【C++进阶】第二十二篇——unordered_map和unordered_set(容器接口介绍和使用+底层代码实现)
⭐️上一篇博客和大家介绍了关于哈希表和哈希桶的内容,今天就要用开散列的哈希表来实现今天要介绍的两个容器unordered_map和unordered_set。
⭐️博客代码已上传至gitee:https://gitee.com/byte-binxin/cpp-class-code
目录
- unordered_map
-
- 介绍
- 使用
-
- 构造函数
- 容量和大小
- 迭代器
- 元素的访问和查找
- 元素的插入和删除
- unordered_set
-
- 介绍
- 使用
-
- 构造函数
- 容量和大小
- 迭代器
- 元素的访问和查找
- 元素的插入和删除
- 测试set和unordered_set两个容器增删查改的性能
- unordered_map和unordered_set的实现
-
- 整体概述
- 改造哈希表
- 封装unordered_map和unordered_set
- 总结
unordered_map
介绍

总结出以下几点:
- unordered_map是存储
- 在unordered_map中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此键关联。键和映射值的类型可能不同。
- 在内部,unordered_map没有对
- unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭代方面效率较低。
- unordered_map实现了直接访问操作符(operator[]),它允许使用key作为参数直接访问value。
- 它的迭代器是一个单向迭代器。
使用
构造函数
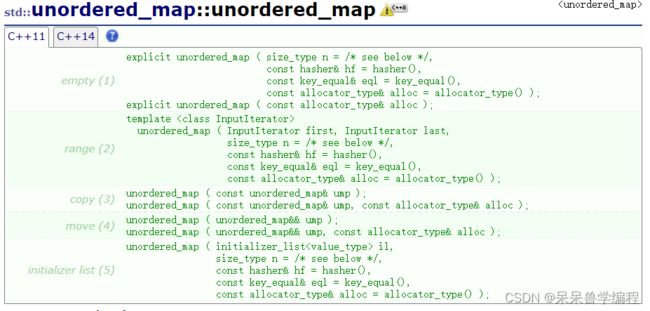
- 构造函数: 可以不初始化地构造,也可以用一个容器的迭代器去构造
- 拷贝构造函数: unordered_map ( const unordered_map& ump );
容量和大小

- empty: 判断容器是否为空
- size: 返回容器中的元素个数
迭代器
这里其实和之前的容器都是类似的,这个容器只有正向迭代器(包括const迭代器)

元素的访问和查找

- operator[]: 可以通过key找到value
- at: 这个用的没有上面的多,但本质是一样的
- find: iterator find ( const key_type& k );查找的时间复杂度可以达到O(1)
元素的插入和删除

- insert: pair
- erase: iterator erase ( const_iterator position ); 删除容器中的键值对
- clear: 清空容器中的元素
- swap: 交换两个容器中的元素
实例演示:
void test_unordered_map()
{
unordered_map<int, int> um;
map<int, int> m;
int arr[] = { 4,2,3,1,6,8,9,3 };
for (auto e : arr)
{
um.insert(make_pair(e, e));
m.insert(make_pair(e, e));
}
unordered_map<int, int>::iterator umit = um.begin();
map<int, int>::iterator mit = m.begin();
cout << "unordered_map:" << endl;
while (umit != um.end())
{
cout << umit->first << ":" << umit->second << endl;
++umit;
}
cout << "map:" << endl;
while (mit != m.end())
{
cout << mit->first << ":" << mit->second << endl;
++mit;
}
}
代码运行结果如下:
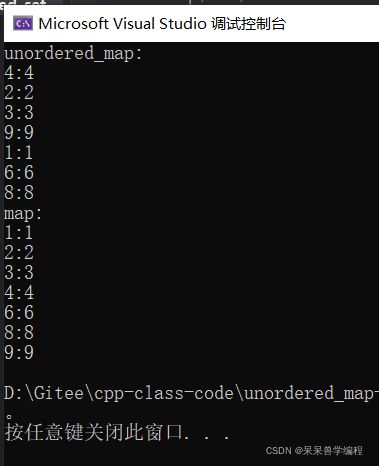
可以看出,unordered_map中的数据是无序的,map中的数据是有序的,但是前者增删查改的效率都可以达到O(1),前者底层是用哈希桶实现的,后者是用红黑树实现的,后面还会对它们两个的性能进行测试比较。
unordered_set
介绍
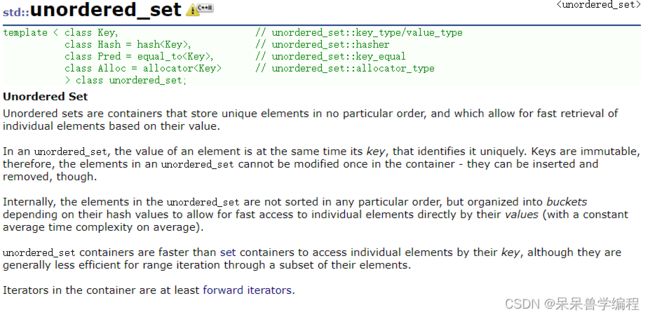
总结以下几点:
- unordered_set是以无特定顺序存储唯一元素的容器,并且允许根据它们的值快速检索单个元素,是一种K模型。
- 在unordered_set中,元素的值同时是它的key,它唯一地标识它。键值是不可变的,因unordered_set中的元素不能在容器中修改一次 ,但是可以插入和删除它们。
- 在内部,unordered_set中的元素不是按任何特定顺序排序的,而是根据它们的哈希值组织成桶,以允许直接通过它们的值快速访问单个元素,时间复杂度可以达到O(1)。
- unordered_set容器比set容器更快地通过它们的key访问单个元素,尽管它们通常对于通过其元素的子集进行范围迭代的效率较低。
- 容器中的迭代器至少是单向迭代器。
使用
构造函数
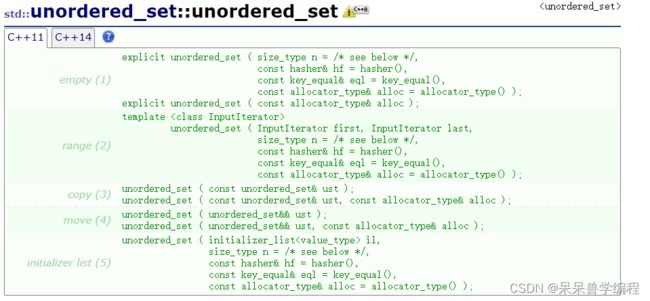
- 构造函数: 可以直接构造,也可以用一个容器的迭代器区间构造,具体看上图
- 拷贝构造: unordered_set ( const unordered_set& ust );
容量和大小

- empty: 判断容器是否为空
- size: 返回容器中的元素个数
迭代器
这里的迭代器也是一个单向的迭代器,和unordered_map是一样的

元素的访问和查找

- operator[]: 可以通过key找到value
- at: 这个用的没有上面的多,但本质是一样的
- find: iterator find ( const key_type& k );查找的时间复杂度可以达到O(1)
元素的插入和删除

- insert: pair
- erase: iterator erase ( const_iterator position ); 删除容器中的key
- clear: 清空容器中的元素
- swap: 交换两个容器中的元素
实例演示:
void test_unordered_set()
{
unordered_set<int> us;
set<int> s;
int arr[] = { 4,2,3,1,6,8,9,3 };
for (auto e : arr)
{
us.insert(e);
s.insert(e);
}
unordered_set<int>::iterator usit = us.begin();
set<int>::iterator sit = s.begin();
cout << "unordered_set:" << endl;
while (usit != us.end())
{
cout << *usit << " ";
++usit;
}
cout << endl;
cout << "set:" << endl;
while (sit != s.end())
{
cout << *sit << " ";
++sit;
}
cout << endl;
}
代码运行结果如下:
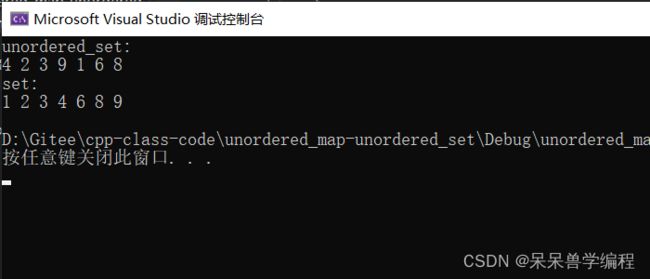
测试set和unordered_set两个容器增删查改的性能
测试代码如下: 我们选择每个容器中放10w个数据,然后进行对应的操作
void test_op()
{
srand((size_t)time(nullptr));
set<int> s;
unordered_set<int> us;
size_t n = 10000000;
vector<int> v;
v.reserve(n);
for (size_t i = 0; i < n; ++i)
{
v.push_back(rand());
}
int begin1 = clock();
for (auto e : v)
{
s.insert(e);
}
int end1 = clock();
cout << "set 插入" << n << "个数据用时:" << end1 - begin1 << "ms" << endl;
int begin2 = clock();
for (auto e : v)
{
us.insert(e);
}
int end2 = clock();
cout << "unordered_set 插入" << n << "个数据用时:" << end2 - begin2 << "ms" << endl;
int begin3 = clock();
for (auto e : v)
{
s.find(e);
}
int end3 = clock();
cout << "set 查找" << n << "个数据用时:" << end3 - begin3 << "ms" << endl;
int begin4 = clock();
for (auto e : v)
{
us.find(e);
}
int end4 = clock();
cout << "unordered_set 查找" << n << "个数据用时:" << end4 - begin4 << "ms" << endl;
int begin5 = clock();
for (auto e : v)
{
s.erase(e);
}
int end5 = clock();
cout << "set 删除" << n << "个数据用时:" << end5 - begin5 << "ms" << endl;
int begin6 = clock();
for (auto e : v)
{
us.erase(e);
}
int end6 = clock();
cout << "unordered_set 删除" << n << "个数据用时:" << end6 - begin6 << "ms" << endl;
}
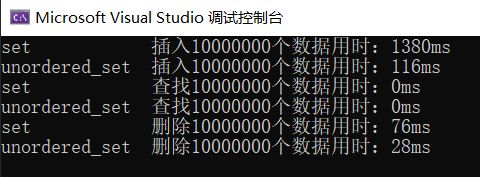
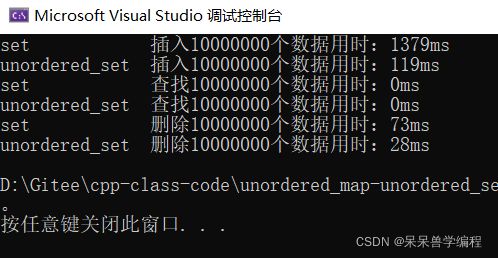
代码运行三次的结果如下:
第一次
第二次
第三次
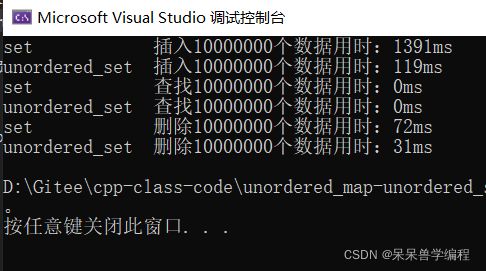
总结: unordered_set插入和删除的效率都比set要高,查找看的不是很明显,但其实前者的增删查改的效率是O(1),后者是O(logN)
unordered_map和unordered_set的实现
整体概述
这里我们用上一篇的博客中的哈希桶来封装出unordered_map和unordered_set两个容器
改造哈希表
这是上一篇有关哈希表的博客——哈希表
整体框架
template<class K, class T, class KOFV, class Hash>
class HashBucket
{
private:
vector<Node*> _tables;
int _num = 0;// 记录表中的数据个数
};
为了让哈希表能够跑起来,我们这里实现一个迭代器的操作
迭代器的框架: 这里有两个成员,一个是节点指针,还有一个是哈希表的指针,只要就是为了方便实现迭代器++遍历哈希表的操作。模板参数列表的前四个主要是为了实现普通迭代器和const迭代器,第五个参数就是为了获得T中的key值,是一个仿函数(前几篇博客都有提到过),最后一个模板参数是哈希函数,为了构造出哈希表指针而存在
template<class K, class T, class Ref, class Ptr, class KOFV, class Hash>
struct __HashBucket_Iterator
{
typedef __HashBucket_Iterator<K, T, Ref, Ptr, KOFV, Hash> Self;
typedef HashNode<T> Node;
typedef HashBucket<K, T, KOFV, Hash> HashBucket;
Node* _node;
HashBucket* _phb;
};
迭代器基本操作的实现:
template<class K, class T, class Ref, class Ptr, class KOFV, class Hash>
struct __HashBucket_Iterator
{
typedef __HashBucket_Iterator<K, T, Ref, Ptr, KOFV, Hash> Self;
typedef HashNode<T> Node;
typedef HashBucket<K, T, KOFV, Hash> HashBucket;
Node* _node;
HashBucket* _phb;
//Node* _node;
//int _index;// 记录此时迭代器在表中那个位置
//vector& _tables;
__HashBucket_Iterator(Node* node, HashBucket* phb)
:_node(node)
,_phb(phb)
{}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
Self& operator++()
{
if (_node->_next)
{
_node = _node->_next;
return *this;
}
else
{
KOFV kofv;
int index = _phb->HashFunc(kofv(_node->_data)) % _phb->_tables.size();
for (size_t i = index + 1; i < _phb->_tables.size(); ++i)
{
if (_phb->_tables[i])
{
_node = _phb->_tables[i];
return *this;
}
}
_node = nullptr;
return *this;
}
}
bool operator==(const Self& self) const
{
return _node == self._node
&& _phb == self._phb;
}
bool operator!=(const Self& self) const
{
return !this->operator==(self);
}
};
哈希表内部改造:(改造了的部分,完整的代码上传至了gitee)
template<class K, class T, class KOFV, class Hash>
class HashBucket
{
typedef HashNode<T> Node;
friend struct __HashBucket_Iterator<K, T, T&, T*, KOFV, Hash>;// 为了让迭代器中能够使用HashFunc这个函数
public:
typedef __HashBucket_Iterator<K, T, T&, T*, KOFV, Hash> iterator;
iterator begin()
{
for (size_t i = 0; i < _tables.size(); ++i)
{
if (_tables[i] != nullptr)
return iterator(_tables[i], this);// 哈希桶的第一个节点
}
return end();// 没有节点返回最后一个迭代器
}
iterator end()
{
return iterator(nullptr, this);
}
};
封装unordered_map和unordered_set
template<class K, class V, class Hash = _Hash<K>>
class unordered_map
{
struct MapKeyOfValue
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
typedef HashBucket<K, pair<K, V>, MapKeyOfValue, Hash> HashBucket;
public:
// 告诉编译器这只是一个类型
typedef typename HashBucket::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
iterator find(const K& key)
{
return _ht.Find(key);
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = insert(make_pair(key, V()));
return ret.first->second;
}
private:
HashBucket _ht;
};
-----------------------------------------------------------------------------------
template<class K, class Hash = _Hash<K>>
class unordered_set
{
struct SetKeyOfValue
{
const K& operator()(const K& key)
{
return key;
}
};
// 告诉编译器这只是一个类型
typedef HashBucket<K, K, SetKeyOfValue, Hash> HashBucket;
public:
// 告诉编译器这只是一个类型
typedef typename HashBucket::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
pair<iterator, bool> insert(const K& kv)
{
return _ht.Insert(kv);
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
iterator find(const K& key)
{
return _ht.Find(key);
}
private:
HashBucket _ht;
};
测试unordered_map:
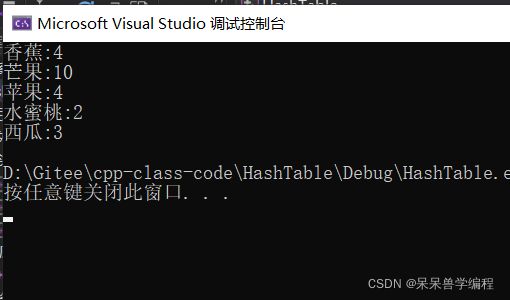
void test_unordered_map3()
{
unordered_map<string, int> countMap;
string strArr[] = { "香蕉","香蕉" ,"水蜜桃","西瓜","苹果","西瓜","香蕉" ,"苹果","西瓜","苹果","苹果","香蕉" ,"水蜜桃" };
for (auto& e : strArr)
{
countMap[e]++;
}
countMap["芒果"] = 10;
for (auto& e : countMap)
{
cout << e.first << ":" << e.second << endl;
}
}
代码运行结果如下:
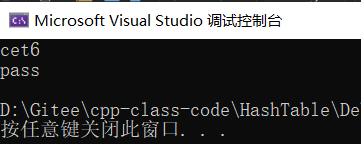
测试unordered_set:
void test_unordered_set2()
{
unordered_set<string> s;
s.insert("sort");
s.insert("pass");
s.insert("cet6");
s.insert("pass");
s.insert("cet6");
s.erase("sort");
for (auto& e : s)
{
cout << e << endl;
}
}
代码运行结果如下:
总结
这两个容器应用的还是比较多的,因为它的效率高,对于map和unordered_map,我们都会倾向于选择后者。今天就先介绍到这来了,喜欢的话,欢迎点赞、支持和关注~
