MySQL之增删改查,常用函数
数据库
目录
数据库
1、增加,删除,修改
2、查询
1、SQL底层执行原理
2、查询分类介绍
避免笛卡尔集
①基础查询
②过滤
③排序
④分组查询
⑤等值连表查询
⑥左外连接
⑦子查询
⑧分页查询
3、常用函数
1、字符函数
2、数字函数
3、日期函数
前言:增加,修改,删除都是固定的SQL语句,重点在于查询!!!
1、增加,删除,修改
#增 语法:insert into 表名(列字段) values(?,?,?...)
#补充:
#什么时候需要声明表名后面的列字段?需要添加的数据字段<表的总字段 未添加的字段需要验证约束是否成立
#id如果是自增长,不用声明
#案列:添加一条学生数据到学生表,如果学生表有非空约束的班级cid字段,下面语句添加失败!!!
insert into tb_student(sname,sage,ssex) values('张三',17,'男')
#删 语法:delete from table where 条件
#案例:删除学生表中id为3的学生
delete from tb_table where id=3
#改 语法:update table set 字段=?,字段=? where 条件
#案列:将学生表中id为4的学生的姓名改为李四,年龄改为18
update tb_table set sname='李四',sage=18 where id=42、查询
1、SQL底层执行原理
首先是测试底层执行原理的两张表!tb_number,tb_word
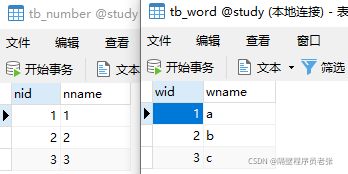
①执行select nname,wname from tb_word w,tb_number n查出来的数据
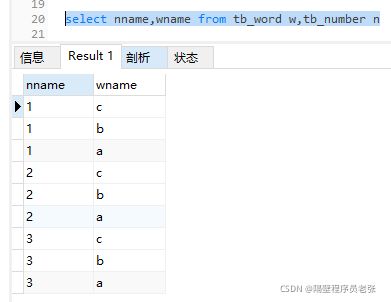
②执行select nname,wname from tb_number n,tb_word w查出来的数据
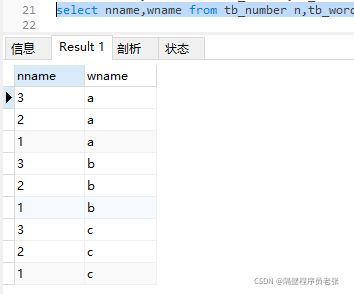
由①②可以推断出这个SQL语句执行时底层的原理
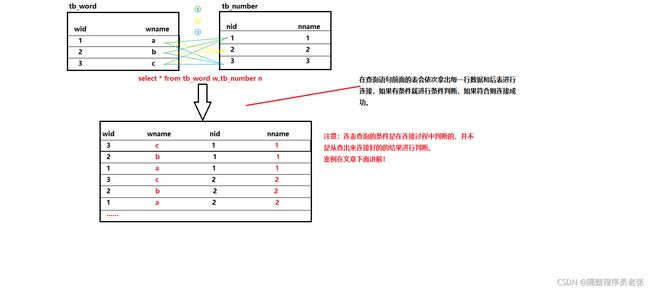
这是全连接的一个执行原理!!!左/右外连接原理和这不一样!
2、查询分类介绍
避免笛卡尔集
笛卡尔集会在下面条件下产生,笛卡尔集是在查询中需要避免的。
– 省略连接条件
– 连接条件无效
– 所有表中的所有行互相连接
• 为了避免笛卡尔集, 可以在 WHERE 加入有 效的连接条件。
按照上述SQL底层执行原理看,如果两张表分别有100条数据,不避免笛卡尔集会查询出
100*100=10000条数据,再进行数据获取,是非常影响速度的!!!
①基础查询
/*
语法:
select 查询列表 from 表名;
类似于:System.out.println(打印东西);
特点:
1、查询列表可以是:表中的字段、常量值、表达式、函数
2、查询的结果是一个虚拟的表格
*/
#3.查询表中的所有字段
#方式一:
SELECT
`employee_id`,
`first_name`,
`last_name`,
`phone_number`,
`last_name`,
`job_id`,
`phone_number`,
`job_id`,
`salary`,
`commission_pct`,
`manager_id`,
`department_id`,
`hiredate`
FROM
t_mysql_employees ;
#方式二:
SELECT * FROM t_mysql_employees;
#区别:
#方式一查询效率快
#4.查询常量值
SELECT 100;
SELECT 'john';
#5.查询表达式
SELECT 100%98;
#6.查询函数
SELECT VERSION();
#7.起别名
/*
①便于理解
②如果要查询的字段有重名的情况,使用别名可以区分开来
*/
#方式一:使用as
SELECT 100%98 AS 结果;
SELECT last_name AS 姓,first_name AS 名 FROM t_mysql_employees;
#方式二:使用空格
SELECT last_name 姓,first_name 名 FROM t_mysql_employees;
#8.去重
#案例:查询员工表中涉及到的所有的部门编号
SELECT DISTINCT department_id FROM t_mysql_employees;
#9.+号的作用
/*
java中的+号:
①运算符,两个操作数都为数值型
②连接符,只要有一个操作数为字符串
mysql中的+号:
仅仅只有一个功能:运算符
select 100+90; 两个操作数都为数值型,则做加法运算
select '123'+90;只要其中一方为字符型,试图将字符型数值转换成数值型
如果转换成功,则继续做加法运算
select 'john'+90;如果转换失败,则将字符型数值转换成0
select null+10; 只要其中一方为null,则结果肯定为null
*/②过滤
/*
语法:
select
查询列表
from
表名
where
筛选条件;
*/
/*
分类:
---------------------一、按条件表达式筛选-------------------------------------------
简单条件运算符:> < = != <> >= <=
*/
#案例1:查询工资>12000的员工信息
SELECT
*
FROM
t_mysql_employees
WHERE
salary>12000;
#案例2:查询部门编号不等于90号的员工名和部门编号
SELECT
last_name,
department_id
FROM
t_mysql_employees
WHERE
department_id != 90;
/*
---------------------二、按逻辑表达式筛选------------------------------------------
逻辑运算符:
作用:用于连接条件表达式
java: && || !
sql: and or not
&&和and:两个条件都为true,结果为true,反之为false
||或or: 只要有一个条件为true,结果为true,反之为false
!或not: 如果连接的条件本身为false,结果为true,反之为false
*/
#案例1:查询工资z在10000到20000之间的员工名、工资以及奖金
SELECT
last_name,
salary,
commission_pct
FROM
t_mysql_employees
WHERE
salary>=10000 AND salary<=20000;
#案例2:查询部门编号不是在90到110之间,或者工资高于15000的员工信息
SELECT
*
FROM
t_mysql_employees
WHERE
NOT(department_id>=90 AND department_id<=110) OR salary>15000;
/*
---------------------------三、模糊查询-----------------------------------------------
like
between and
in
is null|is not null
*/
/*
===============================1.like
特点:
①一般和通配符搭配使用
通配符:
% 任意多个字符,包含0个字符
_ 任意单个字符
*/
#案例1:查询员工名中包含字符a的员工信息
select
*
from
employees
where
last_name like '%a%';
#案例2、查询员名中a开头且长度为2的的员工信息
select
*
from
employees
where
last_name like 'a_'
/*
=============================2.between and
①使用between and 可以提高语句的简洁度
②包含临界值
③两个临界值不要调换顺序
*/
#案例1:查询员工编号在100到120之间的员工信息
SELECT
*
FROM
t_mysql_employees
WHERE
employee_id <= 120 AND employee_id>=100;
#简介写法:employye_id between 100 and 120
/*
==============================3.in
含义:判断某字段的值是否属于in列表中的某一项
特点:
①使用in提高语句简洁度
②in列表的值类型必须一致或兼容
③in列表中不支持通配符
*/
#案例:查询员工的工种编号是 IT_PROG、AD_VP、AD_PRES中的一个员工名和工种编号
SELECT
last_name,
job_id
FROM
t_mysql_employees
WHERE
job_id = 'IT_PROT' OR job_id = 'AD_VP' OR JOB_ID ='AD_PRES';
#简介写法:job_id IN( 'IT_PROT' ,'AD_VP','AD_PRES');
/*
===============================4、is null
=或<>不能用于判断null值
is null或is not null 可以判断null值
*/
#案例1:查询没有奖金的员工名和奖金率
SELECT
last_name,
commission_pct
FROM
t_mysql_employees
WHERE
commission_pct IS NULL;
/*
=============================5、安全等于 <=>
既可以判断空,也可以判断值
IS NULL:仅仅可以判断NULL值,可读性较高,建议使用
<=>:既可以判断NULL值,又可以判断普通的数值,可读性较低
*/
#案例1:查询没有奖金的员工名和奖金率
SELECT
last_name,
commission_pct
FROM
t_mysql_employees
WHERE
commission_pct <=> NULL;
#案例2:查询工资为12000的员工信息
SELECT
last_name,
salary
FROM
t_mysql_employees
WHERE
salary <=> 12000;③排序
#进阶3:排序查询
/*
语法:
select 查询列表
from 表名
【where 筛选条件】
order by 排序的字段或表达式;
特点:
1、asc代表的是升序,可以省略
desc代表的是降序
2、order by子句可以支持 单个字段、别名、表达式、函数、多个字段
3、order by子句在查询语句的最后面,除了limit子句
*/
#1、按单个字段排序
SELECT * FROM t_mysql_employees ORDER BY salary DESC;
#2、添加筛选条件再排序
#案例:查询部门编号>=90的员工信息,并按员工编号降序
SELECT *
FROM t_mysql_employees
WHERE department_id>=90
ORDER BY employee_id DESC;
#3、按表达式排序
#案例:查询员工信息 按年薪降序
SELECT *,salary*12*(1+IFNULL(commission_pct,0))
FROM t_mysql_employees
ORDER BY salary*12*(1+IFNULL(commission_pct,0)) DESC;
#4、按别名排序
#案例:查询员工信息 按年薪升序
SELECT *,salary*12*(1+IFNULL(commission_pct,0)) 年薪
FROM t_mysql_employees
ORDER BY 年薪 ASC;
#5、按函数排序
#案例:查询员工名,并且按名字的长度降序
SELECT LENGTH(last_name),last_name
FROM t_mysql_employees
ORDER BY LENGTH(last_name) DESC;
#6、按多个字段排序
#案例:查询员工信息,要求先按工资降序,再按employee_id升序
SELECT *
FROM t_mysql_employees
ORDER BY salary DESC,employee_id ASC;
④分组查询
/*
功能:用作统计使用,又称为聚合函数或统计函数或组函数
分类:
sum 求和、avg 平均值、max 最大值 、min 最小值 、count 计算个数
特点:
1、sum、avg一般用于处理数值型
max、min、count可以处理任何类型
2、以上分组函数都忽略null值
3、可以和distinct搭配实现去重的运算
4、count函数的单独介绍
一般使用count(*)用作统计行数
5、和分组函数一同查询的字段要求是group by后的字段
*/如果根据某字段分组的某一组中存在一条以上的数据,那么仅允许查询
select分组本身字段和聚合函数!
⑤等值连表查询
底层执行过程原理和全连接没什么区别,只是多了条件判断,判断成功才能连接成功产生这条数
据!!!否则会被过滤掉!
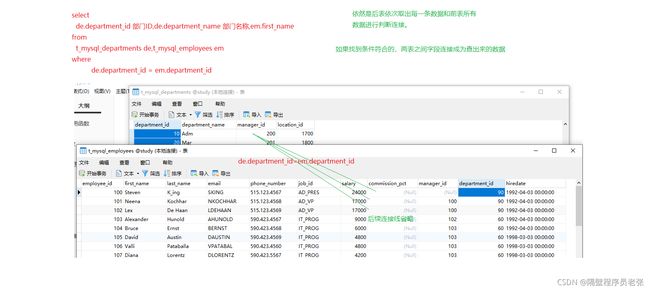
查询结果:
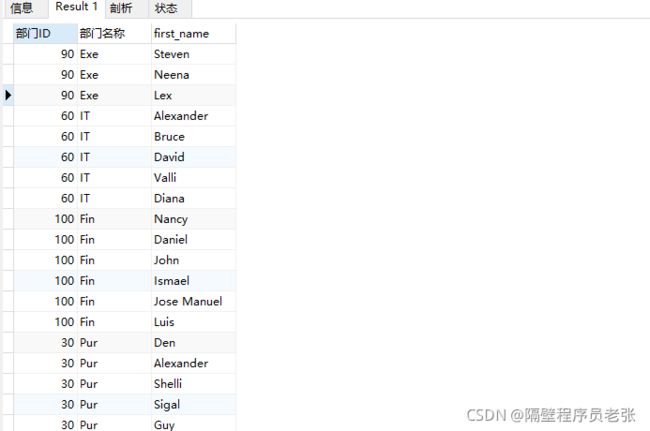
那么这里就有一个疑问了。
首先,假如每张表有100条数据,如果是没有条件的全连接,是不是会产生100*100=10000条数
据,有了where条件之后,最终的结果只有1000条了。那么疑问来了!有条件的查询是先查出
10000条数据之后再进行条件判断筛选?还是每连接一条数据判断一次呢?我认为where是最后进
行筛选!!!
⑥左外连接
和等值连接有不同的地方!
这里存在主从表的关系,左连接就是左表为主表,左/右外连接都一样,更具个人习惯选择使用。
这里就是主表依次有序的取出每一条数据和从表权标数据进行连接,符合连接条件的进行连接,不
符合主表字段数据保留,从表数据为空。where始终是最后的过滤筛选。group by也是对最终的一
个结果的分组。
案例:查出有员工的部门分别有多少人!
先看没有where筛选的左外连接的效果:
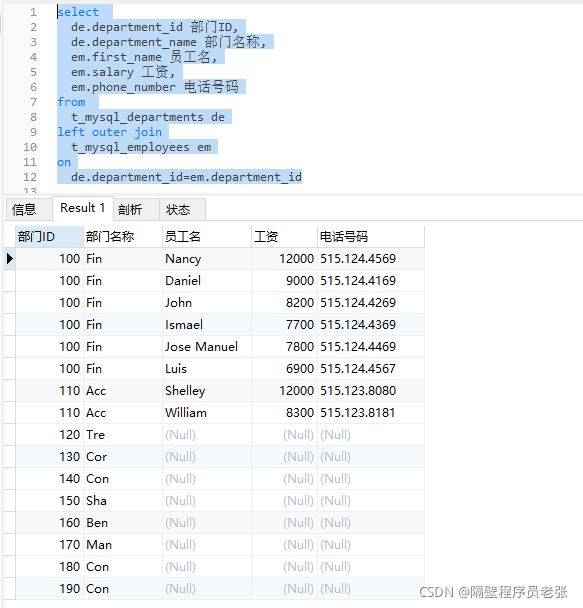
可以看到能查出有些部门是没有员工的的数据,也就是连接条件不成立进行连接的数据。在员工表
中并没有找到该部门id,连接后的数据,主表数据会保留,从表则为空,也就有了上图查询结果。
总的来说就是找到满足关键字on后条件的数据则进行连接,否则主保从空!!!
为了满足案例需求,需要过滤掉没有员工的部门!效果如下:
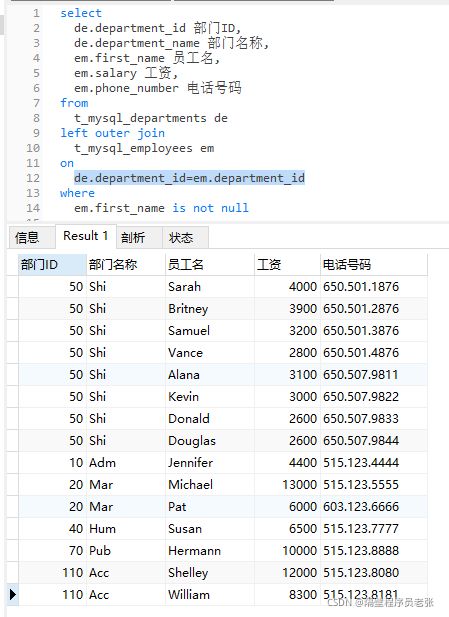
关键字on 仅仅决定两表数据是否可以连接,where 则是后续的筛选!
最后的SQL语句:
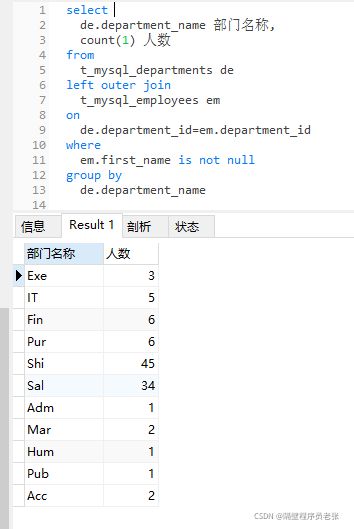
⑦子查询
将一次查询后的结果作为字表再进行查询,在上次的基础上进行查询筛选!
#1.标量子查询★
#案例1:谁的工资比 Abel 高?
#①查询Abel的工资
SELECT salary
FROM t_mysql_employees
WHERE last_name = 'Abel'
#②查询员工的信息,满足 salary>①结果
SELECT *
FROM t_mysql_employees
WHERE salary>(
SELECT salary
FROM t_mysql_employees
WHERE last_name = 'Abel'
);
#案例2:返回job_id与141号员工相同,salary比143号员工多的员工 姓名,job_id 和工资
#①查询141号员工的job_id
SELECT job_id
FROM t_mysql_employees
WHERE employee_id = 141
#②查询143号员工的salary
SELECT salary
FROM t_mysql_employees
WHERE employee_id = 143
#③查询员工的姓名,job_id 和工资,要求job_id=①并且salary>②
SELECT last_name,job_id,salary
FROM t_mysql_employees
WHERE job_id = (
SELECT job_id
FROM t_mysql_employees
WHERE employee_id = 141
) AND salary>(
SELECT salary
FROM t_mysql_employees
WHERE employee_id = 143
);⑧分页查询
/*
应用场景:当要显示的数据,一页显示不全,需要分页提交sql请求
语法:
select 查询列表
from 表
【join type join 表2
on 连接条件
where 筛选条件
group by 分组字段
having 分组后的筛选
order by 排序的字段】
limit 【offset,】size;
offset要显示条目的起始索引(起始索引从0开始)
size 要显示的条目个数
特点:
①limit语句放在查询语句的最后
②公式
要显示的页数 page,每页的条目数size
select 查询列表
from 表
limit (page-1)*size,size;
*/
#案例3:有奖金的员工信息,并且工资较高的前10名显示出来
SELECT
*
FROM
t_mysql_employees
WHERE
commission_pct IS NOT NULL
ORDER BY
salary DESC
LIMIT 10 ;3、常用函数
1、字符函数
| 作用 | 函数 | 结果 |
|---|---|---|
| 转小写 | LOWER('SQL Course') | sql course |
| 转大写 | UPPER('SQL Course') | SQL COURSE |
| 拼接 | CONCAT('Hello', 'World') | HelloWorld |
| 截取 | SUBSTR('HelloWorld',1,5) | Hello |
| 长度 | LENGTH('HelloWorld') | 10 |
| 字符出现索引值 | INSTR('HelloWorld', 'W') | 6 |
| 字符截取后半段 | TRIM('H' FROM 'HelloWorld') | elloWorld |
| 字符替换 | REPLACE('abcd','b','m') | amcd |
2、数字函数
| 作用 | 函数 | 结果 |
|---|---|---|
| 四舍五入 | ROUND(45.926, 2) | 45.93 |
| 截断 | TRUNC(45.926, 2) | 45.92 |
| 求余 | MOD(1600, 300) | 100 |
3、日期函数
| 作用 | 函数 | 结果 |
|---|---|---|
| 获取当前日期 | now() | 当前时间 |
| 将日期格式的字符转换成指定格式的日期 | STR_TO_DATE('9-13-1999','%m-%d-%Y') | 1999-09-13 |
| 将日期转换成字符 | DATE_FORMAT(‘2018/6/6’,‘%Y年%m月%d日’) | 2018年06月06日 |