【数据结构】五种用于查询的数据结构 性能测试
github项目地址
1)总体说明
本报告一共实现了五种用于查询的数据结构:二叉搜索树,二叉平衡树,二叉伸展树,跳表,数组。在完成各种数据的增删查功能的基础上,对于不同数据结构的查询效率进行了评测与对比,对空间性能进行了理论的分析。
大致实验思路如下

2)所涉及的数据结构介绍
a.二叉搜索树
二叉搜索树(BST)又称二叉查找树或二叉排序树。一棵二叉搜索树是以二叉树来组织的,可以使用一个链表数据结构来表示,其中每一个结点就是一个对象。一般地,除了key和卫星数据之外,每个结点还包含属性lchild、rchild和parent,分别指向结点的左孩子、右孩子和双亲(父结点)。如果某个孩子结点或父结点不存在,则相应属性的值为空(NIL)。根结点是树中唯一父指针为NIL的结点,而叶子结点的孩子结点指针也为NIL。

二叉搜索树时间复杂度分析:
它和二分查找一样,插入和查找的时间复杂度均为O(logn),但是在最坏的情况下仍然会有O(n)的时间复杂度。原因在于插入和删除元素的时候,树没有保持平衡。
二叉搜索树空间复杂度分析:
每个节点只需要存放当前节点的key值,所以空间复杂度为O(n)。
b. 二叉平衡树
在AVL树中任何节点的两个子树的高度最大差别为1,所以它也被称为高度平衡树。增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。AVL树得名于它的发明者G. M. Adelson-Velsky和E. M. Landis,他们在1962年的论文《An algorithm for the organization of information》中发表了它。

二叉平衡树时间复杂度分析:
在AVL树中插入元素同在一般BST完全一样的进行,但是每一次都会判断平衡因子是否被破坏,从而判断是否需要进行旋转操作。而每次 AVL 旋转都耗费恒定的时间,插入处理在整体上耗费 O(log n) 时间。
在AVL树中查找同在一般BST完全一样的进行,所以耗费 O(log n) 时间,因为AVL树总是保持平衡的。不需要特殊的准备,树的结构不会由于查询而改变。
查找、插入和删除在平均和最坏情况下都是O(log n)。
二叉平衡树空间复杂度分析:
每个节点只需要存放当前节点的key值,所以空间复杂度为O(n),但相比二叉排序树需要更多空间。
c. 二叉伸展树
伸展树(Splay Tree),也叫分裂树,是一种二叉排序树,它能在O(log n)内完成插入、查找和删除操作。
在伸展树上的一般操作都基于伸展操作:假设想要对一个二叉查找树执行一系列的查找操作,为了使整个查找时间更小,被查频率高的那些条目就应当经常处于靠近树根的位置。于是想到设计一个简单方法, 在每次查找之后对树进行重构,把被查找的条目搬移到离树根近一些的地方。伸展树应运而生。伸展树是一种自调整形式的二叉查找树,它会沿着从某个节点到树根之间的路径,通过一系列的旋转把这个节点搬移到树根去。
它的优势在于不需要记录用于平衡树的冗余信息。
二叉伸展树时间复杂度分析:
伸展树是一种二叉排序树,它能在O(log n)内完成插入、查找和删除操作。伸展树支持所有的二叉树操作。伸展树不保证最坏情况下的时间复杂度为O(logN)。伸展树的时间复杂度边界是均摊的。
二叉平衡树空间复杂度分析:
由于Splay Tree仅仅是不断调整,并没有引入额外的标记,无需记录额外的什么值来维护树的信息,从空间角度来看,要高效得多。所以空间复杂度为O(n)。
d. 跳表
增加了向前指针的链表叫作跳表。跳表全称叫做跳跃表,简称跳表。跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
跳表高度分析:
理想情况下每两个结点会抽出一个结点作为上一级索引的结点,原始的链表有n个元素,则第一级索引有n/2个结点,以此类推,k级索引就有n/(2^k)个元素,最高索引一般有两个元素,索引最大高度k= log2n – 1,加上原始链表,跳表的总高度k= log2n。
注:表极度不平衡发生的概率非常低(一个包含250个元素的字典,一次查找需要花3倍期望时间的概率小于百万分之一)。跳表平衡概率跟随机插入的二叉树差不多,好处是插入顺序不要求随机。

跳表查找时间复杂度分析:
1.查找包括两个循环,外层循环是从上层至底层,内层循环是在同一个level,从左到右。
2.跳表的高度极大概率为O(logn),所以外层循环的次数以极大概率为O(logn)
3.在上层查找比对过的key,不会再下层再次查找对比,任意一个key被查找的比对的概率是1/2,因此内层循环的比对次数期望约等于2,即O(1)。
4.最终查找时间= O(1) * O(logn) = O(logn)
跳表空间复杂度分析:
每层元素个数期望值为1/2^k。列表空间大小为O(2n)。跳表是多级索引链表结构,是一种典型的“以空间换取时间”的做法。
e.数组

时间复杂度:
顺序查找O(n),二分查找O(logn)
空间复杂度
O(n)
3)评测方法
a. 数据结构实现(具体实现见代码附件)
- 主界面


a) 二叉搜索树
结点:
struct BinarySearchTreeNode{
long long int key;
BinarySearchTreeNode* leftChild;
BinarySearchTreeNode* rightChild;
BinarySearchTreeNode(long long int tempKey){
key = tempKey;
leftChild = NULL;
rightChild = NULL;
}
};
方法:
class BinarySearchTree
{
private:
BinarySearchTreeNode* Root;
public:
BinarySearchTree();
BinarySearchTreeNode* GetRoot();
BinarySearchTreeNode* FindBST(long long int);
bool UpdataBSTNode(long long int, long long int);
void InsertBSTNode(long long int);
bool DeleteBSTNode(long long int);
bool SearchBSTNode(long long int);
void DeleteNoOrOneChildBSTNode(BinarySearchTreeNode*, BinarySearchTreeNode*);
void PreOrderBSTPrint(BinarySearchTreeNode*);
void InOrderBSTPrint(BinarySearchTreeNode*);
void SufOrderBSTPrint(BinarySearchTreeNode*);
};
实现效果:(后几个数据结构均为增删改查、显示操作,界面雷同,不再展示)
增:

删:


改:


查:


显示:
b) 二叉平衡树
结点:
struct AVLTreeNode
{
long long key;
int height;
AVLTreeNode* leftChild;
AVLTreeNode* rightChild;
AVLTreeNode(int tempKey)
{
height = 0;
key = tempKey;
leftChild = NULL;
rightChild = NULL;
}
};
方法:
class AVLTree
{
private:
AVLTreeNode* root;
AVLTreeNode* Search(long long int, AVLTreeNode*);
AVLTreeNode* LeftRotate(AVLTreeNode*);
AVLTreeNode* LeftAndRightRotate(AVLTreeNode*);
AVLTreeNode* RightRotate(AVLTreeNode*);
AVLTreeNode* RightAndLeftRotate(AVLTreeNode*);
int GetHeight(AVLTreeNode*);
void PreOrderPrint(AVLTreeNode*);
void InOrderPrint(AVLTreeNode*);
void SufOrderPrint(AVLTreeNode*);
void RotatePrint(AVLTreeNode*, long long int);
AVLTreeNode* Insert(long long int, AVLTreeNode*);
AVLTreeNode* Delete(bool&, long long int, AVLTreeNode*);
public:
AVLTree();
void Insert(long long int);
bool Search(long long int);
bool Delete(long long int);
bool Updata(long long int, long long int);
void PreOrderPrint();
void InOrderPrint();
void SufOrderPrint();
void RotatePrint();
};
c) 二叉伸展树
结点:
class SplayTreeNode
{
public:
long long int key;
SplayTreeNode* leftChild;
SplayTreeNode* rightChild;
SplayTreeNode* parent;
SplayTreeNode(long long int key)
{
this->key = key;
this->leftChild = NULL;
this->rightChild = NULL;
this->parent = NULL;
}
};
方法:
class SplayTree
{
private:
SplayTreeNode* root;
void LeftRotate(SplayTreeNode*);
void RightRotate(SplayTreeNode*);
void Splay(SplayTreeNode*);
void PreOrderSTPrint(SplayTreeNode*);
void InOrderSTPrint(SplayTreeNode*);
void RotateSTPrint(SplayTreeNode*,long long int);
void SufOrderSTPrint(SplayTreeNode*);
void DeleteNoOrOneChildSTNode(SplayTreeNode*, SplayTreeNode*);
public:
SplayTree();
void InsertSplayTree(long long int);
bool DeleteSplayTree(long long int);
bool UpdataSplayTree(long long int, long long int);
SplayTreeNode* FindSplayTree(long long int);
void PreOrderSTPrint();
void InOrderSTPrint();
void RotateSTPrint();
void SufOrderSTPrint();
};
d) 跳表
结点:
class node {
public:
node(int val, int level) {
this->val = val;
this->level = level;
for (int i = 0; i < MAXLEVEL; i++) {
forword[i] = NULL;
}
}
~node() {};
int val;
int level;
node* forword[MAXLEVEL];//指向node*的数组
};
方法:
class skiplist {
private:
node* head;
int max_length;
public:
skiplist();
void insert(int val);
bool search(int val);
void delete_val(int val);
void print();
int get_max_length();
};
显示界面:

e) 数组
Vector<int>
b. 准备工作
a) 时间测试模块
- 引入头文件
#include - 代码块
DWORD start, end;
start = GetTickCount64();
......
end = GetTickCount64() - start;
cout << "Average time:" << (double)end / sum * 1000 << "微秒" << endl;
GetTickCount64()函数返回的是长整型,相减得到的单位是毫秒。
b) 随机数模块
- 引入头文件
#include - 均匀分布
unsigned seed = std::chrono::system_clock::now().time_since_epoch().count();
std::default_random_engine gen(seed);
std::normal_distribution<long double> dis(EX, DX);
long long int key = dis(gen);
- 正态分布
std::uniform_int_distribution<long long> dist(0, sum);// range from 0 - sum
std::random_device rd; // Non-deterministic seed source
std::default_random_engine rng{ rd() }; // Create random number generator
//产生随机数
long long int key = dist(rng);
c) 大数据测试模板
- 插入数据
double N[] = { 1,2,3,4,5,5.1,5.2,7 };
long long int sum = pow(10, N[num]);
start = GetTickCount64();
for (i = 0; i < sum; i++) {
long long int val = dist(rng);
XXX.Insert(val);
}
end = GetTickCount64() - start;
cout << "Average Insert time:" << (double)end / sum * 1000 << "微秒" << endl;
- 查询数据
start = GetTickCount64();
for (long long int i = 0; i < 1e6; i++) {
long long int key = dist(rng);
if (XXX.Find(key))
a++;
else
b++;
}
end = GetTickCount64() - start;
cout << "查找成功的概率:" << a / (a + b) << '\t';
cout << "Average Search time:" << (double)end / 1e6 * 1000 << "微秒" << endl;
- 删除数据
start = GetTickCount64();
for (i = 0; i < sum; i++) {
long long int val = dist(rng);
XXX.Delete(val);
}
end = GetTickCount64() - start;
cout << "Average Delete time:" << (double)end / sum * 1000 << "微秒" << endl;
4)评测结果及分析
测试页面如下,以下评测分析不再附上测试界面,以数据分析为主。(具体数据见附录excel表格)

a. 树表查询评测
a) 二叉搜索树
由前面的分析我们可以知道由于二叉搜索树在插入时,受到关键字是否随机影响较大,最坏情况达到O(n),平均情况达到O(logn)。
首先顺序插入、删除1-n个数字,根据二叉搜索树的性质,复杂度为O(n),效率较低。
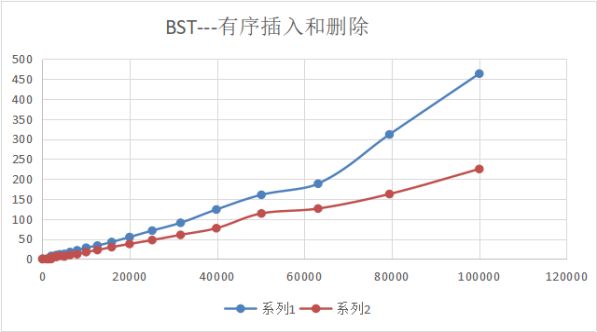
(蓝线:插入,红线:删除)
查找效率如图:
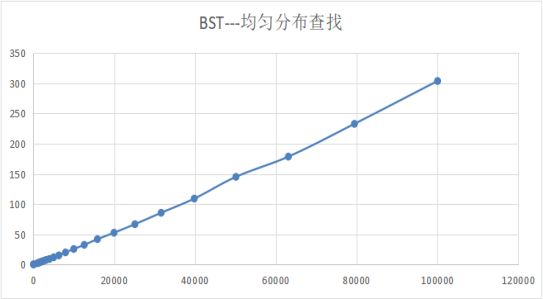
实验可得,当关键词随机性较低时,符合O(n),效率极低。
作为对比,以下为插入随机数列时,BST的测试图,符合O(logn)。

很明显,当数据量达到 1 0 7 10^7 107时,随机数列的平均层数仅为24层,与有序数列效率相差上百倍。
由此可见,关键字随机性对于BST的性能查找影响较大。由此引出以下数据结构—二叉平衡树。

b)二叉平衡树
二叉平衡树每次插入元素都会判断平衡因子是否被破坏,从而判断是否需要进行旋转操作。这样可以保证平均期望为O(logn)。
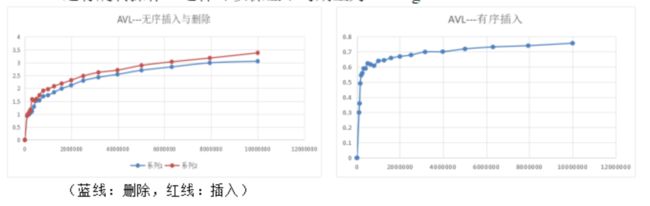
实验可得,二叉平衡树对于有序数列的处理同样高效,减少了关键字随机性对于效率的影响。
AVL树的查找方法与BST相同,并不会对树的结构产生影响。所以时间性能大致相同。

由此可见,二叉平衡树改善了对于关键字随机性的影响,但是对于查询效率影响不大。由此引出以下数据结构—二叉伸展树。

c)二叉伸展树
二叉伸展树虽然不是严格的平衡树,插入时效率会高于BST,低于AVL。其优势在于每次查找会将查询到的结点旋转到树根。因此二叉伸展树对于符合正态分布的数据查询会有明显的性能提升,时间性能为O(logn)。

实验可得,二叉伸展树对于密集的数据比较友好,可以提高效率。
b. 跳表与数组查询评测

跳表是链表查询的另一种数据结构。原理与二分法类似,时间性能为O(logn)。
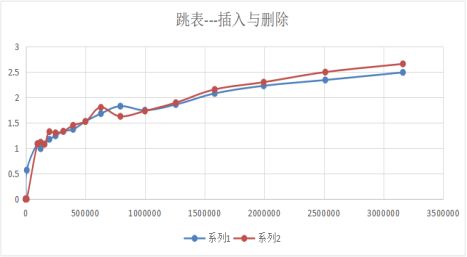

按照区间来查找数据这个操作,红黑树的效率没有跳表高。按照区间查找数据时,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了,非常高效。
最后是数组的查询评测。为了测试同为O(n)和O(logn),选择了顺序查找与二分查找两种算法。
首先是顺序查找,时间复杂度为O(n),显然在大量数据下不是一个优质的算法。

再然后是二分查找法。查找速度是相对高效的,但是创建数组时每次插入数据都需要保证数组是有序的,所以综合效率不如树表查询。

c. 总结

综合几个复杂度为O(logn)的查询算法,当数据量较大时,跳表和数组表现最差(大数组排序时间性能差),在树表比较中,Splay树由于每次都需要翻转节点,在数据比较均匀时,性能最差,但是当数据比较密集时,会有着显著的性能提升。AVL树与BST的查找性能是一致的,差别在于创建过程。

5)核心程序代码清单
头文件:
源文件:
