对抗样本(论文解读七):On Physical Adversarial Patches for Object Detection
准备写一个论文学习专栏,先以对抗样本相关为主,后期可能会涉及到目标检测相关领域。
内容不是纯翻译,包括自己的一些注解和总结,论文的结构、组织及相关描述,以及一些英语句子和相关工作的摘抄(可以用于相关领域论文的写作及扩展)。
平时只是阅读论文,有很多知识意识不到,当你真正去着手写的时候,发现写完之后可能只有自己明白做了个啥。包括从组织、结构、描述上等等很多方面都具有很多问题。另一个是对于专业术语、修饰、语言等相关的使用,也有很多需要注意和借鉴的地方。
本专栏希望在学习总结论文核心方法、思想的同时,期望也可以学习和掌握到更多论文本身上的内容,不论是为自己还有大家,尽可能提供更多可以学习的东西。
当然,对于只是关心论文核心思想、方法的,可以只关注摘要、方法及加粗部分内容,或者留言共同学习。
On Physical Adversarial Patches for Object Detection
MarkLee1 J.ZicoKolter1
1Computer Science Department, Carnegie Mellon University, Pittsburgh, PA 15213, USA. Correspondence to: Mark Lee [email protected].
发表于:ICML 2019 Workshop on Security and Privacy of Machine Learning
针对于目标检测的物理对抗块
Abstract
不同于以前的物理攻击,必须将对抗块覆盖于目标上(overlap with the objects ),
我们设计的对抗块可以位于图像当中的任意位置,且可以攻击目标检测器(YOLOv3)误检测图像当中的所有目标,即使目标远离对抗块( we can place the patch anywhere in the image, causing all existing objects in the image to be missed entirely by the detector, even those far away from thepatchitself. )。
1 Introduction
However, in the object detection setting, these attacks have required a user to manipulate the object being attacked itself, i.e.(即,表示解释), by placing the patch over the object.
2.Related Work
2.1.Adversarial Patch for Classification
The goal is to produce localized, robust, and universal perturbations that are applied to an image by masking instead of adding pixels.
However, because classification systems only classify each image as a single class, to some extent this attack relies on the fact that it can simply place a high-confidence “deep net toaster” into an image (even if it does not look like a toaster to humans) and override other classes in the image.
2.2.Adversarial Patches for Image Segmentation
The work that bears the most similarity to our own is the DPatch method (Liu et al., 2018), the DPatch method was only tested on digital images, and contains a substantial flaw that makes it unsuitable for real experiments: the patches produced in the DPatch work are never clipped to the allowable image range (i.e., clipping colors to the [0,1] range) and thus do not correspond to actual perturbed images.
Furthermore, it is not trivial to use the DPatch loss to obtain valid adversarial images: we compare this approach to our own and show that we are able to generate substantially stronger attacks.
2.3.YOLO
YOLO is a “one-shot” object detector with state-of-the-art performance on certain metrics running up to 3×faster than other models
3. Methodology
3.1 Notation
J(hθ(x),y) 损失函数
3.2. Attack Formulation方式
Here we present our methodology for creating adversarial patches for object detection.
We consider the following mathematical formulation of finding an adversarial patch:
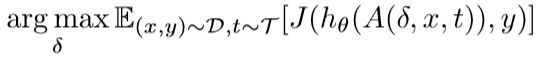
D为样本分布、T为块变换分布、A为块应用函数,δ为块
DPatch更新对抗块方式如下:
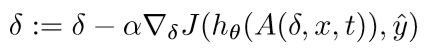
虽然这种更新在数字空间中对补丁的拟合效果相当好,但我们的实验表明,当应用box约束时(可打印颜色范围),这种方法找到的补丁的对抗性较弱,需要多次更新迭代,并始终在相对较高的map保持稳定。
我们采用了一种更简单的方法,简单地从表面值( face value )来考虑优化问题,并直接针对原始目标样本求损失最大化。这本质上就是标准的无目标PGD方法,我们的更新方法如下:
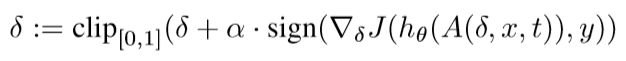
3.3.Experimental Setup
We evaluate on YOLOv3 pretrained for COCO 2014 (Lin et al., 2014) (416 × 416 pixels). The implementation of YOLOv3 achieves around 55.4% mAP-50(mAP at 0.5 IOU metric) using an object-confidence threshold of 0.001 for non-max suppression.
We define a“step”as 1,000 iterations. The following experiments were run for 300 steps with an initial learning rate of 0.1 and momentum of 0.9, which were chosen heuristically. Learning rate was decayed by 0.95 every 5 steps,很详细。
3.4.Unclipped Attack
For the unclipped attack, our method performs the update in Equation 2, except without clipping. The purpose is to benchmark against DPatch which uses Equation 1. 与DPatch攻击作对比。

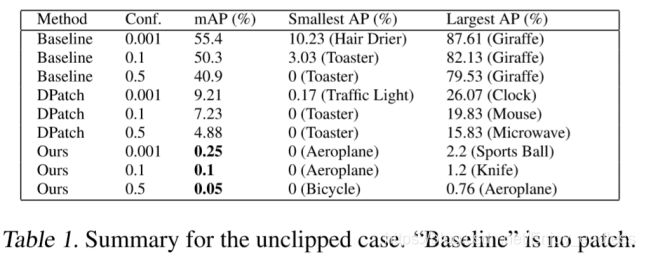
实验对比数据如上,
Figure 1 shows that our method achieves approximately 0 mAP after only 5 steps, whereas DPatch converges to roughly 3 mAP after 50 steps.
Table 1 shows the overall mAP as well as smallest and largest per-class APs for various confidence thresholds.

To verify that our patch attacks at the bounding box proposal level, we plot the pre-non-max suppression bounding box confidence scores for a random image, shown in Figure 2.
攻击是在box提议层级,
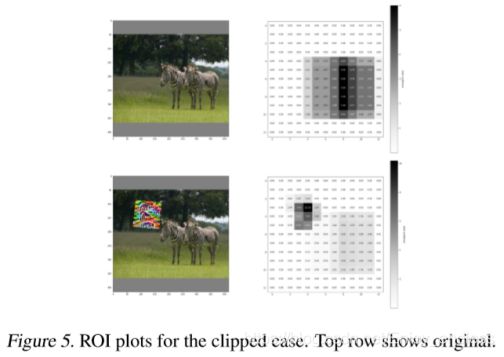
3.5.Clipped Attack
For the clipped attack, our method performs

Figure 3 shows the loss and mAP plots for a clipped patch with all transforms as described in subsection 3.3.
对于x,y随机旋转[-5,5]度,对于z旋转[-10,10]度,从8080到120120随机缩放、亮度调节[0.4,1.6].

3.6.Physical Attack
Figure 6 shows a printed version of our patch attacking YOLOv3 running real-time with a standard webcam. The patch was printed on regular printer paper and recorded under natural lighting.

3.7.Discussion
我们怀疑DPatch的挣扎是因为它把所有的ground truth boxes都集中在了patch周围——它最终驻留在一个单独的单元中,这意味着损失主要是由对该单元负责的提议造成的.只要这个补丁被识别出来,这个模型就不会因为预测所有其他对象而受到什么惩罚,也许会因为客观度得分而受到惩罚,但不会因为边界框或类标签而受到惩罚。即使模型的行为变化不大,损失也可以减少。而在实际应用中,该补丁通常能够在不抑制其他检测的情况下,实现高置信度的检测。在我们的方法中,每个网格单元都被一个ground truth box覆盖,这就造成了损失,当模型不能预测任何ground truth box时,损失增加最多。
4.Conclusion
该论文只是证明了在无目标攻击情况下其攻击效果的有效性。