【信息检索】布尔检索和倒排索引
实验目的
掌握倒排索引(inverted index)的建立过程;掌握倒排记录表(postings lists)的合并算法
实验过程
1. 倒排索引
根据教材《Introduction to Information Retrieval》第8页Figure 1.4中所描述的倒排索引(reverted index)建立的详细过程,使用附件“HW1.txt”(文末)中的60个文档(每行表示一个document),用Java语言或其他常用语言实现倒排索引建立的详细过程。
使用语言:Python3
- 首先将文档读取到一个一维数据之中
代码:
# 打开文件
f = open('HW1.txt')
# 读取文章,并删除每行结尾的换行符
doc = pd.Series(f.read().splitlines())
结果:打印数组进行查看
0 Adaptive Pairwise Preference Learning for Coll…
1 HGMF: Hierarchical Group Matrix Factorization …
2 Adaptive Bayesian Personalized Ranking for Het…
3 Compressed Knowledge Transfer via Factorizatio…
4 A Survey of Transfer Learning for Collaborativ…
5 Mixed Factorization for Collaborative Recommen…
6 Transfer Learning for Heterogeneous One-Class …
7 Group Bayesian Personalized Ranking with Rich …
8 Transfer Learning for Semi-Supervised Collabor…
9 Transfer Learning for Behavior Prediction
10 TOCCF: Time-Aware One-Class Collaborative Filt…
- 将每篇文档转换成一个个token的列表
步骤:
a. 将文本全部转换成小写
b. 根据“非字符”对文本使用正则表达式进行切割(注:当出现两个连续非字符,会切割出现空串,需要手工删除)
代码:
# 转换为小写,并使用正则表达式进行切割
doc = doc.apply(lambda x: re.split('[^a-zA-Z]', x.lower()))
# 删除空串
for list in doc:
while '' in list:
list.remove('')
结果:打印token列表进行查看
Output exceeds the size limit. Open the full output data in a text editor
0 [adaptive, pairwise, preference, learning, for…
1 [hgmf, hierarchical, group, matrix, factorizat…
2 [adaptive, bayesian, personalized, ranking, fo…
3 [compressed, knowledge, transfer, via, factori…
4 [a, survey, of, transfer, learning, for, colla…
5 [mixed, factorization, for, collaborative, rec…
6 [transfer, learning, for, heterogeneous, one, …
7 [group, bayesian, personalized, ranking, with,…
8 [transfer, learning, for, semi, supervised, co…
9 [transfer, learning, for, behavior, prediction]
10 [toccf, time, aware, one, class, collaborative…
- 构建倒排索引
步骤:
a. 建立如下数据结构:
建立一个哈希表,key值为字符串,value值为列表。
其中key值中存储所有单词,并作为哈希表的索引;value值中第1位记录倒排索引长度,第2位开始记录每个单词出现文章的序号。

b. 遍历token列表:- 如果单词出现过,就将文章序号添加到列表尾部,并且长度加一。
- 单词第一次出现时,将单词加入哈希表。
代码:
hashtable = {}
for index, list in enumerate(doc):
for word in list:
if word in hashtable:
hashtable[word].append(index+1)
hashtable[word][0] += 1
else:
hashtable[word] = [1, index+1]
hashtable = dict(
sorted(hashtable.items(), key=lambda kv: (kv[1][0], kv[0]), reverse=True))
结果:
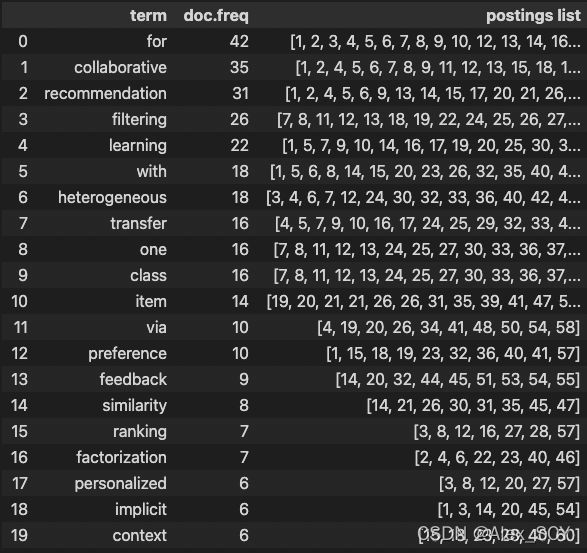
inverted_index = pd.DataFrame(columns=['term', 'doc.freq', 'postings list'])
for term in hashtable:
inverted_index = inverted_index.append(
{'term': term, 'doc.freq': hashtable[term][0], 'postings list': hashtable[term][1:]}, ignore_index=True)
display(inverted_index[:20])
2. 布尔检索
根据教材《Introduction to Information Retrieval》第11页Figure 1.6中所描述的倒排记录表(postings lists)的合并算法,使用第(1)题中的倒排索引,用Java语言或其他常用语言实现以下布尔检索:
a. transfer AND learning
b. transfer AND learning AND filtering
c. recommendation AND filtering
d. recommendation OR filtering
e. transfer AND NOT (recommendation OR filtering)
在完成题目之前,首先完成AND、OR、AND NOT三个函数的编写
- AND
思路:
参数为两个单词对应的倒排索引列表,返回值为完成AND操作后的结果列表。
需要完成的操作是将同时出现在list1,list2的index筛选出来。因为原先两个列表都是从小到大排序,因此,只需要不断地将指向较小数的指针不断向后移,遇到相同的index时,将index加入结果列表,直到一个指针走到底。
def And(list1, list2):
i, j = 0, 0
res = []
while i < len(list1) and j < len(list2):
# 同时出现,加入结果列表
if list1[i] == list2[j]:
res.append(list1[i])
i += 1
j += 1
# 指向较小数的指针后移
elif list1[i] < list2[j]:
i += 1
else:
j += 1
return res
- OR
思路:
参数为两个单词对应的倒排索引列表,返回值为完成OR操作后的结果列表。
需要完成的操作是将在list1,list2中出现的所有index合并筛选出来。思路与AND的解法大致类似,原先两个列表都是从小到大排序,因此,同样只需要不断地将指向较小数的指针不断向后移,区别是在index大小不相同时仍然需要将index加入结果列表,直到一个指针走到底。
因为OR操作是将两个列表合并,还需要将两个列表中剩余未遍历到的index加入结果列表之中。
def Or(list1, list2):
i, j = 0, 0
res = []
while i < len(list1) and j < len(list2):
# 同时出现,只需要加入一次
if list1[i] == list2[j]:
res.append(list1[i])
i += 1
j += 1
# 指向较小数的指针后移,并加入列表
elif list1[i] < list2[j]:
res.append(list1[i])
i += 1
else:
res.append(list2[j])
j += 1
# 加入未遍历到的index
res.extend(list1[i:]) if j == len(list2) else res.extend(list2[j:])
return res
- AND NOT
思路:
参数为两个单词对应的倒排索引列表,返回值为完成AND NOT操作后的结果列表。
需要完成的操作是将出现在list1,但是未出现在list2的index筛选出来。原先两个列表都是从小到大排序,因此,同样需要不断地将指向较小数的指针不断向后移,并且当指向list1的index较小时,将index加入结果列表,直到一个指针走到底。
假设list1未遍历完,list2已经结束,那么list1剩余的index一定不会出现在list2中,所以还需要将剩余未遍历到的index加入结果列表之中。
def AndNot(list1, list2):
i, j = 0, 0
res = []
while i < len(list1) and j < len(list2):
# index相等时,同时后移
if list1[i] == list2[j]:
i += 1
j += 1
# 指向list1的index较小时,加入结果列表
elif list1[i] < list2[j]:
res.append(list1[i])
i += 1
else:
j += 1
# list1 未遍历完,加入剩余index
if i != len(list1):
res.extend(list1[i:])
return res
- 辅助函数:从哈希表中获取倒排索引列表,并删除第一个元素(用于记录元素个数)
def getList(word):
return hashtable[word][1:]
a) transfer AND learning
结果:transfer AND learning: [5, 7, 9, 10, 16, 17, 25, 32, 33, 49, 55, 56]
print('transfer AND learning:', And(getList('transfer'), getList('learning')),'\n')
print('transfer:', getList('transfer'))
print('learning:',getList('learning'))
transfer AND learning: [5, 7, 9, 10, 16, 17, 25, 32, 33, 49, 55, 56]
transfer: [4, 5, 7, 9, 10, 16, 17, 24, 25, 29, 32, 33, 43, 49, 55, 56]
learning: [1, 5, 7, 9, 10, 14, 16, 17, 19, 20, 25, 30, 32, 33, 36, 41, 47, 49, 54, 55, 56, 58]
结果正确
b) transfer AND learning AND filtering
先计算transfer AND learning,在计算AND filtering
结果:transfer AND learning AND filtering: [7, 25, 33, 55, 56]
print('transfer AND learning AND filtering:', And(And(getList('transfer'), getList('learning')), getList('filtering')), '\n')
print('transfer:', getList('transfer'))
print('learning:', getList('learning'))
print('filtering:', getList('filtering'))
print('transfer AND learning:', And(getList('transfer'), getList('learning')))
transfer AND learning AND filtering: [7, 25, 33, 55, 56]
transfer: [4, 5, 7, 9, 10, 16, 17, 24, 25, 29, 32, 33, 43, 49, 55, 56]
learning: [1, 5, 7, 9, 10, 14, 16, 17, 19, 20, 25, 30, 32, 33, 36, 41, 47, 49, 54, 55, 56, 58]
filtering: [7, 8, 11, 12, 13, 18, 19, 22, 24, 25, 26, 27, 30, 33, 36, 37, 38, 41, 42, 46, 52, 54, 55, 56, 57, 58]
transfer AND learning: [5, 7, 9, 10, 16, 17, 25, 32, 33, 49, 55, 56]
结果正确
c) recommendation AND filtering
结果:recommendation AND filtering: [13, 26, 38]
print('recommendation AND filtering:', And(getList('recommendation'), getList('filtering')), '\n')
print('recommendation:', getList('recommendation'))
print('filtering:', getList('filtering'))
recommendation AND filtering: [13, 26, 38]
recommendation: [1, 2, 4, 5, 6, 9, 13, 14, 15, 17, 20, 21, 26, 29, 31, 32, 34, 35, 38, 39, 43, 44, 45, 47, 48, 49, 50, 51, 53, 59, 60]
filtering: [7, 8, 11, 12, 13, 18, 19, 22, 24, 25, 26, 27, 30, 33, 36, 37, 38, 41, 42, 46, 52, 54, 55, 56, 57, 58]
结果正确
d) recommendation OR filtering
结果:recommendation OR filtering: [1, 2, 4, 5, 6, 7, 8, 9, 11, 12, 13, 14, 15, 17, 18, 19, 20, 21, 22, 24, 25, 26, 27, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60]
print('recommendation OR filtering:', Or(getList('recommendation'), getList('filtering')), '\n')
print('recommendation:', getList('recommendation'))
print('filtering:', getList('filtering'))
recommendation OR filtering: [1, 2, 4, 5, 6, 7, 8, 9, 11, 12, 13, 14, 15, 17, 18, 19, 20, 21, 22, 24, 25, 26, 27, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60]
recommendation: [1, 2, 4, 5, 6, 9, 13, 14, 15, 17, 20, 21, 26, 29, 31, 32, 34, 35, 38, 39, 43, 44, 45, 47, 48, 49, 50, 51, 53, 59, 60]
filtering: [7, 8, 11, 12, 13, 18, 19, 22, 24, 25, 26, 27, 30, 33, 36, 37, 38, 41, 42, 46, 52, 54, 55, 56, 57, 58]
结果正确
e) transfer AND NOT (recommendation OR filtering)
先计算recommendation OR filtering,在计算AND NOT
结果:transfer AND NOT (recommendation OR filtering) [10, 16]
print('transfer AND NOT (recommendation OR filtering)', \
AndNot(getList('transfer'), Or(getList('recommendation'), getList('filtering'))), '\n')
print('transfer:', getList('transfer'))
print('recommendation:', getList('recommendation'))
print('filtering:', getList('filtering'))
print('recommendation OR filtering:', Or(getList('recommendation'), getList('filtering')))
transfer AND NOT (recommendation OR filtering) [10, 16]
transfer: [4, 5, 7, 9, 10, 16, 17, 24, 25, 29, 32, 33, 43, 49, 55, 56]
recommendation: [1, 2, 4, 5, 6, 9, 13, 14, 15, 17, 20, 21, 26, 29, 31, 32, 34, 35, 38, 39, 43, 44, 45, 47, 48, 49, 50, 51, 53, 59, 60]
filtering: [7, 8, 11, 12, 13, 18, 19, 22, 24, 25, 26, 27, 30, 33, 36, 37, 38, 41, 42, 46, 52, 54, 55, 56, 57, 58]
recommendation OR filtering: [1, 2, 4, 5, 6, 7, 8, 9, 11, 12, 13, 14, 15, 17, 18, 19, 20, 21, 22, 24, 25, 26, 27, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60]
附录:HW1.txt
Adaptive Pairwise Preference Learning for Collaborative Recommendation with Implicit Feedbacks
HGMF: Hierarchical Group Matrix Factorization for Collaborative Recommendation
Adaptive Bayesian Personalized Ranking for Heterogeneous Implicit Feedbacks
Compressed Knowledge Transfer via Factorization Machine for Heterogeneous Collaborative Recommendation
A Survey of Transfer Learning for Collaborative Recommendation with Auxiliary Data
Mixed Factorization for Collaborative Recommendation with Heterogeneous Explicit Feedbacks
Transfer Learning for Heterogeneous One-Class Collaborative Filtering
Group Bayesian Personalized Ranking with Rich Interactions for One-Class Collaborative Filtering
Transfer Learning for Semi-Supervised Collaborative Recommendation
Transfer Learning for Behavior Prediction
TOCCF: Time-Aware One-Class Collaborative Filtering
RBPR: Role-based Bayesian Personalized Ranking for Heterogeneous One-Class Collaborative Filtering
Hybrid One-Class Collaborative Filtering for Job Recommendation
Mixed Similarity Learning for Recommendation with Implicit Feedback
Collaborative Recommendation with Multiclass Preference Context
Transfer Learning for Behavior Ranking
Transfer Learning from APP Domain to News Domain for Dual Cold-Start Recommendation
k-CoFi: Modeling k-Granularity Preference Context in Collaborative Filtering
CoFi-points: Collaborative Filtering via Pointwise Preference Learning over Item-Sets
Personalized Recommendation with Implicit Feedback via Learning Pairwise Preferences over Item-sets
BIS: Bidirectional Item Similarity for Next-Item Recommendation
RLT: Residual-Loop Training in Collaborative Filtering for Combining Factorization and Global-Local Neighborhood
MF-DMPC: Matrix Factorization with Dual Multiclass Preference Context for Rating Prediction
Transfer to Rank for Heterogeneous One-Class Collaborative Filtering
Neighborhood-Enhanced Transfer Learning for One-Class Collaborative Filtering
Next-Item Recommendation via Collaborative Filtering with Bidirectional Item Similarity
Asymmetric Bayesian Personalized Ranking for One-Class Collaborative Filtering
Context-aware Collaborative Ranking
Transfer to Rank for Top-N Recommendation
Dual Similarity Learning for Heterogeneous One-Class Collaborative Filtering
Sequence-Aware Factored Mixed Similarity Model for Next-Item Recommendation
PAT: Preference-Aware Transfer Learning for Recommendation with Heterogeneous Feedback
Adaptive Transfer Learning for Heterogeneous One-Class Collaborative Filtering
A General Knowledge Distillation Framework for Counterfactual Recommendation via Uniform Data
FISSA: Fusing Item Similarity Models with Self-Attention Networks for Sequential Recommendation
Asymmetric Pairwise Preference Learning for Heterogeneous One-Class Collaborative Filtering
k-Reciprocal Nearest Neighbors Algorithm for One-Class Collaborative Filtering
CoFiGAN: Collaborative Filtering by Generative and Discriminative Training for One-Class Recommendation
Conditional Restricted Boltzmann Machine for Item Recommendation
Matrix Factorization with Heterogeneous Multiclass Preference Context
CoFi-points: Collaborative Filtering via Pointwise Preference Learning on User/Item-Set
A Survey on Heterogeneous One-Class Collaborative Filtering
Holistic Transfer to Rank for Top-N Recommendation
FedRec: Federated Recommendation with Explicit Feedback
Factored Heterogeneous Similarity Model for Recommendation with Implicit Feedback
FCMF: Federated Collective Matrix Factorization for Heterogeneous Collaborative Filtering
Sequence-Aware Similarity Learning for Next-Item Recommendation
FR-FMSS: Federated Recommendation via Fake Marks and Secret Sharing
Transfer Learning in Collaborative Recommendation for Bias Reduction
Mitigating Confounding Bias in Recommendation via Information Bottleneck
FedRec++: Lossless Federated Recommendation with Explicit Feedback
VAE++: Variational AutoEncoder for Heterogeneous One-Class Collaborative Filtering
TransRec++: Translation-based Sequential Recommendation with Heterogeneous Feedback
Collaborative filtering with implicit feedback via learning pairwise preferences over user-groups and item-sets
Interaction-Rich Transfer Learning for Collaborative Filtering with Heterogeneous User Feedback
Transfer Learning in Heterogeneous Collaborative Filtering Domains
GBPR: Group Preference based Bayesian Personalized Ranking for One-Class Collaborative Filtering
CoFiSet: Collaborative Filtering via Learning Pairwise Preferences over Item-sets
Modeling Item Category for Effective Recommendation
Position-Aware Context Attention for Session-Based Recommendation