在浏览器地址栏输入URL,按下enter键后发生了什么?
摘要
文章梳理了浏览器【页面导航】 和 【页面渲染】的过程,理解该过程的实现原理,有助于性能优化和更快地定位问题。
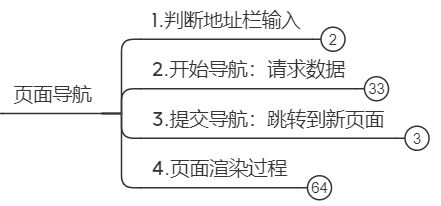
1. 页面导航
在地址栏输入URL后,页面导航过程如下:
2. 判断地址栏输入
通常我们在地址栏输入的信息可以分为两种情况处理:
- 一种是一个合法的URL,浏览器就会访问该URL。
- 其它的非URL输入,会被当做关键字,交给搜索引擎处理。

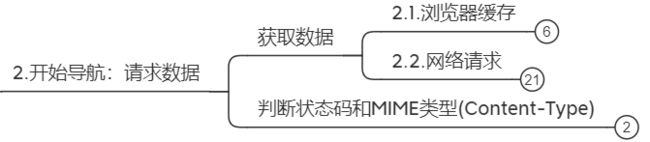
3. 开始导航
当浏览器确认地址栏输入的是一个URL时,就会开始请求数据。在发出HTTP请求数据之前,浏览器会先检查本地缓存数据。
3.1. 浏览器缓存
浏览器缓存有强缓存 和协商缓存 两种方式。

3.1.1. 强缓存
当响应报文中包含Expire报文头时,浏览器会缓存到本地。下次请求时,先检查本地缓存数据,如果Expire未失效,则返回缓存数据,不需要再请求服务器。
3.1.2. 协商缓存
当响应报文中包含的Cache-Control报文头信息符合缓存条件时,浏览器会缓存到本地。下次请求时,浏览器会向服务器请求确认缓存数据是否更新,服务器判断资源更新时间(if-Modified-Since)或资源最新摘要信息(if-None-Match),如果资源已更新,则返回最新数据;否则返回304,浏览器可以继续使用本地缓存数据。
3.2. 网络请求
如果没有命中本地缓存数据,浏览器将会发起HTTP请求数据。用户输入的URL域名需要经过DNS解析,得到IP后再向目标主机发起HTTP请求。
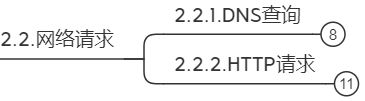
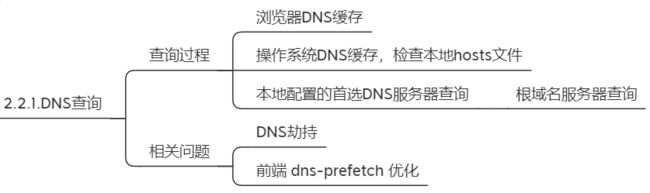
3.2.1. DNS查询
3.2.2. HTTP请求
一次完整的HTTP通信,涉及到TCP/IP协议的应用层、传输层、网络层 和链路层。
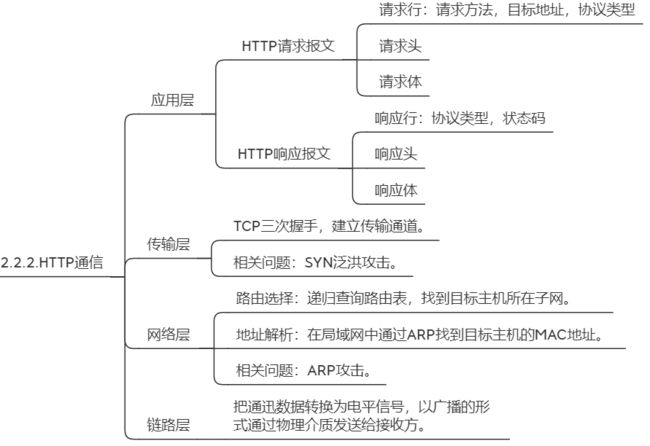
3.3. 处理不同MIME类型数据

4. 提交导航
获取到HTML数据后,浏览器会离开当前页面,跳转到新页面。
具体表现为:浏览器地址栏URL更新,会话历史记录更新,渲染进程开始解析HTML。

5. 页面渲染过程
浏览器解析HTML和CSS代码,构建DOM树并计算每个元素的样式信息 和布局信息,然后绘制到屏幕上。
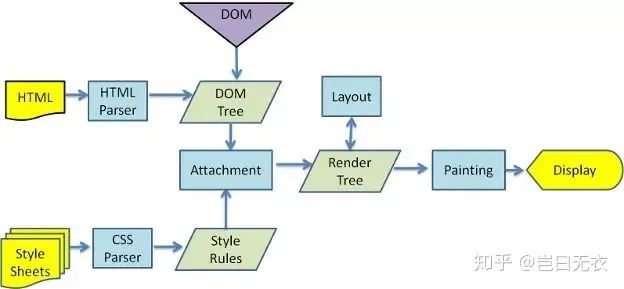
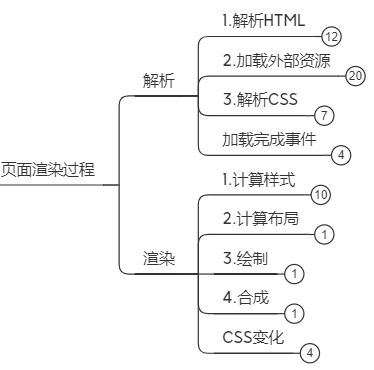
5.1. 解析HTML
构建DOM树:将HTML转换为浏览器可以理解的数据结构,应用程序通过DOM API来操作HTML页面内容。
包括:decoding、预加载资源、词法分析、语法分析、HTML解析结束并触发DOMContentLoaded事件。
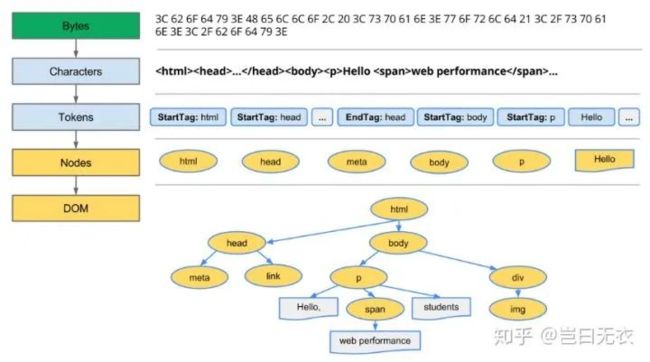

备注:
- document.write()可以把输入的HTML字符串解析到当前DOM树。
5.2. 加载外部资源
在解析HTML过程中,加载页面引用的外部资源(JS、CSS、img)。
5.2.1. 解析阻塞
在解析HTML过程中,会出现 JS阻塞 和 CSS阻塞 的情况。
JavaScript阻塞:因为执行JavaScript可能导致reflow 和 repaint 等问题,所以默认脚本的加载和执行都会阻塞HTML的解析;
CSS阻塞:由于JavaScript可能操作CSS属性,所以当JavaScript执行时,应该保证相关的CSS已经加载完毕,即CSS解析会阻塞JavaScript的执行。同时CSS解析也会阻塞页面渲染。

5.2.2. 优化方案
- 把CSS放在HTML标签头部,JavaScript放在尾部。
- 通过async和defer异步加载脚本。
- 资源预加载。
- CDN加速、缓存、文件压缩。
5.3. 解析CSS
将CSS规则转换为浏览器可以理解的数据结构,应用程序通过CSSOM API来操作CSS样式。
遍历所有的CSS规则(不包含内联样式),然后根据CSS选择器构建的树结构。
5.3.1. 引入方式
CSS的引入方式有:内联样式、内部样式 和外联样式。

5.3.2. 构建CSSOM树

5.4. 加载完成事件
DOMContentLoaded事件表示HTML解析完毕;
load事件表示HTML和所有外部资源解析完毕。

5.5. 计算样式
将DOM树 和CSSOM树 组合成Render树:遍历DOM树的每个可见节点,然后在CSSOM中找到匹配的所有样式规则,最后根据样式层叠 确定每个节点的computedStyle。
生成的Render树中不包含display:none节点,但包含visibility:hidden节点。

5.6. 计算布局
计算Render树 的每个元素在页面上的几何信息(位置和大小)。
5.7. 绘制
根据Render树中每个元素的内容、computedStyle和布局信息,将元素绘制到屏幕上。
5.8.合成
在绘制时,将页面元素分成多层分别进行绘制,然后将重叠部分进行合成。当发生repaint时,只需要repaint对应的层,必要时再进行合成。
5.9. CSS变化
当CSS信息发生变化时,可能导致两种情况:reflow 和repaint。
