本文是使用pycharm下的pytorch框架编写一个训练本地数据集的Resnet深度学习模型,其一共有两百行代码左右,分成mian.py、network.py、dataset.py以及train.py文件,功能是对本地的数据集进行分类。本文介绍逻辑是总分形式,即首先对总流程进行一个概括,然后分别介绍每个流程中的实现过程(代码+流程图+文字的介绍)。
对于整个项目的流程首先是加载本地数据集,然后导入Resnet网络,最后进行网络训练。整体来说一个完整的小项目,难度并不高,需要有一定的pytorch语句以及深度学习的基础。
mian.py文件是该项目的总文件,也是训练网络模型的运行文件,文本的介绍流程是随着该文件一 一对代码进行介绍。
main.py代码如下所示:
from dataset import data_dataloader #电脑本地写的读取数据的函数 from torch import nn #导入pytorch的nn模块 from torch import optim #导入pytorch的optim模块 from network import Res_net #电脑本地写的网络框架的函数 from train import train #电脑本地写的训练函数 def main(): # 以下是通过Data_dataloader函数输入为:数据的路径,数据模式,数据大小,batch的大小,有几线并用 (把dataset和Dataloader功能合在了一起) train_loader = data_dataloader(data_path='./data', mode='train', size=64, batch_size=24, num_workers=4) val_loader = data_dataloader(data_path='./data', mode='val', size=64, batch_size=24, num_workers=2) test_loader = data_dataloader(data_path='./data', mode='test', size=64, batch_size=24, num_workers=2) # 以下是超参数的定义 lr = 1e-4 #学习率 epochs = 10 #训练轮次 model = Res_net(2) # resnet网络 optimizer = optim.Adam(model.parameters(), lr=lr) # 优化器 loss_function = nn.CrossEntropyLoss() # 损失函数 # 训练以及验证测试函数 train(model=model, optimizer=optimizer, loss_function=loss_function, train_data=train_loader, val_data=val_loader,test_data= test_loader, epochs=epochs) if __name__ == '__main__': main()
main.py流程图如图1所示:
图 1 main.py 代码流程图
1.dataset.py(先看代码的总体流程再看介绍)
main.py()前五行分别是导入相应的模块,其中dataset,network以及train是本地编写的文件。在mian()函数中的前几行代码中,我们使用dataset.py文件中的Data_dataloader函数导入训练集、验证集和测试集。Dataset文件是导入我们自己的本地数据库,其功能是得到所有的数据,将其变成pytorch能够识别的tensor数据,然后得到图片。
dataset.py文件代码如下所示:
import torch import os,glob import random import csv from torch.utils.data import Dataset from PIL import Image from torchvision import transforms from torch.utils.data import DataLoader # 第一部分:通过三个步骤得到输出的tensor类型的数据 class Dataset_self(Dataset): #如果是nn.moduel 则是编写网络模型框架,这里需要继承的是dataset的数据,所以括号中的是Dataset #第一步:初始化 def __init__(self,root,mode,resize,): #root是文件根目录,mode是选择什么样的数据集,resize是图像重新调整大小 super(Dataset_self, self).__init__() self.resize = resize self.root = root self.name_label = {} #创建一个字典来保存每个文件的标签 #首先得到标签相对于的字典(标签和名称一一对应) for name in sorted(os.listdir(os.path.join(root))): #排序并且用列表的形式打开文件夹 if not os.path.isdir(os.path.join(root,name)): #不是文件夹就不需要读取 continue self.name_label[name] = len(self.name_label.keys()) #每个文件的名字为name_Label字典中有多少对键值对的个数 #print(self.name_label) self.image,self.label = self.make_csv('images.csv') #编写一共函数来读取图片和标签的路径 #在得到image和label的基础上对图片数据进行一共划分 (注意:如果需要交叉验证就不需要验证集,只划分为训练集和测试集) if mode == 'train': self.image ,self.label= self.image[:int(0.6*len(self.image))],self.label[:int(0.6*len(self.label))] if mode == 'val': self.image ,self.label= self.image[int(0.6*len(self.image)):int(0.8*len(self.image))],self.label[int(0.6*len(self.label)):int(0.8*len(self.label))] if mode == 'test': self.image ,self.label= self.image[int(0.8*len(self.image)):],self.label[int(0.8*len(self.label)):] # 获得图片和标签的函数 def make_csv(self,filename): if not os.path.exists(os.path.join(self.root,filename)): #如果不存在汇总的目录就新建一个 images = [] for image in self.name_label.keys(): # 让image到name_label中的每个文件中去读取图片 images += glob.glob(os.path.join(self.root,image,'*jpg')) #加* 贪婪搜索关于jpg的所有文件 #print('长度为:{},第二张图片为:{}'.format(len(images),images[1])) random.shuffle(images) #把images列表中的数据洗牌 # images[0]: ./data\ants\382971067_0bfd33afe0.jpg with open(os.path.join(self.root,filename),mode='w',newline='') as f : #创建文件 writer = csv.writer(f) for image in images: name = image.split(os.sep)[-2] #得到与图片相对应的标签 label = self.name_label[name] writer.writerow([image,label]) #写入文件 第一行:./data\ants\382971067_0bfd33afe0.jpg,0 images,labels = [],[] with open(os.path.join(self.root,filename)) as f: #读取文件 reader = csv.reader(f) for row in reader: image, label = row label = int(label) images.append(image) labels.append(label) assert len(images) == len(labels) #类似if语句,只有两者长度一致才继续执行,否则报错 return images,labels #返回所有!!是所有的图片和标签(此处的图片不是图片数据本身,而是它的文件目录) #第二步:得到图片数据的长度(标签数据长度与图片一致) def __len__(self): return len(self.image) #第三步:读取图片和标签,并输出 def __getitem__(self, item): # 单张返回张量的图像与标签 image,label = self.image[item],self.label[item] #得到单张图片和相应的标签(此处都是image都是文件目录) image = Image.open(image).convert('RGB') #得到图片数据 #使用transform对图片进行处理以及变成tensor类型数据 transf = transforms.Compose([transforms.Resize((int(self.resize),int(self.resize))), transforms.RandomRotation(15), transforms.CenterCrop(self.resize), transforms.ToTensor(), #先变成tensor类型数据,然后在进行下面的标准化 ]) image = transf(image) label = torch.tensor(label) #把图片标签也变成tensor类型 return image,label #第二部分:使用pytorch自带的DataLoader函数批量得到图片数据 def data_dataloader(data_path,mode,size,batch_size,num_workers): #用一个函数加载上诉的数据,data_path、mode和size分别是以上定义的Dataset_self()中的参数,batch_size是一次性输出多少张图像,num_worker是同时处理几张图像 dataset = Dataset_self(data_path,mode,size) dataloader = DataLoader(dataset,batch_size,num_workers) #使用pytorch中的dataloader函数得到数据 return dataloader #测试 def main(): test = Dataset_self('./data','train',64) if __name__ == '__main__': main()
dataset.py流程图2所示:

图2 dataset.py流程图
如以上代码所示,使用pytorch加载自定义的数据集时,需要定义一个dataset的对象,然后定义一个dataloaber的对象,最后对dataloaber反复得到训练数据和标签。所以本文件主要分为两个部分:自定义的dataset部分和使用pytorch中dataloaber来得到训练数据的部分。
代码首先是导入必要的python库,然后编写第一部分。第一部分主要是通过三个步骤来得到单张输出的tensor类型图片和标签。
三个步骤分别是:初始化、获得数据的长度以及读取数据和标签。其中初始化是为了得到一个文件,文件中保存所有图片相对应的目录以及其标签,再将得到的文件读出分为训练集、验证集和测试集。具体实现如上述代码所示,首先在初始化的函数中定义变量resize、root和name_label,方便与后面的函数调用:

图3 Dataset_self中参数的初始化
然后,我们编写代码读取根目录,得到分类名字及其相对应的标签:

图4 标签的获得
代码中,首先使用os库来把根目录内的文件变成列表被读取出来,然后把根目录内所有文件名保存在name_label字典中,在分别依照存储进字典的个数来给标签数值化。(第一个读取进字典的标签就是0,第二个是1,其余文件以此类推)
得到标签字典后,我们编写一个函数来获得所有图片的目录,便于下面步骤的图片读取:
![]()
图5 图片和标签的读取
编写make_csv函数,来得到image和label(image是每张图片的目录,label是相对应的标签)。
make_csv函数中,首先判断是否以及存在我们需要的文件,如果存在则直接读取,如果不存在就先生成一个存储所有图片目录和标签的文件。
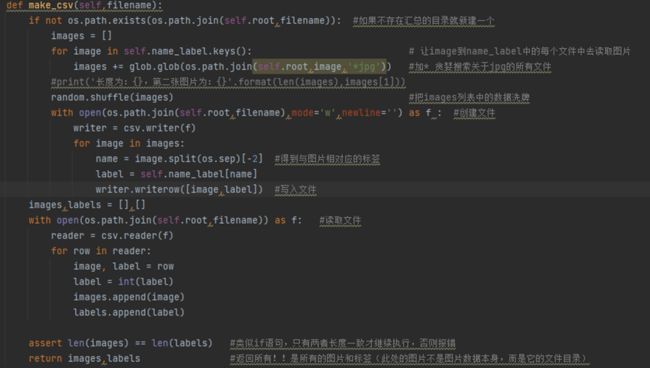
图6 make_csv函数
当文件不存在时(第一行语句的判断),我们编写文件的思路是先编写一个列表来保存所有的图片目录,然后再创建文件使用csv库把列表数据写入文件中。所以在判断语句下面,我们得到一个空的images列表,然后遍历name_label中的keys,对于name_label来说,它是一个key是文件名,value是标签(数值)的字典,因为是用os库把文件读取成为字典的,所以遍历字典内的key时,是读取的是相对应的文件。所以上图第四行代码中是分别读取文件中的图片,然后使用glob库分别把所有jpg文件存储到images列表里面。在列表中images[0]是:./data\ants\382971067_0bfd33afe0.jpg
在得到图片目录列表后,首先将列表内的数据随机排列,然后创造一个文件,在列表images中的目录得到标签名称,用name_label得到标签名称相对应的数值,最后写入文件中。文件第一行是:./data\ants\382971067_0bfd33afe0.jpg,0 (图片相对目录和相对于的标签)
得到文件后,因为我们需要的是每张图片的目录而不是文件(主要是为了后面反复调试,所以得到一个文件做中转站),所以我们需要用两个列表来得到图片目录和相对应的标签值,最后分别把文件中的数据写入列表中,得到图片和标签列表。
至此,我们就能通过函数make_csv来得到image和label。得到这两个列表后,我们对其进行切割,因为列表里面是保存的所以数据,所以我们需要分割为训练集、验证集和测试集。代码很简单,(如果需要交叉验证则只需要划分出训练集和测试集即可)如下图所示:

图7 数据集的划分
以上是第一步初始化的过程,第二步读取图像长度:

图8 读取图像长度
很简单,一个len()函数就搞定,其主要功能是知道一共有多少数据。
第三步:读取数据和标签,读取数据是一张一张来读取的,所以首先从image和label列表中得到单个数据,因为image列表中保存的是图片的目录,所以先读取RGB格式的图片,然后使用transform对图片进行相应的处理(尺寸,图片变化,变成tensor类型等),最后也将label变成tensor类型然后把图片数据和标签数据返回即可,代码如下图所示:
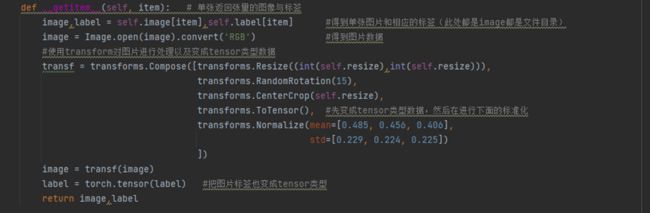
图8 读取图像和标签
第一部分是读取图片和图片相对应的标签,流程是三步:初始化、得到数据长度和读取单张数据,对于pytorch的dataset处理都是基于这三步。其中算法逻辑并不复杂,主要是需要使用的语句有点多,需要仔细思考其中的逻辑。
第二部分相对于第一部分要简单很多,甚至可以把这部分放到main()函数中运行。其主要内容是通过第一部分得到的dataset_self来得到数据,然后使用pytorch自带的dataloader得到放入模型中训练的数据集,代码如下图所示:

图9 数据集的获取
Dataset部分其功能简单概括就是将本地数据集中的图片和标签变成tensor类型数据读取为需要使用的数据集。
2.network.py
main.py()中,我们定义了一些超参数等,分别有学习率,训练轮次,训练模型,优化器以及损失函数。对于训练模型,本文使用的是本地编写的一个小型的Resnet模型。其代码如下所示:
import torch from torch import nn # 先写好resnet的block块 class Res_block(nn.Module): def __init__(self,in_num,out_num,stride): super(Res_block, self).__init__() self.cov1 = nn.Conv2d(in_num,out_num,(3,3),stride=stride,padding=1) #(3,3) padding=1 则图像大小不变,stride为几图像就缩小几倍,能极大减少参数 self.bn1 = nn.BatchNorm2d(out_num) self.cov2 = nn.Conv2d(out_num,out_num,(3,3),padding=1) self.bn2 = nn.BatchNorm2d(out_num) self.extra = nn.Sequential( nn.Conv2d(in_num,out_num,(1,1),stride=stride), nn.BatchNorm2d(out_num) ) #使得输入前后的图像数据大小是一致的 self.relu = nn.ReLU() def forward(self,x): out = self.relu(self.bn1(self.cov1(x))) out = self.relu(self.bn2(self.cov2(out))) out = self.extra(x) + out return out class Res_net(nn.Module): def __init__(self,num_class): super(Res_net, self).__init__() self.init = nn.Sequential( nn.Conv2d(3,16,(3,3)), nn.BatchNorm2d(16) ) #预处理 self.bn1 = Res_block(16,32,2) self.bn2 = Res_block(32,64,2) self.bn3 = Res_block(64,128,2) self.bn4 = Res_block(128,256,2) self.fl = nn.Flatten() self.linear1 = nn.Linear(8192,10) self.linear2 = nn.Linear(10,num_class) self.relu = nn.ReLU() def forward(self,x): out = self.relu(self.init(x)) #print('inint:',out.shape) out = self.bn1(out) #print('bn1:', out.shape) out = self.bn2(out) #print('bn2:', out.shape) out = self.bn3(out) #print('bn3:', out.shape) out = self.fl(out) #print('flatten:', out.shape) out = self.relu(self.linear1(out)) #print('linear1:', out.shape) out = self.relu(self.linear2(out)) #print('linear2:', out.shape) return out #测试 def main(): x = torch.randn(2,3,64,64) net = Res_net(2) out = net(x) print(out.shape) if __name__ == '__main__': main()
network.py流程图如图10所示:
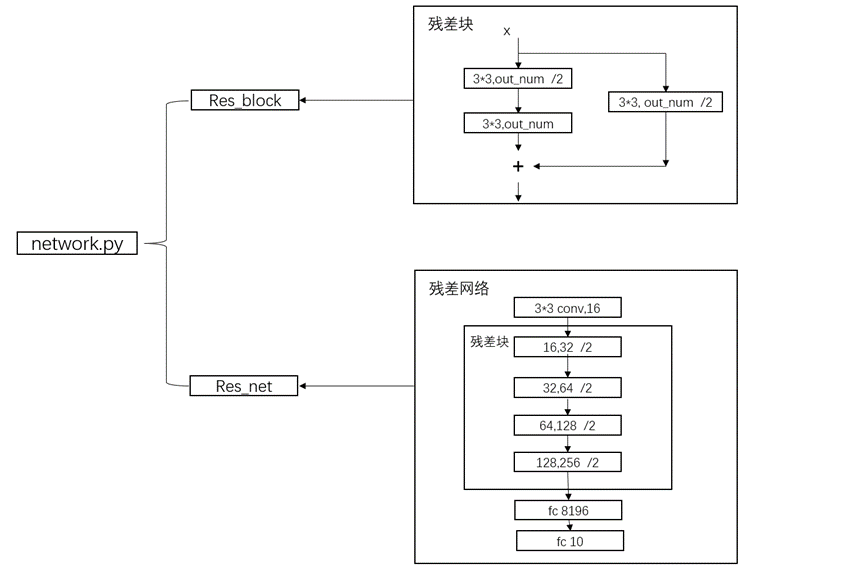
图10 network.py流程图
Resnet模型网络主要是两部分,首先编写resnet中的每个残差块,然后编写整个网络。在开始介绍代码之前,首先用我的理解来介绍一下Resnet,也就是残差网络的思想与逻辑(具体可以搜索其他资料查看)。残差网络其主要的目的是能够训练一个深层次的网络,希望是随着网络的加深,效果越来越好。但是因为网络加深,很有可能一些参数会得不到训练(一次次的迭代,使得梯度消失),所有Resnet网络巧妙的运用了一个残差块来解决因为网络模型太深而导致其梯度消失的问题,如图11所示:

图11 残差块
简单来说就是在x通过两个层后,在和x本身相加,如此在反向传播的过程中,f(x)+x求带就变成如此就在回传给x上面的隐藏层的时候就不会发生梯度消失(至少有个1)。如果在x输入残差块前有n层,那么就算残差快内的隐藏层因为梯度消失的问题而没有训练好,但是至少x输入之前的n层是训练好了的,这样只要残差快中的隐藏层能训练好一部分,神经网络的准确度就很有可能在原来基础上增加。(还是得好好研究,这里Resnet的解释可能并没有那么准确)
基于上述残差块的图片,我们先定义好残差块,代码如下图12所示:

图12 残差块的定义
其流程图如图13:

图13 残差块定义流程图
当残差块写好后,就可以编写一个简单的Resnet网络,代码如图14所示:
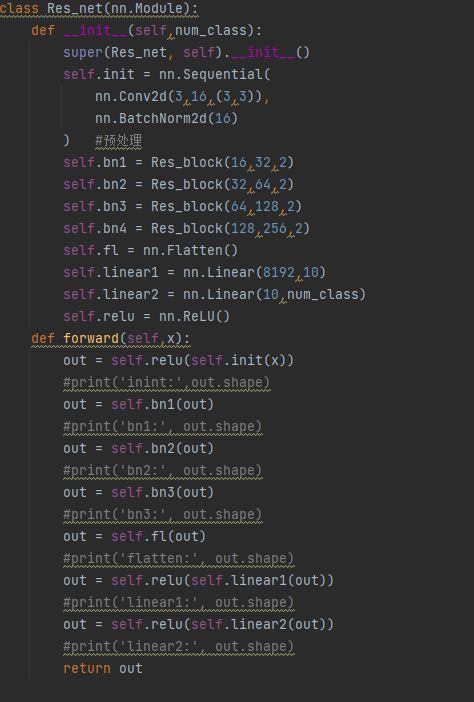
图14 简单Resnet网络模型
上述代码中,首先通过一层正常的卷积层后,再通过3个残差块,最后通过两层线性层,代码十分比较简单。在定义好残差块之后,调用pytorch本身自带的函数即可完成。唯一需要注意的地方是参数的设置,该网络一般来说都是维度在慢慢增加,图像的尺寸慢慢减少。
3.train.py
train.py是整个模型的训练过程,本文将其打包成为一个函数,然后在mian.py中调用,因为基本上网络的训练过程都大同小异,一般都是用训练集训练,在验证集上得到最好的轮次,最后保存网络参数并且在测试集上检测,所以这里直接将训练过程和验证过程打包成为函数,便于以后项目的直接调用。
train.py代码如下所示:
import torch
from torch import optim
from torch.utils.data import DataLoader
from dataset import Dataset_self
from network import Res_net
from torch import nn
from matplotlib import pyplot as plt
import numpy as np
def evaluate(model,loader): #计算每次训练后的准确率
correct = 0
total = len(loader.dataset)
for x,y in loader:
logits = model(x)
pred = logits.argmax(dim=1) #得到logits中分类值(要么是[1,0]要么是[0,1]表示分成两个类别)
correct += torch.eq(pred,y).sum().float().item() #用logits和标签label想比较得到分类正确的个数
return correct/total
#把训练的过程定义为一个函数
def train(model,optimizer,loss_function,train_data,val_data,test_data,epochs): #输入:网络架构,优化器,损失函数,训练集,验证集,测试集,轮次
best_acc,best_epoch =0,0 #输出验证集中准确率最高的轮次和准确率
train_list,val_List = [],[] # 创建列表保存每一次的acc,用来最后的画图
for epoch in range(epochs):
print('============第{}轮============'.format(epoch + 1))
for steps,(x,y) in enumerate(train_data): # for x,y in train_data
logits = model(x) #数据放入网络中
loss = loss_function(logits,y) #得到损失值
optimizer.zero_grad() #优化器先清零,不然会叠加上次的数值
loss.backward() #后向传播
optimizer.step()
train_acc =evaluate(model,train_data)
train_list.append(train_acc)
print('train_acc',train_acc)
#if epoch % 1 == 2: #这里可以设置每两次训练验证一次
val_acc = evaluate(model,val_data)
print('val_acc=',val_acc)
val_List.append((val_acc))
if val_acc > best_acc: #判断每次在验证集上的准确率是否为最大
best_epoch = epoch
best_acc = val_acc
torch.save(model.state_dict(),'best.mdl') #保存验证集上最大的准确率
print('===========================分割线===========================')
print('best acc:',best_acc,'best_epoch:',best_epoch)
#在测试集上检测训练好后模型的准确率
model.load_state_dict((torch.load('best.mdl')))
print('detect the test data!')
test_acc = evaluate(model,test_data)
print('test_acc:',test_acc)
train_list_file = np.array(train_list)
np.save('train_list.npy',train_list_file)
val_list_file = np.array(val_List)
np.save('val_list.npy',val_list_file)
#画图
x_label = range(1,len(val_List)+1)
plt.plot(x_label,train_list,'bo',label='train acc')
plt.plot(x_label,val_List,'b',label='validation acc')
plt.title('train and validation accuracy')
plt.xlabel('epochs')
plt.legend()
plt.show()
#测试
def main():
train_dataset = Dataset_self('./data', 'train', 64)
vali_dataset = Dataset_self('./data', 'val', 64)
test_dataset = Dataset_self('./data', 'test', 64)
train_loaber = DataLoader(train_dataset, 24, num_workers=4)
val_loaber = DataLoader(vali_dataset, 24, num_workers=2)
test_loaber = DataLoader(test_dataset, 24, num_workers=2)
lr = 1e-4
epochs = 5
model = Res_net(2)
optimizer = optim.Adam(model.parameters(), lr=lr)
criteon = nn.CrossEntropyLoss()
train(model,optimizer,criteon,train_loaber,val_loaber,test_loaber,epochs)
if __name__ == '__main__':
main()
train.py流程图如图15所示:

图15 train.py流程图
上述代码中,第一个函数的定义是为了得到一次训练(或者验证或者测试)后的准确率,也就是跑完一次所有训练集后,模型的准确率是多少。其代码内容并不复杂,先得到经过模型logits中的分类标签(是[1,0]还是[0,1],表示分成两类)pred,然后用logits与标签进行比较,从而得到一个batch_size中分类正确的个数,然后累加起来,得到一次训练中网络对数据集分类正确的个数(correct),最后让其除以数据集的个数从而得到准确率并且返回其数值。
对于第二个函数,train的函数的定义,其主要内容是在训练集上训练,每一轮次训练好之后放在验证集上验证(可以是每两次或者三次),执行完所有轮次后,保存在验证集上最好的一次的网络参数与轮次,最后加载保存的网络参数对测试集进行检测。
train函数内部首先定义验证集中最好的准确率和最好的轮次,然后创建两个列表来保存每一次的训练集和验证集的准确率(用来画图查看),然后就是进行epochs次训练。
![]()
图16 trian函数内参数的定义
训练中,如果直接是用x,y来获得数据的图片和标签则可以使用标注里面的代码,而使用enumerate函数,其主要是为了给每次得到的数据(x,y)标上一个索引,这个索引是steps,从0开始(这里没有使用到steps参数)。在每次执行中,图片数据x会被放入网络模型model中被处理,然后使用定义的loss_function函数得到预测和正确标签之间的损失值。优化器先清零(不然会有数值叠加),然后让损失值loss执行反向传播操作(链式求导),最后优化器执行优化功能,如此便实现了模型的一次训练与参数更新。

图17 模型的训练步骤
而后面的代码,每训练一次网络模型,就把验证集放入网络模型中,测试网络模型训练得怎么样,然后保存下epochs次数中最好准确率的网络模型参数与轮次。最后加载保存下的网络模型参数,在测试集上检测准确率如何。

图18 模型参数的保存与测试
最后几句代码是将保存下来的准确率做图,有一点需要注意,因为这里是每次训练后都在验证集上检测过,所以坐标轴的长度就用训练集准确率的长度来表示两个不同数据的长度。
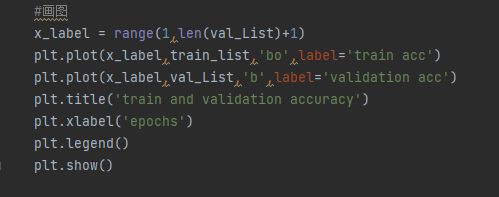
图19 做图
4.结果与总结
本文项目是使用Resnet模型来识别蚂蚁和蜜蜂,其一共有三百九十六张的数据,训练集只有两百多张(数据集很小),运行十轮后,分别对训练集和测试集在每一轮的准确率如图所示:

图20 train and validation accuracy
测试集的准确率如图所示:

图21 测试集准确率
最后得到的效果不理想,很大可能是数据集太少导致导致模型泛化能力变弱(模型把训练集都记下来了),对于这样的问题可以尝试通过交叉验证(效果可能有一定程度的提升)或者增加数据集的方法来增强模型的泛化能力。对精度的提升,会在后续的文章中进行讨论。
在得到模型参数后,我随便在网上找了两张蚂蚁的图片放进模型检测看效果如何:
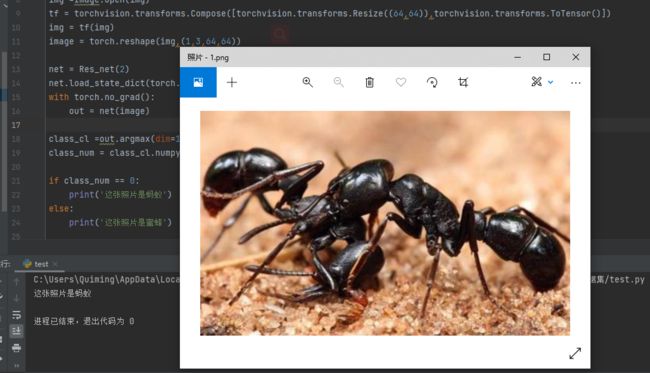
图22 第一次测试

图23 第二次测试
第一次测试识别出来了是蚂蚁,但是第二次就失败了,有可能是模型没有看到过黑色的蜜蜂所以把黑色的都当成了蚂蚁吧,总之改模型还有很多需要改进的地方。
附上单张检测的代码:
from network import Res_net import torch from PIL import Image import torchvision #导入图片 img = '1.jpg' img =Image.open(img) tf = torchvision.transforms.Compose([torchvision.transforms.Resize((64,64)),torchvision.transforms.ToTensor()]) img = tf(img) image = torch.reshape(img,(1,3,64,64)) #加载模型 net = Res_net(2) net.load_state_dict(torch.load('best.mdl')) with torch.no_grad(): out = net(image) #确定分类 class_cl =out.argmax(dim=1) class_num = class_cl.numpy() if class_num == 0: print('这张照片是蚂蚁') else: print('这张照片是蜜蜂')
总的来说,整篇文章对于有pytorch以及深度学习基础的人来说是偏向于简单的,除了dataset.py中可能有一些小问题,而其中的问题也并非与深度学习有关,主要是算法思维上的问题(即如何用代码来实现数据的导入过程)而其他部分则是pytorch编写深度学习算法的常规操作。而其中的框架还是有很多可以改善的内容,比如模型的改善,做图的改善等等。模型最后运行得到的结果并不理想,原因可能是数据集太少,用于训练的图片仅三百张左右,在这样的情况下,要么增加数据集,要么可以使用交叉验证的方法进行网络的精度提升(数据集太少了,网络把所有图片都块记住了,所以训练时的准确率很高但是验证集和测试集准确率却不理想,改进的内容留在下次研究介绍),也有模型比较简单运行轮次太少的缘故,总之其中还是有很多地方需要去研究考虑。
纵横整篇文章,其实主要思想还是如本人其他文章里面的思想一样,先是处理好数据集,然后搭建网络,最后训练,编译等。以我的薄见,以小见大,或许在深度学习中对于一些大的项目或者复杂的项目其本质也是逃不过这几点,但是其分支,其问题,其模块会有很多复杂的考虑。这就关乎于问题中的算法思维了,在后续中,本人可能会把这个小项目做得有深度一些,比如说对于正常物品和损坏物品之间的分类,当然,这样的话对问题的考虑就会多了很多,对其数据集的处理以及模型的框架可能会复杂很多。
对于深度学习也好,写代码也好,如果只是简单的写,很难对自己的能力有所提升,关键还是在于如何把问题算法化(即用代码高效的解决一个问题),所以算法还是得好好学啊。(还有,一定要动手实践)
至此,一个Resnet网络训练本地数据集的小项目就全部介绍完毕了,项目虽然简单了一些,但是麻雀虽小五脏俱全啊!
最后告诫自己以及所有小伙伴们:路漫漫其修远兮,吾将上下而求索。