Task05:推荐流程的构建
Task05:推荐流程的构建
- 0.代码版本
- 1. 整体文件
- 2. offline
-
- 2.1 流程图示
- 2.2 流程描述
-
- 2.2.1 update_hot_value()
- 2.2.2 group_cate_for_news_list_to_redis()
- 2.2.3 generate_cold_user_strategy_templete_to_redis_v2()
- 2.2.4 user_news_info_to_redis()
- 3. online
-
- 3.1 流程图示
- 3.2 流程描述
-
- 3.2.1 get_cold_start_rec_list_v2()
- 3.2.2 get_hot_list_v2
- 3.2.3 get_news_detail
- 3.2.4 update_news_dynamic_info
0.代码版本
该专栏的博客当中涉及的所有代码,均为组队学习期间的版本,大概在2021年12月12日左右,某一个可能的参考版本链接如下:
https://github.com/datawhalechina/fun-rec/tree/9bcfafaae339c443cc7911b9070bf52adef9e994
1. 整体文件
PS D:\Project\fun-rec\codes\news_recsys\news_rec_server\recprocess> tree /f /a
卷 Data 的文件夹 PATH 列表
卷序列号为 7876-8A9C
D:.
| `offline.py`
| 这里大概就是一个处理逻辑,主要控制`cold_start.py`和`hot_recall.py`
| 按照处理逻辑来说,先是`hot_recall.py`,更新热度后,更新分类新闻表
| 然后是`cold_start.py`生成冷启动模板,再将模板赋予具体的已有用户
|
| `online.py`
| 这个文件其实就是后端`server.py`当中调用的`RecsysServer`,是在线服务
| 先说说组件类的东西吧,也比较神奇,`_get_register_user_cold_start_redis_key`
| 这个玩意儿的作用是将计算出用户对应的冷启动模板,但是好像没有用到过
| 这个函数的功能实际上是在`cold_start.py`,由其他函数发挥对应的作用
| 关于`_set_user_group`组件,其在`cold_start.py`出现过,好像一模一样
| 其作用都是初始化模板对应的新闻类别,将文字的类别转换为`id`的类别,也无所谓
| 然后是`_get_register_user_group_id`组件,获取用户对应的模板类别
| 这个给我的感觉就是`cold_start.py`已经出现过相对应的处理逻辑了,这里又来
| 更神奇的是`_copy_cold_start_list_to_redis`,和`cold_start.py`中的一模一样
| 其功能都是给用户依次赋予其模板当中各个类别下所有新闻的新闻`id`,逻辑重复
| 我大概猜测了一下,`cold_start.py`应该是处理的旧数据,就是已经在注册表的
| 而`online.py`则是处理最新的,刚刚注册的,刚刚新增到用户注册表的新用户
| 那这个逻辑有点奇怪,`online.py`今天处理新用户,`cold_start.py`明天再处理
| 接下来是`_judge_and_get_user_reverse_index`,也就是检查用户的倒排索引表
| 也是分情况处理,主要应对热门页`hot_list`和推荐页`cold_start`,如果没有就新增
| 对于热门页,如果没有,就合并所有类别下的所有新闻给该用户的倒排索引
| 对于推荐页,如果没有,就合并该用户模板的新闻类别下的新闻给倒排索引
| 热门要的是全部类别的新闻,全局的;推荐要的是模板当中的类别的新闻,个性化
| 所以说这里就用上了上面那些和`cold_start.py`重复的逻辑,给新用户处理倒排索引
| 然后是`_get_user_expose_set`和`_save_user_exposure`两个针对曝光表的文件
| 两者应该都在下面获取热门页和获取推荐页的时候调用,先拿到曝光去重,再更新曝光
| 关于`_get_polling_rec_list`,其主要作用是轮询,也就是生成指定长度的新闻列表
| 同样针对热门页的推荐页的请求做出不同的处理,不过这里的区别也就在拼装的`key`不同
| 其大概的逻辑是,循环访问给定的新闻类别列表,每次对每个类别的新闻取其热度最高
| 然后记录该新闻对该用户的曝光,避免重复展示,然后在该用户的新闻列表内删除这个新闻
| 所以也就是说,其实我们对每个用户都维护了两个表,一个是热门表,一个是推荐表
| 但是每个用户的曝光表只有一个,热门页和推荐页都根据这个去重,不会在两个表重复出现
| 接下来`get_cold_start_rec_list_v2`就是功能部分了,用于从用户的推荐表返回推荐页面
| 首先当然要先拿到用户的曝光表,然后看看用户是否存在倒排索引表,也就是推荐表,没有则新建
| 拿到推荐表之后,再去拿用户模板当中的新闻类别,这个是用来在轮询的时候拼接`key`的
| 最后就是调用上面的轮询组件了,拿到推荐页,再调用上面的组件用推荐页更新曝光表
| 与之对应的`get_hot_list_v2`就是另一个功能了,用于从用户的热门表返回对应的热门页面
| 同样拿曝光表,再检查是否存在倒排索引表,也就是该用户的热门表,没有则新建
| 拿到热门表之后,再去拿所有新闻的新闻类别,这个是用来在轮询的时候拼接`key`的
| 最后就是调用上面的轮询组件了,拿到热门页,再调用上面的组件用热门页更新曝光表
| 下面又是功能,`get_news_detail`,获取新闻的内容的,上面针对新闻的操作都是`id`
| 最后的还是一个功能吧,`update_news_dynamic_info`,后端接到用户行为后就用这个更新
|
| `README.md`
| 项目说明文件
|
+---cold_start
| `cold_start.py`
| 顾名思义,设计上是用来处理冷启动的
| 但是至少在这个版本的代码上,只有这个
| 也就是说,对于新老用户,都是冷启动推荐
| 接下来说说该文件里面各函数的处理逻辑吧
| 执行该文件之前需要先去更新所有新闻的热度
| 首先是`_set_user_group`,在类的初始化进行
| 这个的主要作用是设定好四个冷启动的模板
| 模板依据性别和年龄划分,模板内是新闻类别
| 也就是说,给模板对应的人,推荐模板内的类
| 在这里我们只有新闻类别,没有新闻的具体内容
| 但是需要注意,这里仅仅建立模板内的新闻类
| 也就是说,给用户分配模板的处理在其他地方
| 然后`generate_cold_user_strategy_templete_to_redis_v2`
| 这里还不是分配模板,而是继续建设模板,加入新闻
| 在之前的模板内,只有新闻的类别,没有其他数据
| 在这里,我们将具体每个类的新闻填入模板,写入库
| 在编号为`0`的数据库,是有序集合类型`sorted set`
| `key`为`"cold_start_group:"+user_group_id+":"+cate_id`
| 意即冷启动模板`user_group_id`的`cate_id`的新闻类别
| `value`为`cate+'_'+news_id,score为新闻的hot_value`
| `value`意即`cate`种类下,所有新闻的新闻`id`,`news_id`
| 也就是说,现在每个模板下,都有对应的新闻`id`
| 所以至少现在可以做到给模板的人推荐对应的新闻
| 现在是`user_news_info_to_redis`函数,对用户进行处理
| 我们先根据性别和年龄判断类别,将用户指向对应模板
| 接着是`_copy_cold_start_list_to_redis`函数
| 我们用这个将模板赋予这个具体的用户,依次赋予每个类别
| 详细地,就是赋予该用户所属模板的每个类别的新闻
| 具体操作为并集,取该模板的每个类别的新闻的并集
| 也就是模板`user_group_id`的每个新闻类别`cate_id`的新闻
| 与具体的用户`user_id`的每个新闻类别`cate_id`新闻的并集
| `key`为`"cold_start_user:"+user_id+":"+cate_id`,其余同上
| 并集操作的意义是更新,因为每个类别每天都有新的新闻
| 在以上操作的同时,也建立了该用户所属模板有什么新闻类别
| `key`为`"cold_start_user_cate_set:"+user_id`,`value`是`cate_id`列表
|
|
|
\---recall
`hot_recall.py`
首先第一件事,那当然是更新所有新闻的热度,有一个计算公式
然后是更新按照类别划分的新闻热度的倒排索引表,依据热度排序
大概逻辑就是遍历每一个类别,然后生产`key`为`"hot_list_news_cate:"+cate_id`
然后赋予`value为cate+'_'+news_id`,对应的`score`为`hot_value`
2. offline
2.1 流程图示
2.2 流程描述
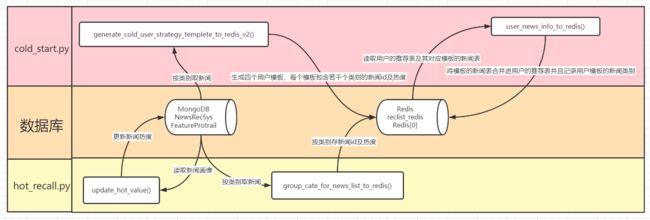
离线部分的处理主要由offline.py来控制逻辑,那就大概按照这个顺序说明离线处理流程吧
2.2.1 update_hot_value()
首先是更新物料的热度值,在hot_recall.py的update_hot_value()函数部分,有一个计算公式1
news_hot_value = (news_likes_num * 0.6 + news_collections_num * 0.3 + news_read_num * 0.1) *
10 / (1 + time_hour_diff / 72)
也就是
N e w s I n f o = l i k e s ∗ 0.6 + c o l l e c t i o n s ∗ 0.3 + r e a d s ∗ 0.1 T i m e D i f f = ( 1 + H o u r D i f f ) / 72 H o t V a l u e = N e w s I n f o ∗ 10 / T i m e D i f f \Large NewsInfo = likes*0.6+collections*0.3+reads*0.1 \\ TimeDiff = ( 1 + HourDiff ) / 72 \\ HotValue = NewsInfo * 10 / TimeDiff NewsInfo=likes∗0.6+collections∗0.3+reads∗0.1TimeDiff=(1+HourDiff)/72HotValue=NewsInfo∗10/TimeDiff
上述公式好像是根据魔方秀公式改的,也是个神奇的公式,如下:
魔方秀热度 = (总赞数 * 0.7 + 总评论数 * 0.3) * 1000 / (公布时间距离当前时间的小时差+2) ^ 1.2
最后的^表示幂运算,也就是1.2次方
再往上追溯,还能找到一个Hacker News算法,如下:
Score = (P-1) / (T+2) ^ G
P表示文章得到的投票数,需要去掉文章发布者的那一票
T表示时间衰减(单位小时)
G为权重,默认值为1.8
2.2.2 group_cate_for_news_list_to_redis()
这里的操作感觉是将新闻根据类别划分了一下,从MongoDB到Redis的0,reclist库
原始的新闻画像肯定是在MongoDB的NewsRecSys库的FeatureProtrail表当中
现在根据key为"hot_list_news_cate:"+cate_id,按照新闻类别cate_id进行存储
其value为value为cate+'_'+news_id,对应的score为hot_value,生成全局热门表
这里的全局热门表是为了接下来拷贝进入用户个人的热门表,就好像模板表和推荐表
所谓模板表其实就是全局推荐表,包含全部新闻,然后推荐表就是用户的个人表,个性化了
为什么要分全局表和个人表呢?因为要去重,个人表其实就是用户还没有看过的新闻
个人热门表就是用户在全部新闻的范围内,没有看过的新闻,主要是挑选一部分在热门页进行展示
而个人推荐表就是用户在模板中没有看过的新闻,模板是指冷启动的时候设定了用户偏好的新闻类别
同样,个人推荐表主要是用于轮询挑选后在推荐页进行展示,记录用户在模板范围内没有看过的新闻
2.2.3 generate_cold_user_strategy_templete_to_redis_v2()
这个函数的主要作用就是生成全局的推荐表,也就是上文所说四个模板中每个模板对应的新闻
数据的流动还是源自新闻特征画像,MongoDB中NewsRecSys库的FeatureProtrail表
然后根据每个预先设定模板当中的新闻类别,将各个类别的新闻按模板整理好
类似每个模板一个表的感觉,记录该模板对应的所有新闻的id和热度,但是实际并不是一个表
key为"cold_start_group:"+user_group_id+":"+cate_id,意即模板user_group_id的cate_id的新闻类别
value为cate+'_'+news_id,score为新闻的hot_value,意即cate种类下,所有新闻的新闻id,news_id
所以说,每个模板里面,新闻还是按类存储的,也就是说要先获得模板有哪些类,再拼接key查询
而这个东西,也就是模板对应的类,由_set_user_group在类初始化的时候已经完成了,存入了字典
所以我们可以根据self.user_group获得user_group_id和cate_id,拼接得到key来取出对应的数据
2.2.4 user_news_info_to_redis()
这里,就是将全局的推荐表,复制给用户,也就是按照模板初始化用户个人的推荐表
其具体调用_copy_cold_start_list_to_redis函数,取全局推荐表和个人推荐表的并集
也就是"cold_start_group:"+user_group_id+":"+cate_id和"cold_start_user:"+user_id+":"+cate_id的并集
在上文当中,我以为并集的意思是更新,因为全局的推荐表会随着物料的更新而更新
但是现在想想好像不太对,并集之后,结果应该就是全局推荐表,因为其包含了个人推荐表
个人推荐表是会随着用户的浏览,而不断删除浏览过的新闻,所以其相比缺失了浏览过了和新入库的
但是取了并集之后,浏览过的和新入库的又一起回来了,还是要根据曝光表对轮询结果进行去重
所以说这里的逻辑我不太理解,暂时还想不明白为什么要取并集,直接用新的全局表覆盖不好吗?
除此之外,_copy_cold_start_list_to_redis函数还赋予了该用户其模板当中的新闻类别
key为"cold_start_user_cate_set:"+user_id,value是该用户的模板当中所有新闻类别cate_id的列表
这个跟上面那个有点像,就是说,用户个人的推荐表,不是一张表,而是根据类别存的
所以说当我们有了用户对应模板当中的新闻类别,也就有了user_id和cate_id
所以说我们可以根据这个拼接出"cold_start_user:"+user_id+":"+cate_id,以此获得该用户的个人推荐表
3. online
3.1 流程图示
3.2 流程描述
这里就按照功能开始叙述吧,相关的组件在其被调用的时候说明
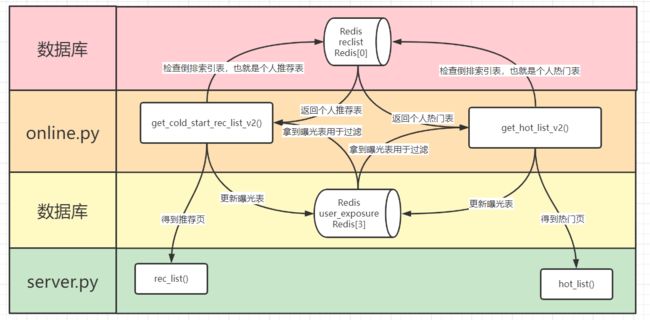
3.2.1 get_cold_start_rec_list_v2()
这个函数就是从用户的个人推荐表当中,轮询返回一个推荐页
函数开始,先调用_get_user_expose_set来获得当前用户的曝光表,用于去重
然后是用_judge_and_get_user_reverse_index,这个操作是检查是否存在个人推荐表
具体地,是查Redis[0]是否存在key为"cold_start_user:"+user_id+":"+cate_id
如果有就好,没有的话就先用_get_register_user_group_id获取该用户的分组,也就是模板编号
然后使用_copy_cold_start_list_to_redis,将该模板内所有的新闻复制到该用户的个人推荐表
确认了用户存在个人推荐表之后,要获取用户对应模板的新闻类别,用于拼接key
这里是直接查表,在Redis[0]当中查询key为"cold_start_user_cate_set:"+user_id
所以我们获得了userid和cateid,可以拼接"cold_start_user:"+user_id+":"+cate_id
然后用获得的模板内多个cateid,去作为参数传入_get_polling_rec_list函数进行轮询
在这里,我们拼接出"cold_start_user:"+user_id+":"+cate_id,查用户的个人推荐表
然后根据上面获得的曝光表进行去重,直到获得的新闻数量足够推荐页展示
注意,每次有效获得新闻后,都要从该用户的个人推荐表中删除,以防重复
这里不仅返回了推荐页,也返回了这次的曝光列表,用_save_user_exposure更新
3.2.2 get_hot_list_v2
这个其实很大程度上可以参考上面的流程,我在叙述的时候做一些简化
同样先用_get_user_expose_set开局,获得曝光表防止重复
然后_judge_and_get_user_reverse_index判断是否存在用户个人的热门表
如果不存在的话,就把全部的新闻按类别拷入,相当于新建了
这里的key也是拼接的,userid和cateid,cateid是全部的,用默认的就好
接着也是_get_polling_rec_list获得热门页的结果以及这次的曝光列表
再用_save_user_exposure更新,最后将结果传给后端的hot_list()
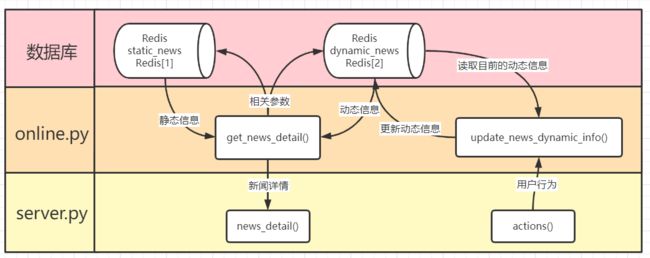
3.2.3 get_news_detail
拼接新闻的动态和静态信息,返回给后端的news_detail()
3.2.4 update_news_dynamic_info
先查询该新闻当前的动态信息,再根据后端actions()传入的参数更新
Task05 推荐流程的构建 ↩︎