基于python手写深度学习网络系列(9)为什么要加深网络?VGG、GoogleNet和ResNet,以及书籍推荐和分享。
基于python手写深度学习网络系列(9)
为什么要加深网络?VGG、GoogleNet和ResNet,以及书籍推荐和分享。
这里使用的卷积层全都是3×3的小型滤波器,特点是随着层的加深,通道数变大(卷积层的通道数从前面的层开始按顺序以16、16、32、32、64、64的方式增加)。 此外,如图8-1所示,插入了池化层,以逐渐减小中间数据的空间大小;并且, 后面的全连接层中使用了Dropout层。

使用He初始值作为权重的初始值,使用adam更新权重参数。
通过数据扩充Data Augmentation来提高识别精度,基于算法“人为地”扩充输入图像(训练图像)。具体地说,如图8-4所示,对于输入图像,通过施加旋转、垂直或水平方向上的移动等微小变化,增加图像的数量。这在数据集的图像数量有限时尤其有效。
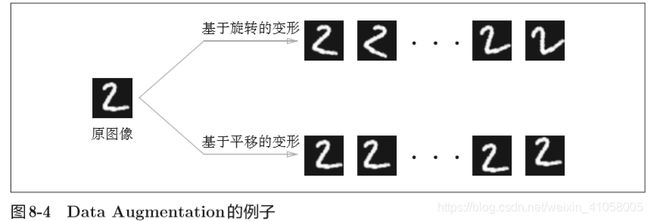
还有裁剪图像的 “crop处理”、将图像左右翻转的“flip 处 理”(只在不考虑图像对称性的情况下有效)
加深层的原因:这个研究目前还不够透彻
(1)首先是可以减少网络的参数量,加深了的网络可以用更少的参数达到同等水平的表现力。
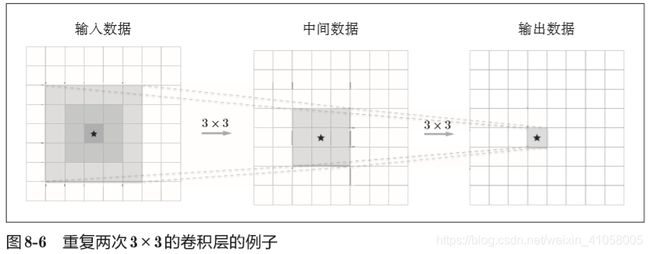
一次5×5的卷积运算的区域可以由两次3×3的卷积运算抵充。并且,相对于前者的参数数量25(5×5),后者一共是18(2×3×3),通过叠加卷积层,参数数量减少了。随着层数的加深,这个参数的差别还会更大。
叠加小型滤波器来加深网络的好处是可以减少参数的数量,扩大感受野(receptive field,给神经元施加变化的某个局部空间区域)。并且,通过叠加层,将ReLU等激活函数夹在卷积层的中间,进一步提高了网络的表现力。这是因为向网络添加了基于激活函数的“非线性” 表现力,通过非线性函数的叠加,可以表现更加复杂的东西。
(2)通过加深网络,就可以分层次地分解需要学习的问题。因此,各 层需要学习的问题就变成了更简单的问题。比如,最开始的层只要专注于学 习边缘就好,这样一来,只需用较少的学习数据就可以高效地进行学习。这 是为什么呢?因为和印有“狗”的照片相比,包含边缘的图像数量众多,并 且边缘的模式比“狗”的模式结构更简单。
(3)通过加深层,可以分层次地传递信息。
大规模图像识别大赛ILSVRC(ImageNet Large Scale Visual Recognition Challenge)

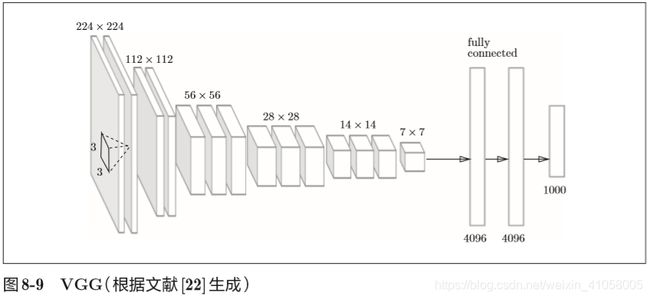
VGG是由卷积层和池化层构成的基础的CNN。不过,如图8-9所示, 它的特点在于将有权重的层(卷积层或者全连接层)叠加至16层(或者19层), 具备了深度(根据层的深度,有时也称为“VGG16”或“VGG19”)。
VGG中需要注意的地方是,基于3×3的小型滤波器的卷积层的运算是连续进行的。如图8-9所示,重复进行“卷积层重叠2次到4次,再通过池化层将大小减半”的处理,最后经由全连接层输出结果
[20] Y. Lecun, L. Bottou, Y. Bengio, and P. Haffner(1998): Gradient-based
learning applied to document recognition. Proceedings of the IEEE 86,
11 (November 1998), 2278 – 2324.
[22] Karen Simonyan and Andrew Zisserman(2014): Very Deep
Convolutional Networks for Large-Scale Image Recognition.
arXiv:1409.1556 [cs] (September 2014).
GoogleNet的特征是,网络不仅 在纵向上有深度,在横向上也有深度(广度)。这种结构叫inception,使用多个大小不同的滤波器和池化,最后合并他们的结果
[23] Christian Szegedy et al(2015): Going Deeper With Convolutions. In
The IEEE Conference on Computer Vision and Pattern Recognition
(CVPR).

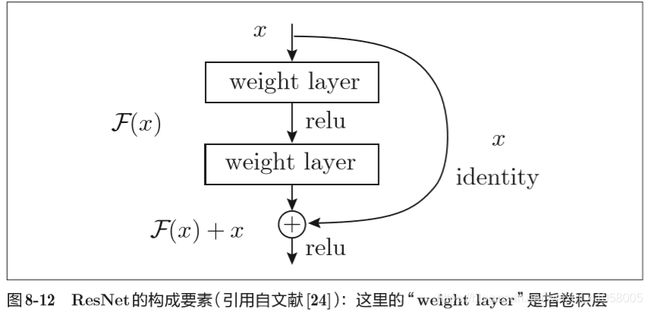
ResNet 微软的,导入了快捷结构,快捷结构横跨(跳过)了输入数据的卷积层,将输入x合计到输出。因为快捷结构只是原封不动地传递输入数据,所以反向传播时会将 来自上游的梯度原封不动地传向下游。这里的重点是不对来自上游 的梯度进行任何处理,将其原封不动地传向下游。因此,基于快捷 结构,不用担心梯度会变小(或变大),能够向前一层传递“有意义 的梯度”。通过这个快捷结构,之前因为加深层而导致的梯度变小的 梯度消失问题就有望得到缓解。
[24] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun(2015) :
Deep Residual Learning for Image Recognition. arXiv:1512.03385 [cs]
(December 2015).
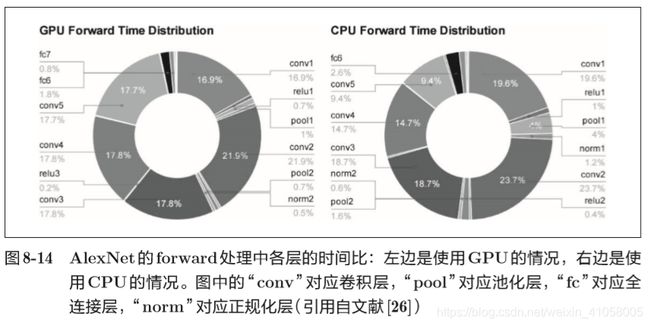
Google的TensorFlow、微软的CNTK(Computational Network Toolki)在开发过程中高度重视分布式学习。
关于深度学习的位数缩减,到目前为止已有若干研究。最近有人提出了用1位来表示权重和中间数据的Binarized Neural Networks方法[31]。为了实现深度学习的高速化,位数缩减是今后必须关注的一个课题,特别是在面向 嵌入式应用程序中使用深度学习时,位数缩减非常重要。
NumPy中提供了16位的半精度浮点数类型(不过,只有16位类型的存储,运算本身不用16位进行),即便使用NumPy的半精度浮点数,识别精度也不会下降。
图像检测
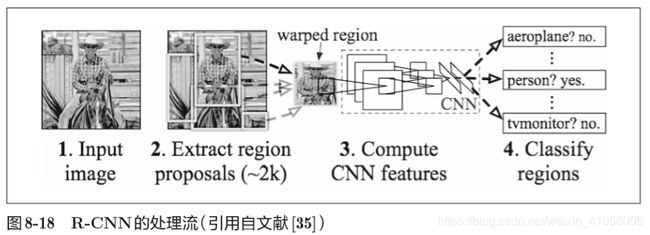
图像分割

有人提出了一个名为FCN(Fully Convolutional Network)[37]的方法。该方法通过一次forward处理,对所有像素进行分类(图 8-20)。
FCN的字面意思是“全部由卷积层构成的网络”。相对于一般的CNN包含全连接层,FCN将全连接层替换成发挥相同作用的卷积层。在物体识别中使用的网络的全连接层中,中间数据的空间容量被作为排成一列的节点进行处理,而只由卷积层构成的网络中,空间容量可以保持原样直到最后的输出。
[37] Jonathan Long, Evan Shelhamer, and Trevor Darrell(2015): Fully
Convolutional Networks for Semantic Segmentation. In The IEEE
Conference on Computer Vision and Pattern Recognition (CVPR).
一个基于深度学习生成图像标题的代表性方法是被称为NIC(Neural Image Caption)的模型。如图8-22所示,NIC由深层的CNN和处理自然语 言的RNN(Recurrent Neural Network)构成。 RNN是呈递归式连接的网络, 经常被用于自然语言、时间序列数据等连续性的数据上。
强化学习的基本框架是,代理(Agent)根据环境选择行动,然后通过这 个行动改变环境。根据环境的变化,代理获得某种报酬。强化学习的目的是 决定代理的行动方针,以获得更好的报酬(图8-26)。
在使用了深度学习的强化学习方法中,有一个叫作Deep Q-Network(通 称DQN)[44]的方法。该方法基于被称为Q学习的强化学习算法。
[41] Alec Radford, Luke Metz, and Soumith Chintala(2015): Unsupervised
Representation Learning with Deep Convolutional Generative
Adversarial Networks. arXiv:1511.06434 [cs] (November 2015).
[44] Volodymyr Mnih et al(2015): Human-level control through deep
reinforcement learning. Nature 518, 7540 (2015), 529 – 533.
写在最后
至此,《深度学习入门-基于Python的理论与实践》这本书的读书笔记就全部发布完了,向大家推荐一下这本书,整本书非常简单,工程驱动,基本涵盖了神经网络的相关知识点。整个神经网络都是可以自己手写出来的,但是也就没办法通过这本书了解到一些框架了。
如果想要继续深入学习,建议理论方面可以看看花书《DeepLearning》、西瓜书(周志华的《机器学习》)或者是李航的《统计学习方法》,实践方面可以看一下keras之父弗朗索瓦肖莱写的那本《Deep Learning with Python》,也就是封面是一位带帽子的人的那本书。如果需要相关资源的话,可以在评论区或者私信我,这些书电子版中英文的我都有,可以分享给大家。