YOLOX改进之插入注意力机制SE、CBAM
文章内容:如何在YOLOX官网代码中插入注意力机制
环境:pytorch1.8
提醒:使用之前先了解YOLOX及注意力机制原理更好
参考链接:
YOLOX官网链接:https://github.com/Megvii-BaseDetection/YOLOX
YOLOX原理解析(Bubbliiiing大佬版):https://blog.csdn.net/weixin_44791964/article/details/120476949
SE注意力机制解析:https://blog.csdn.net/mrjkzhangma/article/details/106178250
CBAM注意力解析:https://blog.csdn.net/Roaddd/article/details/114646354
使用方法:即插即用,不需要修改已有网络结构,只需要维度能够匹配即可。
插入位置:一般为主干网络底部,也就是末端和FPN任何地方(不影响预训练权重加载),主干网络之间(依然能加载预训练权重,但是会有影响)
代码修改过程:
1、在YOLOX-main/yolox/models文件夹下创建一个attention.py文件,内容如下:
注意:代码中激活函数是relu,而yolox全部使用silu,可以自行进行修改;另外,各个版本的代码风格不相同,但大致步骤和使用方法一致(这里只是随便找了一个版本代码)。
# 包含 se cbam 以及 eca
import torch
import torch.nn as nn
import math
# SE注意力机制
class SE(nn.Module):
def __init__(self, channel, ratio=16):
super(SE, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // ratio, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=8):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 利用1x1卷积代替全连接
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
# CBAM注意力机制
class CBAM(nn.Module):
def __init__(self, channel, ratio=8, kernel_size=7):
super(CBAM, self).__init__()
self.channelattention = ChannelAttention(channel, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x*self.channelattention(x)
x = x*self.spatialattention(x)
return x
### ECA注意力机制
class ECA(nn.Module):
def __init__(self, channel, b=1, gamma=2):
super(ECA, self).__init__()
kernel_size = int(abs((math.log(channel, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y)
return x * y.expand_as(x)
2、在YOLOX-main/yolox/models/yolo_pafpn.py下进行修改和使用
步骤一:导入注意力机制模块
import torch
import torch.nn as nn
from .darknet import CSPDarknet
from .network_blocks import BaseConv, CSPLayer, DWConv
from .attention import CBAM, SE # 1、导入注意力机制模块
步骤二:在class YOLOPAFPN(nn.Module)的__init__中实例化CBAM对象,并对应调整通道(这里使用CBAM注意力机制,SE类似,只需要修改通道)
self.C3_n4 = CSPLayer(
int(2 * in_channels[1] * width),
int(in_channels[2] * width),
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
##################
### 2、在dark3、dark4、dark5分支后加入CBAM 模块(该分支是主干网络传入FPN的过程中)
### in_channels = [256, 512, 1024],forward从dark5开始进行,所以cbam_1为dark5
self.cbam_1 = CBAM(int(in_channels[2] * width)) # 对应dark5输出的1024维度通道
self.cbam_2 = CBAM(int(in_channels[1] * width)) # 对应dark4输出的512维度通道
self.cbam_3 = CBAM(int(in_channels[0] * width)) # 对应dark3输出的256维度通道
##################
def forward(self, input):
步骤三:根据步骤二想插入的位置,在forward()中进行使用(这里只是简单对由主干网络输出的特征图使用注意力机制)
def forward(self, input):
"""
Args:
inputs: input images.
Returns:
Tuple[Tensor]: FPN feature.
"""
# backbone
out_features = self.backbone(input)
features = [out_features[f] for f in self.in_features]
[x2, x1, x0] = features
# 3、直接对输入的特征图使用注意力机制
x0 = self.cbam_1(x0)
x1 = self.cbam_2(x1)
x2 = self.cbam_3(x2)
#################################
插入位置示意图如下(Bubbliiiing大佬版画的YOLOX):
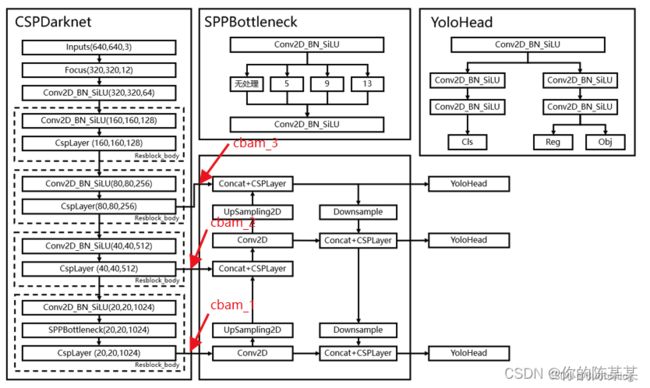
效果:根据个人数据集而定。可能没效果与负提升(几率大);效果提升(也只会提升一点点);
权重大小变化:几乎没有增加(几百K)
以上代码文件下载:
链接内容包括:SE、CBAM、Coordattention(初始化模块有问题,需要自己去修改)、GAM注意力机制
链接:https://pan.baidu.com/s/1Eyc5w1KxNE_hVVmTLGglgQ
提取码:kolu