前言
在上一章,我们主要介绍了如何使用延迟渲染,以及如何对G-Buffer进行一系列优化。而在这一章里,我们将从光源入手,讨论如何对大量的动态光源进行剔除,从而获得显著的性能提升。
在此之前假定读者已经读过上一章,并熟悉了如下内容:
- 计算着色器
- 结构化缓冲区
DirectX11 With Windows SDK完整目录
Github项目源码
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。
基于分块(Tile-Based)的光源剔除
为了剔除光源,一种最简单的方法就是利用摄像机的视锥体与点光源照射范围形成的球体做碰撞测试,和视锥体剔除的原理一致。当光源数目较大散布较为均匀时,可以有效减少光源数量。但这样做最明显的问题在于剔除不够精细,待绘制像素可能会受到视锥体内其余不能照射到当前像素的光源影响。
在此基础上,我们可以考虑将单个视锥体基于屏幕区域来划分为多个块,一个块有一个对应的子视锥体。在我们的demo中,每个分块的大小为16x16的分辨率。然后对每个子视锥体都进行一次全局光源的视锥体剔除,从而分别获得各自受影响的光源列表,最后在着色时根据当前像素所属的分块区域使用其对应的光源列表进行着色计算。而这项任务考虑到其重复计算的特性,可以交给GPU的计算着色器来完成。
带着这样的初步思路,我们直接从具体的代码来进行说明。
分块子视锥体深度范围的计算
考虑到原始的视锥体可以表示从**面到远*面的深度范围,但是这么大的深度范围内,待渲染几何体的深度可能在一个比较小的范围,为此可以进行一些小的优化。
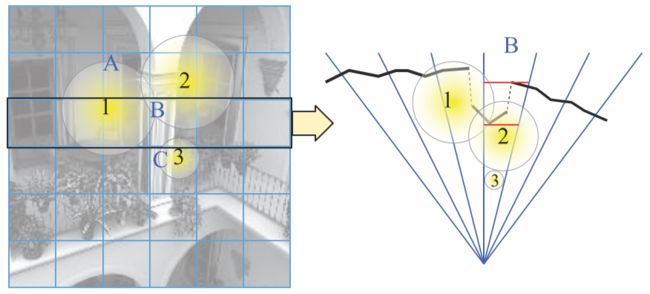
以下图为例,取黑色一行的分块,对应右边的一系列视锥体。对于区块B,右边的图的黑色线条反映的是在深度缓冲区对应位置的几何体深度信息。可以看到几何体的深度反映在一个比较小的范围,我们可以遍历该区块的所有深度值然后算出对应的zmin和zmax作为当前视锥体的**面和远*面,从而缩小视锥体的大小,并更有效地剔除光源。
// 确定分块(tile)的大小用于光照去除和相关的权衡取舍
#define COMPUTE_SHADER_TILE_GROUP_DIM 16
#define COMPUTE_SHADER_TILE_GROUP_SIZE (COMPUTE_SHADER_TILE_GROUP_DIM*COMPUTE_SHADER_TILE_GROUP_DIM)
groupshared uint s_MinZ;
groupshared uint s_MaxZ;
// 当前tile的光照列表
groupshared uint s_TileLightIndices[MAX_LIGHTS];
groupshared uint s_TileNumLights;
[numthreads(COMPUTE_SHADER_TILE_GROUP_DIM, COMPUTE_SHADER_TILE_GROUP_DIM, 1)]
void ComputeShaderTileDeferredCS(uint3 groupId : SV_GroupID,
uint3 dispatchThreadId : SV_DispatchThreadID,
uint3 groupThreadId : SV_GroupThreadID,
uint groupIndex : SV_GroupIndex
)
{
//
// 获取表面数据,计算当前分块的视锥体
//
uint2 globalCoords = dispatchThreadId.xy;
SurfaceData surfaceSamples[MSAA_SAMPLES];
ComputeSurfaceDataFromGBufferAllSamples(globalCoords, surfaceSamples);
// 寻找所有采样中的Z边界
float minZSample = g_CameraNearFar.y;
float maxZSample = g_CameraNearFar.x;
{
[unroll]
for (uint sample = 0; sample < MSAA_SAMPLES; ++sample)
{
// 避免对天空盒或其它非法像素着色
float viewSpaceZ = surfaceSamples[sample].posV.z;
bool validPixel =
viewSpaceZ >= g_CameraNearFar.x &&
viewSpaceZ < g_CameraNearFar.y;
[flatten]
if (validPixel)
{
minZSample = min(minZSample, viewSpaceZ);
maxZSample = max(maxZSample, viewSpaceZ);
}
}
}
// 初始化共享内存中的光照列表和Z边界
if (groupIndex == 0)
{
s_TileNumLights = 0;
s_NumPerSamplePixels = 0;
s_MinZ = 0x7F7FFFFF; // 最大浮点数
s_MaxZ = 0;
}
GroupMemoryBarrierWithGroupSync();
// 注意:这里可以进行并行归约(parallel reduction)的优化,但由于我们使用了MSAA并
// 存储了多重采样的像素在共享内存中,逐渐增加的共享内存压力实际上**减小**内核的总
// 体运行速度。因为即便是在最好的情况下,在目前具有典型分块(tile)大小的的架构上,
// 并行归约的速度优势也是不大的。
// 只有少量实际合法样本的像素在其中。
if (maxZSample >= minZSample)
{
InterlockedMin(s_MinZ, asuint(minZSample));
InterlockedMax(s_MaxZ, asuint(maxZSample));
}
GroupMemoryBarrierWithGroupSync();
float minTileZ = asfloat(s_MinZ);
float maxTileZ = asfloat(s_MaxZ);
float4 frustumPlanes[6];
ConstructFrustumPlanes(groupId, minTileZ, maxTileZ, frustumPlanes);
// ...
}
分块视锥体矩阵的推导及*面的构建
推导分块所属视锥体
首先,我们需要根据当前分块所属的视锥体求出对应的投影矩阵。回想之前的透视投影矩阵(或者看过GAMES101的推导),实际上是可以拆分成:
即一个视锥体挤压成立方体,再进行正交投影的变换,从而变换到齐次裁剪空间
为了取得立方体的其中一个切块,我们需要通过对这个挤压后的立方体进行缩放再*移。但同时因为变换后的点没有做透视除法:
我们需要把这个*移分量放在第三行来抵掉z来实现目标子视锥体的构造:
Gribb/Hartmann法提取视锥体*面
已知我们可以用向量(A, B, C, D)来表示*面Ax+By+Cz+D=0,同时向量(A, B, C)可以表示这个面的法线
已知视锥体对应的投影矩阵P,我们可以对其使用Gribb/Hartmann法提取视锥体对应的6个*面。在上述行矩阵的情况下,我们需要取它的列来计算:
需要注意的是,这些面的法线是指向视锥体的内部的。并且对于这些*面需要进行法线的归一化便于后续的计算。
此外,这种方法也支持观察矩阵和世界矩阵的结合:
- 如果待提取的矩阵为VP,提取出的视锥体*面位于世界空间
- 如果待提取的矩阵为WVP,提取出的视锥体*面位于物体空间
下面给出从透视投影矩阵构建出视锥体*面的方法:
void ConstructFrustumPlanes(uint3 groupId, float minTileZ, float maxTileZ, out float4 frustumPlanes[6])
{
// 注意:下面的计算每个分块都是统一的(例如:不需要每个线程都执行),但代价低廉。
// 我们可以只是先为每个分块预计算视锥*面,然后将结果放到一个常量缓冲区中...
// 只有当投影矩阵改变的时候才需要变化,因为我们是在观察空间执行,
// 然后我们就只需要计算*/远*面来贴紧我们实际的几何体。
// 从[0, 1]中找出缩放/偏移
float2 tileScale = float2(g_FramebufferDimensions.xy) * rcp(float(2 * COMPUTE_SHADER_TILE_GROUP_DIM));
float2 tileBias = tileScale - float2(groupId.xy);
// 计算当前分块视锥体的投影矩阵
float4 c1 = float4(g_Proj._11 * tileScale.x, 0.0f, tileBias.x, 0.0f);
float4 c2 = float4(0.0f, -g_Proj._22 * tileScale.y, tileBias.y, 0.0f);
float4 c4 = float4(0.0f, 0.0f, 1.0f, 0.0f);
// Gribb/Hartmann法提取视锥体*面
// 侧面
frustumPlanes[0] = c4 - c1; // 右裁剪*面
frustumPlanes[1] = c4 + c1; // 左裁剪*面
frustumPlanes[2] = c4 - c2; // 上裁剪*面
frustumPlanes[3] = c4 + c2; // 下裁剪*面
// */远*面
frustumPlanes[4] = float4(0.0f, 0.0f, 1.0f, -minTileZ);
frustumPlanes[5] = float4(0.0f, 0.0f, -1.0f, maxTileZ);
// 标准化视锥体*面(*/远*面已经标准化)
[unroll]
for (uint i = 0; i < 4; ++i)
{
frustumPlanes[i] *= rcp(length(frustumPlanes[i].xyz));
}
// ...
光源剔除
在算出视锥体*面后,我们可以对这些光源的球包围盒进行相交测试,来决定当前光源是否保留。由于一个分块内含16x16个线程,大量光源的碰撞检测可以分散给这些线程进行并行运算,然后将位于子视锥体内的光源加入到列表中:
//
// 对当前分块(tile)进行光照剔除
//
uint totalLights, dummy;
g_Light.GetDimensions(totalLights, dummy);
// 组内每个线程承担一部分光源的碰撞检测计算
for (uint lightIndex = groupIndex; lightIndex < totalLights; lightIndex += COMPUTE_SHADER_TILE_GROUP_SIZE)
{
PointLight light = g_Light[lightIndex];
// 点光源球体与tile视锥体*面的相交测试
// 当球心位于*面外侧且距离超过r,则没有相交
bool inFrustum = true;
[unroll]
for (uint i = 0; i < 6; ++i)
{
float d = dot(frustumPlanes[i], float4(light.posV, 1.0f));
inFrustum = inFrustum && (d >= -light.attenuationEnd);
}
[branch]
if (inFrustum)
{
// 将光照追加到列表中
uint listIndex;
InterlockedAdd(s_TileNumLights, 1, listIndex);
s_TileLightIndices[listIndex] = lightIndex;
}
}
GroupMemoryBarrierWithGroupSync();
在计算着色器完成光照阶段
现在我们可以直接利用前面计算到的信息来完成光照阶段的计算,这里只提取出实际参与计算的代码部分(源码中DEFER_PER_SAMPLE应总是为1,下面的代码略去该宏及无关的代码部分):
RWStructuredBuffer g_Framebuffer : register(u1);
// ...
// 当前tile中需要逐样本着色的像素列表
// 我们将两个16位x/y坐标编码进一个uint来节省共享内存空间
groupshared uint s_PerSamplePixels[COMPUTE_SHADER_TILE_GROUP_SIZE];
groupshared uint s_NumPerSamplePixels;
//--------------------------------------------------------------------------------------
// 用于写入我们的1D MSAA UAV
void WriteSample(uint2 coords, uint sampleIndex, float4 value)
{
g_Framebuffer[GetFramebufferSampleAddress(coords, sampleIndex)] = PackRGBA16(value);
}
// 将两个<=16位的坐标值打包进单个uint
uint PackCoords(uint2 coords)
{
return coords.y << 16 | coords.x;
}
// 将单个uint解包成两个<=16位的坐标值
uint2 UnpackCoords(uint coords)
{
return uint2(coords & 0xFFFF, coords >> 16);
}
[numthreads(COMPUTE_SHADER_TILE_GROUP_DIM, COMPUTE_SHADER_TILE_GROUP_DIM, 1)]
void ComputeShaderTileDeferredCS(uint3 groupId : SV_GroupID,
uint3 dispatchThreadId : SV_DispatchThreadID,
uint3 groupThreadId : SV_GroupThreadID,
uint groupIndex : SV_GroupIndex
)
{
// ...
//
// 光照阶段。只处理在屏幕区域的像素(单个分块可能超出屏幕边缘)
//
uint numLights = s_TileNumLights;
if (all(globalCoords < g_FramebufferDimensions.xy))
{
[branch]
if (numLights > 0)
{
bool perSampleShading = RequiresPerSampleShading(surfaceSamples);
float3 lit = float3(0.0f, 0.0f, 0.0f);
for (uint tileLightIndex = 0; tileLightIndex < numLights; ++tileLightIndex)
{
PointLight light = g_Light[s_TileLightIndices[tileLightIndex]];
AccumulateColor(surfaceSamples[0], light, lit);
}
// 计算样本0的结果
WriteSample(globalCoords, 0, float4(lit, 1.0f));
[branch]
if (perSampleShading)
{
// 创建需要进行逐样本着色的像素列表,延迟其余样本的着色
uint listIndex;
InterlockedAdd(s_NumPerSamplePixels, 1, listIndex);
s_PerSamplePixels[listIndex] = PackCoords(globalCoords);
}
else
{
// 否则进行逐像素着色,将样本0的结果也复制到其它样本上
[unroll]
for (uint sample = 1; sample < MSAA_SAMPLES; ++sample)
{
WriteSample(globalCoords, sample, float4(lit, 1.0f));
}
}
}
else
{
// 没有光照的影响,清空所有样本
[unroll]
for (uint sample = 0; sample < MSAA_SAMPLES; ++sample)
{
WriteSample(globalCoords, sample, float4(0.0f, 0.0f, 0.0f, 0.0f));
}
}
}
#if MSAA_SAMPLES > 1
GroupMemoryBarrierWithGroupSync();
// 现在处理那些需要逐样本着色的像素
// 注意:每个像素需要额外的MSAA_SAMPLES - 1次着色passes
const uint shadingPassesPerPixel = MSAA_SAMPLES - 1;
uint globalSamples = s_NumPerSamplePixels * shadingPassesPerPixel;
for (uint globalSample = groupIndex; globalSample < globalSamples; globalSample += COMPUTE_SHADER_TILE_GROUP_SIZE) {
uint listIndex = globalSample / shadingPassesPerPixel;
uint sampleIndex = globalSample % shadingPassesPerPixel + 1; // 样本0已经被处理过了
uint2 sampleCoords = UnpackCoords(s_PerSamplePixels[listIndex]);
SurfaceData surface = ComputeSurfaceDataFromGBufferSample(sampleCoords, sampleIndex);
float3 lit = float3(0.0f, 0.0f, 0.0f);
for (uint tileLightIndex = 0; tileLightIndex < numLights; ++tileLightIndex) {
PointLight light = g_Light[s_TileLightIndices[tileLightIndex]];
AccumulateColor(surface, light, lit);
}
WriteSample(sampleCoords, sampleIndex, float4(lit, 1.0f));
}
#endif
}
分块光源剔除的优缺点
优点:
- 对含有大量动态光源的场景,能够有效减少相当部分无关光源的计算
- 对延迟渲染而言,光源的剔除和计算可以同时在计算着色器中进行
缺点:
- tile的光源列表信息受动态光源、摄像机变换的影响,需要每帧都重新计算一次,带来一定的开销
- 基于屏幕空间tile的划分仍不够精细,没有考虑到深度值的划分
- 需要支持计算着色器
对于缺点2,空间的进一步精细划分有下述两种方法:
- 分块2.5D光源剔除
- Cluster Light Culling(分簇光源剔除)
由于篇幅有限,接下来我们只讨论第一种方式,并且留作练习。第二种方式读者可以自行寻找材料阅读。
分块2.5D光源剔除
我们直接从下图开始:

其中蓝色表示分片的子视锥体,黑色表示几何体的信息,黄色为点光源。在确定了当前子视锥体观察空间的zmin和zmax后,我们可以在这一深度范围内进一步均分成n个单元。右边表示的是我们对当前深度范围均分成了8份,如果当前光源位于某一份范围内,则把该光源对应的8位光源掩码的对应位置为1;同样如果当前深度范围内的所有几何体(以像素中的深度集合表示)位于某一份范围内,则把8位几何体掩码的对应位置置为1。如果光照掩码和几何体掩码的按位与运算为0,则表示对于该切片,当前光源不会产生任何光照计算从而应该剔除掉。
为了提高效率,n设置为32,然后对所有的灯光进行迭代,为每一个通过视锥体碰撞测试的灯光创建一个32位光照掩码。
2.5D光源剔除的具体做法为:
- 使用16x16大小的Tile先进行子视锥体与光源的碰撞测试,生成一个初步的光源列表
- 然后以64个线程为一组,每个线程对Tile中的4个像素与光源列表的光进行比较,进一步剔除这个列表。如果当前Tile中没有一个像素的位置在点光源内,那么该灯光就可以从列表中剔除。由此产生的灯光集可以算是相当准确的,因为只有那些保证至少影响一个像素的灯光被保存。
Forward+
考虑前面分块剔除光源的过程,实际上也可以应用到前向渲染当中。这种做法的前向渲染可以称之为Forward+ Rendering,具体流程如下:
- Pre-Z Pass,因为在光源剔除阶段我们需要利用深度信息,所以记录场景深度信息到深度缓冲区中
- 执行Tile-Based Light Culling
- 前向渲染,仅绘制和深度缓冲区深度值相等的像素,并利用所在tile的光源列表来计算颜色
由于光源剔除和光照被分拆了,我们需要保存光照剔除的结果给下一阶段使用。其中光源剔除的shader如下:
struct TileInfo
{
uint tileNumLights;
uint tileLightIndices[MAX_LIGHT_INDICES];
};
RWStructuredBuffer g_TilebufferRW : register(u0);
groupshared uint s_MinZ;
groupshared uint s_MaxZ;
// 当前tile的光照列表
groupshared uint s_TileLightIndices[MAX_LIGHTS >> 3];
groupshared uint s_TileNumLights;
// 当前tile中需要逐样本着色的像素列表
// 我们将两个16位x/y坐标编码进一个uint来节省共享内存空间
groupshared uint s_PerSamplePixels[COMPUTE_SHADER_TILE_GROUP_SIZE];
groupshared uint s_NumPerSamplePixels;
[numthreads(COMPUTE_SHADER_TILE_GROUP_DIM, COMPUTE_SHADER_TILE_GROUP_DIM, 1)]
void ComputeShaderTileForwardCS(uint3 groupId : SV_GroupID,
uint3 dispatchThreadId : SV_DispatchThreadID,
uint3 groupThreadId : SV_GroupThreadID,
uint groupIndex : SV_GroupIndex
)
{
//
// 获取深度数据,计算当前分块的视锥体
//
uint2 globalCoords = dispatchThreadId.xy;
// 寻找所有采样中的Z边界
float minZSample = g_CameraNearFar.y;
float maxZSample = g_CameraNearFar.x;
{
[unroll]
for (uint sample = 0; sample < MSAA_SAMPLES; ++sample)
{
// 这里取的是深度缓冲区的Z值
float zBuffer = g_GBufferTextures[3].Load(globalCoords, sample);
float viewSpaceZ = g_Proj._m32 / (zBuffer - g_Proj._m22);
// 避免对天空盒或其它非法像素着色
bool validPixel =
viewSpaceZ >= g_CameraNearFar.x &&
viewSpaceZ < g_CameraNearFar.y;
[flatten]
if (validPixel)
{
minZSample = min(minZSample, viewSpaceZ);
maxZSample = max(maxZSample, viewSpaceZ);
}
}
}
// 初始化共享内存中的光照列表和Z边界
if (groupIndex == 0)
{
s_TileNumLights = 0;
s_NumPerSamplePixels = 0;
s_MinZ = 0x7F7FFFFF; // 最大浮点数
s_MaxZ = 0;
}
GroupMemoryBarrierWithGroupSync();
// 注意:这里可以进行并行归约(parallel reduction)的优化,但由于我们使用了MSAA并
// 存储了多重采样的像素在共享内存中,逐渐增加的共享内存压力实际上**减小**内核的总
// 体运行速度。因为即便是在最好的情况下,在目前具有典型分块(tile)大小的的架构上,
// 并行归约的速度优势也是不大的。
// 只有少量实际合法样本的像素在其中。
if (maxZSample >= minZSample)
{
InterlockedMin(s_MinZ, asuint(minZSample));
InterlockedMax(s_MaxZ, asuint(maxZSample));
}
GroupMemoryBarrierWithGroupSync();
float minTileZ = asfloat(s_MinZ);
float maxTileZ = asfloat(s_MaxZ);
float4 frustumPlanes[6];
ConstructFrustumPlanes(groupId, minTileZ, maxTileZ, frustumPlanes);
//
// 对当前分块(tile)进行光照剔除
//
uint totalLights, dummy;
g_Light.GetDimensions(totalLights, dummy);
// 计算当前tile在光照索引缓冲区中的位置
uint2 dispatchWidth = (g_FramebufferDimensions.x + COMPUTE_SHADER_TILE_GROUP_DIM - 1) / COMPUTE_SHADER_TILE_GROUP_DIM;
uint tilebufferIndex = groupId.y * dispatchWidth + groupId.x;
// 组内每个线程承担一部分光源的碰撞检测计算
[loop]
for (uint lightIndex = groupIndex; lightIndex < totalLights; lightIndex += COMPUTE_SHADER_TILE_GROUP_SIZE)
{
PointLight light = g_Light[lightIndex];
// 点光源球体与tile视锥体的碰撞检测
bool inFrustum = true;
[unroll]
for (uint i = 0; i < 6; ++i)
{
float d = dot(frustumPlanes[i], float4(light.posV, 1.0f));
inFrustum = inFrustum && (d >= -light.attenuationEnd);
}
[branch]
if (inFrustum)
{
// 将光照追加到列表中
uint listIndex;
InterlockedAdd(s_TileNumLights, 1, listIndex);
g_TilebufferRW[tilebufferIndex].tileLightIndices[listIndex] = lightIndex;
}
}
GroupMemoryBarrierWithGroupSync();
if (groupIndex == 0)
{
g_TilebufferRW[tilebufferIndex].tileNumLights = s_TileNumLights;
}
}
最终的前向渲染着色器如下:
StructuredBuffer g_Tilebuffer : register(t9);
//--------------------------------------------------------------------------------------
// 计算点光源着色
float4 ForwardPlusPS(VertexPosHVNormalVTex input) : SV_Target
{
// 计算当前像素所属的tile在光照索引缓冲区中的位置
uint dispatchWidth = (g_FramebufferDimensions.x + COMPUTE_SHADER_TILE_GROUP_DIM - 1) / COMPUTE_SHADER_TILE_GROUP_DIM;
uint tilebufferIndex = (uint) input.posH.y / COMPUTE_SHADER_TILE_GROUP_DIM * dispatchWidth +
(uint) input.posH.x / COMPUTE_SHADER_TILE_GROUP_DIM;
float3 litColor = float3(0.0f, 0.0f, 0.0f);
uint numLights = g_Tilebuffer[tilebufferIndex].tileNumLights;
[branch]
if (g_VisualizeLightCount)
{
litColor = (float(numLights) * rcp(255.0f)).xxx;
}
else
{
SurfaceData surface = ComputeSurfaceDataFromGeometry(input);
for (uint lightIndex = 0; lightIndex < numLights; ++lightIndex)
{
PointLight light = g_Light[g_Tilebuffer[tilebufferIndex].tileLightIndices[lightIndex]];
AccumulateColor(surface, light, litColor);
}
}
return float4(litColor, 1.0f);
}
Forward+的优缺点
优点:
- 由于结合了分块光源剔除,使得前向渲染的效率能够得到有效提升
- 强制Pre-Z Pass可以过滤掉大量不需要执行的像素片元
- 前向渲染对材质的支持也比较简单
- 降低了带宽占用
- 支持透明物体绘制
- 支持硬件MSAA
缺点:
- 相比于延迟渲染的执行效率还是会慢一些
- 需要支持计算着色器
性能对比
下面使用RTX 3080 Ti 对6种不同的渲染方式及4种MSAA等级的组合进行了帧数测试,结果如下:
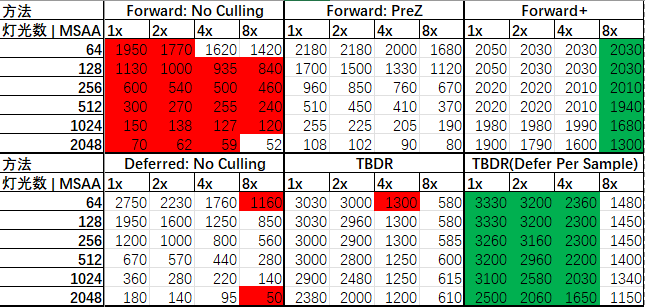
其中TBDR(Defer Per Sample)是我们目前使用的方法,与TBDR的区别在于:
- 将分支中非0样本着色的过程推迟,先将哪些需要逐样本着色的像素添加到像素列表中
- 完成0号样本的着色后,Tile中所有线程分担这些需要逐样本计算的像素着色
注意:要测试以前的TBDR,需要到
ShaderDefines.h将DEFER_PER_SAMPLE设为0,然后运行程序即可。
可以发现,TBDR(Defer Per Sample)的方法在4x MSAA前都有碾压性的优势,在8x MSAA不及Forward+。由于延迟渲染对MSAA的支持比较麻烦,随着采样等级的变大,帧数下降的越明显;而前向渲染由于直接支持硬件MSAA,提升MSAA的等级对性能下降的影响比较小。
此外,由于TBDR在Tile为16x16像素大小时,一次可以同时处理256个光源的碰撞检测,或者256个逐样本着色的像素着色,可能要在灯光数>256的时候才会有比较明显的性能影响。
演示
由于现在分辨率大了,GIF录起来很难压到10M内,这里就只放几张演示图跟操作说明
- MSAA:默认关闭,可选2x、4x、8x
- 光照剔除模式:默认开启延迟渲染+无光照剔除,可选前向渲染、带Pre-Z Pass的前向渲染
- Animate Lights:灯光的移动
- Face Normals:使用面法线
- Clear G-Buffer:默认不需要清除G-Buffer再来绘制,该选项开启便于观察G-Buffer中的图
- Visualize Light Count:可视化每个像素渲染的光照数,最大255。
- Visualize Shading Freq:在开启MSAA后,红色高亮的区域表示该像素使用的是逐样本着色
- Light Height Scale:将所有的灯光按一定比例抬高
- Lights:灯光数,2的指数幂
- Normal图:展示了从Normal_Specular G-Buffer还原出的世界坐标下的法线,经[-1, 1]到[0, 1]的映射
- Albedo图:展示了Albedo G-Buffer
- PosZGrad图:展示了观察空间下的PosZ的梯度
下图展示了每个分块的灯光数目(越亮表示此处产生影响的灯光数越多):
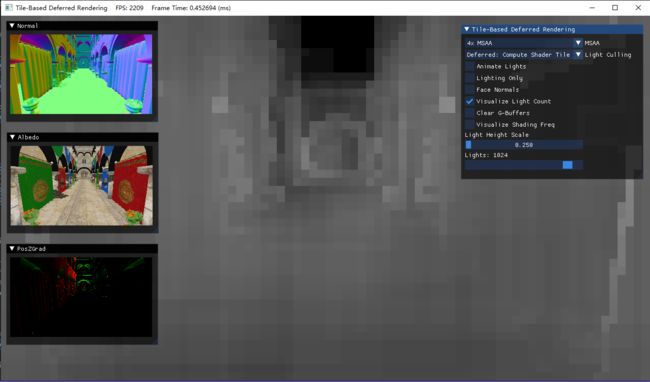
下图展示了需要进行逐样本着色的区域(红色边缘区域):
练习题
- 尝试实现分块2.5D光源剔除
补充&参考
Deferred Rendering for Current and Future Rendering Pipelines
Fast Extraction of Viewing Frustum Planes from the World-View-Projection Matrix
DirectX11 With Windows SDK完整目录
Github项目源码
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。