ResNet论文笔记及Pytorch代码解析
注:个人学习记录
感谢B站up主“同济子豪兄”的精彩讲解,参考视频的记录
【精读AI论文】ResNet深度残差网络_哔哩哔哩_bilibili
算法的意义(大概介绍)
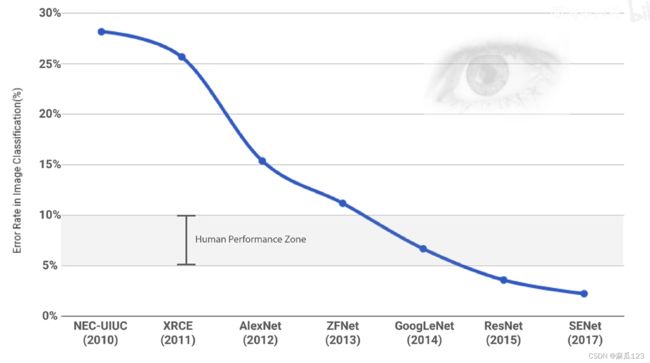
CV史上的技术爆炸,第一次是AlexNet首次把深度学习和卷积神经网络用在了大规模计算机视觉任务中,并取得了显著的进展,第二次技术爆炸就是ResNet,让计算机的识别效果超过了人眼,可以使用更深的网络进行研究。
2015年ResNet的成绩,2016年CVPR最佳论文,2015竞赛中进一步赢得了ImageNet检测、ImageNet定位、COCO检测和COCO分割的第一名

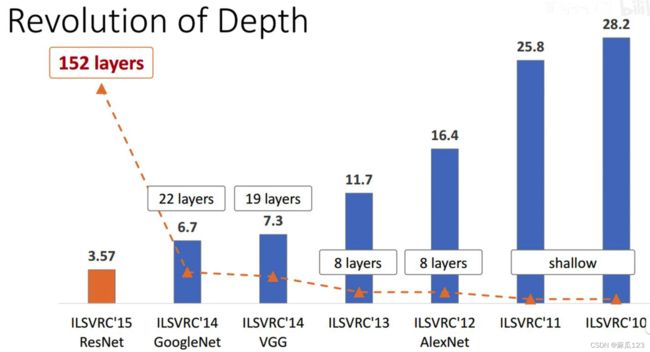
ResNet使用了152层的深度网络,深层次网络可以提取更多而且有效的特征,可以用在不同的领域(目标检测、图像分割、图像识别、定位等),从更丰富的特征中获得更好的效果
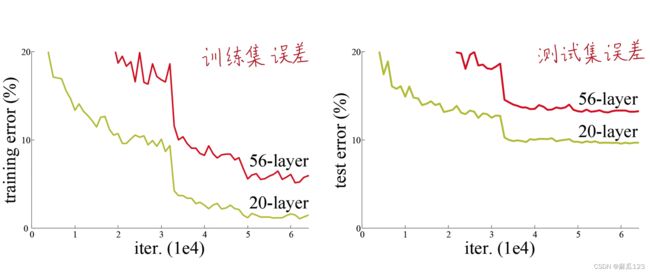
解决的最主要的问题“网络退化问题”(网络变深,效果表差,后面的网络没有进行有效的学习,训练和测试的误差都高。过拟合是训练错误率低,测试错误率高)
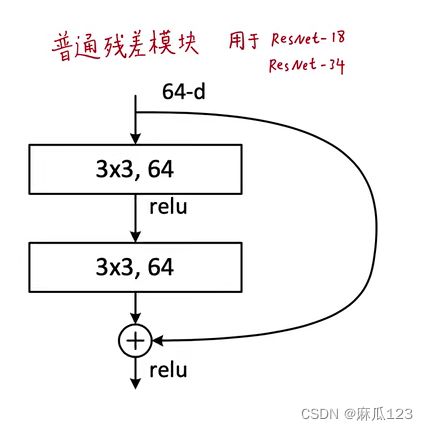
添加了一个残差模块,相比常规神经网络多加了一条路,右边的路是将未经过网络的数据直接和经过后数据进行相加,这里的相加是进行逐个元素求和
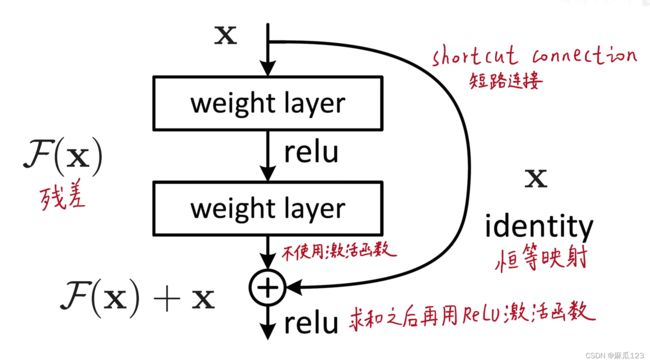
ResNet为什么可以解决网络退化问题
深层梯度回传顺畅
恒等映射这一路的梯度为1,把深度梯度注入底层,防止梯度消失。(没有中间商赚差价)
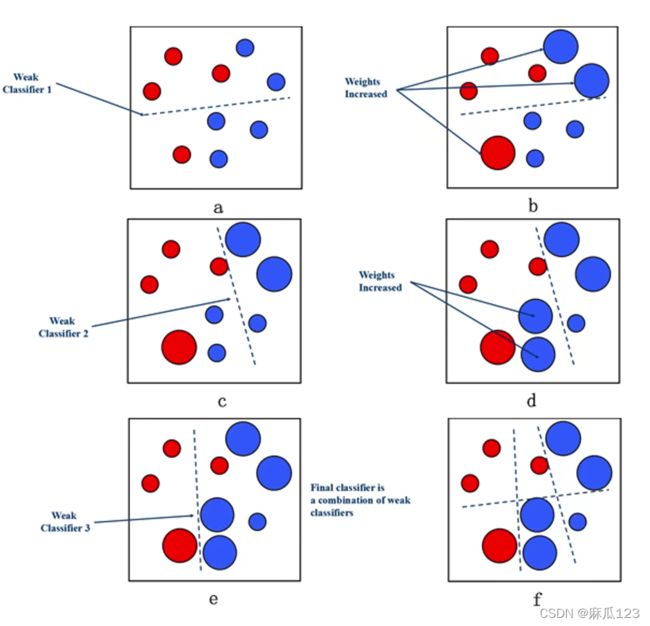
下面两个图进行了大致的解释,图一中以为每次分类的效果不好,所以在进行第二次分类之前就把之前分错的数据巨大化(把重要性提高),第二次分类就可以将这两种在分开,之后再将分错的数据巨大化,以此类推下去就可以得到一个把两种数据分开的曲线。
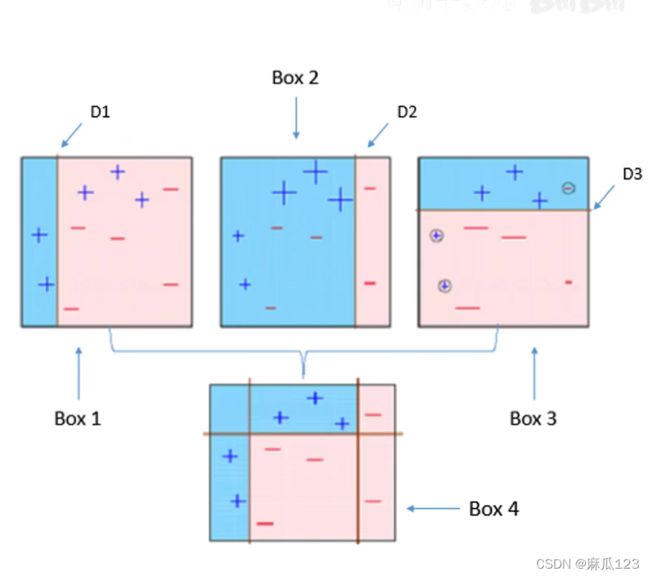
图二中类似,只是换了另一种方式,使用三个不同的分类来修正分类,使用D2、D3修正D1。
类比到其他机器学习模型
集成学习boosting,每一个弱分类器你和“前面的模型与GT之差”
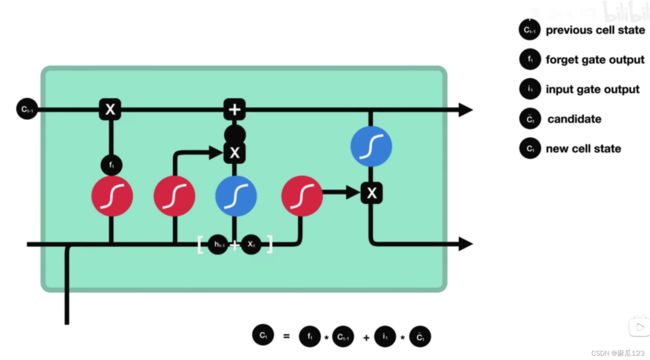
长短时记忆神经网络LSTM的遗忘门
ReLu激活函数(x>0时输出x,x<0时输出0),重要时输出,不重要时丢弃
传统线性结构网络难以拟合“恒等映射”
什么都不做优势很重要,传统神经网络中,输入和输出相同的模型没有,中间总会处理些什么
"ship connetction"可以让模型自行选择要不要更新
弥补了高度非线性造成的不可逆的信息损失(MobileNet V2)
ResNet反向传播传回的梯度相关性好
这篇论文里有具体介绍

大致介绍:网络加深,相邻像素回传回来的梯度相关性越来越低,最后接近白噪声。
单相邻像素之前具有局部相关性,相邻像素的梯度也应该局部相关。
相邻像素不相关的白噪声梯度只意味着随机扰动,并无拟合。
ResNet梯度相关性衰减从1/2^L增加为1/根号L。保持了梯度相关性。
神经网络的可解释性分析*(主要是对神经网络黑箱的解释)
具体可以参考一下网址进行详细内容了解
Resnet到底在解决一个什么问题呢?Resnet到底在解决一个什么问题呢? - 知乎
Resnet是否只是一个深度学习的trick?Resnet是否只是一个深度学习的trick? - 知乎
为什么resnet效果会那么好?为什么resnet效果会那么好? - 知乎
论文内容笔记
Abstract
提出残差学习结构,解决非常深网络的退化问题和训练问题。每层都学习相对于本层输入的残差,然后与本层输入加法求和,残差学习可以加快优化、加深层数、提高准确度。
基于VGG19训练了一个152层的网络模型,该网络模型的参数量更小,准确度更高
ResNet五项竞赛冠军 ImageNet COCO CIFAR-10的分类、分割、目标检测
1、Introduction(介绍背景以及研究的不足点)
深度卷积神经网络中一般集成底层-中层-高层的特征图(ZFNet论文进行了可视化),特征的不同“levels”有不同的作用,例如,底层特征负责提取边缘、形状等,中层负责某种纹理,高层负责纹理中特化的特征(眼睛、轮子)
VGG、GoogleNet等网络结构都表明更深的网络用于提取特征有不错的效果,
Is learning better networks as easy as stacking more layers?那简单粗暴的堆深网络是否可以做到提高精度的功能呢?
答案是不可以,有两个问题会阻碍收敛:
1、梯度消失和梯度爆炸问题 这些问题可以通过使用权重初始化技巧解决,例如Xavier初始化、MSRA初始化(可以参考cs231n李飞飞的公开课) 适当的权重初始化+Batch Normalization 可以加快网络收敛
2、网络退化(degrades)问题(不是由梯度消失和过拟合导致的)
网络越深,训练集上误差愈大 本文主要解决的就是该问题
这表明不是任何网络都能用相同的方式(加深网络)优化
文章中提出了一种方案,使用一种递归的浅模型进行问题解决,第二个浅模型结构也是如图所示的结构
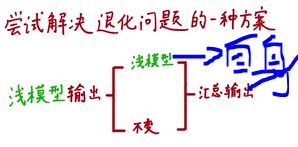
该模型加深网络至少不会让网络结构变得更差,以为如果走下面“不变”,输出和输入就相同,但是这种递归结构的网络很难求解优化
残差模块
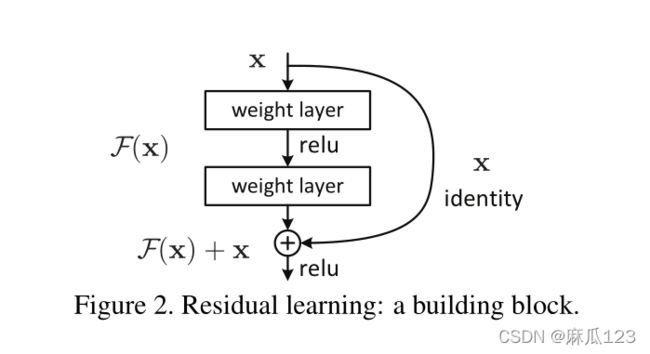
右边箭头代表的是“identity”或者叫"shortcut connections",改变之后的拟合方式改变了,从以前的直接拟合H(x)“底层映射”变为拟合残差F(x) = H(x) - X,这样当输入足够好时,残差块输出为0
"shortcut connections"在本网络中只进行恒等映射,不引入额外的参数量和计算量,同样可以使用随机梯度下降方法和端到端进行训练。
在ImageNet上的测试结果表明: 1)易于优化收敛 2)解决退化问题 3)可以很深 网络模型的准确率相较之前大大提升了
在CIFAR-10数据集上的测试表明,使用100层网络和1000层网络进行对比,发现同样出现网络退化问题
在各大竞赛上的结果,可以证明深度残差学习的原则是普适的,使用其他计算机视觉方面
2、Related Work(相关工作/文献综述)
该部分主要是介绍其他类似的研究中的不足
2.1、“残差表示”的现有工作
18号文献“VLAD"和30号文献”Fisher Vector"他们的工作表明残差向量在结果中表现更好
在计算机图形学中,为了解决偏微分方程问题,广泛的使用多重网格,把问题分解成若干子问题,每个子问题都是要求得一个粗粒度和细粒度的一个残差。多重网格的替换方法时使用级联机方法,该方法也是使用残差解决问题。但现有工作都没有体现残差现象更本质的运用于机器学习的提升。
2.2、"shortcut connections"现有工作
shortcut connections在之前就有被提及和研究,例如训练多层感知机时添加一个线性层连接输入和输出层、GoogleNet中的辅助分类器用于解决梯度消失,其中“inception”也是包含了shortcut连接的
“highway networks”: 门控函数 扮演残差角色 门控参数 有学习的到 深层网络性能提升不明显
相比“highway networks”的本文中使用的“shortcut ”没有参数,现有表明也没有发现把它用在较深的网络中有效果
传统的“shortcut ” is “close时,它就变成了输入什么样输出什么样的门
3、Deep Residual learning(深度残差网络)
3.1、Residual learning
万能近似定理(universal approxiamation theorem):如果一个前馈神经网络具有线性输出层和至少一层隐藏层,只要给予网络足够数量的神经元,便可以实现以足够高精度来逼近任意一个在 ℝn 的紧子集 (Compact subset) 上的连续函数。(暂时没证明)
这里介绍了该研究的做法,不去拟合H(x),而是拟合残差F(x) = H(x) - X,最后的值是F(x)+x。神经网络在拟合恒等映射的性能比较差
后面的网络只拟合前面网络的输出与期望函数的残差
3.2、Identity Mapping by Shortcuts(通过短路连接传递自身映射)
残差使用数学公式分析

![]()
其中x为输入,经过W1网络层,在经过一层激活函数,之后传给W2网络层不进行激活
其中的偏置项忽略,如果卷积层后加BN层则不需要偏置项
之后将偏置项和输入加起来F(x) + x,并使用shortcut进行逐元素对应相加 ,之后将相加的结果再进行一次激活(relu)
残差F(X)与自身输入x维度必须一致才能实现,elment-wise相加
也可以使用方阵(输入和输出是一样大小)
3.3、Network Architectures(带残差网络和不带残差网络的对比)
3.3.1、Plain Network
一种类似VGG结构的网络,都是用3x3的卷积核,每个block内filter个数不变,feature map大小减半时 filter个数*2,使用步长为2的卷积进行下采样(类似vgg的池化)。全连接层替换为GPA(global average pooling),使用更少的参数量和计算量防止过拟合。三种结构如下图:
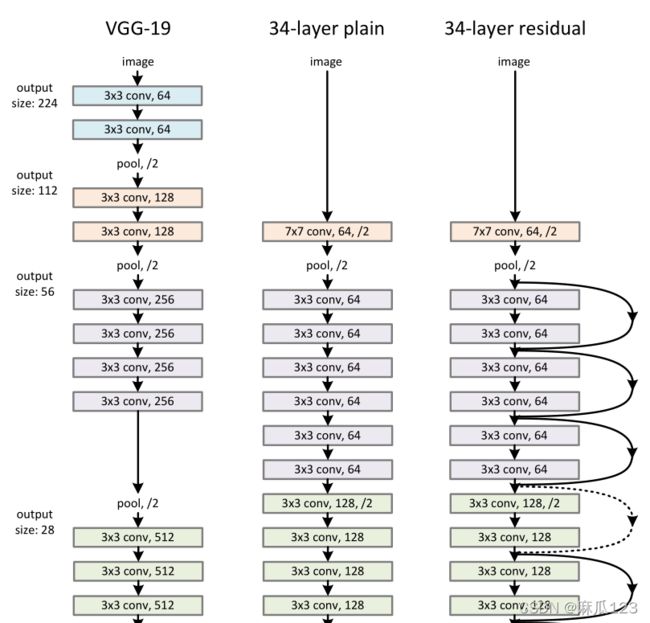
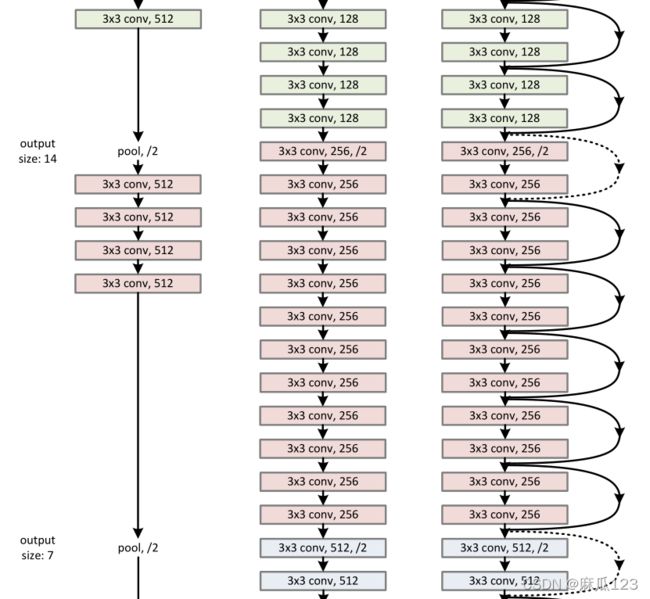
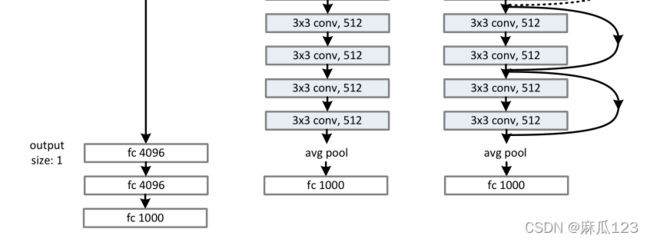
3.3.2、Residual Network
残差网络就是将前面介绍的普通网络添加残差模块
其中在残差网路结构中,shortcut会有两种,一种是实线就是直接将输入传给输出,虚线则是使用了下采样,下采样采用步长为2的卷积,这里涉及到数据的大小调整,有三种方法实现:
1)多出来的通道padding补零填充(为引入额外计算量 2)用1x1卷积升维 3)暂未介绍
3.4、Implementation
训练阶段-图像增强-超参数
图像增强采用不同尺度[21,41] [256,480],不同位置(在224x224的图像中随机剪裁图像),使用通alexnet相同的方式,计算一张图的像素点均值,在进行训练时让所有的像素点减去像素点均值。具体见ALEXNET
训练阶段:在每一个卷积层后面和激活之前都是使用BN(batch normalization)
使用SGD的mini-batch size 为256
学习率开始使用0.1,遇到瓶颈时除以10(先大走,再慢慢走),并训练60万个迭代次数
权重使用0.0001,动量使用0.09,不使用dropout(因为不可以和BN共存)
测试阶段:多尺度裁剪与结果融合(fully-convolutional form),即将图像缩放到不同尺度,对不同尺度的结果进行融合。
4、Experiments
4.1、ImageNet Classfication (使用了Imagenet 中的1000个类别分类图片数据集)
4.1.1、Plain Networks:
实验结果如下图:
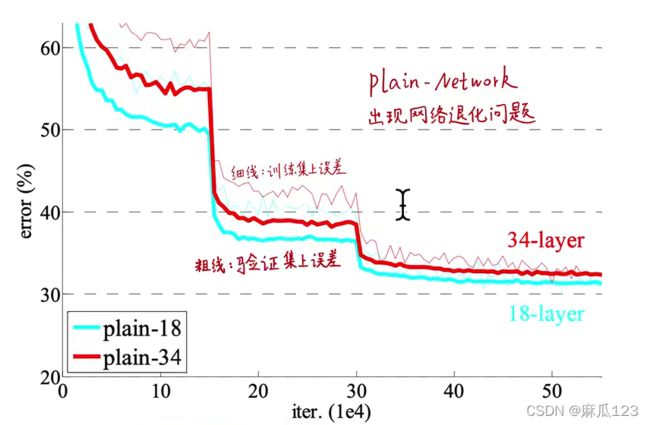
34层普通网络的模型容量和求解空间比18层大,但训练集上误差始终比18层高
其中前向传播和反向传播都是良好的,不是因为过拟合等问题,应该是“网络退化问题”,网络退化问题不是由梯度消失导致的
文中尝试解释了网络退化问题:深度的普通网络,网络深度加大,收敛的速度指数级的降低,这不利于训练误差的降低。使用更多次的迭代训练并不能解决这个问题
两上限定律:
1)数据本身决定了该类问题的上限,而模型只是逼近这个上限(算法) 2)模型结构本身决定了模型上限,而训练调参只是在逼近这个上限(模型)
4.1.2、Residual Networks
使用控制变量方法进行试验,所以这里的残差网络除了添加了残差模块其他都和普通网络相同
实验结果如下图:
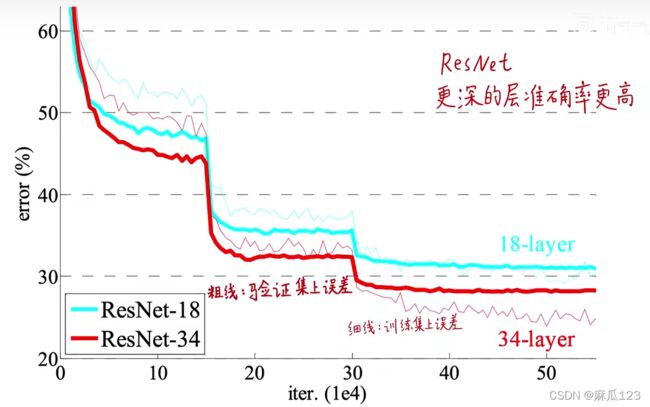
残差分支出现下采样时,对于shortcut connection:
采用A方案:对于对出来的通道padding补零填充,相比plainNet没有额外的参数
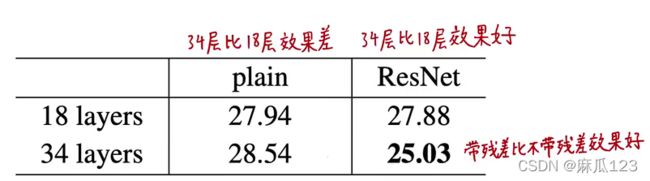
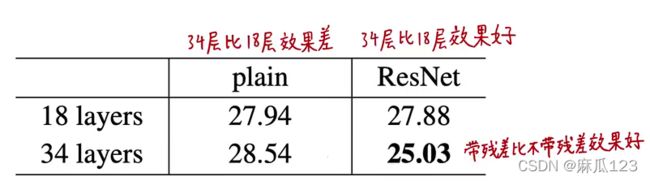
纵向比较:34层比18层效果好,验证集和训练集误差都小,泛化性能更好
退化问题得以解决,层数越深,性能越好
横向比较:带残差比不带残差效果好
残差学习可以用来搭建比较深的网络
残差网络收敛的更快(具体数学推导和优化原理可以参考《Identity Mapping in Deep Residual Networks》)
4.1.3、Identity VS Projection Shortcuts
shortcut connetction 用恒等映射identity mapping还是经过其他投射处理
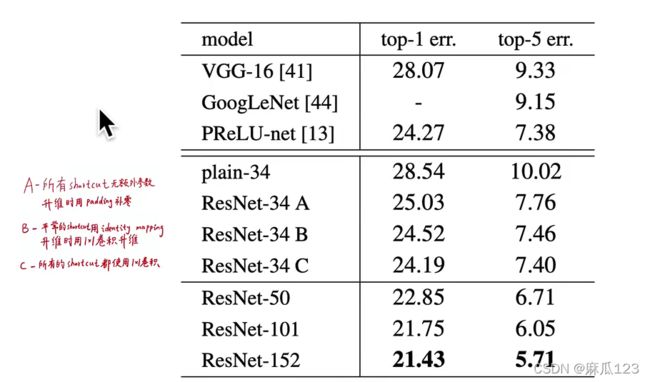
上图中间一行将残差三种下采样方式通不带残差的plainNet进行对比,结果显示都比plainNet好
残差三个的比较:
B比A好,A在升维时用padding补零,相当于丢失了shortcut分支的信息,没有进行进行残差学习 C比B好,C的13个非下采样残差模块的shortcut都有参数,模型表现能力强 A、B、C差不多,说明identity mapping的shortcut足以解决退化问题了
4.1.4、Deeper Bottleneck Architectures
更大深度的残差结构
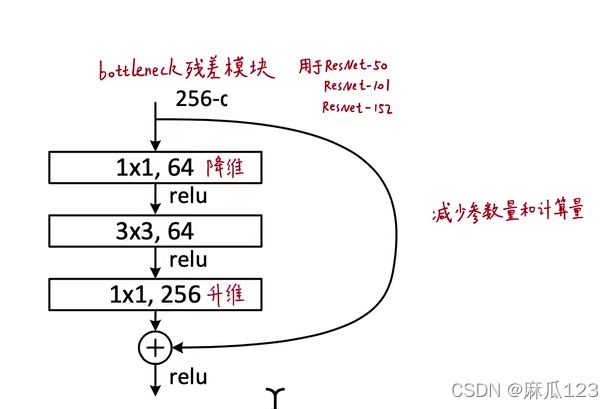
其中1x1卷积的作用比较突出,可用于降维、升维重建
其中无参数的恒等映射(the parameter-free identity shortcut)起到了很大作用,应为其两端连接的都是高维数据,如果引入projection,时间复杂度/计算量或者模型尺寸/参数量都会翻倍
50层的残差网络:将之前的残差模型中只有2层的模块( block)换成了3层(bottleneck block),降采样使用B方案,3.8 billion FLOPS
101层和152层网络:使用更多的3层(blocks),152-layer计算量11.3 billion FLOPs,依然小于VGGNet16/19的15.3/19.6 billion FLOPs
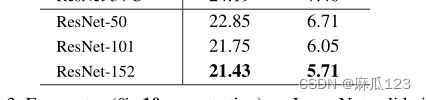
更深的网络,错误率更低,加深网络以后各项系数都有提升
4.1.5、Comparisons with State-of-the-art Methods.
对比其他先进方法
This single-model result outperforms all previous ensemble results (Table5).
ResNet-152单模型性能超过了过去所有多模型集成的结果
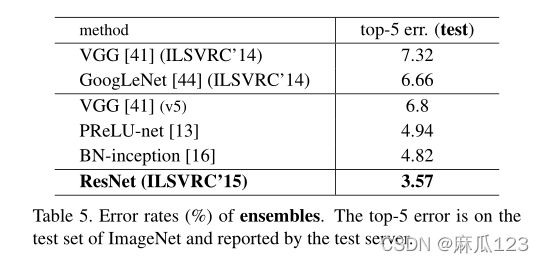
4.2、CIFAR-10 and Analysis
50k数据量,10个类比的数据集
关注点在于实现极深的网络而非单纯的刷分
同ImageNet的实验方式一样,数据增强方式也一样(每个像素点减去均值)
下图为网络结构中用到的卷积核大小和层数,一共是6n+2层
三个卷积分别是在{32,16,8}的像素大小上进行卷积,最后试驾了一个GPA层代替全连接层

超参数设置如下:
We use a weight decay of 0.0001 and momentum of 0.9,and adopt the weight initialization in [13] and BN [16] but with no dropout. These models are trained with a mini-batch size of 128 on two GPUs. We start with a learning rate of 0.1, divide it by 10 at 32k and 48k iterations, and terminate training at 64k iterations, which is determined on a 45k/5k train/val split. We follow the simple data augmen-tation in [24] for training: 4 pixels are padded on each side,and a 32×32 crop is randomly sampled from the padded image or its horizontal flip. For testing, we only evaluate the single view of the original 32×32 image.
我们使用了0.0001的权重衰减和0.9的动量,并采用了[13]和BN[16]中的权重初始化,但没有遗漏。这些模型在两个GPU上以128的小批量进行训练。我们从0.1的学习率开始,在32k和48k迭代时除以10,在64k迭代时终止训练,这取决于45k/5k训练/val分割。我们按照[24]中的简单数据扩充进行训练:每侧填充4个像素,并从填充图像或其水平翻转中随机采样32×32裁剪。对于测试,我们只评估原始32×32图像的单个视图。
结果如下图:
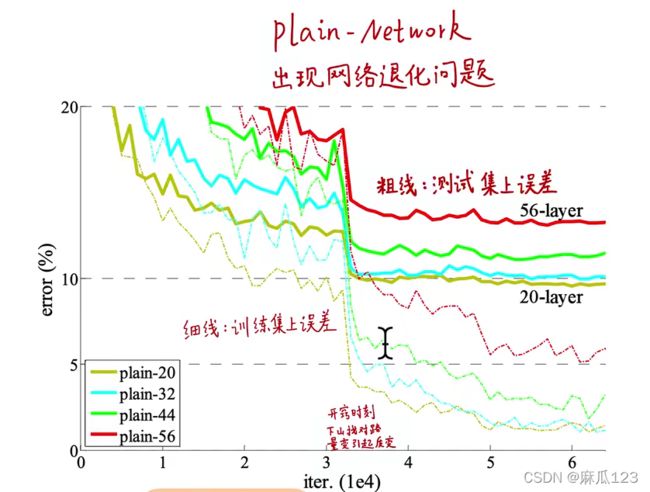
其中粗的红线在3步的时候有急速下降,这个可以称为“开窍时刻”,这之前是在寻找正确的路径,这里就是找到了正确收敛的方向(寻找下山的路,量变引起质变),而且可以发现图中其他线条也是在这一时刻急速下降,所以说明都是在这个时刻开窍,暂时无法解释。
不同深度的网络进行结果对比:
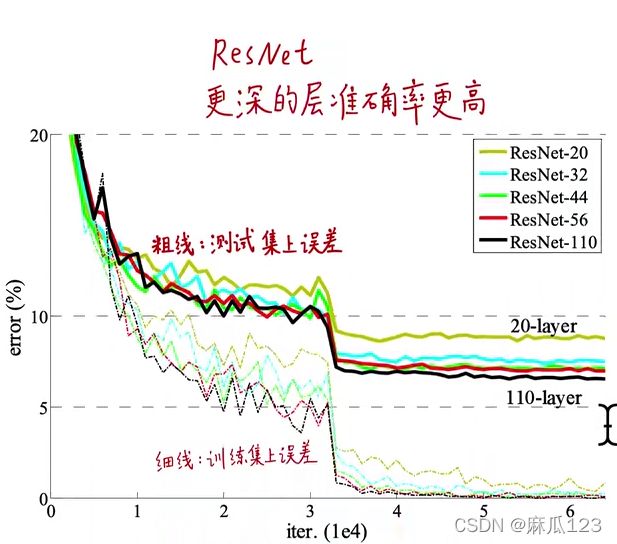
之后让n=18,就有了110层的ResNet,修改实验方法,分成两阶段学习:1、0.01小学习率“预热”,2、之后使用0.1大学习率进行学习
相比FitNet(用浅而宽的老师网络训练窄而深的学生网络 《花书》知识蒸馏)和 Highway具有更少的参数量,更好的结果。
4.2.1、Analysis of Layer Responses.
每层相应分布(每层残差层输出)
使用标准差来判断,在每层卷积BN之后激活之前的标准差(std),相当于输出信号的大小
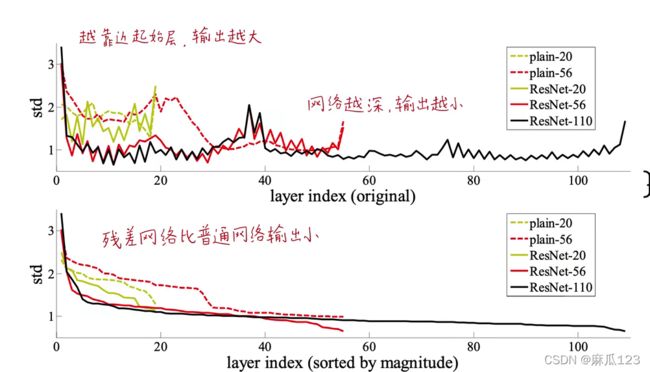
残差网络输出响应小,网络越深输出响应越小
4.2.2、Exploring Over 1000 layers(超深网络)
ResNet-1202无优化困难 能收敛且没有过拟合 测试集上性能不如ResNet-110(因为模型太深,参数过多,表示空间过于大,对小数据集而言没有必要)
对于其中的正则化问题:
仅通过深而窄的网络结构起到正则化效果,不加花里胡哨的正则化技巧以免偏离主线任务:优化困难问题
扩大数据集规模是防止过拟合的根本
超深网络的正则化研究留待后续进行
4.3. Object Detection on PASCAL and MS COCO
网络结构在目标检测中的效果
做法:替换目标检测骨干网络
Reference
其中有很多大佬的论文,使用到相关研究可以参考
附录
主要进行网络结构用在目标检测的实验和结果
Pytorch代码实现
from typing import Type, Any, Callable, Union, List, Optional
import torch
import torch.nn as nn
from torch import Tensor
from .._internally_replaced_utils import load_state_dict_from_url
from ..utils import _log_api_usage_once
#不同深度宽度网络
#18、34、50等不同的深度,每个网络效果不同
__all__ = [
"ResNet",
"resnet18",
"resnet34",
"resnet50",
"resnet101",
"resnet152",
"resnext50_32x4d",
"resnext101_32x8d",
"wide_resnet50_2",
"wide_resnet101_2",
]
model_urls = {
"resnet18": "https://download.pytorch.org/models/resnet18-f37072fd.pth",
"resnet34": "https://download.pytorch.org/models/resnet34-b627a593.pth",
"resnet50": "https://download.pytorch.org/models/resnet50-0676ba61.pth",
"resnet101": "https://download.pytorch.org/models/resnet101-63fe2227.pth",
"resnet152": "https://download.pytorch.org/models/resnet152-394f9c45.pth",
"resnext50_32x4d": "https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth",
"resnext101_32x8d": "https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth",
"wide_resnet50_2": "https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth",
"wide_resnet101_2": "https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth",
}
# 经过bn操作,会生成新的数据分布,偏置项的作用将被消除掉,所以不用加偏置
#后面的->的作用使用来解释该函数的作用和返回类型,可以忽略
# 将conv2d封装起来,其中第一个参数代表input_channels,第二个参数代表output_channels
# 对conv2d的封装其实作用不大,也可以不封装,直接输入输入维度、输出维度、卷积核大小、
# 步长、补零值、分组卷积数量、膨胀卷积数量、偏置的值
def conv3x3(in_planes: int, out_planes: int, stride: int = 1, groups: int = 1, dilation: int = 1) -> nn.Conv2d:
"""3x3 convolution with padding"""
return nn.Conv2d(
in_planes,
out_planes,
kernel_size=3,
stride=stride,
padding=dilation,
groups=groups,
bias=False,
dilation=dilation,
)
def conv1x1(in_planes: int, out_planes: int, stride: int = 1) -> nn.Conv2d:
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
# 定义基础版的参数模块,由两个3x3的卷积叠加而成
class BasicBlock(nn.Module):
expansion: int = 1
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
# 分组卷积,这里设置groups = 1,也就是不分组卷积
groups: int = 1,
base_width: int = 64,
# 膨胀卷积的膨胀系数设为1,也就是不膨胀卷积
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
) -> None:
#单继承,即只有一个父类(继承__init__()中的属性)
super().__init__()
if norm_layer is None:
# 对于norm_layer什么也不设置就用默认BatchNorm2d,如果有设置就用相应norm_layer
norm_layer = nn.BatchNorm2d
# 异常判断
if groups != 1 or base_width != 64:
raise ValueError("BasicBlock only supports groups=1 and base_width=64")
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# 最普通的conv、bn、relu流程
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
# 进行下采样,后面也会详细说明
self.downsample = downsample
self.stride = stride
# 模块执行的过程。后面的forward()函数都是类似原理。但是forward()函数什么时间被调用?
def forward(self, x: Tensor) -> Tensor:
#输入
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# 如果出现下采样,要对输入的数据做上采样(乘以expansion系数),这样才能保证输入输出的维度一致,
# 这样子两个tensor才能够相加
if self.downsample is not None:
identity = self.downsample(x)
#把初始输入和经过网络的数值相加,之后在进行relu激活
out += identity
out = self.relu(out)
return out
# 加强版的残差网络,与基础版本的不同之处在于从两个3x3卷积变成了
# 1x1、3x3、1x1卷积,前一个1x1卷积用来压缩维度,后一个1x1卷积用来恢复维度
# 卷积的时候都把bias设成False了,这是因为每次卷积之后都会做一个bn的操作,
# 经过bn操作,会生成新的数据分布,偏置项的作用将被消除掉,所以不用加偏置
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion: int = 4
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.0)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
#代码中未涉及到调去forward()函数,其实forward()自动触发的,内部机制自动触发执行该函数
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
#开始和前面两个结构的设置差不多,后面有不同
class ResNet(nn.Module):
def __init__(
self,
block: Type[Union[BasicBlock, Bottleneck]],
layers: List[int],
num_classes: int = 1000,
zero_init_residual: bool = False,
groups: int = 1,
width_per_group: int = 64,
replace_stride_with_dilation: Optional[List[bool]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
_log_api_usage_once(self)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
#异常检测
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError(
"replace_stride_with_dilation should be None "
f"or a 3-element tuple, got {replace_stride_with_dilation}"
)
self.groups = groups
self.base_width = width_per_group
#首先conv1进行一个7x7卷积
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
#进行3x3的max_pool
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 定义一个_make_layer()函数,生成conv2_x-conv5_x几个stage
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2])
# 最后进行avgpool和全连接层
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 进行参数初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0) # type: ignore[arg-type]
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0) # type: ignore[arg-type]
def _make_layer(
self,
block: Type[Union[BasicBlock, Bottleneck]],
planes: int,
blocks: int,
stride: int = 1,
dilate: bool = False,
) -> nn.Sequential:
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
# 当stride != 1 or self.inplanes != planes * block.expansion出现下采样
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
# 重复生成layer
layers = []
# 每个blocks的第一个residual结构保存在layers列表中。
layers.append(
block(
self.inplanes, planes, stride, downsample, self.groups, self.base_width, previous_dilation, norm_layer
)
)
self.inplanes = planes * block.expansion
# 然后从1开始重复生成,因为每一个convx_x中都包含好几个layer
for _ in range(1, blocks):
# 该部分是将每个blocks的剩下residual 结构保存在layers列表中,这样就完成了一个blocks的构造。
layers.append(
block(
self.inplanes,
planes,
groups=self.groups,
base_width=self.base_width,
dilation=self.dilation,
norm_layer=norm_layer,
)
)
# *layer进行拆包处理,将列表拆成一个个元素,因为Sequential()不接受列表
return nn.Sequential(*layers)
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def _resnet(
arch: str,
block: Type[Union[BasicBlock, Bottleneck]],# 模块类型
layers: List[int],# 网络配置
pretrained: bool,# 是否要加载预训练参数
progress: bool,
**kwargs: Any,
) -> ResNet:
model = ResNet(block, layers, **kwargs)
# 如果需要,通过model_urls来装载预训练参数
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch], progress=progress)
model.load_state_dict(state_dict)
return model
def resnet18(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
r"""ResNet-18 model from
`"Deep Residual Learning for Image Recognition" `_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
#将resnet50(网络名)、 Bottleneck(模块的类型)变成变量,这里的[2,2,2,2]是指conv2-5的模块组数
return _resnet("resnet18", BasicBlock, [2, 2, 2, 2], pretrained, progress, **kwargs)
def resnet34(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
r"""ResNet-34 model from
`"Deep Residual Learning for Image Recognition" `_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet("resnet34", BasicBlock, [3, 4, 6, 3], pretrained, progress, **kwargs)
def resnet50(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
r"""ResNet-50 model from
`"Deep Residual Learning for Image Recognition" `_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet("resnet50", Bottleneck, [3, 4, 6, 3], pretrained, progress, **kwargs)
def resnet101(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
r"""ResNet-101 model from
`"Deep Residual Learning for Image Recognition" `_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet("resnet101", Bottleneck, [3, 4, 23, 3], pretrained, progress, **kwargs)
def resnet152(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
r"""ResNet-152 model from
`"Deep Residual Learning for Image Recognition" `_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet("resnet152", Bottleneck, [3, 8, 36, 3], pretrained, progress, **kwargs)
def resnext50_32x4d(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
r"""ResNeXt-50 32x4d model from
`"Aggregated Residual Transformation for Deep Neural Networks" `_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs["groups"] = 32
kwargs["width_per_group"] = 4
return _resnet("resnext50_32x4d", Bottleneck, [3, 4, 6, 3], pretrained, progress, **kwargs)
def resnext101_32x8d(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
r"""ResNeXt-101 32x8d model from
`"Aggregated Residual Transformation for Deep Neural Networks" `_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs["groups"] = 32
kwargs["width_per_group"] = 8
return _resnet("resnext101_32x8d", Bottleneck, [3, 4, 23, 3], pretrained, progress, **kwargs)
def wide_resnet50_2(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
r"""Wide ResNet-50-2 model from
`"Wide Residual Networks" `_.
The model is the same as ResNet except for the bottleneck number of channels
which is twice larger in every block. The number of channels in outer 1x1
convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
channels, and in Wide ResNet-50-2 has 2048-1024-2048.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs["width_per_group"] = 64 * 2
return _resnet("wide_resnet50_2", Bottleneck, [3, 4, 6, 3], pretrained, progress, **kwargs)
def wide_resnet101_2(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
r"""Wide ResNet-101-2 model from
`"Wide Residual Networks" `_.
The model is the same as ResNet except for the bottleneck number of channels
which is twice larger in every block. The number of channels in outer 1x1
convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
channels, and in Wide ResNet-50-2 has 2048-1024-2048.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs["width_per_group"] = 64 * 2
return _resnet("wide_resnet101_2", Bottleneck, [3, 4, 23, 3], pretrained, progress, **kwargs)