YOLOv5训练自数据集(VOC格式)
关于YOLOV5训练YOLO格式数据集在上篇提到过【yolov5+deepsort运行和训练自数据集(自看)】
VOC数据集最终格式(此处是最终的实现效果,初始格式在下面):

其中JPEGImages中是所需要的所有图片,Annotations是所有图片标记之后生成的.xml文档,ImageSets中有名为Main的文件夹,文件夹下有test.py、train.txt、val.txt、trainval.txt四个文档(ImageSets文件夹和Main文件夹需要自己建立,Main中四个文档后续用代码生成),labels放的VOC转化为YOLO之后的.txt标签(后续代码生成),最后三个.txt文件是训练指定的路径文件(后续代码生成)
1.VOC数据集初始格式:

JPEGImages中是所需要的所有图片,Annotations是所有图片标记之后生成的.xml文档
2.新建ImageSets文件夹,在文件夹中再新建一个Main空文件夹,然后使用Main.py生成Main文件夹和其中的四个.txt文档,代码如下:
import os
import random
trainval_percent = 0.9 # 训练和验证集所占比例,剩下的0.1就是测试集的比例
train_percent = 0.8 # 训练集所占比例,可自己进行调整
xmlfilepath = 'VOCdevkit/VOC2007/Annotations'
txtsavepath = 'VOCdevkit/VOC2007/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
# print(total_xml)
num = len(total_xml)
list = range(num)
# print(list)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('VOCdevkit/VOC2007/ImageSets/Main/trainval.txt', 'w')
ftest = open('VOCdevkit/VOC2007/ImageSets/Main/test.txt', 'w')
ftrain = open('VOCdevkit/VOC2007/ImageSets/Main/train.txt', 'w')
fval = open('VOCdevkit/VOC2007/ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
# print(name)
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
运行Main.py之后将在 ImageSets文件夹下生成名为Main的文件夹,Main文件夹下有test.py、train.txt、val.txt、trainval.txt四个文档,效果如图:
3.使用xml_2_txt.py,生成labels文件夹和三个.txt文档,代码如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
#sets设置的就是
sets=['train', 'val', 'test']
# classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
classes = ["drone"] # 修改为自己的label
def convert(size, box):
dw = 1./(size[0]) # 有的人运行这个脚本可能报错,说不能除以0什么的,你可以变成dw = 1./((size[0])+0.1)
dh = 1./(size[1]) # 有的人运行这个脚本可能报错,说不能除以0什么的,你可以变成dh = 1./((size[0])+0.1)
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml'%(image_id))
out_file = open('VOCdevkit/VOC2007/labels/%s.txt'%(image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('VOCdevkit/VOC2007/labels/'): # 修改路径(最好使用全路径)
os.makedirs('VOCdevkit/VOC2007/labels/') # 修改路径(最好使用全路径)
image_ids = open('VOCdevkit/VOC2007/ImageSets/Main/%s.txt' % (image_set)).read().strip().split() # 修改路径(最好使用全路径)
list_file = open('VOCdevkit/VOC2007/%s.txt' % (image_set), 'w') # 修改路径(最好使用全路径)
for image_id in image_ids:
list_file.write('VOCdevkit/VOC2007/JPEGImages/%s.jpg\n' % (image_id)) # 修改路径(最好使用全路径)
convert_annotation(image_id)
list_file.close()
到此处数据集格式和文章开头的最终格式相同则没有问题了。
4.建立自己的.yaml
我是复制了一个VOC.yaml自己改的路径
train: VOCdevkit/VOC2007/train.txt #此处是xml_2_txt.py生成的train.txt的路径,不要弄成Main文件夹下的.txt
val: VOCdevkit/VOC2007/val.txt #此处是xml_2_txt.py生成的train.txt的路径,不要弄成Main文件夹下的.txt
test: VOCdevkit/VOC2007/test.txt #此处是xml_2_txt.py生成的train.txt的路径,不要弄成Main文件夹下的.txt
# Classes
nc: 1 # number of classes 数据集类别数量
names: ['drone'] # class names 数据集类别名称,注意和标签的顺序对应
5.因为初始的放图片的文件夹是JPEGImages,而yolov5默认的图片和标签对应的文件夹叫做images,所以要改动datasets.py中的代码,将
sa, sb = os.sep + 'images' + os.sep, os.sep + 'labels' + os.sep,改成
sa, sb = os.sep + 'JPEGImages' + os.sep, os.sep + 'labels' + os.sep,效果如图:
def img2label_paths(img_paths):
# Define label paths as a function of image paths
sa, sb = os.sep + 'JPEGImages' + os.sep, os.sep + 'labels' + os.sep # /images/, /labels/ substrings
return [sb.join(x.rsplit(sa, 1)).rsplit('.', 1)[0] + '.txt' for x in img_paths]如果你的数据集一开始存放图片的文件夹就是images的话,此处就不需要改动,但是在 xml_2_txt.py中要把最下面的读取图片的文件夹路径对应成images文件夹
for image_id in image_ids:
list_file.write('VOCdevkit/VOC2007/JPEGImages/%s.jpg\n' % (image_id)) # 修改路径(最好使用全路径)
convert_annotation(image_id)
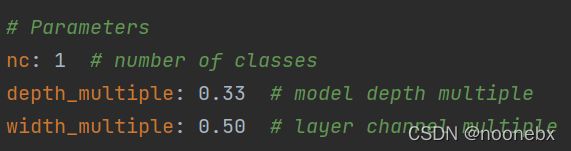
list_file.close()6. 在所用模型的.yaml中将nc类别数量改掉,我用的yolov5s.yaml,我的数据集只有一个类别:
7.train.py中把路径对应好,运行即可开始训练
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='weights/yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/try.yaml', help='datasets.yaml path')