息的类型。
“ db”:未压缩的视频帧
“ dc”:压缩的视频帧
“ wb”:音频数据
AVIIdx1Entry (索引)

- dwFlags:是不是关键帧?
T/F questions
1.MPEG-1 is used in DVD. (F)
MPEG-1 is used in VCD ,MPEG-2 is used in DVD
2.MP3 is a lossy compression method. (T)
3.WMA is a video file format(container). (F)
4.H.261 is used in VCD.(F)
H.261主要用于可视电话
5.TIFF is an audio file container.(F)
TIFF是图像文件格式
6.In BMP a scan line must be zero-padded to end on a 32-bit boundary.(T)
三丶Audio Coding Basics
1.什么是数字音频编码

数字音频编码器是一种设备:
- 将模拟音频信号作为输入
- 将它们转换为方便的数字表示形式(编码器)
- 之后,我们可以存储,处理或传输它
- 当我们想收听音频时,我们将数字数据转换回模拟信号(解码器)
2.音频编码目标
- 保真度:最大化音频解码器的感知音频质量(最小化失真)。
- 数据速率:最小化代表原始音频信号的数字数据量。
- 复杂度:将计算复杂度降至最低。
- 延迟:最小化编码延迟。
3.The Simplest Coder–PCM
参考资料:脉冲调制编码

- 量化是一个有损过程,原始信号中包含的某些信息会丢失。
- 量化过程中使用的离散值数量越多,输出信号将越接近输入信号越精确。
4. Compact Disk (CD)
- Sony在80年代中期由Sony和Phillips引入。
- 音频信号被数字表示为以0.023ms的时间间隔或44.1kHz的采样频率采样的立体声信号。
- CDCD中每个样本的位数R为16位。此精度允许65536个离散级别代表音频采样幅度
- The data rate of the CD is : 44.1 * 16 *2 = 1.4112 Mb/s
- 抽样速率每秒44.1
- 每个信号16位
- 2个通路
5.WAVE Format
- 使用RIFF结构将文件内容分为不同的块:
- 样本格式
- 音频数据
- 每个块均由标头和数据字节组成。
- Header指定块数据字节的类型和大小。
- 某些类型的块可能包含子块。
- RIFF文件块必须字对齐。
Format Chunk (WAVEFORMATEX)
Format(fmt)块描述了波形数据的基本参数,例如采样率,位分辨率和通道数。
注意:可能还有其他字段,具体取决于wFormatTag。
wFormatTag (重点)
- WAVE_FORMAT_PCM 0x0001
- WAVE_FORMAT_ADPCM 0x0002 自适应差分脉冲编码调制
- WAVE_FORMAT_ALAW 0x0006 (电话格式)
- WAVE_FORMAT_MULAW 0x0007 (电话格式)
- WAVE_FORMAT_MP3 0x0055
Data Chunk
数据块包含实际的采样帧(即波形数据的所有通道)。
typedef struct {
ID chunkID;
long chunkSize;
unsigned char waveformData[ ];
} DataChunk;
隔行立体声波样本(Interlaced Stereo Wave Samples)
多通道样本存储为隔行波数据; 8位样本使用无符号数据表示,而其他样本使用有符号表示。
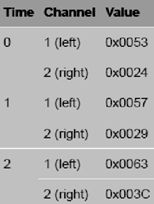

假设存在两个通路,先存放time1的左通道和右通道数据,再存放time2,以此类推。
WAVEFORMATEXTENSIBLE
typedef struct {
WAVEFORMATEX Format;
union {
WORD wValidBitsPerSample;
WORD wSamplesPerBlock;
WORD wReserved;
} Samples;
DWORD dwChannelMask;
GUID SubFormat;
} WAVEFORMATEXTENSIBLE
/*
用于具有两个以上通道或更高分辨率的音频数据
wFormatTag= FFFE
cbSize= 24
/*
- wValidBitsPerSample:信号精度的位数。
假设使用24bit,但只前20位有效,则wValidBitsPerSample=20 - SwSamplesPerBlock:一个音频数据压缩块中包含的样本数。
一个块多少个抽样信号,在ADPCM压缩时,会将信号组成块,或在(WMA中); - dwChannelMask:位掩码,指定流中的声道分配给扬声器位置。

- SubFormat:为每种类型的波形数据定义一个ID。例如WMA中不同压缩方式
Examples: 6 Channels in 5.1 Format
WAVEFORMATPCMEX waveFormatPCMEx;
wFormatTag = WAVE_FORMAT_EXTENSIBLE;//FFFE
wChannels = 6;
dwSamplesPerSec = 48000L;
dwAvgBytesPerSec = 864000L; // nBlkAlign * nSamp/Sec = 48000 * 18
wBitsPerSample = 24; //Container has 3 bytes
cbSize = 22;
wValidBitsPerSample = 20; // Top 20 bits have data
dwChannelMask = KSAUDIO_SPEAKER_5POINT1;
// SPEAKER_FRONT_LEFT | SPEAKER_FRONT_RIGHT |
// SPEAKER_FRONT_CENTER |SPEAKER_LOW_FREQUENCY |
// SPEAKER_BACK_LEFT | SPEAKER_BACK_RIGHT
SubFormat = KSDATAFORMAT_SUBTYPE_PCM; // Specify PCM
6. 潜在的编码错误
- 抽样错误 - 混叠效果 (抽样速率小于二倍带宽)
- 量化错误
- 过载噪声
- 截取噪声
- 存储和传输错误
7. A More Complex Coder
- 心理声学研究表明,理想情况下,每个样本需要18-20位来描述中频(2至5kHz)的音频样本。
A More Complex Coder: An Example

- 感知冗余
- 某块数据4bit,另一块18bit,存在bit分配的策略
- 统计冗余
- 例如 1111111111 可以使用 1,10。两个字节来表示
8.Lossy Compression

- X 1 X 2 . . . X n X_1X_2...X_n X1X2...Xn是实数随机序列。
- X 1 ^ X 2 ^ . . . X n ^ \hat{X_1}\hat{X_2}...\hat{X_n} X1^X2^...Xn^与 X 1 X 2 . . . X n X_1X_2...X_n X1X2...Xn不同,但必须满足给定的再现质量(保真度)。
- 有损压缩是通过量化实现的。
9.Quantization
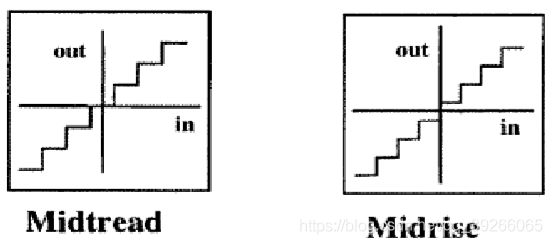
- Midtread(中平!)有零电频输出,而Midrise(中升!)则没有。
- 如果R位代表最多 2 R 2^R 2R个不同的编码/样本,则Midtread允许 2 R − 1 2^R-1 2R−1个不同的编码,而Midrise允许 2 R 2^R 2R个编码。
- 一般而言, Midtread量化器产生更好的结果。因为小电频通常为噪声,Midtread会过滤掉。
10.均匀量化 Uniform Quantization
- input将相等大小的输入幅度范围映射到每个代码上。
- 要定义输入范围,从而定义量化器本身,需要三项信息:
- 量化器是 Midtread还是Midrise;
- 最大非过载输入值 X m a x X_{max} Xmax;
- 描述编码需要位数。
- 对于Midrise量化器,R位允许我们设置输入
Δ = 2 ∗ X m a x / 2 R \Delta = 2 \ast X_{max}/2^R Δ=2∗Xmax/2R - 对于Midtread量化器
Δ = 2 ∗ X m a x / ( 2 R − 1 ) \Delta = 2 \ast X_{max}/(2^R-1) Δ=2∗Xmax/(2R−1)

以Midrise为例
量化时,例如当前number=0.6,当R=2时,s=0, 2 R − 1 ∣ n u m b e r ∣ = 1.2 2^{R-1}|number|=1.2 2R−1∣number∣=1.2,INT(1.2)=1,则最终结果为:01
解码时,当前为01,则sign=1,$(|code|+0.5)/2^{R-1}=(1+0.5)/2=3/4
11.Nonuniform Quantization
- 均匀量化器的最大舍入误差等于分档宽度的一半( △ △ △/ 2)。
- 但是,相对于非常低的幅度信号,此误差可能会很大。
- 由于截取失真的感知与相对误差更相关,因此这意味着均匀量化器在低功率输入信号上的表现要比在高功率信号上的差得多。
- 要解决此问题,可以使用非均匀量化。
A companding method for nonuniform quantization

12.Companding Methods
- 幂律压扩
c p o w e r ( ∣ x ∣ ) = ∣ x ∣ p c_{power}(|x|)=|x|^p cpower(∣x∣)=∣x∣p
在AAC和MP3中0 - 对数压扩 (电话)
c μ ( ∣ x ∣ ) = l o g b ( 1 + μ ∣ x ∣ ) l o g b ( 1 + μ ) c_\mu(|x|)={log_b(1+\mu|x|) \over log_b(1+\mu) } cμ(∣x∣)=logb(1+μ)logb(1+μ∣x∣)
Quantization Errors
- 量化误差: q ( t ) = x o u t ( t ) – x i n ( t ) q(t)= x_{out}(t)–x_{in}(t) q(t)=xout(t)–xin(t)
- 信噪比:
S N R = 10 l o g 10 ( < x i n 2 > / < q 2 > ) SNR = 10 log_{10}( - 低量化误差对应于高SNR。
Round-off Error
- 截取误差来自输入信号幅度范围到单个编码的映射。
- 映射到单个编码的输入幅度范围越广,舍入误差越差。
- 在统一量化和高速率量化的情况下,
< q 2 > ≈ x m a x 2 3 ∗ 2 2 R
Overload Errorq
- 过载噪声来自信号幅度,该幅度对于量化器而言太高。
- 也就是说,误差来自输入幅度大于量化器最大幅度 x m a x x_{max} xmax的信号。
- 过载噪声倾向于以突发(削波)的形式出现,并带有可听见的效果。
- 我们希望将 x m a x x_{max} xmax设置足够大以避免削波,但是,这会引入较大的截取误差。
- 量化器设计要求在减少两种类型的误差之间取得平衡。
13.Lossless Compression—Entropy Coding 熵编码
- 除了量化,我们还可以使用熵编码的思想进一步降低比特率。
- 在熵编码中,我们将量化代码转换为不同的符号表示形式,每个符号使用可变数量的位。
- 我们使通用代码更短,以使平均比特率下降。 这需要估计每种可能代码的概率。
Example
考虑具有代码[00],[01],[10],[11]的2bit量化信号。 q
假设每个代码的概率分别为70%,15%,10%,5%。
考虑使用以下映射:[00]-> [0],[01]-> [10],[10]-> [110]和[11]-> [111]。
此新映射的信号平均比特率较低:R = 0.7 *1 + 0.15 * 2 + 0.15 * 3 = 1.45位/码
Entropy 熵
- 熵代表编码极限,可以表示为: E n t r o p y = ∑ n c o d e s p n l o g 2 ( 1 / p n ) Entropy = \sum_n^{codes}p_nlog_2(1/p_n) Entropy=n∑codespnlog2(1/pn)
- 当我们非常确定接下来会出现什么代码时,熵将很低。
- 如果我们对接下来将要发布的代码一无所知,那么熵会很高。
T/F questions
ln AVI container
1.What does fourcc code “vids” stands for?
2.What does fourcc code “auds” stands for?
3.What does fourcc code “00db” stands for?
4.What does fourcc code “01wb” stands for?
熵与p的关系

对于2码符号,熵等于:
H ( x ) = − p l o g 2 p – ( 1 − p ) l o g 2 ( 1 − p ) H(x)= -plog_2p –(1-p)log_2(1-p) H(x)=−plog2p–(1−p)log2(1−p)
- 当p = 0或1时,熵为零。我们确定知道下一个代码是什么,我们不需要发送任何位。
- p当p = 0.5时,熵等于1,这意味着需要一位来区分两个结果。
对于其他概率,存在可以使用平均每个代码符号少于1位来编码的方案。当所有代码符号均等可能时,熵的最大值就会出现。在这种情况下,采用熵编码不会节省任何费用。
- 示例: 2 R 2^R 2R个相等概率代码符号的熵。
14.Huffman Coding 霍夫曼编码
霍夫曼编码用于编码或压缩传真,ASCII文本等数据。由David A. Huffman博士于1952年提出“构建最小冗余码的方法”。 霍夫曼编码是统计编码的一种形式,它是一种最佳的无记忆编码C,以使C的平均码字长度最小。代码字的长度会有所不同,对于更常用的字符,其长度会更短。
霍夫曼编码算法
a)将两个概率最小的符号合并为一个概率等于两个最小概率之和的符号。
b)重复a)直到剩下一个符号。

我们得到一个二叉树,其中终端节点代表原始符号,所有其他节点代表合并符号。
c)将从每个非终端节点发出的两个分支(叶)标记为0和1。 x j x_j xj的代码字是从根到与 x j x_j xj对应的终端节点读取的二进制序列
1)霍夫曼编码过程不是唯一的。 标记分支的不同方法和合并符号的不同选择将产生不同的前缀代码。
2)如果符号分布不是等概率的,霍夫曼编码可以比固定比特编码减少比特。
3)霍夫曼码中每个样本的平均位数在熵的一位以内:
E n t r o p y ≤ < R > H u f f m a n ≤ E n t r o p y + 1 Entropy ≤
四丶WAVE MS-ADPCM
1、PCM脉冲编码调制(Pulse Code Modulation,PCM),由A.里弗斯于1937年提出的,这一概念为数字通信奠定了基础,60年代它开始应用于市内电话网以扩充容量,使已有音频电缆的大部分芯线的传输容量扩大24~48倍。
2、ADPCM (ADPCM Adaptive Differential Pulse Code Modulation),是一种针对16bit (或者更高) 声音波形数据的一种有损压缩算法,它将声音流中每次采样的 16bit 数据以 4bit 存储,所以压缩比1:4。而压缩/解压缩算法非常的简单,所以是一种低空间消耗,高质量声音获得的好途径。
1.ADPCM
ADPCM或差分脉冲编码调制:编码器使用PCM的基线,但基于采样信号的预测添加了一些功能。不是直接传输原始PCM样本,而是在ADPCM中传输基于先前传输的样本的原始样本和预测值之间的差,例如
d i f f = x n + 1 – x p n + 1 diff = x_{n + 1}–xp_{n + 1} diff=xn+1–xpn+1
其中 x p n + 1 = a x n + b x n − 1 xp_{n + 1} = ax_n + bx_{n-1} xpn+1=axn+bxn−1
2. MS-ADPCM
diff通常很小。为了节省存储和传输空间,我们必须将其表示限制在一定范围内,例如从16位到4位。
但是,由于传输信号有时会发生急剧变化,因此我们不能总是保证差异总是很小。
为解决此问题,引入了变化系数iDelta。 如果差异很大,则iDelta会很大,反之亦然。
然后定义一个新的差异iErrordata = diff / iDelta。这样,新的差异将保持稳定。
iErrordata保存为4位,称为“nibble”。 半字节的范围是-8到7。每次生成新的iErrordata时,iDelta都会相应更改。
iDelta = iDelta * AdaptableTable[(unsigned)nibble]/256;
const int AdaptationTable[ ] = {
230, 230, 230, 230, 307, 409, 512, 614,
768, 614, 512, 409, 307, 230, 230, 230 };
typedef struct adpcmcoef_tag{
int16 icoef1; // predction coefficient
int16 icoef2; // predction coefficient
} adpcmcoefset;
acoeff:预测系数
它们可以解释为定点8.8的有符号值。有7个预设系数集,并且必须按以下顺序出现。

typedef struct adpcmwaveformat_tag{
waveformatex wfxx;
word wsamplesperblock; // number of samples per block
word wnumcoef; // number of predction coefficient sets
adpcmcoefset acoeff[wnumcoef];
} adpcmwaveformat;
Wsamplesperblock
= (wBlockAlign-7*wChannels)*8/(wbitspersample * wChannels)+2

在MS-ADPCM波形文件中,除了格式块和数据块以外,还有另一个块,称为事实块,用于存储样本的长度。
在数据块中,数据一一存储为块。 Block块包含三个部分,头,数据和填充。
Block Header
typedef struct adpcmblockheader_tag {
byte bpredictor[nchannels];
int16 idelta[nchannels];
int16 isamp1[nchannels];
int16 isamp2[nchannels];
} adpcmblockheader;
字段描述
- bpredictor:index到acoef数组中,以定义用于对该块进行编码的预测变量。
- Idelta:要使用的初始增量值。
- Isamp1:块的第二个采样值。
- Isamp2:块的第一个样本值。
3. 编码过程
对于每个通道的每个块:
- 确定要用于该块的预测变量。
- 确定块的初始idelta。(保证差异总很小)
- 写出块头。
- 编码并写出数据。
块标题写入
一旦选择了预测值和起始量化值,就可以按以下方式写入块标题:
- 写下预测值的选择(针对每个通道)。
- 写出初始idelta(量化比例)(针对每个通道)。
- 写出第二个样本(isamp1)的16位PCM值(针对每个通道)。
- 最后,第一个样本(isamp2)(每个通道)的16位PCM值被写出。
然后可以对该块的其余部分进行编码。请注意,第一个编码值将是该块中的第三个样本,前两个包含在标题中。
当块中有更多样本要编码时,使用以下步骤:
- 1)从前两个样本中预测下一个样本。
lpredsamp =((isamp1 * icoef1)+(isamp2 * icoef2))/ fixed_point_coef_base - 2)然后生成4位带符号错误增量,并防止了上溢/下溢。
ierrordelta =(sample(n)-lpredsamp)/ idelta
将ierrordelta裁剪为[-8,7]的范围。 - 3)然后写出半字节ierrordelta:putnibble(ierrordelta)
- 4)将“预测误差”添加到预测的下一个样本中,并防止出现上溢/下溢错误。
lnewsamp = lpredsample +(idelta * ierrordelta);
将数据限制为短类型(16位) - 5)调整用于计算“预测误差”的量化步长。
idelta = idelta * adaptivetable [ierrordelta] / fixed_point_adaption_base
如果idelta太小,则使其成为最小允许值。 - 6)更新以前的样本记录。
isamp2 = isamp1;
isamp1 = lnewsample
步骤5,目的是自适应量化步长。步骤4.6是为了保持和解码端一致,真正预测时是通过编码解码后的信号。此时和解码端保持一致,使误差不会太大。
T/F questions
1.What is audio CD rate?
44.1KHZ × 2 × 16bit/s = 1.411 Mbit
2.What are audio coding goals?
delity,rate,complexity,delay
3.List the components of a chunk.
header,data
4.ln which scemarops is wFormatTag equal to -2 in a WAVE file?
音频通道大于2,每一个抽样信号大于16bit
5.What kind of quantization errors are there in audio coding?
overlode,round-off
6.What is the average number of bits per sample in a Huffman code?
∑ P ( s i ) R : \sum P(s_i) R: ∑P(si)R:
五丶Image and Video Coding Basics
介绍在时间,空间和频域中消除冗余。
人眼和大脑(人类视觉系统)对低频更为敏感。 尽管已删除了许多信息,但仍可以识别该图像。
下图是视频序列中的连续帧。以每秒25帧的速度捕获序列。 两个框架之间几乎没有差异。显然存在明显的时间冗余,即大多数图像在连续帧之间保持不变。


(统计上的冗余度)通过使用熵编码方案对处理后的数据进行编码,可以实现进一步的压缩。 图像和视频压缩一直是研究和开发的活跃领域,已有20多年的历史,并且已经开发了许多不同的压缩系统和算法。有必要定义标准的压缩方法,以使不同制造商的产品有效地进行通信。这导致了图像和视频压缩国际标准的发展,包括JPEG,MPEG和H.26×标准。
视频编码的四种冗余度?
时间,空间,感知,统计
1.自然视频场景
典型的“真实世界”或“自然”视频场景是由多个对象组成的,每个对象都有自己独特的形状,深度,纹理和照明。 自然视频场景的颜色和亮度会在整个场景中以不同程度的平滑度变化(“连续色调”)。 与视频处理和压缩相关的典型自然视频场景的特征包括:
- 空间特征,例如,场景内的纹理变化,对象的数量和形状,颜色等;
- 时间特性,即物体运动,照明变化,相机或视点的运动等。
A typical natural video scene

2.捕获
自然的视觉场景在空间和时间上是连续的。 以数字形式表示视觉场景涉及:
- 在空间上对真实场景进行采样(通常在视频图像平面中的矩形网格上);
- 对临时场景进行临时采样(作为一系列静止帧或以规则的时间间隔采样的帧的组成部分)。
数字视频是数字形式的采样视频场景的表示。 每个样本(像素)表示为描述亮度(亮度)和颜色的数字或一组数字。
为了获得2D采样的图像,相机将视频场景的2D投影聚焦到传感器上,例如电荷耦合器件(CCD)阵列。 对于彩色图像,每种颜色成分都会分别过滤并投影到CCD阵列上。 CCD阵列的输出是模拟视频信号,是表示视频图像的变化的电信号。
3.Spatial Sampling 空域采样
在某个时间点对信号进行采样会生成在一组采样点处具有已定义值的采样图像或帧。 采样图像的最常见格式是矩形,采样点位于正方形或矩形网格上。具有两个不同采样网格的连续色调帧。

在每个相交点处发生采样,并且可以通过将每个采样表示为正方形像素(像素)来重构采样图像。 图像的视觉质量受采样点数量的影响。
“粗略”采样会生成低分辨率的采样图像(左图),而增加采样点的数量会略微提高采样图像的分辨率(右)。
4.Temporal Sampling 时域采样
通过以周期性的时间间隔对信号进行矩形“快照”来捕获运动视频图像。 播放一系列帧会产生运动感。 更高的时间采样率(帧速率)使视频场景中的运动看起来更平滑,但需要捕获和存储更多的样本。 每秒10帧以下的帧速率用于非常低的比特率视频通信(数据量相对较小),但在此速率下运动显然是不平稳的且不自然的。
对于低比特率视频通信,每秒10帧和20帧更为典型。 图像更平滑,但在序列的快速移动部分中可能会看到抖动的运动。 以每秒25或30个完整帧进行采样是电视图像的标准配置。 每秒50或60帧产生平滑的视在运动(以非常高的数据速率为代价)。
5.Color Spaces
大多数数字视频应用程序都依赖于彩色视频的显示,并且需要一种机制来捕获和表示彩色信息。 单色图像只需一个数字即可表示每个空间样本的亮度或亮度。 另一方面,彩色图像在每个像素位置至少需要三个数字才能准确表示颜色。 选择用来表示亮度(亮度或亮度)和颜色的方法称为色彩空间。
5.1 RGB Color Space
在RGB颜色空间中,彩色图像样本用三个数字表示,这些数字指示红色,绿色和蓝色的相对比例。 可以通过将红色,绿色和蓝色以不同的比例组合来创建任何颜色。
RGB色彩空间非常适合捕获和显示彩色图像。捕获RGB图像涉及滤除场景中的红色,绿色和蓝色分量,并使用单独的传感器阵列捕获每个分量。
彩色阴极射线管(CRT)和液晶显示器(LCD)通过根据每个像素的强度分别照射每个像素的红色,绿色和蓝色成分来显示RGB图像。单独的组件合并以呈现“真”颜色。
5.2 YCbCrColor Space
人类视觉系统(HVS)对颜色的敏感性不如对亮度(亮度)的敏感性。在RGB颜色空间中,这三种颜色同等重要,因此通常都以相同的分辨率存储。为了更有效地表示彩色图像,我们将亮度与颜色信息分开,并以比彩色更高的分辨率表示亮度。YCbCrcolor空间是一种有效表示彩色图像的流行方法。 Y是亮度(亮度)分量,可以计算为R,G和B的加权平均值,
Y = k r R + k g G + k b B Y=k_rR+k_gG+k_bB Y=krR+kgG+kbB
可以在捕获后将RGB图像转换为YCbCr,以减少存储和传输要求。 HVS对亮度比颜色更敏感。Y分量可以用比色度更高的分辨率表示。
颜色信息可以表示为色差(色度)分量,其中每个色度分量是R,G或B与Y之间的差。Cr和Cb分量可以用比Y低的分辨率表示。
YCbCrSampling格式
为了利用HVS对亮度和色度信息的敏感度差异,将视频信号转换为亮度/色度色彩空间后,可以对色度分量进行空间低通滤波和二次采样。
4:4:4采样:
Y,Cb和 Cr具有相同的分辨率,因此在每个像素位置都存在每个分量的样本。

4:2:2采样:
色度分量的垂直分辨率与亮度相同,但水平分辨率的一半。
表示在水平方向上每四个亮度样本有两个Cb和两个Cr样本。
视频用于高质量的色彩再现。

4:2:0采样:(因为4:1:1在JPEG标准中被使用,所以叫4:2:0)
Cb和 Cr的水平和垂直分辨率均为Y的一半。
采样广泛用于视频会议,DVD等消费类应用。
YCbCrvideo所需的样本恰好是4:4:4(或R:G:B)视频的一半。

YCbCrSampling格式-示例
图像分辨率720×576像素
4:4:4 每个采样8bits:720×576×8×3 = 9 953 280位。
4:2:0 Cb,Cr分辨率:360×288个样本,每个样本8bits:(720×576×8)+(360×288×8×2)= 4976 640位。
4:2:0 版本需要的比特数是4:4:4版本的一半。
使用4:4:4采样,总共需要12个采样–每个Y,Cb和Cr四个,总共需要12×8 = 96位,每个像素平均96/4 = 24位
使用4:2:0采样,只需要六个采样–四个Y,每个Cb,Cr总共需要6×8 = 48位,每个像素平均48/4 = 12位
6.Video Frame Formats
捕获的视频在压缩和传输之前被捕获或转换为一组“中间格式”中的一个。 通用中间格式(CIF)是流行格式集的基础。
1.Quality Evaluation
测量视觉质量是一件困难且往往不精确的艺术,因为有太多因素会影响结果。 视觉质量本质上是主观的,并且受许多因素的影响,例如不同的内容和人们的不同体验。 使用客观标准来测量视觉质量会给出准确,可重复的结果,但是到目前为止,还没有客观的测量系统能够完全重现观看视频的观众的主观体验。
1.1 Subjective Measurement — ITU-R 500
常用程序:ITU-R BT.500-11中定义的双刺激连续质量量表(DSCQS)方法。

诸如DSCQS之类的测试被认为是主观视觉质量的现实度量。 彻底进行DSCQS测试既昂贵又耗时。
1.2 Objective Quality Measurement
主观质量测量的复杂性和成本使得能够使用算法自动测量质量具有吸引力。 视频压缩和处理系统的开发人员严重依赖于所谓的客观(算法)质量度量。 使用最广泛的方法是峰值信噪比(PSNR)。
P S N R d B = 10 l o g 10 ( 2 n − 1 ) 2 M S E PSNR_{dB} = 10log_{10}{(2^n-1)^2 \over MSE} PSNRdB=10log10MSE(2n−1)2
MSE:原始图像与受损图像或视频帧之间的均方误差
2.图像和视频编码原则
目的是减少信号中存在的冗余和不相关性:
- 时间冗余:视频序列中的连续帧通常高度相关,因为它们包含相同的对象。
- 空间冗余:在单个帧内,相邻像素的幅度通常是相关的。
- 感知冗余:例如,给定像素的R,G,B分量经常相关。
- 统计冗余
T/F questions
1.Write down the full name of ADPCM in English
ADPCM Adaptive Differential Pulse Code Modulation
2.List the four types of redundancy used in video coding
时间、空间、感知、统计
3.What is the sample resolution of CIF
352*288
4.Write down the formula of PSNR
峰值信噪比 P S N R d B = 10 l o g 10 ( 2 n − 1 ) 2 M S E PSNR_{dB} = 10log_{10}{(2^n-1)^2 \over MSE} PSNRdB=10log10MSE(2n−1)2
5.ln video coding , there are three basic types of coded frames, what are they?
I P B
3.Video Compression Challenge
原始或未压缩的视频需要存储或传输大量数据。 标清NTSC视频(720x480、4:2:2 YCrCb,每秒30帧)需要超过165 Mbps的数据速率。 90分钟的视频需要超过110 GB的存储空间。 在视频流应用中使用的低分辨率视频(例如CIF(352x288、4:2:0、30帧/秒))要求超过36.5 Mbps。 今天的宽带网络提供1-10 Mbps的吞吐量。 因此,需要压缩来存储或传输数字视频。
3.1 Image Compression—JPEG
在JPEG压缩中,将图像划分为8x8像素块,然后为每个块计算2D离散余弦变换(DCT)。 DCT将块中的大多数信号能量压缩为DCT系数的一小部分。 量化这些DCT系数会导致大多数系数为零。
对量化系数进行曲折(zigzag)扫描,对游程长度编码,然后对霍夫曼编码。

3.2 Intra-and Inter-frame Prediction 帧内和帧间预测
每个帧可以编码为单独的图像,例如,通过对每个帧独立应用类似JPEG的编码。 通过利用帧之间的时间冗余或相似性,视频压缩可以实现比图像压缩更高的压缩率。
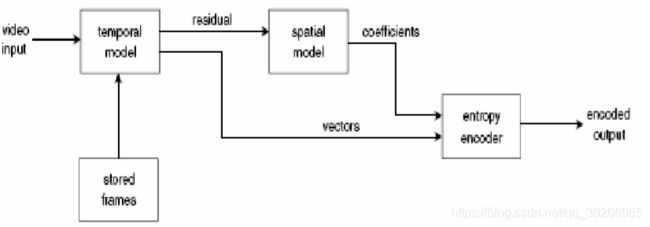
编码帧有三种基本类型:
- 帧内编码帧或I帧是独立于所有其他帧进行编码的帧。
- 预测编码帧或P帧,它是基于先前编码的帧进行编码的。
- 双向预测帧或B帧,它根据先前和将来的编码帧进行编码。

3.3 运动估计和补偿
为了最大程度地利用相邻帧之间的可预测性,重要的是估算帧之间的运动,然后在补偿运动的同时形成适当的预测。
估计帧之间的运动的过程称为运动估计。 在补偿两个帧之间的相对运动的同时,基于先前编码的参考帧预测给定帧的过程称为运动补偿预测(MC-prediction)。
基于块的运动估计和补偿
对于当前帧中的每个MxN样本块:
- 在参考帧中搜索一个区域以找到“匹配的” MxN样本区域。
- 所选的候选区域成为当前块的预测变量,并从当前块中减去以形成残差。
- 对残差块进行编码和传输,并且还传输当前块与候选区域位置(运动矢量)之间的偏移量
Sub-pixel(子像素)运动补偿
通过从参考帧中的内插样本位置进行预测,可以形成更好的运动补偿预测。 子像素运动估计和补偿涉及搜索子样本插值位置以及整数样本位置,选择最匹配的位置,然后在该位置使用整数或子样本值进行运动补偿预测。
- 在整数样本网格(圆形)上找到最佳匹配。
- 立即搜索此最佳匹配(正方形)旁边的半样本位置。
- 如果需要,则搜索在最佳半样本位置(三角形)旁边的四分之一样本位置。

细化插值以提高复杂性为代价提供更好的运动补偿性能。 随着内插步长的增加,性能增益趋于降低。
- 半采样插值比整数采样运动补偿具有明显的增益。
- 四分之一样本插值法带来了适度的进一步改进。
- 第八个样本插值可以带来较小的进一步改进,依此类推。
与更复杂的运动补偿方案相关的压缩效率的折衷:
- 更精确的运动补偿需要更多的比特来编码矢量场,而需要更少的比特来编码残差,反之亦然。
4. Image Model
变换
- 对数据进行解相关和压缩
量化
- 降低转换后的数据的精度
重新排序
- 安排数据将有效值分组在一起
预测图像编码
4.1 Predictive Image Coding - Spatial prediction (DPCM)
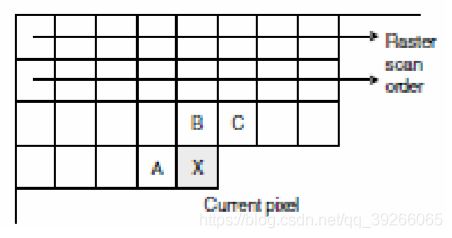
Example:
Encoder prediction P(X) = (2A+B+C)/4
Residual R(X) = X-P(X) is encoded and transmitted
Decoder decodes R(X) and forms the prediction P(X) = (2A+B+C)/4
Reconstructed pixel X = R(X) + P(X)
4.2 Transform Coding
转换后的数据应去相关且紧凑:
- 转换后的数据中的大部分能量都应集中在少量值上。
转换应该是可逆的。转换应在计算上易于处理:
- 低内存需求
- 可使用有限精度算术实现
- 算术运算次数少
已经提出了许多变换,例如KLT,SVD,DCT。受欢迎的DCT在N×N个样本的块上运行,并且图像以块为单位进行处理。
运动补偿残差往往会在块边缘出现瑕疵(“块状”)。
基于图像的变换可对整个图像或帧进行操作:
- 诸如离散小波变换(DWT)之类的图像变换已显示出优于静态图像压缩的块变换,例如JPEG2000。
- DWT往往具有更高的内存要求(尤其是大图片),因为整个图像是作为一个单元处理的。
- DWT不适用于基于块的运动补偿。
5 D-DCT
Forward DCT : Y = A X A T Y=AXA^T Y=AXAT
Inverse DCT(IDCT) : X = A T Y A X=A^TYA X=ATYA
X is a block of N ×N samples, Y is a matrix of coefficients, A is an N ×Ntransform matrix
A i j = C i c o s ( 2 j + 1 ) i π 2 N A_{ij}=C_icos{(2j+1)i \pi \over 2N} Aij=Cicos2N(2j+1)iπ
where C i = 1 N ( i ) = 0 C_i=\sqrt{1 \over N}(i)=0 Ci=N1(i)=0 C i = 2 N ( i > 0 ) C_i=\sqrt{2 \over N}(i>0) Ci=N2(i>0)
Characteristics of DCT Coefficients
FDCT输出是一组N×N系数,代表DCT域中的图像块数据。 DCT本身将所有信息保留在NXN图像块中。 人眼对低频DCT系数更敏感。 DCT有助于将感知力较高的信息与感知力较差的信息分开。 以较高的精度对低频DCT系数进行编码,但使用较少或不使用任何位来编码高频系数,因此会丢弃感知上不太重要的信息。
在计算IDCT之前添加更多的系数将对原始块进行逐步更准确的重建,并且到包含五个系数时,重建的块已与原始块相当接近。可以从16个DCT系数的子集中重建该块的近似副本。
DCT计算复杂度
单个8x8 DCT或IDCT在典型的DSP上需要数百个指令周期。 以CIF(352x288)分辨率和30 fps的帧速率运行的解码器每秒可能需要多达71,280 IDCTs。在德州仪器(TI)的TMS320C55x DSP处理器上,IDCT计算将需要40 MHz以上的频率。 IDCT计算可能会占用视频解码器实施中所用周期的30%。
由于DCT和IDCT在较小的图像块上运行,因此与图像和视频压缩应用中的帧缓冲区和其他数据的大小相比,内存要求非常小并且通常可以忽略不计。DCT和IDCT函数的高计算需求和小内存需求使其成为使用专用硬件加速器实现的理想选择。
6 Quantization
F Q = r o u n d ( X Q P ) FQ=round({X \over QP}) FQ=round(QPX) Y = F Q ∗ Q P ( 量 化 系 数 ∗ 量 化 步 长 ) Y = FQ*QP(量化系数*量化步长) Y=FQ∗QP(量化系数∗量化步长)量化用于丢弃感知上无关紧要的信息。 经过量化后,使用统计方法以尽可能少的比特对剩余信息进行编码。 量化和反量化的内存要求通常可以忽略不计。
7 Run Length Coding
量化后,绝大多数高频DCT系数为零。
游程长度编码
- 一组连续的零值系数(“行程”)
- 编码零的数量(“长度”),而不是对各个零值系数进行编码。
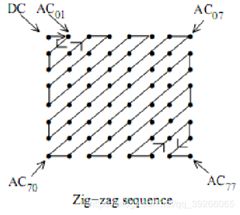
为了使连续的零值系数的平均数尽可能高,我们在对角Z型图案中扫描DCT系数矩阵。 游程编码(RLC)之后通常是可变长度编码(VLC)。

重新排序(目的?)是将非零系数组合在一起并有效地表示零系数。使用zig-zag扫描可使右上角的零排列在一起。
8 可变长度编码(VLC)
一对中的每个可能值(行程,量化的DCT系数)称为符号。 常见的符号分配有较短的代码字,而较少见的符号分配有较长的代码字。
VLC的一个缺点是,编码图像中间的位错误会阻止解码器正确地重建剩余的位流。 通过在整个编码的比特流中穿插“重新同步标记”,解码器能够搜索下一个重新同步标记,以在发生错误时进行重新同步。
9 Encoder Data Flow

编码器中的两个主要数据流路径,从左至右(编码)和从右至左(重构)。
编码流程如下:
1.输入视频帧Fn被呈现用于编码,并以宏块为单位进行处理。
2.Fn与参考帧比较,例如,先前的编码帧( F n − 1 ′ F_{n-1}' Fn−1′)。运动估计功能在 F n − 1 ′ F_{n-1}' Fn−1′中找到一个16×16区域,该区域与Fn中的当前宏块“匹配”。当前宏块位置和所选参考区域之间的偏移是运动矢量MV。
3.基于选择的MV,生成运动补偿预测P(运动估计器选择的16×16区域)。4
4.P产生残差或差异宏块D。使用DCT转换
5.通常,D被分成8×8或4×4个子块,并且每个子块被分别变换。
6.量化每个子块的DCT系数
7.量化的DCT系数重新排序并进行运行级编码。
8.最后,对每个宏块的系数,MV和相关头信息进行熵编码,以产生压缩比特流。
重建数据流如下:
1.对每个量化的宏块X进行重新缩放和逆变换,以生成解码后的残差D’。注意,不可逆量化过程意味着D’与D不相同(即,已经引入了失真)。
2.将运动补偿的预测P加到残差D’上,以产生重构的宏块,并保存重构的宏块以产生重构的帧Fn’。
3.在对完整帧进行编码之后,重建的帧Fn’可以用作下一个编码帧 F n + 1 F_{n+1} Fn+1的参考帧。

解码器数据流解码数据流如下:
1.对压缩的比特流进行熵解码,以提取每个宏块的系数,运动矢量和标头。
2.将运行级编码和重新排序相反,以生成量化的转换宏块X。
3.对X进行重新缩放并进行逆变换,以生成解码后的残差Dn’。
4.解码后的运动矢量用于在前一帧(参考) F n − 1 F_{n-1} Fn−1的解码器副本中定位16×16区域。该区域成为运动补偿预测P。
5.P被添加到Dn’以产生重构的宏块。 保存重建的宏块以产生解码帧Fn’。
6.在解码完一帧后,Fn’准备好显示,也可以存储为下一个解码帧 F n − 1 ′ F_{n-1}' Fn−1′的参考帧。
七丶JPEG Image Coding
1.Introduction
ISO / ITU联合委员会称为JPEG(联合图像专家组)已致力于建立灰度和彩色连续色调静态图像的第一个国际压缩标准。
JPEG提出的标准旨在成为通用的,以支持各种应用程序。迄今为止,Baseline方法是实现最广泛的JPEG方法,它本身足以满足大量应用。
Baseline顺序编解码器作为运动图像压缩方法-每个帧都被编码为单独的图像。 此类运动图像编码虽然提供比MPEG之类的帧间方法更少的压缩,但在视频编辑方面具有更大的灵活性。尽管在这里我们只关注JPEG作为静止图像标准(如ISO预期),但有趣的是JPEG也几乎成为了“公认的”帧内运动标准。
2.DCT-based Decoding Process
输入组件的样本分为8×8块。每个块都通过前向DCT(FDCT)转换为一组64个值,称为DCT系数:
- 第一个值称为DC系数;
- 其他63个是AC系数。

熵解码器解码量化的DCT系数的之字形序列。 反量化后,DCT系数通过逆DCT(IDCT)转换为8×8的样本块。
正向DCT(公式非重点)
在编码器的输入处,源图像样本分为8x8块,从范围为[0, 2 P 2^P 2P-1]的无符号整数转移到范围为[- 2 ( P − 1 ) 2^{(P-1)} 2(P−1), 2 ( P − 1 ) − 1 ] 2^{(P-1)}-1] 2(P−1)−1]的有符号整数 ,并输入到正向DCT(FDCT)。
逆DCT(公式非重点)
在解码器的输出处,逆DCT(IDCT)输出8x8样本块以形成重构图像
块样本与DCT系数之间的关系
在为一个块计算FDCT之后,使用统一量化器对64个所得DCT系数中的每一个进行量化。
T/F
What is the purpose of DCT?
去相关,使数据更紧凑
What is the purpose of Zigzag Scan or reordering?
是将非零系数组合在一起并有效地表示零系数
3. What is the purpose of quantization?
量化用于丢弃感知上无关紧要的信息
4.In motion estimation and compensation, what kind of redundancy is used in video coding?
temporal 时间冗余
5.In 010 editor template, the following variable is defined at the beginning: char type[4];
The variable type is mapped to 0 bytes 3 to in the file.
3.DC Coding
相邻的8x8块的DC系数之间通常存在很强的相关性,量化的DC系数被编码为与前一个块的DC项之差。这种特殊处理是值得的,因为DC系数包含了总图像能量的很大一部分
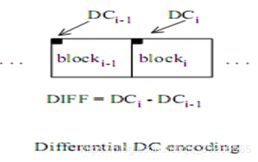
4.Zig-Zag Scan 之字形扫描
所有量化系数按“ zigzag”顺序排序,以通过将低频系数(更可能为非零)放在高频系数之前来促进熵编码
5.Compression and Picture Quality
对于场景较为复杂的彩色图像,所有基于DCT的操作模式通常会产生以下级别的图像质量:
- 0.25-0.5位/像素:中等到良好的质量,足以满足某些应用;
- 0.5-0.75位/像素:好到很好的质量,足以用于许多应用;
- 0.75-1.5位/像素:出色的质量,足以满足大多数应用的要求;
- 1.5-2.0位/像素:通常与原始像素没有区别,足以满足对质量的要求。
根据来源特征和场景内容,质量和压缩率可能会有很大差异
6.Source Image with Multiple Components
源图像可能包含1到255个图像分量。每个组件都由一个矩形样本数组组成。 样本定义为[0, 2 P 2^P 2P-1]范围内的无符号整数。
图像中的所有样本必须具有相同的精度P,对于基于DCT的编解码器,P可以为8或12。

6.1 Interleaved Multiple Components
许多应用程序需要与减压过程并行地流水线显示或打印多分量图像的过程。
仅当组件在压缩数据流中交错在一起时才可行。如果编码器压缩来自A的数据单元,来自B的数据单元,来自C的数据单元,然后再编码A,则编码将交错。
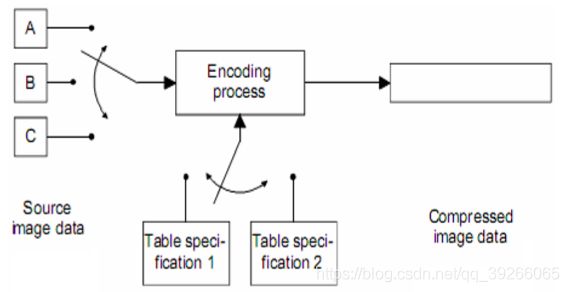
6.2 Interleaved Order for Components with Different Dimensions

分量B和C中的两个分量相对于分量A具有一半水平采样。在这种情况下,来自A的两个数据单元将和来自B和C的每个数据单元相互交错。
6.3 最小编码单位(MCU)
为了使相同的交织机适用,JPEG提案定义了“数据单元”的概念。 数据单元是基于DCT的编解码器中的8x8样本块。JPEG提案将术语“最小编码单位(MCU)”定义为最小的交错数据单位组。
对于非交错数据,MCU是一个数据单元。 对于交错数据,MCU是由扫描中组件的采样因子定义的数据单元序列。
交错数据是MCU的有序序列,MCU中包含的数据单元的数量取决于交错组件的数量及其相对采样因子。

当交错两个或多个组件时,每个组件被单元划分为Hi*Vi的矩形区域。
可交错的最大组件数为4,MCU中的数据单元的最大数为10

7.Modes of Operation
有四种不同的操作模式,用于定义各种编码过程:基于顺序-DCT,基于渐进-DCT,无损和层次。(重点)

7.1顺序模式与渐进模式
在连续模式下,每个图像分量均在一次扫描中编码。
在渐进扫描模式下,每个图像分量均经过多次扫描编码。第一次扫描对图像的粗糙但可识别的版本进行编码,可以快速传输该图像,并通过后续的扫描进行精修,直到达到由量化表确定的图像质量水平为止。
有两种互补的方法,可以对一部分量化的DCT系数进行部分编码:
- 在第一种方法中,在给定扫描中仅需要对zig-zag序列中指定的系数“带”进行编码。
- 在第二种方法中,无需在给定扫描中将当前频带内的系数编码为完全(量化)精度。
- 可以在第一次扫描中对N个最高有效位进行编码。
- 在后续扫描中,可以对次要位进行编码。
- 此过程称为“逐次逼近”。
这两种程序可以单独使用,也可以灵活组合使用。
Sequential Mode vs Progressive Mode
- 量化DCT系数的传输
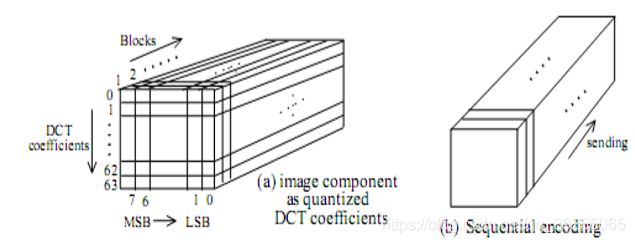
Spectral Selection & Successive Approximation
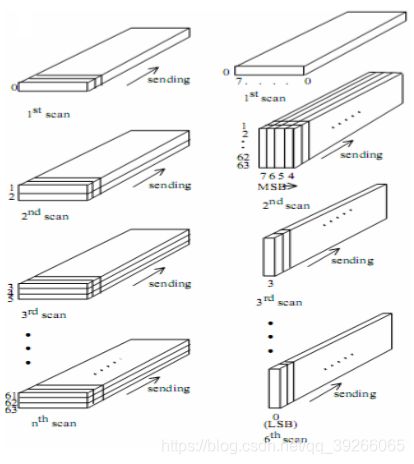
7.2 Hierarchical Mode
分层模式以多种分辨率对图像进行“金字塔形”编码,每种分辨率在水平或垂直方向上或与水平方向或垂直方向上都与相邻编码的分辨率相差两倍:
- 1.通过以下方法对原始图像进行滤波和下采样: 每个维度中2的期望倍数。
- 2.使用前面描述的顺序DCT,逐行DCT或无损编码器之一对缩小尺寸的图像进行编码
- 3.解码此缩小尺寸的图像,然后使用接收机必须使用的相同插值滤波器对它进行水平和/或垂直2插值和上采样。
- 4.使用此上采样图像作为该分辨率下的原始图像的预测,并使用前面介绍的顺序DCT,逐行DCT或无损编码器之一对差异图像进行编码
- 5.重复第3步和第4步,直到图像的全分辨率被编码
8 Baseline Sequential Entropy Coding
基线顺序编码器中的FDCT,量化,DC差分和zig-zag字形排序后步骤是熵编码。 在熵编码之前,通常只有很少的非零系数和很多零值系数。 熵编码的任务是有效地编码这几个系数。
分两个步骤给出 Baseline Sequential 熵编码:
- 将量化的DCT系数转换为符号的中间序列 - 游程编码
- 将可变长度代码分配给符号 - 哈夫曼编码
8.1 AC系数
每个非零AC系数与zig-zag序列中位于其前面的零值AC系数的“游程长度”(连续数)组合表示。
每个这样的游程长度/非零系数组合(通常)由一对符号表示:
s y m b o l − 1 s y m b o l − 2 \quad \quad \quad symbol-1 \quad \quad \quad \quad \quad \quad symbol-2 symbol−1symbol−2
( R U N L E N G T H , S I Z E ) ( A M P L I T U D E ) (RUNLENGTH,SIZE) \quad (AMPLITUDE) (RUNLENGTH,SIZE)(AMPLITUDE)

example
0005 → \rightarrow → (3,3)(5)
000003 → \rightarrow → (5,2)(3)
00,-12 → \rightarrow → (2,4)(-12)
00000000000000001 → \rightarrow → (16,0)(1) ×
RUN-LENGTH是表示非零AC系数之前的之字形序列中连续的零值AC系数的数量。SIZE是用于编码AMPLITUDE的位数。
RUN-LENGTH表示长度为0到15的零游程。
zag-zig字形序列中的实际零行程可以大于15,因此将符号1的值(15,0)解释为游程长度= 16的扩展符号。
000000000000000|01 → \rightarrow → (15,0)(0,1)(1)
000000000000000|001 → \rightarrow → (15,0)(1,1)(1)
000000000000000|000,-3 → \rightarrow → (15,0)(2,2)(-3)
在最后一个非零系数之后,使用特殊 symbol-1 终止8x8采样块。
symbol-1值(0,0)表示EOB(块结尾),可以将其视为“转义”符号。

0000030000…0000 → \rightarrow → (5,2)(3)(0,0)
0013 → \rightarrow → (2,1)(1) (0,2)(3)
The SIZE and AMPLITUDE Range For AC Symbol-1 and Symbol-2
量化AC系数的可能范围决定了AMPLITUDE和SIZE信息都必须代表的值的范围。
对 8x8 FDCT方程的数值分析表明,如果64点(8x8块)输入信号包含N位整数,则输出数字的非小数部分(DCT系数)最多可以增长3位。这也是量化DCT系数的最大可能大小。
基线顺序在[- 2 7 2^7 27, 2 7 2^7 27-1]范围内有8位整数源样本,因此量化的AC系数幅度由[- 2 10 2^{10} 210, 2 10 2^{10} 210-1]范围内的整数覆盖。
带符号整数编码使用长度为1到10位的 symbol-2 AMPLITUDE码,因此SIZE也代表1到10的值。RUNLENGTH表示从0到15的值。
8.2 DC系数
一个8x8样本块的差分DC系数的中间表示形式类似。
但是,symbol-1 仅代表SIZE信息; symbol-2 像以前一样表示 AMPLITUDE 信息:
s y m b o l − 1 s y m b o l − 2 \quad symbol-1 \quad \quad \quad \quad symbol-2 symbol−1symbol−2
( S I Z E ) ( A M P L I T U D E ) \quad (SIZE) \quad \quad \quad (AMPLITUDE) (SIZE)(AMPLITUDE)

因为DC系数是差分编码的,所以它覆盖的整数值[- 2 11 2^{11} 211, 2 11 2^{11} 211-1]是AC系数的两倍,因此必须为DC系数增加一个附加的电平。
因此,DC系数大小的 symbol–1表示从0到11的值。
差分编码(differential encoding)指的是对数字数据流,除第一个元素外,将其中各元素都表示为各该元素与其前一元素的差的编码。
差分编码的简单例子是储存序列式资料之间的差异(而不是储存资料本身):不存“2, 4, 6, 9, 7”,而是存“2, 2, 2, 3, -2”。
8.3 Variable-Length Entropy Coding
对于DC和AC系数,每个 symbol-1 均使用来自 Huffman 表集中的可变长度代码(VLC)进行编码。 每个 symbol-2 均使用“可变长度整数”(VLI)码进行编码。
VLCs和VLIs是具有可变长度的代码,但VLI不是霍夫曼代码。
一个重要的区别是,直到解码VLC( Huffman code)的长度才知道,而VLI的长度存储在其前一个VLC中。
Huffman码必须在外部指定为JPEG编码器的输入。
请注意,Huffman表在数据流中的表示形式是一种间接规范,解码器在解压缩之前必须以此间接规范来构造表(解码时需要重新构建Huffman树进行解码)。 JPEG标准包括一组Huffman表的示例,但这不是强制性的。
8.4 Baseline Encoding Example

经过FDCT和量化后,图(d)中的数字被 Huffman 编码。
zag-zig:15 0 -2 -1 -1 -1 0 0 -1 0 0 … 0
要编码的块的第一个数字是DC项,该项被差分编码。 如果先前块的量化DC项例如为12,则差为+3。
因此,对于SIZE = 2和AMPLITUDE = 3,中间表示为(2)(3)。
接着,对量化的AC系数进行编码。 遵循zag-zig字形顺序,第一个非零系数为-2,之后为零游程1。这产生了(1,2)(-2)的中间表示。
接下来以zag-zig字形顺序遇到的是三个连续非零幅度-1,每个非零都产生一个中间符号(0,1)(-1)。表示此8x8块的最终符号是EOB。
此示例8x8块的中间符号序列为:(2)(3),(1,2)(-2),(0,1)(-1),(0,1)(-1),(0,1)(-1),(2,1)(-1),(0,0)。
The differential-DC VLC for this example is:
- (2) 011
The AC luminance VLCs for this example are:
- (0,0) 1010
- (0,1) 00
- (1,2) 11011
- (2,1) 11100
The VLIs specified in JPEG standard are related to the two’s complement representation. They are:
- (3) 11
- (-2) 01
- (-1) 0
Finally, the bit-stream for this 8x8 example block isgenerated as:
01111 1101101 000 000 000 111000 1010
T/F
1.What are four modes of operation in JPEG compression
顺序,渐进,层次,无损
2.Assume that we have following quantized AC DCT coeffcients,0000000000000000003005
(15,0)(2,2)(3)(2,3)(5)
3.In JPEG compression,if three components of an image are interleaved, how many scans are there in a frame?
1
4.In JPEG an image has three components.The encoding of three components is interleaved.Assume that the sampling factors are H1=2,V1=2,H2=1,V2=2,H3=1,V3=1 respectively.Determin the number of data units in an MCU
7 a11 a12 a21 a22 b11 b21 c11
9.图像,相框和扫描
压缩图像数据仅包含一张图像。
在顺序和逐行编码过程中,一张图像仅包含一帧。 图像可能在层次模式下包含多个帧。
一帧可能包含一个或多个扫描。
在顺序模式下,扫描包含一个或多个图像成分的完整编码。
在层次模式中,如果图像的三个分量未交织,则一帧包括三个扫描。 如果所有三个分量都交织在一起,则一帧包括一次扫描。
一帧也可能包含两次扫描:一次扫描的成分是非交错的,而另一次扫描的成分是交错的。
9.1.Marker
标记用于识别压缩数据格式的各个结构部分。 大多数标记以包含相关参数组的标记段开头。
所有标记都分配有两个字节的代码:
一个0xFF字节,后跟一个不等于0或0xFF的字节
一个标记段由一个标记和随后的一系列相关参数组成。
标记段中的第一个参数是两个字节长度参数。 这指定了标记段中的字节数,包括长度参数(两字节标记除外)
将由SOF和SOS标记代码标识的标记段称为标头:
分别为帧标头和扫描标头。
- SOI(0xFFD8):图像开始标记–标记压缩图像的开始。
- EOI(0xFFD9):图像结尾标记–标记压缩图像的结尾。
9.2.Frame Header Syntax
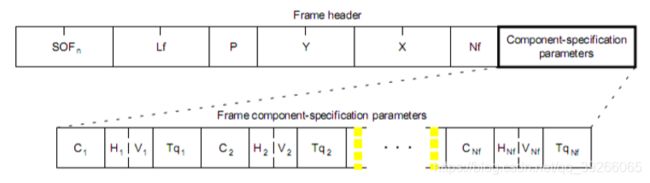
帧头应出现在帧的开头。 该标题指定源图像特性,帧中的成分以及每个成分的采样因子,并指定从中检索要与每个成分一起使用的量化表的目的地。

9.3 Scan Header Symantics

扫描开始时应有一个扫描头。 此标头指定扫描中包含哪些组件,指定从中检索要与每个组件一起使用的熵表的目标

9.4 DQTMarker Segment Syntax.

一个DQT(定义量化表)标记段,它定义一个或多个量化表

9.5 Huffman Table Specification Syntax
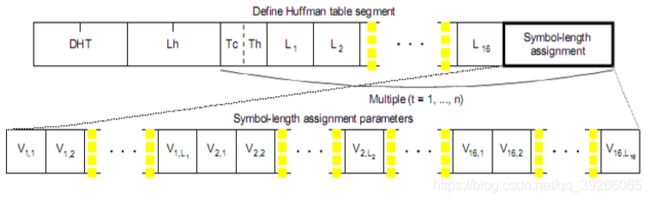
霍夫曼表标记(DHT)段定义了一个或多个霍夫曼表规范。

10.JPEG Files
到目前为止,我们描述的文件格式称为“ JPEG交换格式”(JIF)。
但是,这种“纯”文件格式很少使用,主要是由于该标准的某些缺点:
- 色彩空间定义
- 组件子采样注册
- 像素长宽比定义
JPEG文件交换格式(JFIF)解决了JIF的局限性。 JFIF文件中的图像数据使用JPEG标准中的技术进行压缩,因此JFIF有时称为“ JPEG / JFIF”。
JPEG文件交换格式是一种最小的文件格式,它使JPEG位流能够在各种平台和应用程序之间进行交换。
此简化格式的唯一目的是允许交换JPEG压缩图像。
尽管JPEG文件交换格式(JFIF)的语法支持任何JPEG处理,但强烈建议将JPEG基线处理用于文件交换。
这确保了与所有支持JPEG的应用程序的最大兼容性
.
JPEG文件交换格式与标准JPEG交换格式完全兼容。
唯一的附加要求是在SOI标记之后必须强制存在APP0标记。
一个JFIF文件使用APP0标记段并按照以下定义约束帧头中的某些参数:
- length, identifier, version, units, Xdensity, Ydensity, Xthumbnail, Ythumbnail, (RGB)n
T/F
1.What are markers used for in JIF?
标识压缩数据格式中不同的结构部分
2.Describe the full name of SOI,EOI,SOF,SOS
Start of image marker,End of image marker,Start of Frame marker,Start of Scan marker
3.What is JPEG file interchange format used for?
定义分辨率颜色等相关参数,为了能在不同应用和平台转换
4.An image contains ___ frame in the cases of sequential and progressive coding processes.
one frame
八丶Video Coding
0.1.Video Compression and ITU
ITU-T国际电信联盟-电信
International Telecommunications Union-Telecommunications
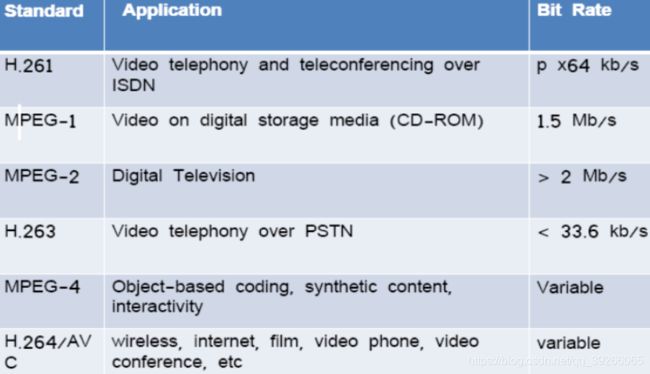
H.261,第一个视频压缩标准(1990年)
- 专为通过集成服务进行视频会议而设计数字网络**(ISDN)**。
- 以基准ISDN数据速率的倍数或 p x 64 kb / s,p= 1,2,…,30。
H.263(1996) - 通过公用电话交换网**(PSTN)**进行的视频电话。
H.264 - 高级视频编码
0.2.The Moving Pictures Expert Group(MPEG)
ISO –国际标准化组织(ISO)
International Organization for Standardization (ISO)
MPEG成立于1988年,旨在开发压缩标准在数字存储媒体上移动图片(视频)和关联的音频(光盘)。
MPEG-1,可在获得大约等于VHS品质的视频和音频大约1.5 Mb / s(1991)。>VCD
MPEG-2是MPEG-1的扩展,是为数字电视开发的比特率较高的应用:>DVD
- DTV,HDTV和DVD
MPEG-4,将提供增强的功能: - 基于内容的处理,天然和合成的集成(计算机生成的)素材,以及与场景的互动性。
0.3.Scope of Standardization 标准化范围
视频压缩系统由一个编码器,压缩比特流和解码器。
标准范围有限,无法确保互操作性同时尽可能实现差异化:
- 指定比特流语法和解码过程;
- 不要指定编码过程或特定的解码器实现。

1.MPEG-1
MPEG-1是由ISO制定的第一个视频压缩算法
应用程序是动态图像的存储和检索和使用CIF的视频CD等数字媒体上的音频分辨率(29.97 fps时为352x240或25 fps时为352X288)1.15 Mbps:
- 需要更多的计算资源来支持更重的运动电影内容比典型的视频电话更重要。
- 允许更长的延迟和B帧
- 使用自适应感知量化。单独的量化比例因子专门应用于每个频点以进行优化人类的视觉感知。
2.MPEG-2
MPEG-2是针对数字电视而开发的,很快成为迄今为止最成功的视频压缩标准。
MPEG-2由许多部分组成,包括视频,音频,系统,兼容性测试。
与MPEG-1相比,它支持更高的比特率,更高分辨率和隔行扫描图片(用于电视)。(先打奇数行再偶数行)
MPEG-2在30:1左右的压缩率下表现良好。 MPEG-2以4~8 Mbps达到的质量对于消费者视频应用程序是可接受的。
3 MPEG编码结构
MPEG以称为序列的单位层次结构对视频进行编码,图像组(GOP),图像,切片,宏块和DCT块:
- 对16x16像素的宏块执行MC预测(运动补偿预测)。
- 这些宏块组成一个切片。
- 一帧中的所有切片均包含一张图片,连续的图片形成一个GOP。
- 所有GOP形成一个序列。

3.1 MPEG GOP
视频帧被分组为称为组的编码单元图片(GOP)。
- GOP具有重新初始化时间的属性编码中使用的预测
- GOP的第一帧始终以帧内模式进行编码,并且称为I帧

用帧间模式编码的帧通过正向预测或双向预测,分别称为P或B帧
GOP长度通常在9到15帧之间。
每个B帧都取决于过去帧和一个将来帧,这意味着将来帧必须是在当前B帧可以被(解码)编码之前被(解码)编码。
编码后的视频数据以编码顺序放置在数据流中,而不是显示顺序。
3.2 I P B帧编码属性
I,P和B帧的编码通常要求不同数据量。
I帧需要大量数据,因为它们已编码与其他框架无关。
P和B帧通常需要的数据少于I帧,因为时间预测。
B帧的编码数据通常少于P帧,因为:
- 同时使用在前和在后的参考帧,可以形成更好的预测。
- 较低的质量编码B帧不会带来负面影响影响其他帧的质量,B帧的编码质量较低不会影响序列中的其他帧。
3.3 MPEG Macroblocks
MPEG使用16x16像素MC预测来减少时间视频中固有的冗余。
在I帧中,必须以帧内模式对每个宏块进行编码。
在P帧中,每个宏块都可以使用前向编码预测或帧内模式。
在B帧中,每个宏块都可以前向编码,后向或双向预测或帧内模式。
为每个前向和后向预测指定一个MV(motion vector)宏块,同时为每个双向指定两个MV预测宏块。
3.4 MPEG DCT Blocks
每个宏块被划分为8x8像素块。
为每个块计算二维DCT。 DCT系数被单独量化。
量化系数经过zigzag扫描,游程长度进行编码,结果(游程长度,幅度)对经过霍夫曼编码并放置在比特流中。
还有一些区块间和宏块间处理。
3.5 MPEG Slices
MPEG编码要求每个宏块都属于一个切片,所有切片都构成整个图片。
切片是一系列任意数量的连续宏块:
- 每个切片至少应包含一个宏块。
- 切片不得重叠。
- 切片的位置可能因图片而异。
这提供了一种用于预测宏块中某些参数的结构,同时保持一定程度的错误弹性。
在I帧中,DCT系数的DC值在一个片内从块到块被差分编码。>(JPEG是整幅图做差分编码)
在P和B帧中,运动矢量在片内从宏块到宏块进行差分编码。
如果位流中发生错误,则切片中的剩余数据将丢失。 但是,解码器可以通过搜索下一个切片起始码,重新同步位流并继续解码过程来恢复。
3.6 MPEG Syntax
序列头指定图片的高度/宽度,以及样本宽高比,帧速率,比特率和缓冲区大小序列。 如果未使用默认的量化器,则还包括量化矩阵。
GOP头指定时间代码并指示是否GOP打开或关闭。
图像头指定时间参考参数,图片类型(I,P或B)以及缓冲区充满度。 如果是使用时域预测,它还描述了运动矢量精度(完整或半像素)和运动矢量范围。
切片头指定切片所在的宏块行开始,DCT的初始量化器比例因子系数。
宏块头包含一个标志,指示是内部还是帧间编码。
- 对于帧间编码,它包含编码的运动矢量,相对于先前的运动矢量被差分编码。
- 可以在宏块级别上调整量化器比例因子。1bit用于指定是否调整因子。
序列,GOP,图片和切片标头以起始代码开头: - 例如,可以在第二张图片的第二片中找到编码数据通过简单地检查编码数据流而无需检查第二个GOP解析和解码数据。
- 促进对压缩比特流的有效随机访问。
- 容错能力
3.7 MPEG-2 Profiles and Levels
这些标准旨在解决大量不同的应用程序,其中每个应用程序都需要许多不同的工具或功能。
典型的应用程序可能仅使用MPEG功能的一小部分。 为了实现更有效的实现,MPEG将功能的适当子集分组在一起,并定义了一组配置文件和级别。
- 配置文件定义了视频语法和功能的子集。
- 在配置文件中,级别定义了某些参数的最大范围,例如分辨率,帧速率,比特率和缓冲区大小(下限)。
两个广泛使用的配置文件/级别是:(了解)
- Main Level at Main Profile用于压缩DVD上使用的常规电视(例如NTSC或PAL)和标清数字电视(SD DTV)
- 高级别的主要资料(MP @ HL),可用于压缩高清电视(HDTV)(1080p)

4 H.261
ITU(国际电联)定义的H.261是第一个主要视频压缩标准:
- 双向视频会议的目标,并且已设计用于支持40kbps-2Mbps的ISDN网络。
- 支持352X288(CIF)和176X144(QCIF)的分辨率色度分辨率子采样为4:2:0。
- 由于视频电话需要,因此要求较低的复杂性同时进行实时编码和解码。
- 由于它专注于对延迟敏感的双向视频,H.261仅允许I和P帧,不允许B帧。(B帧需要等待后帧解码,存在时延)
- 运动估计被计算为全像素(整数)精度和搜索范围为+/- 15像素。
- 将基于8x8块的DCT应用于残差。
- 然后在所有AC系数上进行固定的线性量化用固定的量化步长线性量化。
- 首先对量化系数进行游程编码,然后可变长度(霍夫曼)编码。
- 一个简单的2D FIR滤波器也应用于块边缘减少块效应。
5 H.263
H.263是在H.261之后开发的,专注于更好更低比特率的视频质量。
重要目标之一是通过普通电话调制解调器以33.6 Kbps的速度传输视频。目标分辨率为SQCIF(128x96)至CIF(352X288)。
与H.261类似,但运动矢量略有不同允许为½(“半像素”)的倍数。使用16x16宏块中的四个8x8像素块的四个运动矢量,而不是宏块的单个运动矢量。
一个PB帧由两个编码为一个单元的帧组成,其中一帧是P帧,另一帧是B帧,这是从当前编码的P帧和后一个先前编码的P帧预测而来的,PB帧执行通过增加帧速率,同时只需要一点点增加比特率就可以很好地实现。
基于内容的算术编码模式代替霍夫曼编码,对于相同的图像质量,比特率略有降低。
H.263通常在相同的比特率下实现大约3 dB的改善,或者在相同的SNR(质量)下将比特率减少50%。
6 MPEG-4 Standard
MPEG-4与MPEG-1和MPEG-2完全不同,它的主要目标是启用新功能,而不仅仅是提供更好的压缩。
MPEG-4支持基于对象或基于内容的表示。
这样可以对视频场景中的不同视频对象进行单独的编码,并且还可以单独访问和操纵视频中的不同对象。
请注意,MPEG-4没有指定如何识别或分割视频中的对象。但是,如果单个对象已知,MPEG-4提供了一种压缩这些对象的方法。
MPEG-4还支持对合成或计算机生成的视频对象进行压缩,以及在单个视频中集成自然对象和合成对象。
此外,MPEG-4支持通过易错通道(例如Internet和3G无线系统)进行防错通信。
因此,MPEG-4同时支持基于对象和基于帧的视频编码
Demuxer用于解析和解码视频和音频对象。
场景描述信息描述了解码对象如何组成和渲染以形成最终场景。
与MPEG-2和MPEG-4简单配置文件相比,H.264 / AVC在压缩效率方面取得了重大突破,通常可实现约2倍的压缩。
为了满足从低质量,低分辨率监视摄像机到高清电视广播和DVD的各种应用,MPEG-4第2部分定义了大约21个配置文件,包括称为简单,高级简单,主要,核心,高级编码效率,高级实时简单等。
最常用的配置文件是Advanced Simple和Simple,这是Advanced Simple的子集。
T/F
1.H.263 is uesd in DVD (F,可视电话)
2.The bit stream synatax is specified in MPEG video coding standard (T)
3.The encoding process is specified in MPEG coding standard (F)
4.MPEG-1 allows B frames (T)
5.P frames require more data than I frames because of temporal prediction (F)
6.In video coding the position of slices may change from picture to picture (T)
7.In video coding the GOP header specifiles the temporal reference parameter (F,picture header)
7 H.264/MPEG-4 AVC
过去十年来,视频编码中最重要的发展之一就是ITU和ISO / IEC联合视频小组(JVT)对H.264 / MPEG-4 AVC标准的定义。
国际电联于1997年开始使用新的编码工具进行H.26L(长期)的研究。 结果令人印象深刻,ISO / IEC决定与ITU合作,在联合视频小组的支持下采用通用标准。
国际电联于2003年5月批准了新的H.264标准。ISO于2003年10月批准了该标准为MPEG-4 Part 10,高级视频编码或AVC。
与MPEG-2和MPEG-4简单配置文件相比,H.264 / AVC在压缩效率方面取得了重大突破,通常可实现约2倍的压缩。
当H.264标准化时,它支持三个配置文件:基线,主要和扩展。
后来,一项称为保真度范围扩展(FRExt)的修正案引入了四个附加配置文件,称为“高级配置文件”。
早期,baseline profile 和 mian profile 引起了最大的兴趣。
baseline profile 需要较少的计算和系统内存,并且针对低延迟进行了优化:
- 由于其固有的等待时间,它不包括B帧;由于计算复杂性,它不包括CABAC。
- baseline profile 非常适合视频电话应用程序以及其他需要经济高效的实时编码的应用程序。
mian profile 旨在用于广播和内容存储应用程序,以最低的比特率利用最高的视频质量。
(图!重点!!!) (WMV9\AVS 了解)

Prediction Modes:Frame(逐行扫描) Fleld(隔行扫描)
7 H.264/AVC Standard
7.1 H.264 / AVC的目标和应用
ITU-T SG16视频编码专家组(VCEG)
- H.26L项目(1998年初),H.26L最初专注于视频会议和电话。
- 目标–编码效率是其他任何编码的两倍其他现有的视频编码标准。
应用
- 通过电缆,卫星,地面进行数字视频广播
- 媒体存储,DVD,蓝光DVD等
- Internet流视频,3G / 4G网络上的可视电话,视频会议
- 数字视频监控,数字电影院等
7.2 Relationship to Other Standards
ITU-T和MPEG均批准相同的设计
在ITU-T中,这将是一个新的独立标准
- ITU-T H.264建议书
- ITU-T系统(H.32x)将被修改以支持它
在MPEG中,这将是MPEG-4套件中的新“组成部分”
- 与以前的MPEG-4视觉效果分开的编解码器设计
- 新的第10部分称为“高级视频编码”(类似于“ AAC”MPEG-2中的位置作为单独的编解码器)
- 不与先前的标准向后或向前兼容(先前的MPEG-4视觉规范。 –核心技术不同)
- 修改MPEG-4系统/文件格式以支持它
IETF致力于RTP有效负载包
7.3 New Features and Common Elements
视频编码层基于混合视频编码(时域+空域),其本质上与其他标准相似,但有重要区别。
新的主要功能包括:
- 增强的运动补偿
- 更小块进行变换编码
- 改进的去块滤波器
- 增强的熵编码
与先前标准的共同要素:
- 16x16宏块
- 块运动位移
- 块变换
- 标量量化
- I,P和B图片类型
与先前标准的性能相比,等效的感知质量可节省约50%的比特率。
7.4 Profiles
Constrained Baseline Profile (CBP)
- 主要用于2009年开发的低成本应用程序,例如**视频会议和移动应用程序。**
- 它对应于以下所述的 Baseline, Main, 和 High Profiles 中共有的特征子集。
Baseline Profile (BP)
- 主要用于需要额外数据丢失健壮性的低成本应用程序,例如视频会议和移动应用程序。
- 包括“Constrained Baseline Profile”配置文件中支持的所有功能,以及用于增强健壮性的其他功能。
- 所有受约束的基准配置文件位流也被视为基准配置文件位流,因为这两个配置文件共享相同的配置文件标识符代码值。
Main Profile(MP)
- 用于标清数字电视广播,该广播使用DVB标准中定义的MPEG-4格式。
Extended Profile (XP)(XP)
- 用作流视频配置文件。
- 具有相对较高的压缩能力,并具有一些其他技巧,可增强数据丢失和服务器流切换的稳定性。
High Profile (HiP)
- 于2004年开发,用于广播和光盘存储应用程序,特别是用于高清电视应用程序(例如,蓝光光盘存储格式和DVB HDTV广播服务已采用它)。
High 10 Profile (Hi10P)
- 在“高级配置文件”的基础上,增加了对每个解码图像精度样本最多10位的支持。
High 4:2:2 Profile (Hi422P)
- 针对使用隔行视频的专业应用程序;
- 在 High 10 Profile 的基础上,增加了对4:2:2色度子采样格式的支持,同时每个解码图像精度样本最多使用10位。
High 4:4:4 Predictive Profile (Hi444PP)
- 建立在 Hi422P 之上,支持高达4:4:4色度采样,每个采样最多14位;
- 此外,还支持高效的无损区域编码以及将每个图片编码为三个单独的色彩平面。
7.5 Baseline Profile (BP)特征(重点)
- I和P slice 类型(非B)
- 回路解块滤波器
- 1/4采样运动补偿
- 树结构的运动分割小至4x4块大小
- 基于VLC的熵编码
- 一些增强的错误恢复能力
- 灵活的宏块排序/任意切片排序
- 冗余切片
- 主要用于视频会议和无线应用
7.6 Main Profile(MP)特征 (重点)
- 包含所有Baseline Profile (BP)特征,增强的错误恢复功能除外
- B slice
- CABAC
- MB级帧/场切换**(场模式和帧模式的转换,即逐行和隔行)**
- 用于B和P图片预测的自适应加权
- 支持隔行扫描图片
- 主要用于广播应用
7.7 Basic Macroblock Coding Structure

7.8 Motion Compensation
各种块尺寸和形状的运动补偿
1/4样本精度
- 6 tap 滤波,达到1/2采样精度
- Simplified 滤波,达到1/4的采样精度
多张参考图片
暂时反向运动和广义B帧
B帧预测加权
7.9 H.264/AVC Coded Data Format
H.264区分视频编码层(VCL)和网络抽象层(NAL)。
编码过程的输出是VCL数据(代表已编码视频数据的位)传输或存储前的NAL单元。
分别指定VCL和NAL的目的是为了区分特定于编码的功能(在VCL中)和特定于运输的功能。
每个NAL单元包含一个原始字节序列有效载荷(RBSP),一个与编码视频数据相对应的数据集以及标头信息。
编码的视频序列由可通过基于数据包的网络或比特流传输链路传输或存储在文件中的NAL单元序列表示。


NAL数据包的第一个字节是标头,其中包含有关数据包类型的信息。
ubyte forbidden_bit: 1; // set to 0
ubyte nal_ref_idc:2; // the level of priority
ubyte nal_unit_type:5; // NAL type

7.10 Reference Pictures
H.264编码器可以将一个或两个先前编码的图片用作每个帧间编码宏块或宏块分区的运动补偿预测的参考。
使编码器能够从更宽的图像集中搜索当前宏块分区的最佳“匹配”,而不仅仅是先前编码的图像。
编码器和解码器分别维护一两个参考图片列表,其中包含先前已编码和解码的图片(按显示顺序在当前图片之前和/或之后出现)。
- 根据单个列表(列表0)中的图片预测P切片中的帧间编码宏块和宏块分区。
- 可以根据两个列表(列表0和列表1)中的图片预测B切片中的帧间编码宏块和宏块分区。
7.11 Slices
视频图像被编码为一个或多个切片,每个切片包含整数个宏块,从每个切片1 MB到图片中的宏块总数(每个图片1个切片)。
图片中每个切片的宏块数量不必恒定。编码片之间的相互依赖性最小,这可以帮助限制错误的传播。
符合 Baseline Profile 的比特流包含编码的 I 和/或 P slices:
- I片仅包含帧内编码宏块(根据同一片中先前编码的样本进行预测);
- P切片可以包含帧间编码的宏块(根据先前编码图片中的样本预测),帧内编码的宏块或跳过宏块。
编码图片可能由不同类型的切片组成:(重点)
- Baseline Profile 编码的图片可能包含I和P切片的混合;
- Main or Extended Profile 图片可能包含I,P和B切片的混合。
切片数据由切片标头,一系列已编码宏块和/或已跳过(未编码)宏块的指示组成。
切片标头定义了切片类型和切片“所属”的编码图像,并且可能包含与参考图片管理有关的指令。
7.12 Macroblocks 宏块
每个MB包含一系列标题元素和编码的残差数据
一个MB中的编码数据对应于视频帧的16×16样本区域(16×16亮度样本,8×8 Cb和8×8 Cr样本)。
宏块在一个帧中按光栅扫描顺序编号或寻址:
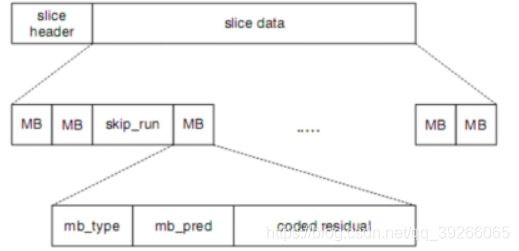
7.13 Macroblock Prediction
H.264切片中的每个编码宏块都是根据先前编码的数据预测的。
- 从当前切片中已经编码,解码和重建的样本中预测内部宏块内的样本;
- 从先前编码的帧中预测帧间宏块中的样本。
根据已编码的图像样本(在同一切片中或在先前编码的切片中)创建当前宏块或块的预测(尽可能类似于当前宏块或块的模型)。
从当前宏块或块中减去此预测。减法的结果(残差)与解码器重复进行预测处理所需的信息(运动矢量,预测模式等)一起压缩并传输到解码器。
解码器创建一个相同的预测,并将其添加到解码后的残差或块中。
编码器的预测基于编码和解码的图像样本(而不是原始视频帧样本),以确保编码器和解码器的预测相同。
7.13 Motion Vector Prediction
为每个分区编码运动矢量可能会花费大量位数,尤其是在选择较小分区大小的情况下。
相邻分区的运动矢量通常高度相关,因此,每个运动矢量都是根据附近的先前编码分区的矢量预测的。根据先前计算的运动矢量和MVD形成预测矢量MVp,对当前矢量和预测矢量之差进行编码和传输。
形成预测MVp的方法取决于运动补偿分区的大小以及附近矢量的可用性。
示例:当前和相邻分区(不同的分区大小)
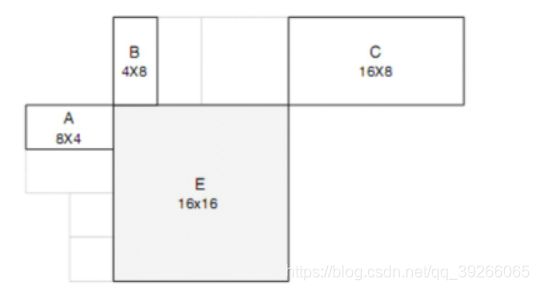
- 1.对于不包括16×8和8×16分区大小的已传输分区,MVp是分区A,B和C的运动矢量的中值。
- 2.对于16×8分区,根据B预测较高的16×8分区的MVp,根据A预测较低的16×8分区的MVp。
- 3.对于8×16分区,从A预测左8×16分区的MVp,从C预测右8×16分区的MVp。
- 4.对于跳过的宏块,如在第一种情况下(即,该块是以16×16帧间模式编码)那样,生成16×16矢量MVp。

8. Intra-Frame Prediction
Intra 4×4
- 非常适合对图像的重要细节进行编码。
- 9种预测模式
Intra_16×16
- 更适合对图片的非常平滑的区域进行编码
- 4种预测模式
Intra 8×8
- 4种预测模式
I_PCM
- 绕过预测和变换编码并发送的值直接编码的样本。
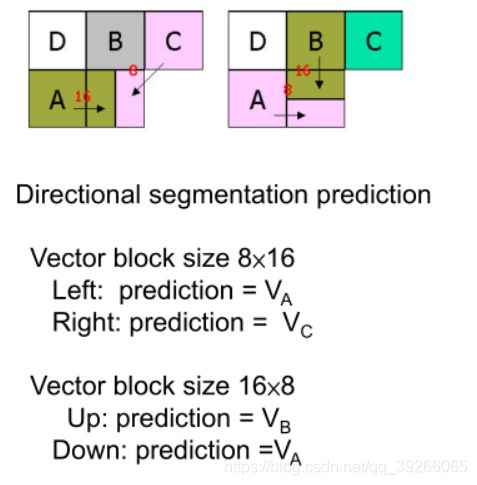
8.1 Intra 4 ×4 luma block prediction
上方和左侧的样本(标为A–M)以前已经过编码和重建,因此可以在编码器和解码器中使用以形成预测参考。
预测块P的样本a,b,c ,… ,p是根据样本A–M计算的。

箭头指示每种模式下的预测方向。 对于模式3–8,预测样本由预测样本A–M的加权平均值形成。
例如,如果选择了模式4,则可以通过以下方式预测P的右上样本(标记为“ d”):round(B / 4 + C / 2 + D / 4)。

8.2 16 × 16 Luma Prediction Modes
作为上一节中描述的4×4亮度模式的替代方法,可以在一个操作中预测宏块的整个16×16亮度分量。
四种模式可用:
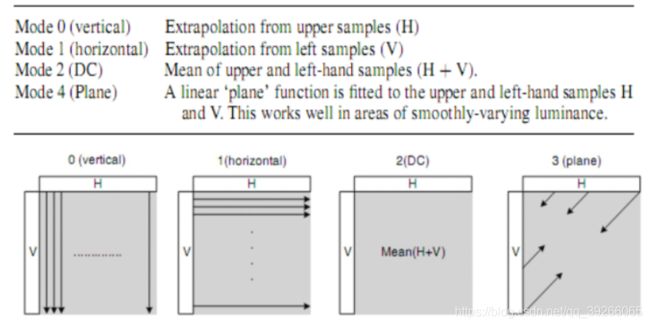
8.3 8 ×8 Chroma Prediction Modes
帧内编码宏块的每个8×8色度分量是根据上方和/或左侧的先前编码色度样本预测的。
两个色度分量始终使用相同的预测模式。
四种预测模式与16×16亮度预测模式非常相似,只不过模式的编号不同。
模式为DC(模式0),水平(模式1),垂直(模式2)和平面(模式3)。
T/F
1.H.261 baseline profile allows B frames (F)
2.H.261 has a motion vector resolution of 1/2 pixel (F)
3.H.264 has a motion vector resolution of 1/4 pixel (T)
4.In H.264 spatial intra prediction is not supported (F)
5.H.264 main profile supports CABAC (T)
6.A Main or Extended Profile picture in H.264 coding contains a mixture of I and P sices (I.P.B)
8.4 Signaling Intra Prediction Modes
必须将每个4×4块的帧内预测模式选择发送给解码器,这可能需要大量的位
相邻4×4块的帧内模式通常是相关的:
- 例如,假设A,B和E分别为左,上和当前4×4块。
- 如果使用模式1预测了先前编码的4×4块A和B,则块E(当前块)的最佳模式也可能是模式1。
为了利用此相关性,预测编码用于发信号通知4×4帧内模式。
对于每个当前块E,编码器和解码器将计算最可能的预测模式,即A和B的最小预测模式。
如果这些相邻块中的任何一个都不可用(当前切片之外或未以内部4×4模式编码),则将对应的值A或B设置为2(DC预测模式)。
编码器为每个4×4块发送一个标志,即prev_intra_4×4_pred_mode。
- 如果标志为“ 1”,则最可能的预测模式被使用。
- 如果标志为“ 0”,则发送另一个参数rem_intra_4×4_pred_mode指示模式更改
- 如果rem_intra_4×4_pred_mode < 当前最可能的模式,则将预测模式设置为rem_intra_4×4_pred_mode;
- 否则,预测模式= rem_intra_4×4_pred_mode + 1。
- 这样,只需要8个rem_intra_4×4_pred_mode值(0至7)即可发出当前帧内模式的信号(0至8)
9.Residual Coding
9.1 Transform, Scaling and Quantization
Intra_16×16,用于平滑区域
DC系数经过第二次变换,结果是变换系数覆盖了整个宏块
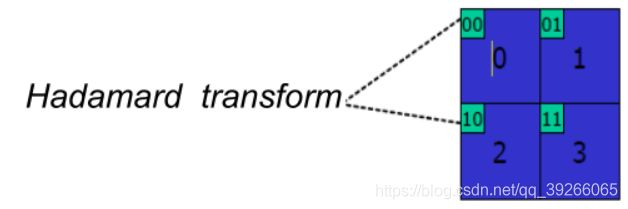
扫描顺序
- zig-zag扫描
- 对于2×2色度分量的DC系数–光栅扫描顺序
只使用16位整数值的加法和移位操作来实现H.264 / AVC中的所有变换操作。仅需要16位内存访问就可以很好地实现变换和量化过程。

9.2 4x4残差变换和量化
在运动补偿预测或帧内预测之后,此变换对4x4的残差数据块进行操作。
基于DCT变换,但有一些基本差异:
- 这是一个整数变换(所有运算都可以使用整数算术执行)。
- 变换的核心部分是无乘法的,即只需要加法和移位。
- 比例乘法(完整转换的一部分)已集成到量化器中(减少了乘法的总数)。
9.3 Entropy Coding
我们介绍H.264使用的两种基本的可变长度编码(VLC)技术:Exp-Golomb码和上下文自适应VLC(CAVLC):
- Exp-Golomb码普遍用于除变换系数以外的所有符号。
- CAVLC用于编码变换系数:
- 无块尾,但解码了系数个数。
- 向后扫描系数。
- 上下文取决于变换系数。
Exp-Golomb Code
Exp-Golomb码是具有常规结构的可变长度代码。

Exp-Golomb码的每个码字的结构如下:
[M zeros][1][INFO]
其中INFO是一个携带信息的M位字段。因此,码字的长度是2M + 1。
给定一个code_num,可以通过以下过程获取相应的Exp-Golomb码字:
a) M = ⌊ l o g 2 [ c o d e n u m + 1 ] ) ⌋ M = \lfloor log_2[code_{num}+1]) \rfloor M=⌊log2[codenum+1])⌋
b) I N F O = c o d e n u m + 1 − 2 M INFO = code_{num}+1-2^M INFO=codenum+1−2M
Example:(重点)
code_num=6
M= ⌊ l o g 2 [ 6 + 1 ] ) ⌋ \lfloor log_2[6+1])\rfloor ⌊log2[6+1])⌋=2
INFO= 6 + 1 − 2 2 = 3 6+1-2^2=3 6+1−22=3
对应的Exp-Golomb码字:
=[M zeros][1][INFO]=00111
给定一个Exp-Golomb码字,其code_num可以如下找到:
a) Read in M leading zeros followed by 1.
b) Read M-bit INFO field
c) code_num = 2 M + I N F O − 1 2^M+INFO-1 2M+INFO−1
Example:(重点)
Exp-Golomb codeword=00111
a) M = 2
b) INFO = 3
c) code_num = 2 2 + 3 − 1 = 6 2^2+3-1=6 22+3−1=6
CAVLC
这是用于编码变换系数的残差和之字形有序块的方法。

CAVLC旨在利用量化的4×4块的几个特性:
- 经过预测,变换和量化后,块通常比较稀疏(主要包含零)。
- Zig / zag扫描后的最高非零系数通常是+/- 1的序列。
- 相邻块中非零系数的数量相关。
- 在曲折扫描开始时,非零系数的水平(幅值)倾向于较高,而在高频处则较低。
变换系数块的CAVLC编码如下进行:
-
编码系数和尾数的数量。
-第一步是对非零系数(NumCoef)和尾随系数(T1s)的总数进行编码。
-非零系数可以是0(4x4块中没有系数)到16(16个非零系数)之间的任何值。
T1s可以是0到3之间的任何值。
如果尾随的+/- 1多于3个,则仅将最后3个视为``特殊情况’’,而将其他3个作为正常系数进行编码。

表格的选择取决于上部和左侧先前编码的块NU和NL中的非零系数的数量。
参数N的计算如下:
如果U和L块可用(即,在同一编码片中),N =(NU + NL)/ 2。
如果只有块U可用,则N = NU。
如果只有块L可用,则N = NL。
如果两者都不可用,则N = 0。

-
对每个尾随的符号进行编码。
对于每个T1,单个位对符号进行编码(0 = +,1 =-)。
这些从最高频率T1开始以 相反顺序编码。 -
编码其余非零系数的电平。
块中每个剩余的非零系数的电平(符号和大小)以 相反的顺序编码。
根据每个连续编码级别(上下文自适应)的大小,可以选择用于编码每个级别的VLC表。
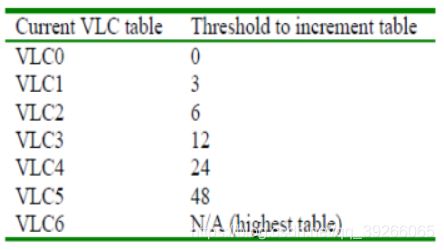
有7个VLC表可供选择,从Level_VLC0到Level_VLC6。
Level_VLC0偏向较低的幅度,Level_VLC1偏向较高的幅度,依此类推。
将表初始化为Level_VLC0(除非存在大于10的非零系数且小于3的尾随系数,在这种情况下以Level_VLC1开头)。
对最高频率的非零系数进行编码。
如果该系数的大小大于预定义的阈值,请移至下一个VLC表。
- 对最后系数之前的零总数进行编码。
- 对每次运行的零进行编码。
每个非零系数(run_before)之前的零个数以相反的顺序编码。
为每个非零系数编码run_before参数,但有两个例外:
(a)如果没有更多的零要编码;
(b) 对于最终代码,不必对run_before进行编码(最低频率)非零系数。



T/F
1.In H.264,Intra 4×4 frame prediction is suited for coding vert smooth area of a picture (F)
2.In H.264,the encoder bases its prediction on original video frame samples (F)
3.The core part of the DCT transform in H.264 is multiply-free (T)
4.In H.264 Exp-Golomb code is encode transform coeffients (F)
5.The maximum of trailing ones in CAVLC used by H.264 is 3 (T)
6.Human visual system is more sensitive to luminance than color (T)
九丶MP3 Encoder and Decoder
1.MP3 Encoder (Informative Elements)

1.2. Introduction to Psychoacoustics
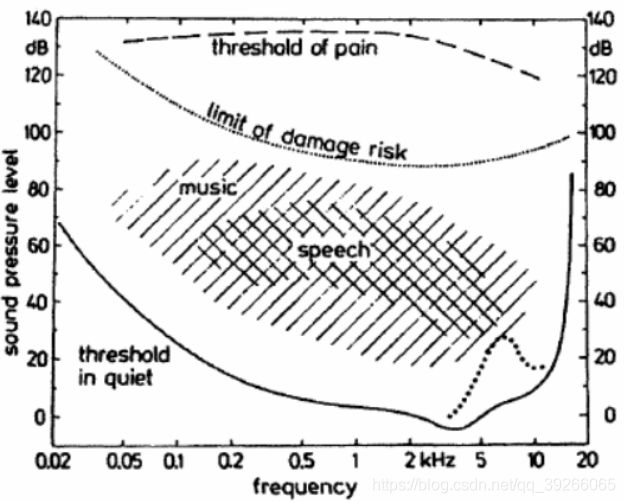
1.2.1 Sound Pressure Levels
声音以压力波p的形式到达人耳,在 1 0 − 5 P a 10^{-5}Pa 10−5Pa和 1 0 2 10^2 102Pa之间变化。
为了描述各种相关的声压,我们通常将声压级SPL定义为 S P L = 10 l o g 1 0 ( p / p 0 ) 2 SPL = 10log_10(p/p_0)^2 SPL=10log10(p/p0)2单位为dB, p 0 = 20 μ P a p_0 =20μPa p0=20μPa(对于2kHz左右的音调频率,听力阈值处的声压)。
声音也可以用声音强度I(声波中每单位面积的功率,与p2成正比)来描述。 SPL定义为 S P L = 10 l o g 1 0 ( I / I 0 ) SPL = 10log_10(I/I_0) SPL=10log10(I/I0), I 0 = 1 0 − 12 W / m 2 I_0 = 10^{-12}W / m^2 I0=10−12W/m2对应于参考压力 p 0 p_0 p0的波动。
1.2.2 Loudness 响度
响度级别定义为1 kHz音调的级别,它与正入射平面场的检查声音一样响亮。
音频响度除了取决于强度外,还取决于持续时间,时间和频谱结构。
响度单位是phon,它描述了等响度随频率变化的曲线。高电平时,以声为单位的响度值与以dB为单位的强度值之间的差减小。

1.2.3 Hearing Range
1.3. The Masking Phenomenon
1.3.1 Frequency Masking

1.3.2 Temporal Masking

1.3.3 Narrow Band Noise Masking Tones

SMR,信噪比,在特定频率下信号分量与掩蔽阈值之间的电平差
1.3.4 Tones Masking Tones

1kHZ音调屏蔽器在不同级别的屏蔽音调下的屏蔽阈值
1.3.5 Critical Bandwidths

作为两个正弦波之间的频率间隔的函数,以两个正弦波掩膜之间的中心为50dB的窄带噪声的阈值
1.3.6 Masking
在接近屏蔽器频率的频率处,屏蔽曲线级别最高。
随着测试信号频率远离掩蔽频率的移动超过临界带宽,它们会迅速下降。
屏蔽频率曲线的形状取决于屏蔽器的频率及其电平。
屏蔽曲线在很大程度上取决于屏蔽器是否为音调或类噪声。
1.4.Psychoacoustic Models for Audio Coding
1.4.1 The Bark Scale
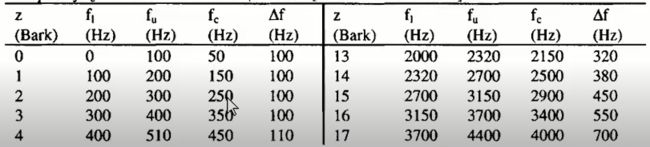
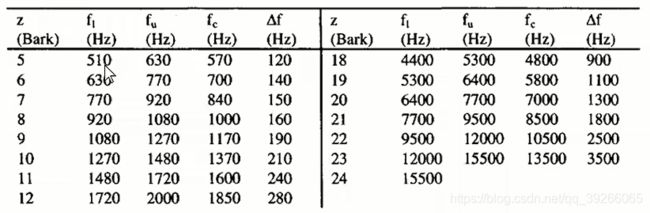
每个临界带宽(频率)对应于沿耳基底膜的固定距离,我们可以将基底距离度量z中的长度单位定义为一个关键带宽。
为了纪念该领域的早期研究人员巴克豪森,该部门被称为“Bark”。 第182页的表1中显示了与基底距离的每个单位相对应的频率范围。
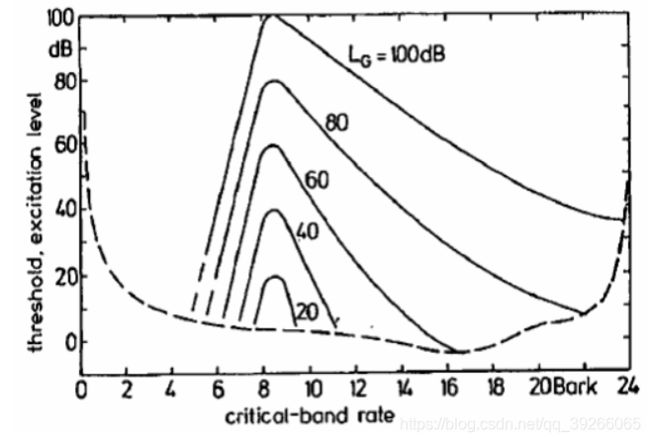
1.4.2 Models for the Spreading of Masking

1.5.Time to Frequency Mapping
PQMF:在一帧中,对1152个PCM音频样本序列进行了过滤,因此每个子带包含36个子带样本。
Window:在MDCT之前将四个窗口功能应用于子带样本。
MDCT:两种不同的MDCT块长度,一个长块包含36个样本,一个短块包含12个样本。
- MPEG-I layer3 1152个信号组成一帧
- MPEG-II layer3 576个信号组成一帧
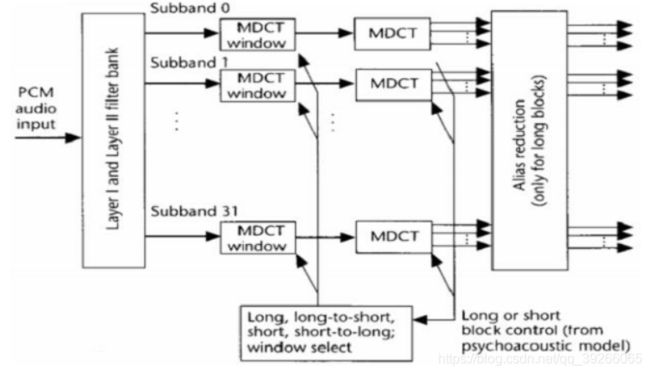
1.6. Block Mode 块模式
请注意,短块长度是长块的1/3。在短块模式下,三个短块替换了一个长块,因此,与块类型无关,音频样本帧的MDCT样本数不变。
对于给定的音频样本帧,MDCT都可以具有相同的块长(长或短)或具有混合块模式。
在混合块模式下,MDCT对两个低频子带使用长窗,对30个高频子带使用短窗。 此模式可为较低的频率提供更好的频率分辨率,而不会牺牲较高频率的时间分辨率。
1.In H.264 CAVLC,each run of zeros needs to be encoded (F)
2.The audio loudness only depends on the audio intensity (F)
3.In H.264 predictive coding is used to signal 4×4 intra modes.(T)
4.The masking curve levels of the audio masker are lowest at frequencies near the masker frequency (F)
5.In motion estimation and compensation,the temporal redundancy of the video is utilized.(T)
6.code_num=11,what is the codeword generated by Exy-Golomb code?(0001100)
在量化之前,为了减少传输信息量,应用了别名减少来去除分析PQMF中引入的别名。减少是通过一系列蝶形计算得出的。
1.7.Nonuniform Quantization
在量化之前将MDCT系数提高到3/4幂,以在量化值的范围内提供更一致的信噪比。
比例因子可为量化噪声着色,以适应掩蔽阈值变化的频率轮廓。
1.8.Huffman Encoding
有序频率线分为三个不同的区域,分别称为“ rzero”,“ count1”和“ big_value”区域。(重点)
从较高的频率开始,编码器将全零值的连续运行识别为一个区域,“ rzero”。“ rzero”区域必须包含偶数个零。
第二个区域“ count1_region”包含一个仅由-1、0或1组成的连续值。该区域的两个霍夫曼表一次编码4个值,因此值的数量必须为4的倍数。
第三区域覆盖所有剩余值,称为“ big_values区域”。 这些值与30个霍夫曼表成对编码。
此区域进一步细分为三个子区域,每个子区域都有其自己的特定Huffman表。
1.9.Bitstream Formatting
为了产生符合MP3的比特流,将霍夫曼编码的频率线,边信息和帧头组合在一起以形成比特流。
比特流被划分为帧,每个帧代表1152个音频样本。
头信息描述了用于编码音频的比特率和采样频率。
边信息说明使用哪种块类型,霍夫曼表,子带增益和子带比例因子。
一种“bit reservoir”方法用于满足编码器对代码位的时变要求。
编码器只能借用上一帧捐赠的比特; 但不能从将来的帧中借位。
MPEG /音频第3层比特流使用称为main_data_begin的9位指针来显示当前处理帧的主要数据的起点。
1.10 sampling frequency

1.11 Scalefactors
缩放因子在编码器和解码器中用于获取值块的分割因子。这些区块延伸到几个频率线上。这些块被称为尺度因子频带,并被选择来尽可能接近关键频带。
'0’ scalefactors are transmitted for each granule.
'1‘ scalefactors transmitted for granule 0 are also valid for granule 1.
2.MPEG Audio Layer III Decoding Overview
解码器具有三个主要部分:“比特流解码”,“逆量化”和“频率映射时间”。<.font>
输入的编码比特流通过第一部分进行同步,然后提取量化的频率线和每帧的其他信息。
接下来,对量化的频率线进行反量化。
最后,应用逆MDCT和合成PQMF获得PCM格式的输出信号。
T/F
1.In MPEG-1 layer III,the audio sampling frequency may be 44.1kHZ (T)
2.In MP3,an audio frame contains 1152 samples if the sampling frequency is equal to 44.1kHZ. (T)
3.In MP3 coding each granule is made up of 36 samples.(F,18*32 subban samples)
4.An MP3 encoder can borrow bits from future frames.(F,只能从上一帧借)
5.In MP3 standard,the MP3 encoder part is normative. (F)
