Mx-yolov3环境配置+本地模型训练+K210
文章目录
一、Mx-yolov3环境配置
二、模型训练
1.测试
2.数据集制作
3.VOTT标注与模型测试
三、部署到k210
1.模型转换
2.脚本运行
3.脱机运行
4.一个问题
四、总结
一、Mx-yolov3环境配置
1. Mx-yolov3软件下载:链接:https://pan.baidu.com/s/1U0c6hk5PNdOwECnhu_XjuA 提取码:fy22
2. 在安装路径中打开文件夹,打开环境配置,运行环境配置.exe。

3.安装python3.7.4
点击安装Python3.7.4会弹出python的安装界面,然后跟随视频 【K210】识别神器Mx-yolov3安装教程_哔哩哔哩_bilibili的操作安装即可。
如果你的电脑安装过其他版本的python,要先卸载、删除干净,不然后面Mx-yolov3训练时会报错。
4.安装依赖包和预训练权重
点击安装python依赖库和预训练权重,会弹出终端窗口自动安装,如果出现报错,应该检查python3.7.4是否安装在默认路径上。
5.安装CUDA和cudnn
点击安装cuda和cudnn,会弹出安装包的路径窗口,点击安装教程。
Cuda和Cudnn 安装教程|极客教程
也可参考http://t.csdn.cn/33Ml1,但Mx-yolov3文件夹内已有安装包,所以可以跳过下载教程,从安装开始跟着教程走。
二、模型训练
1.测试
环境配置好后,我们就可以开始本地模型训练,首先我们不要急着去制作数据集进行模型训练,可以先利用文件夹内现成的数据集去测试一下,一般首次打开软件后训练图片地址和训练标签地址已经填好了,直接点击开始训练,如果没报错说明环境配置成功。
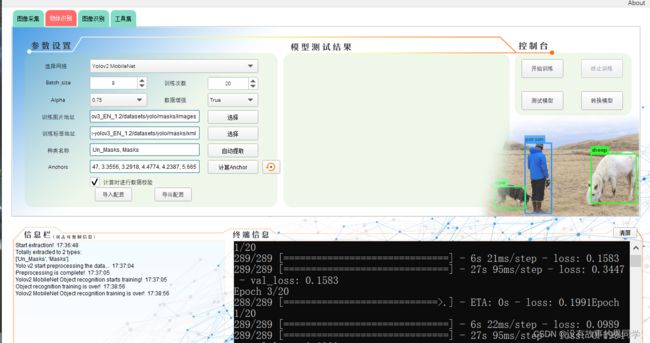
2.数据集制作
测试证明环境配置成功后我们就可以开始制作数据集开始进行本地训练。制作数据集需要拍摄大量照片,因为我使用的是k210,所以我们可以利用脚本自动拍照,照片会自动保存在sd卡内,所以我们得为K210准备一张sd卡。
自动拍照脚本 链接:https://pan.baidu.com/s/18wraqZQrdgvrm2wm1Gnx4Q 提取码:fy22
下载完毕后打开第三个物体检测拍照脚本
部分代码示例
boot_press_flag = 1
start = time.ticks_ms()
end = time.ticks_ms()
ui_num = 0
image_save_path = "/sd/image/"#图片保存目录头
claass = 0#文件夹名
image_num = 0#图像文件保存名
#完整图片保存路径image_save_path+claass+"/"
image_data = image.Image()#图像
shoot_flag = 0
first_button = 0#第一次点击boot按钮标志
##################################################################################
def sensor_init():#摄像头初始化
sensor.reset(freq=22000000, dual_buff=False)
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.set_vflip(1)
sensor.set_windowing((240, 240))
sensor.run(1)
##################################################################################
def lcd_init():#LCD初始化
lcd.init(type=1, freq=15000000, color=bg)
lcd.clear()
##################################################################################
def button_init():#boot按钮初始化
global key
fm.register(board_info.BOOT_KEY, fm.fpioa.GPIOHS0)
key = GPIO(GPIO.GPIOHS0, GPIO.PULL_UP)
##################################################################################
def boot_key_irq(pin_num):#boot按钮中断
global ui_num
global boot_press_flag,start,end
global claass
global image_num因为我们制作的数据集照片分辨率必须为240*240,所以我们可以修改代码63行,但是缺点就是k210屏幕显示不完整,优点就是不用再将照片进行分辨率转化。拍摄完毕后会得到100张照片,首先在桌面创建一个文件夹,将照片存在其中,然后删除SD卡内的所有文件,重新插至k210 重复上述操作。
制作数据集时照片越多越好,这样训练出来的模型精确度越高。
3.VOTT标注与模型测试
数据集制作完成后我们就可以开始标注了,这里我们使用的是vott
vott安装包
其中提供了windows/linux/mac下编译好的可执行文件,直接下载即可。
软件下载好后我们就可以开始标注了
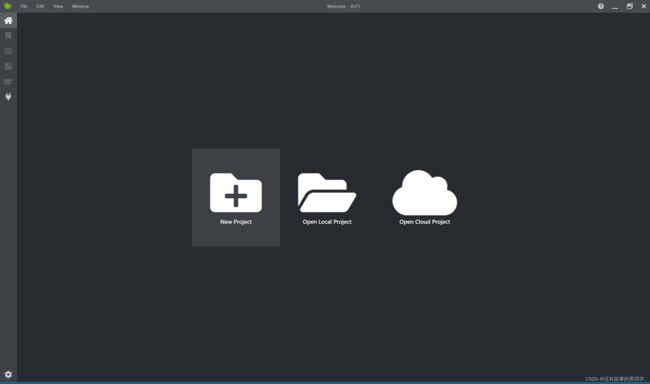
新建一个项目
Display Name:项目名称
Security Token:一般就选默认
Source Connection:原始数据路径,就是原来你照片存放的位置
Target Connection:目标数据存放路径,就是标注完成后文件存放的位置
Description:项目描述
Frame Extraction Rate(frames per a video second):视频帧率
Tags:待标注的标签列表,可用英文自己设置
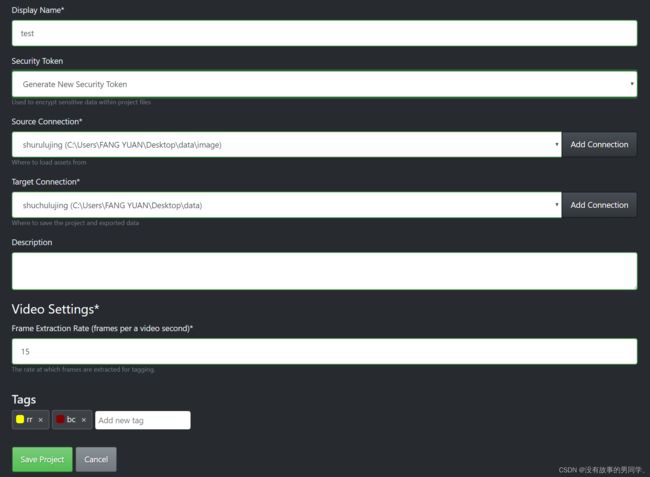
设置好后点击保存就可以开始标注了
当所有照片标注完毕后先点击保存,然后再点击右边的箭头(避坑,这个必须点,不然导出的文件全是JSON格式,不是Mx-yolov3需要的xlm格式)最后我们再选择左边的导出箭头。
导出时有多种格式可选,如果使用k210官网进行云端训练则导出JSON格式,使用Mx-yolov3则选择VOC格式。
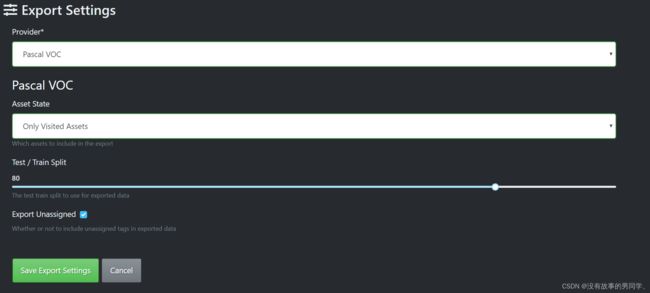
导出完毕后会存储在你设置的输出路径文件夹内,如图。

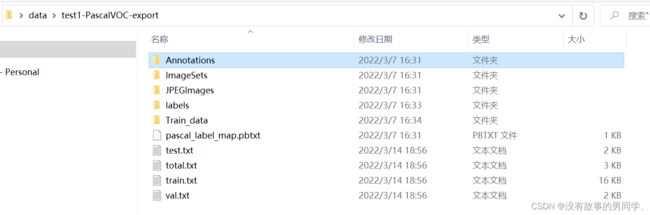
Annotations文件夹里就是Mx-yolov3所需的xml文件格式。到这我们就可以去进行模型训练了。训练图片地址选择原先存放照片的文件夹,而训练标签地址就是上一步我们导出所得到的xml文件,如下图所示,然后点击开始训练。
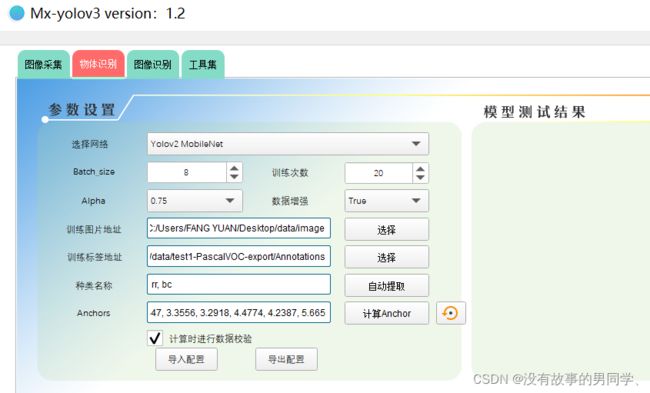
训练完毕后在会自动弹出一个文件夹,如图所示

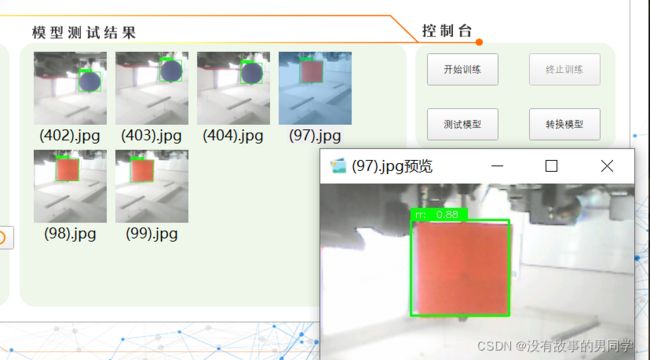
我们会看到一个h5文件,这个时候我们就回到Mx-yolov3去测试模型,点击测试模型后选中文件夹中的h5,等待一会后会出现如图所示的结果,点击图片放大能看到左上角显示rr,0.88,rr是我标注时自己设置的标签,代表红色的圆形,0.88就是识别率,到这里表示我们的本地模型训练完成。
三、部署到k210
1.模型转换
测试完毕后我们就要部署到k210上,首先我们要将训练出来的文件转换成k210适配的kmodel文件,点击Mx-yolov3模型转换,模型输入路径就是训练完毕后得到的tflite文件,输出路径就是转换后kmodel文件存放的位置,建议放在一个文件夹下,方便查找。
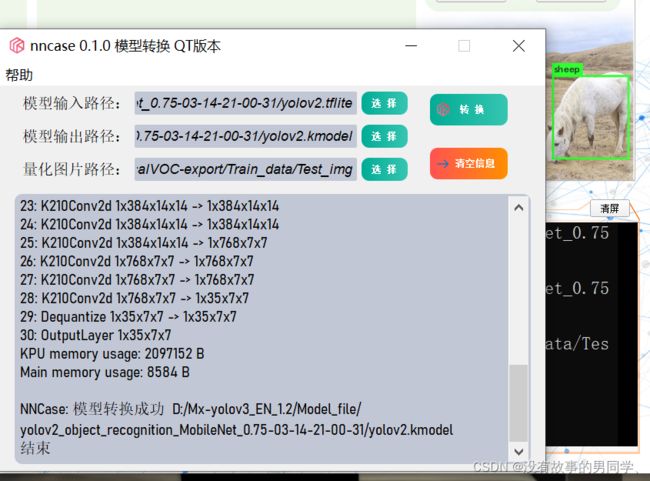
这里需要注意的是量化图片路径必须和模型输入,输出路径在一个盘。因为我制作数据集时是直接在桌面新建文件夹,默认在c盘,vott导出文件时也在这个文件夹下,最后导致模型转换失败,所以我们可以将导出时的文件移到d盘后再添加,如图所示。

转换完毕后可以看到我们的模型文件夹下多了一个kmodel文件。

2.脚本运行
打开kflash,用数据线将电脑和k210连接,将固件和kmodel文件烧录到开发板中,如图所示


注意烧录时地址不能一样,kmodel使用0x300000,烧录完毕后我们就可以打开IDE用脚本运行。
import sensor
import image
import lcd
import KPU as kpu
lcd.init()
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.set_windowing((224, 224))
sensor.set_hmirror(0)
sensor.run(1)
task = kpu.load(0x300000) #使用kfpkg将 kmodel 与 maixpy 固件打包下载到 flash
anchor = (0.9654, 1.1208, 1.7105, 2.1856, 2.5347, 3.3556, 3.2918, 4.4774, 4.2387, 5.665) #通过K-means聚类算法计算
a = kpu.init_yolo2(task, 0.6, 0.3, 5, anchor)
classes=["rr","bc"] #标签名称要和你训练时的标签名称顺序相同
while(True):
img = sensor.snapshot()
try:
code = kpu.run_yolo2(task,img)
except:
print("TypeError")
#a=img.draw_rectangle([0,0,360,20],0xFFFF,1,1)
if code:
for i in code:
a=img.draw_rectangle(i.rect(),(255, 255, 255),1,0)
a=lcd.display(img)
# = img.draw_string(0,0, classes[i.classid()], color=(0,255,0), scale=2)
for i in code:
lcd.draw_string(i.x()+40,i.y()-30,classes[i.classid()] , lcd.RED, lcd.WHITE)
lcd.draw_string(i.x()+40,i.y()-10,str(round((i.value()*100),2))+"%", lcd.RED, lcd.WHITE)
else:
a = lcd.display(img)
a = kpu.deinit(task)
连接运行后如图所示,识别率只有60~70%左右,是因为数据集我只拍了200张照片,数据集越多识别越准确,拍照时物体也尽可能多移动位置,抗干扰能力也就越强。

3.脱机运行
脱机运行则不需要烧录kmodel文件,但需要准备一张内存卡,将模型文件夹内的anchor.txt文件、label.txt文件、转换得到的yolov2.kmodel模型文件、程序文件内的物体识别脚本boot.py拷贝到sd卡即可

 上电运行结果如图
上电运行结果如图

4.一个问题
脱机运行我自己在做时做了一下午,我没想到boot文件竟然和脚本运行时的boot文件是一个也能运行,因为我做过k210官方的云端训练,云端训练完毕后会自动生成一个boot文件用于脱机运行,所以我照着那个代码自己改了一下,但是却无法运行,我想应该是代码的问题,下面是我的代码,如果有路过的大佬希望可以指点一下。
import sensor, image, lcd
import KPU as kpu
lcd.init()
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.set_windowing((224, 224))
sensor.set_hmirror(0)
sensor.run(1)
task = kpu.load("/sd/yolov2.kmodel")
f=open("anchors.txt","r")
anchor_txt=f.read()
L=[]
for i in anchor_txt.split(","):
L.append(float(i))
anchor=tuple(L)
f.close()
f=open("lable.txt","r")
lable_txt=f.read()
lable = lable_txt.split(",")
anchors = (0.9654, 1.1208, 1.7105, 2.1856, 2.5347, 3.3556, 3.2918, 4.4774, 4.2387, 5.665)
a = kpu.init_yolo2(task, 0.7, 0.3, 5, anchor)
classes= ["rr", "bc"]#gt=1 rr=2 vb=3 bc=4 fb=5
while(True):
img = sensor.snapshot()
code = kpu.run_yolo2(task, img)
if code:
for i in code:
a=img.draw_rectangle(i.rect(),(0,255,0),2)
a = lcd.display(img)
for i in code:
lcd.draw_string(i.x()+45, i.y()-5, classes[i.classid()]+" "+'%.2f'%i.value(), lcd.WHITE,lcd.GREEN)
else:
a = lcd.display(img)
a = kpu.deinit(task)
四、总结
模型训练是我在做非接触物体尺寸形态测量时用到的一个方法,用的是k210云端训练。后来因为考虑到云端训练耗时问题才想着去做本地训练,这次本地训练虽然基本完成,但也存在很多问题,比如识别率低,矩形框不稳导致中心坐标变化大等等问题,这都需要去解决。写下这篇博客的是为了记录自己的学习生活,因为我自己在做时也花了很长时间去找教程,查资料,这个过程是痛苦的,所以我想能不能从环境配置到模型训练到最后k210能运行来自己写一个完整的教程去帮助更多的人,因为自己也是一个小白,所以肯定也有很多错误的地方,希望我们可以一起交流学习。